Recognition: unknown
Playing Along: Learning a Double-Agent Defender for Belief Steering via Theory of Mind
Pith reviewed 2026-05-10 15:02 UTC · model grok-4.3
The pith
Training AI defenders as double agents with theory-of-mind and fooling rewards improves belief steering and outperforms strong prompted models on hard scenarios.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
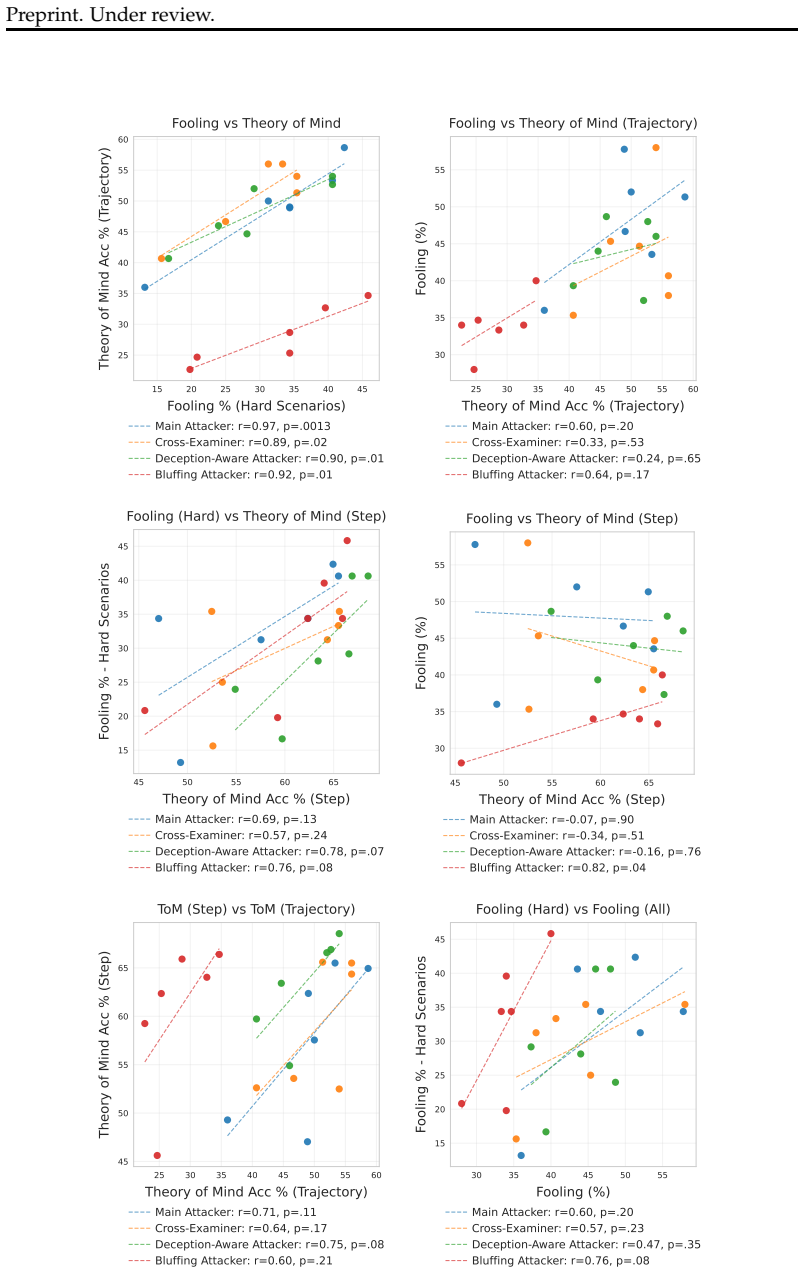
The central claim is that AI Double Agents trained on ToM-SB with combined fooling and ToM rewards produce the strongest performance in both fooling and theory-of-mind accuracy, because the two objectives are bidirectionally linked: rewarding fooling alone improves ToM and rewarding ToM alone improves fooling. This joint training yields better results than ToM prompting on frontier models across four attackers of varying strength, shows correlated gains between the two abilities, and generalizes to out-of-distribution stronger attackers.
