Recognition: unknown
Retrieval Is Not Enough: Why Organizational AI Needs Epistemic Infrastructure
Pith reviewed 2026-05-10 14:54 UTC · model grok-4.3
The pith
Organizational AI is limited by missing epistemic structure in knowledge rather than by retrieval quality alone.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
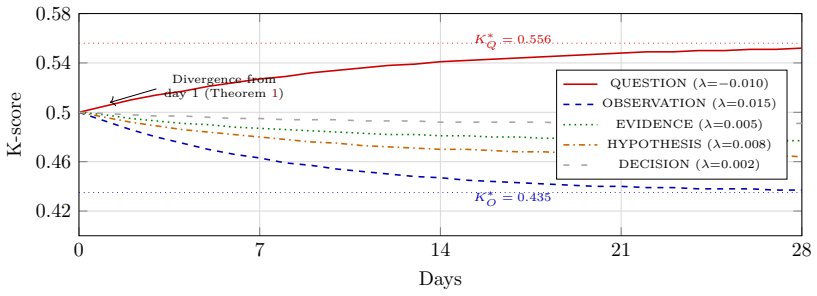
The ceiling on organizational AI is not retrieval fidelity but epistemic fidelity—the system's ability to represent commitment strength, contradiction status, and organizational ignorance as computable properties. OIDA structures knowledge as typed Knowledge Objects that carry an epistemic class, class-specific importance scores with decay, and signed contradiction edges. The Knowledge Gravity Engine updates these scores deterministically and converges under a proved sufficient condition of maximum degree less than 7. It introduces QUESTION objects whose importance grows inversely to model ignorance with increasing urgency. An Epistemic Quality Score evaluates outputs across five components,
What carries the argument
The OIDA framework's Knowledge Objects and Knowledge Gravity Engine, which maintain epistemic classes, importance scores, signed contradictions, and inverse-decay QUESTION objects to represent organizational ignorance as a first-class, computable property.
If this is right
- Knowledge objects carry explicit commitment levels so AI agents can weight binding decisions more heavily than abandoned hypotheses.
- Signed contradiction edges make conflicting claims detectable and resolvable rather than hidden inside retrieved passages.
- QUESTION objects with inverse decay surface organizational ignorance with rising urgency, directing attention to unresolved gaps.
- The Epistemic Quality Score supplies a five-component metric that includes explicit checks for circular reasoning in AI outputs.
- Convergence guarantees under bounded graph degree support deterministic maintenance of the epistemic layer at scale.
Where Pith is reading between the lines
- AI agents built on this structure could refuse or flag answers when ignorance scores exceed a threshold instead of hallucinating from incomplete context.
- Adoption would require organizations to annotate decisions with epistemic metadata at the point of creation rather than retrofitting later.
- The same primitives could extend to non-organizational settings where knowledge evolves through commitments and disputes, such as scientific literature tracking.
- Equal-budget comparisons could clarify whether metadata maintenance overhead is offset by reduced need for large context windows.
Load-bearing premise
The epistemic metadata and Knowledge Gravity Engine can be maintained at acceptable cost inside real organizations while preserving claimed quality gains when compared at equal token or compute budgets.
What would settle it
A completed ablation experiment that runs the OIDA RAG condition against a matched-token standard RAG baseline on the same queries and measures the resulting Epistemic Quality Scores.
