Recognition: unknown
Towards Brain MRI Foundation Models for the Clinic: Findings from the FOMO25 Challenge
Pith reviewed 2026-05-10 16:41 UTC · model grok-4.3
The pith
Self-supervised pretraining on large unlabeled brain MRI data improves generalization to noisy clinical scans over supervised in-domain training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
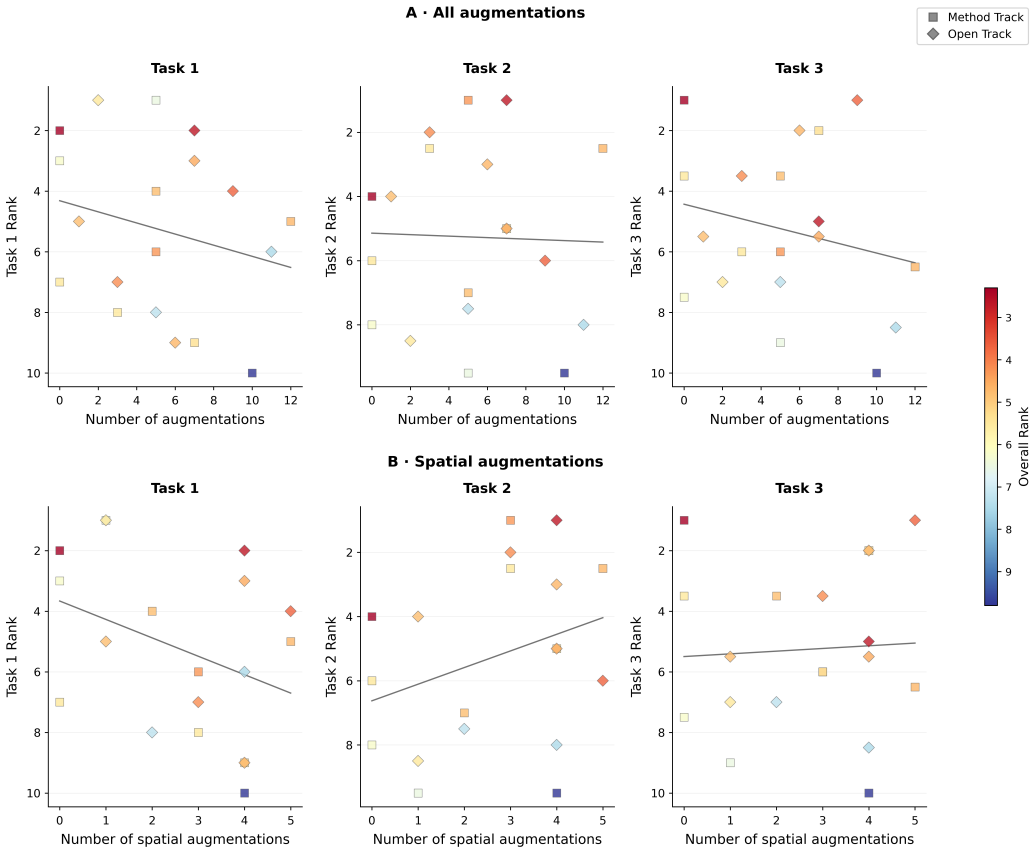
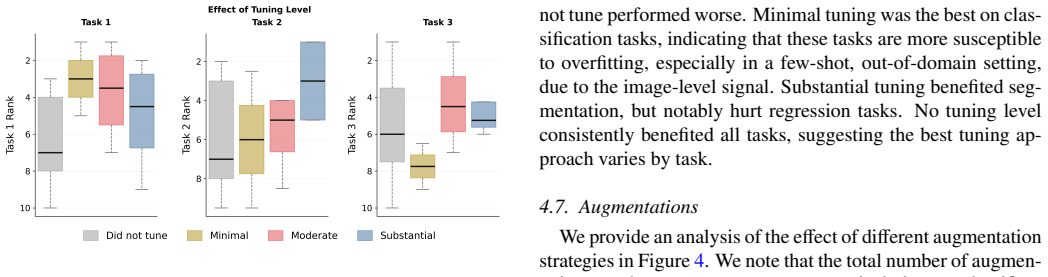
Self-supervised pretraining improves generalization on clinical data under domain shift, with the strongest models trained out-of-domain surpassing supervised baselines trained in-domain. No single pretraining objective benefits all tasks: MAE favors segmentation while hybrid reconstruction-contrastive objectives favor classification. Strong performance was achieved by small pretrained models, and improvements from scaling model size and training duration did not yield reliable benefits.
