Recognition: 2 theorem links
· Lean TheoremBeyond Instance-Level Self-Supervision in 3D Multi-Modal Medical Imaging
Pith reviewed 2026-05-15 05:24 UTC · model grok-4.3
The pith
Leveraging cross-instance anatomical topology consistency as a supervisory signal improves self-supervised representations in 3D multi-modal medical imaging.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that treating cross-instance topological consistency as a supervisory signal, via a cross-modal triplet objective for intra-instance alignment and pseudo-correspondences for inter-instance partial alignment, produces representations that outperform instance-level self-supervision in multi-modal 3D medical imaging tasks.
What carries the argument
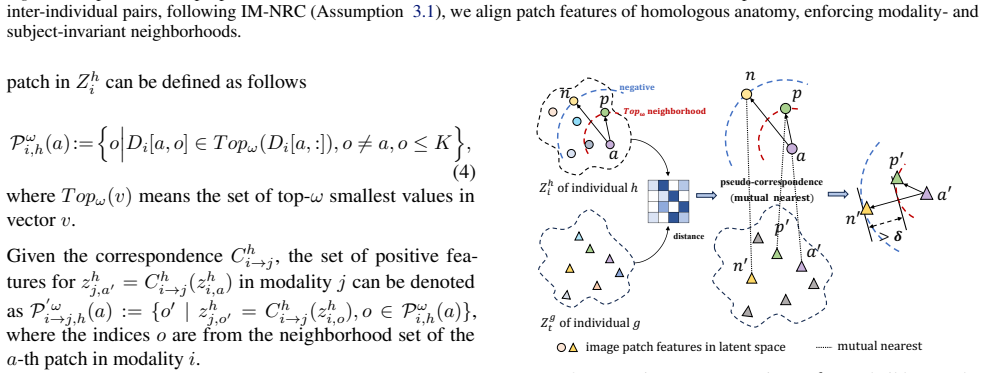
Cross-instance topological consistency enforced through intra-instance cross-modal triplet loss and inter-instance pseudo-correspondence alignment to preserve local neighborhood topology across modalities.
If this is right
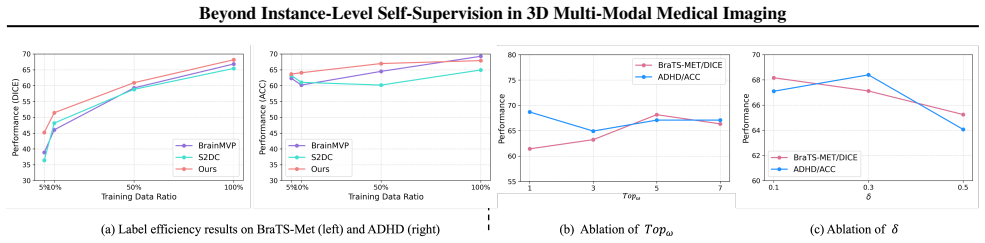
- Downstream segmentation tasks see an average 1.1% improvement.
- Classification tasks improve by an average 5.94%.
- Models become significantly more robust to missing modalities at test time.
- The approach works across seven different multi-modal downstream tasks.
Where Pith is reading between the lines
- Similar topology-based signals could apply to non-medical 3D imaging domains where objects have consistent relative positions.
- Handling pathology-induced topology changes might require adaptive weighting of the consistency signal.
- Combining this with other self-supervision objectives like contrastive learning could yield further gains.
- The pseudo-correspondence method might generalize to other unpaired multi-modal settings.
Load-bearing premise
Anatomical structures maintain consistent spatial relationships across different individuals even with variations in size, shape, or pathology.
What would settle it
A dataset where pathology causes major disruptions in anatomical topology across instances, leading to degraded performance compared to standard methods.