Figures

read the original abstract
Organizational knowledge used by AI agents typically lacks epistemic structure: retrieval systems surface semantically relevant content without distinguishing binding decisions from abandoned hypotheses, contested claims from settled ones, or known facts from unresolved questions. We argue that the ceiling on organizational AI is not retrieval fidelity but \emph{epistemic} fidelity--the system's ability to represent commitment strength, contradiction status, and organizational ignorance as computable properties. We present OIDA, a framework that structures organizational knowledge as typed Knowledge Objects carrying epistemic class, importance scores with class-specific decay, and signed contradiction edges. The Knowledge Gravity Engine maintains scores deterministically with proved convergence guarantees (sufficient condition: max degree $< 7$; empirically robust to degree 43). OIDA introduces QUESTION-as-modeled-ignorance: a primitive with inverse decay that surfaces what an organization does \emph{not} know with increasing urgency--a mechanism absent from all surveyed systems. We describe the Epistemic Quality Score (EQS), a five-component evaluation methodology with explicit circularity analysis. In a controlled comparison ($n{=}10$ response pairs), OIDA's RAG condition (3,868 tokens) achieves EQS 0.530 vs.\ 0.848 for a full-context baseline (108,687 tokens); the $28.1\times$ token budget difference is the primary confound. The QUESTION mechanism is statistically validated (Fisher $p{=}0.0325$, OR$=21.0$). The formal properties are established; the decisive ablation at equal token budget (E4) is pre-registered and not yet run.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript argues that the primary limitation on organizational AI performance is the lack of epistemic structure in knowledge representations, rather than retrieval fidelity. It proposes the OIDA framework, which models organizational knowledge as typed Knowledge Objects with epistemic classes, importance scores subject to class-specific decay, signed contradiction edges, and a QUESTION primitive for representing modeled ignorance with inverse decay. A Knowledge Gravity Engine is introduced to maintain these scores deterministically, with a convergence proof under the condition that the maximum degree is less than 7 (empirically robust to 43). The Epistemic Quality Score (EQS) is presented as a five-component evaluation method with circularity analysis. A controlled comparison with n=10 response pairs shows OIDA-RAG achieving an EQS of 0.530 compared to 0.848 for a full-context baseline, though with a 28.1x difference in token budget flagged as a confound. The QUESTION mechanism is validated statistically (Fisher's p=0.0325, OR=21.0), and a decisive equal-token-budget ablation (E4) is pre-registered but not executed.
Significance. If the central claims hold, particularly that epistemic metadata and the Knowledge Gravity Engine can deliver quality gains without the token overhead of full-context approaches, this could represent a significant shift in how AI systems handle organizational knowledge, moving from semantic retrieval to structured epistemic modeling. The work provides formal guarantees via the convergence proof and independent validation of the QUESTION primitive, which are notable strengths. However, the empirical demonstration of net benefits at equal computational cost remains pending.
major comments (2)
- Abstract: The reported n=10 comparison between OIDA-RAG (EQS 0.530, 3,868 tokens) and full-context baseline (EQS 0.848, 108,687 tokens) is confounded by the 28.1x token-budget difference, which the authors identify as the primary confound. The pre-registered E4 ablation that equalizes token budgets to isolate the effect of epistemic structure has not been executed, leaving the evidence for EQS gains from OIDA untested against this acknowledged issue.
- Evaluation methodology: The paper claims to include explicit circularity analysis within the five-component EQS, but the full definition of EQS and its components is not provided in sufficient detail to allow verification of whether any score element reduces to a fitted parameter by construction.
minor comments (1)
- The manuscript would benefit from clearer notation for the free parameters such as the max degree threshold and class-specific decay rates in the Knowledge Gravity Engine.
Simulated Author's Rebuttal
We thank the referee for their constructive and precise comments, which help clarify the evidential boundaries of our work. We respond to each major comment below.
read point-by-point responses
-
Referee: Abstract: The reported n=10 comparison between OIDA-RAG (EQS 0.530, 3,868 tokens) and full-context baseline (EQS 0.848, 108,687 tokens) is confounded by the 28.1x token-budget difference, which the authors identify as the primary confound. The pre-registered E4 ablation that equalizes token budgets to isolate the effect of epistemic structure has not been executed, leaving the evidence for EQS gains from OIDA untested against this acknowledged issue.