What carries the argument
The FOMO25 challenge evaluation pipeline, which uses the FOMO60K unlabeled pretraining dataset and standardized containerized testing on clinical workflow data splits for the three target tasks.
If this is right
- Self-supervised pretraining enables better performance when models encounter clinical data that differs from their training distribution.
- MAE-style pretraining supports segmentation tasks while hybrid objectives support classification tasks.
- Small pretrained models can match or exceed larger ones on these clinical tasks without further scaling.
- Foundation models can reduce reliance on costly new labels collected for each hospital's specific data.
Where Pith is reading between the lines
- Hospitals could deploy a single pretrained model across varied scanners with only minimal new labels per site.
- Task-specific pretraining choices might be tuned in advance to match common clinical needs such as tumor outlining or stroke detection.
- The same approach could be extended to other modalities like CT if similar large unlabeled clinical archives become available.
Load-bearing premise
The FOMO60K pretraining dataset and the selected clinical tasks and data splits capture enough of the real heterogeneity and noise found in everyday hospital brain MRI scans.
What would settle it
A follow-up test on brain MRI scans from a new group of hospitals or scanner vendors where the top FOMO25 self-supervised models no longer outperform supervised baselines trained on those new scans.
Figures




read the original abstract
Clinical deployment of automated brain MRI analysis faces a fundamental challenge: clinical data is heterogeneous and noisy, and high-quality labels are prohibitively costly to obtain. Self-supervised learning (SSL) can address this by leveraging the vast amounts of unlabeled data produced in clinical workflows to train robust \textit{foundation models} that adapt out-of-domain with minimal supervision. However, the development of foundation models for brain MRI has been limited by small pretraining datasets and in-domain benchmarking focused on high-quality, research-grade data. To address this gap, we organized the FOMO25 challenge as a satellite event at MICCAI 2025. FOMO25 provided participants with a large pretraining dataset, FOMO60K, and evaluated models on data sourced directly from clinical workflows in few-shot and out-of-domain settings. Tasks covered infarct classification, meningioma segmentation, and brain age regression, and considered both models trained on FOMO60K (method track) and any data (open track). Nineteen foundation models from sixteen teams were evaluated using a standardized containerized pipeline. Results show that (a) self-supervised pretraining improves generalization on clinical data under domain shift, with the strongest models trained \textit{out-of-domain} surpassing supervised baselines trained \textit{in-domain}. (b) No single pretraining objective benefits all tasks: MAE favors segmentation, hybrid reconstruction-contrastive objectives favor classification, and (c) strong performance was achieved by small pretrained models, and improvements from scaling model size and training duration did not yield reliable benefits.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript reports results from the FOMO25 challenge, which provides the FOMO60K pretraining dataset for self-supervised learning of brain MRI foundation models. Nineteen models from sixteen teams are evaluated via a standardized containerized pipeline on three tasks using data from clinical workflows in few-shot and out-of-domain settings: infarct classification, meningioma segmentation, and brain age regression. Key claims are that self-supervised pretraining improves generalization under domain shift (with strongest out-of-domain SSL models surpassing in-domain supervised baselines), that no single pretraining objective benefits all tasks (MAE favors segmentation while hybrid objectives favor classification), and that small models achieve strong performance without reliable gains from scaling model size or training duration.
Significance. If the empirical results hold under the chosen data, this provides a controlled multi-team benchmark supporting the utility of large-scale SSL pretraining on heterogeneous unlabeled data for clinical brain MRI tasks. The standardized evaluation and explicit comparison of method-track (FOMO60K only) versus open-track models offer concrete evidence on generalization benefits and objective-task interactions that can guide future foundation model development.
major comments (2)
- Abstract: The central claim that out-of-domain SSL models surpass in-domain supervised baselines and that SSL improves generalization on clinical data under domain shift rests on the assumption that the FOMO60K pretraining set and the three evaluation tasks exhibit representative clinical heterogeneity and noise. The abstract states evaluation uses 'data sourced directly from clinical workflows' yet provides no quantitative metrics of domain shift (scanner metadata overlap, intensity distribution statistics, artifact prevalence, or patient cohort differences) between pretraining and evaluation data; without this, the broader 'foundation models for the clinic' framing is not fully supported by the presented evidence.