Figures





read the original abstract
Self-supervised pre-training methods in medical imaging typically treat each individual as an isolated instance, learning representations through augmentation-based objectives or masked reconstruction. They often do not adequately capitalize on a key characteristic of physiological features: anatomical structures maintain consistent spatial relationships across individuals (instances), such as the thalamus being medial to the basal ganglia, regardless of variations in brain size, shape, or pathology. We propose leveraging this cross-instance topological consistency as a supervisory signal. The challenge arises from the inherent variability in medical imaging, which can differ significantly across instances and modalities. To tackle this, we focus on two alignment regimes. (i) Intra-instance: with pixel-level correspondences available, a cross-modal triplet objective explicitly preserves local neighborhood topology. (ii) Inter-instance: without such supervision, we derive pseudo-correspondences to control partial neighborhood alignment and prevent topology collapse across modalities. We validate our approach across 7 downstream multi-modal tasks, achieving average improvements of 1.1% and 5.94% in segmentation and classification tasks, respectively, and demonstrating significantly better robustness when modalities are missing at test time.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a self-supervised pre-training method for 3D multi-modal medical imaging that extends beyond per-instance augmentation by exploiting cross-instance topological consistency of anatomical structures (e.g., thalamus medial to basal ganglia). It introduces an intra-instance cross-modal triplet objective that preserves local neighborhoods where pixel correspondences exist and an inter-instance partial neighborhood alignment objective that uses derived pseudo-correspondences to prevent collapse across modalities. The approach is validated on seven downstream multi-modal tasks, reporting average gains of 1.1% in segmentation and 5.94% in classification together with improved robustness when modalities are absent at test time.
Significance. If the gains and robustness improvements prove reliable, the work would offer a concrete way to inject anatomical priors across patients into self-supervised pre-training, which is especially useful in clinical multi-modal settings where one modality is frequently missing. The modest numerical improvements and the absence of error bars or ablations on the pseudo-correspondence mechanism limit the strength of the current evidence, but the core idea of topology-aware inter-instance alignment is a plausible direction for the field.
major comments (4)
- [Abstract and §4] Abstract and experimental section: the reported average improvements (1.1% segmentation, 5.94% classification) are presented without error bars, standard deviations across runs, or statistical significance tests, so it is impossible to determine whether the gains exceed experimental variance.
- [§3.2] §3.2: the construction of pseudo-correspondences for the inter-instance regime is not ablated; it remains unclear how these correspondences are obtained from topological consistency, whether they are independent of the training distribution, and how they behave when pathology (mass effect, edema) violates the assumed spatial relationships.
- [§3.3] §3.3: the partial neighborhood alignment objective lacks explicit description of the mechanisms (margin values, weighting schedule, or collapse-prevention regularizers) that are claimed to avoid topology collapse across modalities, especially when one modality is missing.
- [Discussion] Discussion: the central modeling assumption that anatomical spatial relationships remain sufficiently consistent 'regardless of ... pathology' is stated but not empirically tested; a sensitivity study on deformed cases would be required to support the robustness claims at test time.
minor comments (2)
- [§3] Notation for the inter-instance loss and the definition of pseudo-correspondences should be made fully explicit, including the precise form of the neighborhood alignment term.
- [§4] The seven downstream tasks and the exact multi-modal datasets should be listed with references and split statistics for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment point by point below and indicate where revisions will be made.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and experimental section: the reported average improvements (1.1% segmentation, 5.94% classification) are presented without error bars, standard deviations across runs, or statistical significance tests, so it is impossible to determine whether the gains exceed experimental variance.
Authors: We agree that reporting error bars and statistical tests would strengthen the results. In the revised manuscript we will include standard deviations computed over multiple independent runs and add paired statistical significance tests for the reported average gains. revision: yes
-
Referee: [§3.2] §3.2: the construction of pseudo-correspondences for the inter-instance regime is not ablated; it remains unclear how these correspondences are obtained from topological consistency, whether they are independent of the training distribution, and how they behave when pathology (mass effect, edema) violates the assumed spatial relationships.