Authors: We agree that the 28.1x token-budget difference is a primary confound that prevents strong causal claims about epistemic structure alone. As stated in the manuscript, the E4 ablation was pre-registered specifically to equalize budgets and isolate this factor, but it has not yet been executed. In the revision we will update the abstract and evaluation section to foreground this limitation more explicitly, present the current n=10 results strictly as feasibility evidence, and note the pending E4 as the required next step. The independent statistical validation of the QUESTION primitive (Fisher p=0.0325, OR=21.0) remains unaffected by the token confound. revision: partial
-
Referee: Evaluation methodology: The paper claims to include explicit circularity analysis within the five-component EQS, but the full definition of EQS and its components is not provided in sufficient detail to allow verification of whether any score element reduces to a fitted parameter by construction.
Authors: The referee is correct that the current manuscript supplies only an overview of the five EQS components and states that circularity analysis was performed, without the complete formal definitions needed for verification. We will revise by adding a dedicated subsection (or appendix) containing the exact mathematical definitions of all five components, the procedure used for the circularity analysis, and explicit checks confirming that no component is circular by construction or dependent on parameters fitted from the same evaluation data. Each component is defined from independent epistemic properties (class-specific decay, signed edges, inverse-decay urgency) prior to aggregation. revision: yes
Circularity Check
No significant circularity; formal proofs and explicit EQS analysis keep derivation self-contained
full rationale
The paper supplies a deterministic convergence proof for the Knowledge Gravity Engine under an explicit sufficient condition (max degree <7, robust to 43) and independent statistical validation for the QUESTION mechanism (Fisher p=0.0325). It explicitly states that EQS incorporates circularity analysis. No quoted equation or step reduces a claimed result to a fitted parameter, self-citation chain, or input by construction; the framework's properties are presented as independently verifiable rather than tautological.
Axiom & Free-Parameter Ledger
free parameters (2)
- max degree threshold
- class-specific decay rates
axioms (1)
- standard math Graph convergence under bounded degree
invented entities (3)
-
Knowledge Object
no independent evidence
-
QUESTION primitive
no independent evidence
-
Knowledge Gravity Engine
no independent evidence
Reference graph
Works this paper leans on
-
[1]
PoggioAI/MSc: ML theory research with humans on the loop
MahmoudAbdelmoneum, PierfrancescoBeneventano, andTomasoPoggio. PoggioAI/MSc: ML theory research with humans on the loop. Technical Report Technical Report v0, MIT, 2026
2026
-
[2]
Anderson, Daniel Bothell, Michael D
John R. Anderson, Daniel Bothell, Michael D. Byrne, et al. An integrated theory of the mind.Psychological Review, 111(4):1036–1060, 2004. 12
2004
-
[3]
Anderson and Lael J
John R. Anderson and Lael J. Schooler. Reflections of the environment in memory.Psy- chological Science, 2(6):396–408, 1991
1991
-
[4]
The semantic web.Scientific American, 284(5):34–43, 2001
Tim Berners-Lee, James Hendler, and Ora Lassila. The semantic web.Scientific American, 284(5):34–43, 2001
2001
-
[5]
Bingnan Cai, Yongqiang Xiang, et al. A survey on temporal knowledge graph: Represen- tation learning and applications.arXiv preprint arXiv:2403.04782, 2024
-
[6]
Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory
Prateek Chhikara, Deshraj Khant, et al. Mem0: Building production-ready AI agents with scalable long-term memory.arXiv preprint arXiv:2504.19413, 2025
work page internal anchor Pith review arXiv 2025
-
[7]
Early impacts of M365 Copilot.arXiv preprint arXiv:2504.11443, 2025
Eleanor Wiske Dillon et al. Early impacts of M365 Copilot.arXiv preprint arXiv:2504.11443, 2025
-
[8]
From Local to Global: A Graph RAG Approach to Query-Focused Summarization
Darren Edge, Ha Trinh, Newman Cheng, et al. From local to global: A graph RAG approach to query-focused summarization.arXiv preprint arXiv:2404.16130, 2024
work page internal anchor Pith review arXiv 2024
-
[9]
Signed graph representation learning: A survey.arXiv preprint arXiv:2402.15980, 2024
others. Signed graph representation learning: A survey.arXiv preprint arXiv:2402.15980, 2024
-
[10]
others. Dealing with inconsistency for reasoning over knowledge graphs: A survey.arXiv preprint arXiv:2502.19023, 2025
-
[11]
Knowledge management in a world of generative AI: Impact and implications.ACM Transactions on Management Information Systems, 2025
others. Knowledge management in a world of generative AI: Impact and implications.ACM Transactions on Management Information Systems, 2025. Verify author names against published ACM version before submission
2025
-
[12]
Retrieval-Augmented Generation for Large Language Models: A Survey
Yunfan Gao, Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Yuxi Bi, Yi Dai, Jiawei Sun, Qianyu Guo, Meng Wang, and Haofen Wang. Retrieval-augmented generation for large language models: A survey.arXiv preprint arXiv:2312.10997, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
Glean: AI-powered enterprise search and knowledge discovery.https://www.glean.com/resources/guides/ glean-ai-enterprise-search-knowledge-discovery, 2024
Glean Technologies. Glean: AI-powered enterprise search and knowledge discovery.https://www.glean.com/resources/guides/ glean-ai-enterprise-search-knowledge-discovery, 2024. Product documenta- tion
2024
-
[14]
LightRAG: Simple and Fast Retrieval-Augmented Generation
ZiruiGuo, LianghaoShi, ZhenWang, etal. LightRAG:Simpleandfastretrieval-augmented generation.arXiv preprint arXiv:2410.05779, 2024. Accepted at EMNLP 2025
work page internal anchor Pith review arXiv 2024
-
[15]
Confidence is not timeless: Modeling temporal validity for rule-based temporal knowl- edge graph forecasting
Rikui Huang, Wei Wei, Xiaoye Qu, Shengzhe Zhang, Dangyang Chen, and Yu Cheng. Confidence is not timeless: Modeling temporal validity for rule-based temporal knowl- edge graph forecasting. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 10783–10794, 2024
2024
-
[16]
Uncertainty management in the con- struction of knowledge graphs: a survey.Transactions on Graph Data and Knowledge (TGDK), 3(1), 2024
Lucas Jarnac, Yoan Chabot, and Miguel Couceiro. Uncertainty management in the con- struction of knowledge graphs: a survey.Transactions on Graph Data and Knowledge (TGDK), 3(1), 2024
2024
-
[17]
A survey on temporal knowledge graph embedding: Models and appli- cations.Knowledge-Based Systems, 304, 2024
Yishi Jiang et al. A survey on temporal knowledge graph embedding: Models and appli- cations.Knowledge-Based Systems, 304, 2024
2024
-
[18]
Xu, Luyu Gao, Zhiqing Sun, Qian Liu, Jane Dwivedi-Yu, Yiming Yang, Jamie Callan, and Graham Neubig
Zhengbao Jiang, Frank F. Xu, Luyu Gao, Zhiqing Sun, Qian Liu, Jane Dwivedi-Yu, Yiming Yang, Jamie Callan, and Graham Neubig. Active retrieval augmented generation. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 7969–7992, 2023. arXiv:2305.06983. 13
-
[19]
Long context RAG performance of large language models