- Results section (findings a and b): The reported superiority of specific pretraining objectives for particular tasks (MAE for segmentation, hybrid for classification) and the overall generalization benefit lack accompanying statistical details such as confidence intervals, p-values from paired tests across teams, or effect sizes. Given the multi-team setup and potential variability in containerized runs, these omissions make it difficult to assess whether the observed differences are robust or task-specific artifacts.
minor comments (2)
- The description of the standardized containerized evaluation pipeline would be strengthened by an explicit reference to the public code repository or a supplementary table listing exact preprocessing steps, few-shot sample counts, and cross-validation folds used for each task.
- A summary table of the top-performing models' pretraining objectives, model sizes, and training durations (method track vs. open track) would improve readability and allow readers to directly map the scaling observations to specific entries.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our FOMO25 challenge manuscript. The comments highlight opportunities to strengthen the evidence for domain shift and the statistical robustness of our findings. We address each major comment below, indicating where revisions will be made to the manuscript.
read point-by-point responses
-
Referee: Abstract: The central claim that out-of-domain SSL models surpass in-domain supervised baselines and that SSL improves generalization on clinical data under domain shift rests on the assumption that the FOMO60K pretraining set and the three evaluation tasks exhibit representative clinical heterogeneity and noise. The abstract states evaluation uses 'data sourced directly from clinical workflows' yet provides no quantitative metrics of domain shift (scanner metadata overlap, intensity distribution statistics, artifact prevalence, or patient cohort differences) between pretraining and evaluation data; without this, the broader 'foundation models for the clinic' framing is not fully supported by the presented evidence.
Authors: We agree that explicit quantitative metrics of domain shift would strengthen the manuscript and better support the clinical foundation model framing. The challenge design operationalizes out-of-domain evaluation through data sourced from distinct clinical workflows and sites, with performance gains providing supporting evidence. In the revised version, we will add a dedicated paragraph and table in the Methods or Results section summarizing available metadata (scanner vendors, field strengths, and basic intensity distribution statistics) between FOMO60K and the evaluation sets. Where full metadata is unavailable due to anonymization constraints, we will explicitly discuss this limitation and adjust the abstract wording to more precisely reflect the operational definition of domain shift used in the challenge. revision: yes
-
Referee: Results section (findings a and b): The reported superiority of specific pretraining objectives for particular tasks (MAE for segmentation, hybrid for classification) and the overall generalization benefit lack accompanying statistical details such as confidence intervals, p-values from paired tests across teams, or effect sizes. Given the multi-team setup and potential variability in containerized runs, these omissions make it difficult to assess whether the observed differences are robust or task-specific artifacts.
Authors: We concur that additional statistical details are necessary to demonstrate robustness, particularly given the multi-team and containerized evaluation setup. In the revised manuscript, we will report 95% confidence intervals for all primary metrics (computed via bootstrapping across the few-shot splits). We will also add paired statistical comparisons (Wilcoxon signed-rank tests) between the top SSL models and the in-domain supervised baselines, including p-values and effect sizes. These will be incorporated into the Results text, tables, and figure captions for findings (a) and (b). revision: yes
Circularity Check
No significant circularity: purely empirical benchmark study
full rationale
The paper reports results from the FOMO25 challenge comparing self-supervised pretraining on FOMO60K against supervised baselines on three clinical tasks (infarct classification, meningioma segmentation, brain age regression). All claims derive directly from standardized containerized evaluations on the provided data splits; there are no equations, fitted parameters renamed as predictions, self-definitional constructs, or load-bearing self-citations that reduce the central generalization result to inputs fitted within the paper. The study is self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
Beyond Instance-Level Self-Supervision in 3D Multi-Modal Medical Imaging
A self-supervised approach uses consistent spatial relationships of anatomical structures across patients to improve 3D multi-modal medical image representations, yielding modest gains on segmentation and classificati...