Authors: Pseudo-correspondences are obtained by matching anatomical landmarks according to fixed topological priors (e.g., relative medial-lateral positions) that are independent of any single training distribution. We will add an explicit description of this procedure in §3.2 together with an ablation that removes the inter-instance term. Regarding pathology, our current training sets contain moderate deformations; we will expand the discussion to note that extreme mass-effect cases may violate the priors and flag this as a limitation. revision: partial
-
Referee: [§3.3] §3.3: the partial neighborhood alignment objective lacks explicit description of the mechanisms (margin values, weighting schedule, or collapse-prevention regularizers) that are claimed to avoid topology collapse across modalities, especially when one modality is missing.
Authors: We will revise §3.3 to state the exact margin (0.5), the linear weighting schedule from 0 to 1 over the first 50 epochs, and the modality-dropout regularizer that randomly masks one modality during training to prevent collapse. revision: yes
-
Referee: [Discussion] Discussion: the central modeling assumption that anatomical spatial relationships remain sufficiently consistent 'regardless of ... pathology' is stated but not empirically tested; a sensitivity study on deformed cases would be required to support the robustness claims at test time.
Authors: We acknowledge that a dedicated sensitivity study on severely deformed pathological cases is absent. We will expand the discussion to explicitly list this modeling assumption as a limitation and identify a sensitivity analysis on mass-effect and edema cases as important future work, while noting that the missing-modality robustness experiments provide indirect evidence. revision: partial
- Full empirical sensitivity study on cases with large pathological deformations (mass effect, edema) because suitable additional annotated datasets are not available within the current experimental scope.
Circularity Check
No significant circularity; derivation rests on external anatomical prior
full rationale
The paper's chain begins from the stated external premise that anatomical structures maintain consistent spatial relationships across individuals (e.g., thalamus medial to basal ganglia) regardless of size, shape, or pathology. This premise is used to motivate two alignment regimes: an intra-instance cross-modal triplet objective that preserves local neighborhood topology using available pixel-level correspondences, and an inter-instance regime that derives pseudo-correspondences to enforce partial neighborhood alignment. Neither regime is shown, in the provided text, to define its supervisory signal or pseudo-correspondences by construction from the model's own fitted outputs or from a self-referential loop. Downstream validation across seven tasks supplies an independent empirical check. No load-bearing step reduces to renaming a fitted quantity as a prediction or to a self-citation chain that is itself unverified.
Axiom & Free-Parameter Ledger
free parameters (1)
- alignment weights and margins in triplet and neighborhood losses
axioms (1)
- domain assumption Anatomical structures maintain consistent spatial relationships across individuals regardless of size, shape, or pathology
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
anatomical structures maintain consistent spatial relationships across individuals (instances), such as the thalamus being medial to the basal ganglia, regardless of variations in brain size, shape, or pathology
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Instance-agnostic Cross-Modal Neighborhood Ranking Consistency (IM-NRC) ... triplet loss ... partial neighborhood alignment
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
FirstName LastName , title =
-
[2]
FirstName Alpher , title =
-
[3]
Journal of Foo , volume = 13, number = 1, pages =
FirstName Alpher and FirstName Fotheringham-Smythe , title =. Journal of Foo , volume = 13, number = 1, pages =
-
[4]
Journal of Foo , volume = 14, number = 1, pages =
FirstName Alpher and FirstName Fotheringham-Smythe and FirstName Gamow , title =. Journal of Foo , volume = 14, number = 1, pages =
-
[5]
FirstName Alpher and FirstName Gamow , title =
-
[6]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Momentum contrast for unsupervised visual representation learning , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[7]
Advances in neural information processing systems , volume=
Bootstrap your own latent-a new approach to self-supervised learning , author=. Advances in neural information processing systems , volume=
-