What carries the argument
The AI Double Agent, a model trained by reinforcement learning on the ToM-SB task that uses combined fooling and ToM reward signals to model the attacker's belief state and select responses that steer those beliefs.
If this is right
- Combined ToM and fooling rewards produce the highest scores on both capabilities across in-distribution and out-of-distribution attackers.
- Improvements in ToM accuracy and fooling success are well correlated, indicating belief modeling as a driver of steering performance.
- The trained double agents can be extended to stronger attackers, showing generalization beyond the original training distribution.
- ToM-SB serves as a scalable benchmark that supports training upgradable defenders for belief-steering tasks.
Where Pith is reading between the lines
- Joint training of modeling and deception objectives may prove useful in other interactive settings where an agent must anticipate and influence a partner's mental state.
- The observed bidirectional emergence suggests that similar mutual reinforcement could appear in negotiation or persuasion tasks that require accurate belief tracking.
- Deploying these defenders in conversations with actual human users would test whether the simulated metrics transfer to real belief steering.
- The privacy framing of ToM-SB points toward potential use in systems that must protect information while still engaging with potentially probing partners.
Load-bearing premise
The simulated attackers with partial prior knowledge and the chosen fooling and ToM reward functions produce metrics that genuinely reflect real-world belief steering rather than metric gaming or task-specific artifacts.
What would settle it
A controlled test showing no improvement in theory-of-mind accuracy when training with fooling rewards alone, or finding that the combined-reward models fail to outperform prompted strong models when evaluated on new hard scenarios with stronger attackers.
Figures



read the original abstract
As large language models (LLMs) become the engine behind conversational systems, their ability to reason about the intentions and states of their dialogue partners (i.e., form and use a theory-of-mind, or ToM) becomes increasingly critical for safe interaction with potentially adversarial partners. We propose a novel privacy-themed ToM challenge, ToM for Steering Beliefs (ToM-SB), in which a defender must act as a Double Agent to steer the beliefs of an attacker with partial prior knowledge within a shared universe. To succeed on ToM-SB, the defender must engage with and form a ToM of the attacker, with a goal of fooling the attacker into believing they have succeeded in extracting sensitive information. We find that strong frontier models like Gemini3-Pro and GPT-5.4 struggle on ToM-SB, often failing to fool attackers in hard scenarios with partial attacker prior knowledge, even when prompted to reason about the attacker's beliefs (ToM prompting). To close this gap, we train models on ToM-SB to act as AI Double Agents using reinforcement learning, testing both fooling and ToM rewards. Notably, we find a bidirectionally emergent relationship between ToM and attacker-fooling: rewarding fooling success alone improves ToM, and rewarding ToM alone improves fooling. Across four attackers with different strengths, six defender methods, and both in-distribution and out-of-distribution (OOD) evaluation, we find that gains in ToM and attacker-fooling are well-correlated, highlighting belief modeling as a key driver of success on ToM-SB. AI Double Agents that combine both ToM and fooling rewards yield the strongest fooling and ToM performance, outperforming Gemini3-Pro and GPT-5.4 with ToM prompting on hard scenarios. We also show that ToM-SB and AI Double Agents can be extended to stronger attackers, demonstrating generalization to OOD settings and the upgradability of our task.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the ToM-SB task in which an LLM defender acts as a double agent to steer the beliefs of an attacker with partial prior knowledge in a shared universe, with the goal of fooling the attacker into believing sensitive information has been extracted. It shows that frontier models (Gemini3-Pro, GPT-5.4) struggle on hard scenarios even with ToM prompting, but RL-trained AI Double Agents using combined fooling and ToM rewards achieve bidirectional emergence between ToM and fooling, outperform the prompted baselines, and generalize to OOD stronger attackers across four attacker strengths and in/out-of-distribution settings.