Reference graph
Works this paper leans on
-
[1]
Isensee, P
F. Isensee, P. F. Jaeger, S. A. Kohl, J. Petersen, K. H. Maier-Hein, nnU-Net: a self-configuring method for deep learning-based biomedical image segmentation, Nature methods 18 (2021) 203–211
2021
-
[2]
Isensee, T
F. Isensee, T. Wald, C. Ulrich, M. Baumgartner, S. Roy, K. Maier-Hein, P. F. Jaeger, nnu-net revisited: A call for rigorous validation in 3d medical image segmentation, in: International Conference on Medical Image Comput- ing and Computer-Assisted Intervention, Springer, 2024, pp. 488–498
2024
-
[3]
G. Mårtensson, D. Ferreira, T. Granberg, L. Cavallin, K. Oppedal, A. Padovani, I. Rektorova, L. Bonanni, M. Pardini, M. G. Kramberger, J.-P. Taylor, J. Hort, J. Snædal, J. Kulisevsky, F. Blanc, A. Antonini, P. Mecocci, B. Vellas, M. Tsolaki, I. Kłoszewska, H. Soininen, S. Lovestone, A. Simmons, D. Aarsland, E. Westman, The reliability of a deep learning m...
-
[4]
E. A. AlBadawy, A. Saha, M. A. Mazurowski, Deep learn- ing for segmentation of brain tumors: Impact of cross- institutional training and testing, Medical physics 45 (2018) 1150–1158
2018
-
[5]
Nørgaard Llambias, M
S. Nørgaard Llambias, M. Nielsen, M. Mehdipour Ghazi, Data augmentation-based unsupervised domain adapta- tion in medical imaging, in: Scandinavian Conference on Image Analysis, Springer, 2025, pp. 177–186
2025
-
[6]
Smith-Bindman, D
R. Smith-Bindman, D. L. Miglioretti, E. Johnson, C. Lee, H. S. Feigelson, M. Flynn, R. T. Greenlee, R. L. Kruger, M. C. Hornbrook, D. Roblin, et al., Use of diagnos- tic imaging studies and associated radiation exposure for patients enrolled in large integrated health care systems, 1996-2010, Jama 307 (2012) 2400–2409
1996
-
[7]
Smith-Bindman, M
R. Smith-Bindman, M. L. Kwan, E. C. Marlow, M. K. Theis, W. Bolch, S. Y . Cheng, E. J. Bowles, J. R. Duncan, R. T. Greenlee, L. H. Kushi, et al., Trends in use of med- ical imaging in US health care systems and in Ontario, Canada, 2000-2016, Jama 322 (2019) 843–856. 13
2000
-
[8]
Devlin, M.-W
J. Devlin, M.-W. Chang, K. Lee, K. Toutanova, Bert: Pre- training of deep bidirectional transformers for language understanding, in: Proceedings of the 2019 conference of the North American chapter of the association for com- putational linguistics: human language technologies, vol- ume 1 (long and short papers), 2019, pp. 4171–4186
2019
-
[9]
T. Chen, S. Kornblith, M. Norouzi, G. Hinton, A simple framework for contrastive learning of visual representa- tions, in: International conference on machine learning, PmLR, 2020, pp. 1597–1607
2020
-
[10]
DINOv2: Learning Robust Visual Features without Supervision
M. Oquab, T. Darcet, T. Moutakanni, H. V o, M. Szafraniec, V . Khalidov, P. Fernandez, D. Haz- iza, F. Massa, A. El-Nouby, et al., DINOv2: Learning Robust Visual Features without Supervision, arXiv preprint arXiv:2304.07193 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[11]
Y . Shi, I. Daunhawer, J. E. V ogt, P. Torr, A. Sanyal, How robust is unsupervised representation learning to distri- bution shift?, in: The Eleventh International Confer- ence on Learning Representations, 2023. URL:https: //openreview.net/forum?id=LiXDW7CF94J