[8]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Masked autoencoders are scalable vision learners , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[9]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Anatomical invariance modeling and semantic alignment for self-supervised learning in 3d medical image analysis , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[10]
arXiv preprint arXiv:2507.02581 , year=
Structure-aware Semantic Discrepancy and Consistency for 3D Medical Image Self-supervised Learning , author=. arXiv preprint arXiv:2507.02581 , year=
-
[11]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Towards a Universal 3D Medical Multi-modality Generalization via Learning Personalized Invariant Representation , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[12]
Nature Reviews Neuroscience , volume=
A roadmap towards standardized neuroimaging approaches for human thalamic nuclei , author=. Nature Reviews Neuroscience , volume=. 2024 , publisher=
work page 2024
-
[13]
arXiv preprint arXiv:2212.06079 , year=
Robust perception through equivariance , author=. arXiv preprint arXiv:2212.06079 , year=
-
[14]
Forty-second International Conference on Machine Learning , year=
Aligning Multimodal Representations through an Information Bottleneck , author=. Forty-second International Conference on Machine Learning , year=
-
[15]
arXiv preprint arXiv:2205.15236 , year=
Ranksim: Ranking similarity regularization for deep imbalanced regression , author=. arXiv preprint arXiv:2205.15236 , year=
-
[16]
Joint European Conference on Machine Learning and Knowledge Discovery in Databases , pages=
Spectral Distribution Alignment for Enhanced Generalization in Regression , author=. Joint European Conference on Machine Learning and Knowledge Discovery in Databases , pages=. 2025 , organization=
work page 2025
-
[17]
The brain tumor segmentation (brats) challenge 2023: Focus on pediatrics (cbtn-connect-dipgr-asnr-miccai brats-peds) , author=. ArXiv , pages=
work page 2023
-
[18]
ISLES 2022: A multi-center magnetic resonance imaging stroke lesion segmentation dataset , author=. Scientific data , volume=. 2022 , publisher=
work page 2022
-
[19]
The brain tumor segmentation-metastases (brats-mets) challenge 2023: Brain metastasis segmentation on pre-treatment mri , author=. ArXiv , pages=
work page 2023
-
[20]
The Alzheimer's disease neuroimaging initiative (ADNI): MRI methods , author=. Journal of Magnetic Resonance Imaging: An Official Journal of the International Society for Magnetic Resonance in Medicine , volume=. 2008 , publisher=
work page 2008
-
[21]
Frontiers in systems neuroscience , volume=
The ADHD-200 consortium: a model to advance the translational potential of neuroimaging in clinical neuroscience , author=. Frontiers in systems neuroscience , volume=. 2012 , publisher=
work page 2012
-
[22]
Identifying the best machine learning algorithms for brain tumor segmentation, progression assessment, and overall survival prediction in the BRATS challenge , author=. arXiv preprint arXiv:1811.02629 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
Decoupled Weight Decay Regularization
Decoupled weight decay regularization , author=. arXiv preprint arXiv:1711.05101 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Multi-modal Vision Pre-training for Medical Image Analysis , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[25]
International conference on medical image computing and computer-assisted intervention , pages=
Swinmm: masked multi-view with swin transformers for 3d medical image segmentation , author=. International conference on medical image computing and computer-assisted intervention , pages=. 2023 , organization=
work page 2023
-
[26]
Dinov3 , author=. arXiv preprint arXiv:2508.10104 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
Advances in Neural Information Processing Systems , volume=
Mind the gap: Understanding the modality gap in multi-modal contrastive representation learning , author=. Advances in Neural Information Processing Systems , volume=
-
[28]
IEEE transactions on medical imaging , volume=
The multimodal brain tumor image segmentation benchmark (BRATS) , author=. IEEE transactions on medical imaging , volume=. 2014 , publisher=
work page 2014
-
[29]
Radiology: Artificial Intelligence , volume=
TotalSegmentator: robust segmentation of 104 anatomic structures in CT images , author=. Radiology: Artificial Intelligence , volume=. 2023 , publisher=
work page 2023
-
[30]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Preservational learning improves self-supervised medical image models by reconstructing diverse contexts , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[31]
arXiv preprint arXiv:2404.15580 , year=
MiM: Mask in Mask Self-Supervised Pre-Training for 3D Medical Image Analysis , author=. arXiv preprint arXiv:2404.15580 , year=
-
[32]