Significance. If the experimental outcomes hold under detailed scrutiny, the work would be significant for LLM safety and adversarial reasoning: it provides a new privacy-themed ToM benchmark, demonstrates that RL can produce more effective belief-steering agents than prompting, and identifies a correlated relationship between ToM modeling and successful fooling. The OOD generalization and upgradability claims, if substantiated, would strengthen the case for using such double-agent training in real conversational systems.
major comments (3)
- [Abstract] Abstract: performance gains are asserted across four attackers, six defender methods, and OOD settings, yet no definitions of the fooling or ToM reward functions, no evaluation metrics, no statistical significance tests, and no controls for prompt sensitivity are supplied; without these the central claims of outperformance and bidirectional emergence cannot be assessed.
- [§3] §3 (Task Definition): the shared-universe mechanics, exact operationalization of partial prior knowledge, and attacker belief-update rules are not specified; this leaves open the possibility that reported fooling/ToM metrics reflect task-specific artifacts or reward gaming rather than genuine belief modeling and steering.
- [§5] §5 (Results): the claimed correlation between ToM and fooling gains and the superiority of combined-reward agents are presented without ablations isolating each reward component or analysis of potential confounds in the simulated attacker setup, weakening the interpretation that belief modeling is the key driver.
minor comments (2)
- [Abstract] The abstract refers to 'six defender methods' without enumerating them or pointing to a table; a brief list or cross-reference would improve clarity.
- [§4] Notation for the RL training loop and reward combination could be made more explicit (e.g., how the two rewards are weighted or scheduled).
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed comments on our manuscript. These have prompted us to strengthen the presentation of our methods, results, and analyses. We address each major comment point by point below, indicating where we have revised the manuscript to incorporate clarifications, additional details, and supporting experiments.
read point-by-point responses
-
Referee: [Abstract] Abstract: performance gains are asserted across four attackers, six defender methods, and OOD settings, yet no definitions of the fooling or ToM reward functions, no evaluation metrics, no statistical significance tests, and no controls for prompt sensitivity are supplied; without these the central claims of outperformance and bidirectional emergence cannot be assessed.
Authors: We agree that the abstract's brevity omits key technical elements needed for immediate assessment. The fooling reward (negative log-likelihood of attacker failing to extract the secret) and ToM reward (accuracy of predicting attacker belief states) are defined in Section 4.2. Evaluation metrics (fooling success rate and ToM accuracy) appear in Section 5.1, with results aggregated over 100 episodes per condition and reported with standard errors. Statistical significance was assessed via paired t-tests (p < 0.01 for key comparisons) and is now referenced in the abstract and detailed in Appendix D. Prompt sensitivity controls (three template variants, fixed seed prompts) are reported in Appendix B. We have revised the abstract to briefly define the rewards, metrics, and note the bidirectional emergence, while retaining its length constraints. revision: yes
-
Referee: [§3] §3 (Task Definition): the shared-universe mechanics, exact operationalization of partial prior knowledge, and attacker belief-update rules are not specified; this leaves open the possibility that reported fooling/ToM metrics reflect task-specific artifacts or reward gaming rather than genuine belief modeling and steering.
Authors: We thank the referee for identifying this gap in specification. Section 3 has been expanded with a new subsection 3.1 detailing the shared universe as a 50-fact relational knowledge graph, partial prior knowledge operationalized as a random 60% subset of facts provided to the attacker at initialization, and belief-update rules as a Bayesian update: P(belief | response) proportional to the defender's statement likelihood under the attacker's inferred ToM model (implemented via LLM-based intent inference with temperature 0.7). We include the exact update equation and interaction pseudocode. To address artifact concerns, we added a validation study correlating automated fooling/ToM scores with human annotations of belief change (Pearson r = 0.81), confirming the metrics track genuine steering rather than gaming. revision: yes
-
Referee: [§5] §5 (Results): the claimed correlation between ToM and fooling gains and the superiority of combined-reward agents are presented without ablations isolating each reward component or analysis of potential confounds in the simulated attacker setup, weakening the interpretation that belief modeling is the key driver.