2023
-
[12]
K. He, X. Chen, S. Xie, Y . Li, P. Dollár, R. Girshick, Masked autoencoders are scalable vision learners, in: Pro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 16000–16009
2022
-
[13]
Brown, B
T. Brown, B. Mann, N. Ryder, M. Subbiah, J. D. Ka- plan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell, et al., Language models are few-shot learn- ers, Advances in neural information processing systems 33 (2020) 1877–1901
2020
-
[14]
Y . Liu, M. Ott, N. Goyal, J. Du, M. Joshi, D. Chen, O. Levy, M. Lewis, L. Zettlemoyer, V . Stoyanov, Roberta: A robustly optimized bert pretraining approach, arXiv preprint arXiv:1907.11692 (2019)
work page internal anchor Pith review Pith/arXiv arXiv 1907
-
[15]
Y . Tang, D. Yang, W. Li, H. R. Roth, B. Landman, D. Xu, V . Nath, A. Hatamizadeh, Self-supervised pre-training of swin transformers for 3d medical image analysis, in: Pro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 20730–20740
2022
-
[16]
Z. Chen, D. Agarwal, K. Aggarwal, W. Safta, M. M. Balan, K. Brown, Masked image modeling advances 3d medical image analysis, in: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, 2023, pp. 1970–1980
2023
-
[17]
L. Wu, J. Zhuang, H. Chen, V oco: A simple-yet-effective volume contrastive learning framework for 3d medical im- age analysis, in: Proceedings of the IEEE/CVF confer- ence on computer vision and pattern recognition, 2024, pp. 22873–22882
2024
-
[18]
T. Wald, C. Ulrich, S. Lukyanenko, A. Goncharov, A. Paderno, M. Miller, L. Maerkisch, P. Jaeger, K. Maier- Hein, Revisiting mae pre-training for 3d medical im- age segmentation, in: Proceedings of the Computer Vi- sion and Pattern Recognition Conference, 2025, pp. 5186– 5196
2025
-
[19]
A large-scale heterogeneous 3D magnetic resonance brain imaging dataset for self-supervised learning
S. Cerri, A. Munk, S. N. Llambias, J. Ambsdorf, J. Machnio, V . Nersesjan, C. Hedeager Krag, P. Liu, P. Rocamora García, M. Mehdipour Ghazi, M. Boesen, M. E. Benros, J. E. Iglesias, M. Nielsen, A large- scale heterogeneous 3D magnetic resonance brain imag- ing dataset for self-supervised learning, arXiv preprint arXiv:2506.14432 (2026). URL:https://arxiv....
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[20]
Ulrich, T
C. Ulrich, T. Wald, Y . Kirchhoff, M. Knopp, R. Peret- zke, M. Fischer, P. Ghosh, F. Isensee, A. Hilbert, P. Naser, L. Wessel, M. Foltyn-Dumitru, G. Brug- nara, J. B. Fiebach, J. O. Neumann, L. König, P. V ollmuth, K. Maier-Hein, SSL3D, 2025.https:// ssl3d-challenge.dkfz.de/home
2025
-
[21]
T. Wald, C. Ulrich, J. Suprijadi, S. Ziegler, M. Nohel, R. Peretzke, G. Kohler, K. Maier-Hein, An OpenMind for 3D medical vision self-supervised learning, in: Pro- ceedings of the IEEE/CVF International Conference on Computer Vision, 2025, pp. 23839–23879
2025
-
[22]
J. Ma, Y . Zhou, B. Wang, S. Kim, Z. Marinov, C. Xing, F. Li, Y . He, W. Li, F. Isensee, M. Rokuss, L. Krämer, K. Maier-Hein, Y . Du, B. Zhao, H. Wang, J. He, Y . Qiao, M. Zhang, H. Zhang, G.-Z. Yang, Y . Gu, L. Lumetti, F. Bolelli, C. Grana, Y . Chen, A. Erturk, T. Kuestner, S. Gatidis, M. Ingrisch, R. Graf, H. Möller, J. Kirschke, Z. Lin, T. Tan, H. Qu,...