Novel coronavirus and common pneumonia detection from CT scans using deep learning-based extracted features , author=. Viruses , volume=. 2022 , publisher=
work page 2022
-
[33]
International MICCAI brainlesion workshop , pages=
Swin unetr: Swin transformers for semantic segmentation of brain tumors in mri images , author=. International MICCAI brainlesion workshop , pages=. 2021 , organization=
work page 2021
-
[34]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Voco: A simple-yet-effective volume contrastive learning framework for 3d medical image analysis , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[35]
An intuitive proof of the data processing inequality
An intuitive proof of the data processing inequality , author=. arXiv preprint arXiv:1107.0740 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[36]
European journal of nuclear medicine and molecular imaging , pages=
A cross-scanner and cross-tracer deep learning method for the recovery of standard-dose imaging quality from low-dose PET , author=. European journal of nuclear medicine and molecular imaging , pages=. 2022 , publisher=
work page 2022
-
[37]
arXiv preprint arXiv:2403.11391 , year=
Investigating the Benefits of Projection Head for Representation Learning , author=. arXiv preprint arXiv:2403.11391 , year=
-
[38]
The Journal of business , volume=
Mutual fund performance , author=. The Journal of business , volume=. 1966 , publisher=
work page 1966
-
[39]
International Conference on Machine Learning , pages=
Robust Perception through Equivariance , author=. International Conference on Machine Learning , pages=. 2023 , organization=
work page 2023
-
[40]
Communications of the ACM , volume=
Generative adversarial networks , author=. Communications of the ACM , volume=. 2020 , publisher=
work page 2020
-
[41]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Truly shift-invariant convolutional neural networks , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[42]
OASIS-3: longitudinal neuroimaging, clinical, and cognitive dataset for normal aging and Alzheimer disease , author=. medrxiv , pages=. 2019 , publisher=
work page 2019
-
[43]
IEEE Transactions on Radiation and Plasma Medical Sciences , year=
A Total-Body Ultra-Low Dose PET Reconstruction Method via Image Space Shuffle U-Net and Body Sampling , author=. IEEE Transactions on Radiation and Plasma Medical Sciences , year=
-
[44]
A large annotated medical image dataset for the development and evaluation of segmentation algorithms , author=. arXiv preprint arXiv:1902.09063 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1902
-
[45]
Miccai multi-atlas labeling beyond the cranial vault--workshop and challenge , author=. Proc. MICCAI Multi-Atlas Labeling Beyond Cranial Vault—Workshop Challenge , volume=
-
[46]
The autopet challenge: towards fully automated lesion segmentation in oncologic pet/ct imaging , author=
-
[47]
Medical Image Analysis , volume=
Dive into the details of self-supervised learning for medical image analysis , author=. Medical Image Analysis , volume=. 2023 , publisher=
work page 2023
-
[48]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
An image is worth 16x16 words: Transformers for image recognition at scale , author=. arXiv preprint arXiv:2010.11929 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[49]
IEEE Transactions on Medical Imaging , year=
Prior Knowledge-guided Triple-Domain Transformer-GAN for Direct PET Reconstruction from Low-Count Sinograms , author=. IEEE Transactions on Medical Imaging , year=
-
[50]
arXiv preprint arXiv:2301.00772 , year=
Pcrlv2: A unified visual information preservation framework for self-supervised pre-training in medical image analysis , author=. arXiv preprint arXiv:2301.00772 , year=
-
[51]
Revisiting Rubik’s cube: Self-supervised learning with volume-wise transformation for 3D medical image segmentation , author=. Medical Image Computing and Computer Assisted Intervention--MICCAI 2020: 23rd International Conference, Lima, Peru, October 4--8, 2020, Proceedings, Part IV 23 , pages=. 2020 , organization=
work page 2020
-
[52]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Geometric visual similarity learning in 3d medical image self-supervised pre-training , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[53]
arXiv preprint arXiv:2306.08913 , year=
Advancing volumetric medical image segmentation via global-local masked autoencoder , author=. arXiv preprint arXiv:2306.08913 , year=
-
[54]
Clinically applicable AI system for accurate diagnosis, quantitative measurements, and prognosis of COVID-19 pneumonia using computed tomography , author=. Cell , volume=. 2020 , publisher=
work page 2020
-
[55]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Squid: Deep feature in-painting for unsupervised anomaly detection , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[56]