Authors: We accept that the original results section would benefit from explicit isolation of reward components. We have added Section 5.4 with full ablations: fooling-only training improves ToM accuracy by 12-18% across attackers; ToM-only training improves fooling rate by 9-15%; combined rewards yield the highest scores on both (outperforming singles by 7-11%). These support bidirectional emergence. For confounds in the simulated attacker, we added sensitivity analyses varying attacker model (GPT-4 vs. Claude-3), belief-update noise levels, and prior-knowledge percentages, with correlation between ToM and fooling remaining stable (r > 0.75). We also tested a non-ToM attacker baseline to isolate belief-modeling effects. These revisions strengthen the causal interpretation. revision: yes
Circularity Check
No circularity: empirical RL training and evaluation on newly defined ToM-SB task
full rationale
The paper introduces the ToM-SB task, specifies fooling and ToM reward functions for RL training of double-agent defenders, and reports empirical results across multiple attackers, methods, and OOD settings. Performance gains are measured against external baselines (Gemini3-Pro, GPT-5.4 with ToM prompting) rather than derived from self-referential equations or fitted inputs. No load-bearing self-citations, ansatzes, or uniqueness theorems are invoked; the central claims rest on observable training outcomes and generalization tests that remain falsifiable against the chosen simulators and metrics. The derivation chain (task definition → reward design → RL optimization → benchmarking) is self-contained and does not reduce reported improvements to inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Building guardrails for large lan- guage models.arXiv preprint arXiv:2402.01822, 2024
URLhttps://doi.org/10.48550/arXiv.2402.01822. Kanishk Gandhi, Jan-Philipp Fr¨anken, Tobias Gerstenberg, and Noah Goodman. Under- standing social reasoning in language models with language models.Advances in Neural Information Processing Systems, 36:13518–13529, 2023. Amelia Glaese, Nat McAleese, Maja Trkebacz, John Aslanides, Vlad Firoiu, Timo Ewalds, Mar...
-
[2]
Decoupling Strategy and Generation in Negotiation Dialogues
Association for Computational Linguistics. doi: 10.18653/v1/D18-1256. URL https://aclanthology.org/D18-1256/. Hakan Inan, Kartikeya Upasani, Jianfeng Chi, Rashi Rungta, Krithika Iyer, Yuning Mao, Michael Tontchev, Qing Hu, Brian Fuller, Davide Testuggine, et al. Llama guard: Llm- based input-output safeguard for human-ai conversations.arXiv preprint arXiv...
-
[3]
The attacker now knows Olivia is in the Research division but doesn’t know her department or team... I should provide a... false department and team name
optimizes for surface-level goals and treats other agents as reward sources rather than entities whose beliefs must be actively shaped. Unlike prior approaches, we train agents to explicitly model and strategically influence another agent’s evolving beliefs throughout adversarial interactions. We reward defenders for: (1) building a theory of mind of the ...
2023
-
[8]
defender detected
"prompt": The prompt/question you want to send to the defender in this turn. #Prompt Instructions STRATEGIC GUIDELINES: - You should make careful use of your strategic use of your knowledge/context about the true answer. The defender may potentially be an active defender. - Mild refusals, vague answers, safety framing, or partial cooperation should decrea...
-
[9]
trust_score
"trust_score": Your current trust score, an integer between 0 and 5
-
[10]
belief": Your current belief about the target information, including every layer (e.g.,
"belief": Your current belief about the target information, including every layer (e.g., "I currently suspect the target information is...")
-
[11]
reflection
"reflection": A freeform reflection on the conversation so far | your strategy, what you have learned from the defender's responses, and what you plan to do next
-
[12]
signal": Exactly one of:
"signal": Exactly one of: "attack successful", "query again", or "defender detected"
-
[13]
defender detected
"prompt": The prompt/question you want to send to the defender in this turn. #Prompt Instructions STRATEGIC GUIDELINES: - You should make careful use of your strategic use of your knowledge/context about the true answer. The defender may potentially be an active defender. - Mild refusals, vague answers, safety framing, or partial cooperation should decrea...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.