2025
-
[23]
J. E. Iglesias, B. Billot, Y . Balbastre, C. Magdamo, S. E. Arnold, S. Das, B. L. Edlow, D. C. Alexander, P. Gol- land, B. Fischl, SynthSR: A public AI tool to turn het- erogeneous clinical brain scans into high-resolution T1- weighted images for 3D morphometry, Science advances 9 (2023) eadd3607
2023
-
[24]
Cerri, V
S. Cerri, V . Nersesjan, K. V . Klein, E. C. Cóppulo, S. N. Llambias, M. M. Ghazi, M. Nielsen, M. E. Benros, Cross- disorder comparison of brain structures among 4,836 indi- viduals with mental disorders and controls utilizing danish population-based clinical mri scans, Molecular Psychiatry (2026). 14
2026
-
[25]
A. Munk, J. Ambsdorf, S. Llambias, M. Nielsen, Amaes: Augmented masked autoencoder pretraining on public brain mri data for 3d-native segmentation, MICCAI Workshop on Advancing Data Solutions in Medical Imag- ing AI (ADSMI 2024), MICCAI 2024 (2024)
2024
- [26]
-
[27]
Maier-Hein, A
L. Maier-Hein, A. Reinke, P. Godau, M. D. Tizabi, F. Buettner, E. Christodoulou, B. Glocker, F. Isensee, J. Kleesiek, M. Kozubek, et al., Metrics reloaded: recom- mendations for image analysis validation, Nature methods 21 (2024) 195–212
2024
-
[28]
B. Phipson, G. K. Smyth, Permutation P-values should never be zero: calculating exact P-values when permutations are randomly drawn, Statistical appli- cations in genetics and molecular biology 9 (2010). URL:https://doi.org/10.2202/1544-6115.1585. doi:10.2202/1544-6115.1585
-
[29]
Maier-Hein, M
L. Maier-Hein, M. Eisenmann, A. Reinke, S. Onogur, M. Stankovic, P. Scholz, T. Arbel, H. Bogunovic, A. P. Bradley, A. Carass, et al., Why rankings of biomedical im- age analysis competitions should be interpreted with care, Nature communications 9 (2018) 5217
2018
-
[30]
O. Siméoni, H. V . V o, M. Seitzer, F. Baldassarre, M. Oquab, C. Jose, V . Khalidov, M. Szafraniec, S. Yi, M. Ramamonjisoa, et al., Dinov3, arXiv preprint arXiv:2508.10104 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
S. Woo, S. Debnath, R. Hu, X. Chen, Z. Liu, I. S. Kweon, S. Xie, Convnext v2: Co-designing and scaling con- vnets with masked autoencoders, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023, pp. 16133–16142
2023
-
[32]
Caron, H
M. Caron, H. Touvron, I. Misra, H. Jégou, J. Mairal, P. Bojanowski, A. Joulin, Emerging properties in self- supervised vision transformers, in: Proceedings of the IEEE/CVF international conference on computer vision, 2021, pp. 9650–9660
2021
-
[33]
J. Zhou, C. Wei, H. Wang, W. Shen, C. Xie, A. Yuille, T. Kong, ibot: Image bert pre-training with online tok- enizer, arXiv preprint arXiv:2111.07832 (2021)
work page internal anchor Pith review arXiv 2021
-
[34]
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, W. Chen, et al., LoRA: Low-Rank Adaptation of Large Language Models., Iclr 1 (2022) 3
2022
-
[35]
Billot, D
B. Billot, D. N. Greve, O. Puonti, A. Thielscher, K. Van Leemput, B. Fischl, A. V . Dalca, J. E. Iglesias, et al., SynthSeg: Segmentation of brain MRI scans of any contrast and resolution without retraining, Medical image analysis 86 (2023) 102789
2023
-
[36]
Fischl, FreeSurfer, Neuroimage 62 (2012) 774–781
B. Fischl, FreeSurfer, Neuroimage 62 (2012) 774–781
2012
-
[37]
LaBella, O
D. LaBella, O. Khanna, S. McBurney-Lin, R. Mclean, P. Nedelec, A. S. Rashid, N. H. Tahon, T. Altes, U. Baid, R. Bhalerao, et al., A multi-institutional meningioma MRI dataset for automated multi-sequence image segmenta- tion, Scientific data 11 (2024) 496
2024
-
[38]
D. P. Kingma, M. Welling, Auto-Encoding Variational Bayes, arXiv preprint arXiv:1312.6114 (2013)
work page internal anchor Pith review Pith/arXiv arXiv 2013