Medical Image Analysis , volume=
A geometric approach to robust medical image segmentation , author=. Medical Image Analysis , volume=. 2024 , publisher=
work page 2024
-
[57]
Advances in Neural Information Processing Systems , volume=
Keypoint-augmented self-supervised learning for medical image segmentation with limited annotation , author=. Advances in Neural Information Processing Systems , volume=
-
[58]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Self-supervised learning of object parts for semantic segmentation , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[59]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Groupcontrast: Semantic-aware self-supervised representation learning for 3d understanding , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[60]
International Conference on Medical Image Computing and Computer-Assisted Intervention , pages=
Swinunetr-v2: Stronger swin transformers with stagewise convolutions for 3d medical image segmentation , author=. International Conference on Medical Image Computing and Computer-Assisted Intervention , pages=. 2023 , organization=
work page 2023
-
[61]
Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision , pages=
Masked image modeling advances 3d medical image analysis , author=. Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision , pages=
-
[62]
International conference on machine learning , pages=
A simple framework for contrastive learning of visual representations , author=. International conference on machine learning , pages=. 2020 , organization=
work page 2020
-
[63]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Jigsaw clustering for unsupervised visual representation learning , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[64]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Positional label for self-supervised vision transformer , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[65]
Medical image analysis , volume=
Models genesis , author=. Medical image analysis , volume=. 2021 , publisher=
work page 2021
-
[66]
Advances in neural information processing systems , volume=
3d self-supervised methods for medical imaging , author=. Advances in neural information processing systems , volume=
-
[67]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Simmim: A simple framework for masked image modeling , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[68]
Advances in Neural Information Processing Systems , volume=
Vicregl: Self-supervised learning of local visual features , author=. Advances in Neural Information Processing Systems , volume=
-
[69]
Representation Learning with Contrastive Predictive Coding
Representation learning with contrastive predictive coding , author=. arXiv preprint arXiv:1807.03748 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[70]
arXiv preprint arXiv:2306.04654 , year=
DenseDINO: boosting dense self-supervised learning with token-based point-level consistency , author=. arXiv preprint arXiv:2306.04654 , year=
-
[71]
arXiv preprint arXiv:2203.13868 , year=
Self-supervised semantic segmentation grounded in visual concepts , author=. arXiv preprint arXiv:2203.13868 , year=
-
[72]
arXiv preprint arXiv:2407.20395 , year=
Dense Self-Supervised Learning for Medical Image Segmentation , author=. arXiv preprint arXiv:2407.20395 , year=
-
[73]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Dense contrastive learning for self-supervised visual pre-training , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[74]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Segment anything , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[75]
arXiv preprint arXiv:2405.19492 , year=
TotalSegmentator MRI: Sequence-Independent Segmentation of 59 Anatomical Structures in MR images , author=. arXiv preprint arXiv:2405.19492 , year=
-
[76]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Superglue: Learning feature matching with graph neural networks , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[77]
The annals of mathematical statistics , volume=
A relationship between arbitrary positive matrices and doubly stochastic matrices , author=. The annals of mathematical statistics , volume=. 1964 , publisher=
work page 1964
-
[78]
Advances in neural information processing systems , volume=
Neighbourhood consensus networks , author=. Advances in neural information processing systems , volume=
-
[79]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
LoFTR: Detector-free local feature matching with transformers , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[80]
Neuroimaging Clinics of North America , volume=
The Alzheimer’s disease neuroimaging initiative , author=. Neuroimaging Clinics of North America , volume=. 2005 , publisher=
work page 2005
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.