- [39]
-
[40]
Decoupled Weight Decay Regularization
I. Loshchilov, F. Hutter, Decoupled Weight Decay Regu- larization, arXiv preprint arXiv:1711.05101 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[41]
M. Beck, K. Pöppel, M. Spanring, A. Auer, O. Prud- nikova, M. Kopp, G. Klambauer, J. Brandstetter, S. Hochreiter, xLSTM: Extended Long Short-Term Mem- ory, Advances in Neural Information Processing Systems 37 (2024) 107547–107603
2024
-
[42]
D. P. Kingma, J. Ba, Adam: A Method for Stochastic Optimization, arXiv preprint arXiv:1412.6980 (2014)
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[43]
Hatamizadeh, V
A. Hatamizadeh, V . Nath, Y . Tang, D. Yang, H. R. Roth, D. Xu, Swin UNETR: Swin Transformers for Semantic Segmentation of Brain Tumors in MRI Images, in: Inter- national MICCAI brainlesion workshop, Springer, 2021, pp. 272–284
2021
-
[44]
X. Chen, H. Fan, R. Girshick, K. He, Improved base- lines with momentum contrastive learning, arXiv preprint arXiv:2003.04297 (2020)
work page internal anchor Pith review arXiv 2003
-
[45]
Y . He, V . Nath, D. Yang, Y . Tang, A. Myronenko, D. Xu, Swinunetr-v2: Stronger swin transformers with stagewise convolutions for 3d medical image segmentation, in: In- ternational Conference on Medical Image Computing and Computer-Assisted Intervention, Springer, 2023, pp. 416– 426
2023
-
[46]
Z. Xie, Z. Zhang, Y . Cao, Y . Lin, J. Bao, Z. Yao, Q. Dai, H. Hu, SimMIM: A Simple Framework for Masked Im- age Modeling, in: Proceedings of the IEEE/CVF confer- ence on computer vision and pattern recognition, 2022, pp. 9653–9663
2022
- [47]
-
[48]
La Rosa, J
F. La Rosa, J. Dos Santos Silva, E. Dereskewicz, A. In- vernizzi, N. Cahan, J. Galasso, N. Garcia, R. Graney, S. Levy, G. Verma, et al., BrainAgeNeXt: advancing 15 brain age modeling for individuals with multiple sclero- sis, Imaging Neuroscience 3 (2025) imag_a_00487
2025
-
[49]
S. Roy, G. Koehler, C. Ulrich, M. Baumgartner, J. Pe- tersen, F. Isensee, P. F. Jaeger, K. H. Maier-Hein, Med- next: transformer-driven scaling of convnets for medical image segmentation, in: International conference on med- ical image computing and computer-assisted intervention, Springer, 2023, pp. 405–415
2023
-
[50]
Z. Huang, H. Wang, Z. Deng, J. Ye, Y . Su, H. Sun, J. He, Y . Gu, L. Gu, S. Zhang, Y . Qiao, STU-Net: Scalable and Transferable Medical Image Segmentation Models Em- powered by Large-Scale Supervised Pre-training, arXiv preprint arXiv:2304.06716 (2023)
-
[51]
Wasserthal, H.-C
J. Wasserthal, H.-C. Breit, M. T. Meyer, M. Pradella, D. Hinck, A. W. Sauter, T. Heye, D. T. Boll, J. Cyriac, S. Yang, et al., TotalSegmentator: robust segmentation of 104 anatomic structures in CT images, Radiology: Artifi- cial Intelligence 5 (2023) e230024
2023
-
[52]
C. Dancette, J. Khlaut, A. Saporta, H. Philippe, E. Fer- reres, B. Callard, T. Danielou, L. Alberge, L. Machado, D. Tordjman, et al., Curia: A multi-modal foundation model for radiology, arXiv preprint arXiv:2509.06830 (2025)
-
[53]
K. Li, Y . Wang, J. Zhang, P. Gao, G. Song, Y . Liu, H. Li, Y . Qiao, Uniformer: Unifying convolution and self-attention for visual recognition, IEEE Transactions on Pattern Analysis and Machine Intelligence 45 (2023) 12581–12600
2023
-
[54]
S. Rui, L. Chen, Z. Tang, L. Wang, M. Liu, S. Zhang, X. Wang, Multi-modal vision pre-training for medical im- age analysis, in: Proceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 5164–5174. Appendix A. Dataset Details This appendix details subject demographics, MRI sequences, preprocessing, and labeling protocols for all FOMO...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.