Quinn Leng, Jacob Portes, Sam Havens, Matei Zaharia, and Michael Carbin. Long context RAG performance of large language models. InNeurIPS 2024 Workshop on Adaptive Foundation Models, 2024. arXiv:2411.03538
-
[20]
Retrieval-augmented generation for knowledge-intensive NLP tasks
Patrick Lewis, Ethan Perez, Aleksandra Piktus, et al. Retrieval-augmented generation for knowledge-intensive NLP tasks. InAdvances in Neural Information Processing Systems, volume 33, 2020
2020
-
[21]
Continuous knowledge graph refinement with confidence propagation
Junheng Li et al. Continuous knowledge graph refinement with confidence propagation. IEEE Transactions on Knowledge and Data Engineering, 2023
2023
-
[22]
Xinze Li, Yixin Cao, Yubo Ma, and Aixin Sun. Long context vs. RAG for LLMs: An evaluation and revisits.arXiv preprint arXiv:2501.01880, 2025
-
[23]
Retrieval augmented generation or long-context LLMs? a comprehensive study and hybrid approach
Zhuowan Li, Cheng Li, Mingyang Zhang, Qiaozhu Mei, and Michael Bendersky. Retrieval augmented generation or long-context LLMs? a comprehensive study and hybrid approach. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Process- ing (Industry Track), 2024. arXiv:2407.16833
-
[24]
Memory in the Age of AI Agents
Shichun Liu et al. Memory in the age of AI agents: A survey.arXiv preprint arXiv:2512.13564, 2025
work page internal anchor Pith review arXiv 2025
-
[25]
MemTensor. MemOS: An operating system for memory-augmented generation.arXiv preprint arXiv:2505.22101, 2025
-
[26]
PROV-DM: The PROV data model.https://www.w3
Luc Moreau, Paolo Missier, et al. PROV-DM: The PROV data model.https://www.w3. org/TR/prov-dm/, 2013. W3C Recommendation
2013
-
[27]
A dynamic theory of organizational knowledge creation.Organization Science, 5(1):14–37, 1994
Ikujiro Nonaka. A dynamic theory of organizational knowledge creation.Organization Science, 5(1):14–37, 1994
1994
-
[28]
The ultimate guide to AI-powered knowl- edge hubs in notion.https://www.notion.com/help/guides/ ultimate-guide-to-ai-powered-knowledge-hubs-in-notion, 2024
Notion Labs. The ultimate guide to AI-powered knowl- edge hubs in notion.https://www.notion.com/help/guides/ ultimate-guide-to-ai-powered-knowledge-hubs-in-notion, 2024. Product doc- umentation
2024
-
[29]
MemGPT: Towards LLMs as Operating Systems
Charles Packer, Sarah Wooders, Kevin Lin, et al. MemGPT: Towards LLMs as operating systems.arXiv preprint arXiv:2310.08560, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[30]
Palantirontology: Connectingdatatotherealworld, 2023
PalantirTechnologies. Palantirontology: Connectingdatatotherealworld, 2023. Platform Documentation
2023
-
[31]
Zep: A Temporal Knowledge Graph Architecture for Agent Memory
Preston Rasmussen et al. Zep: A temporal knowledge graph architecture for agent memory. arXiv preprint arXiv:2501.13956, 2025
work page internal anchor Pith review arXiv 2025
-
[32]
Large Language Models Can Be Easily Distracted by Irrelevant Context
Freda Shi, Xinyun Chen, Kanishka Misra, Nathan Scales, David Dohan, Ed H. Chi, Nathanael Schärli, and Denny Zhou. Large language models can be easily distracted by irrelevant context. InProceedings of the 40th International Conference on Machine Learn- ing, volume 202 ofProceedings of Machine Learning Research, pages 31210–31227, 2023. arXiv:2302.00093
-
[33]
Stein and Vladimir Zwass
Eric W. Stein and Vladimir Zwass. Actualizing organizational memory with information systems.Information Systems Research, 6(2):85–117, 1995
1995
-
[34]
Walsh and Gerardo Rivera Ungson
James P. Walsh and Gerardo Rivera Ungson. Organizational memory.Academy of Man- agement Review, 16(1):57–91, 1991. 14
1991
-
[35]
Knowledge conflicts for LLMs: A survey
Rongwu Xu et al. Knowledge conflicts for LLMs: A survey. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, 2024
2024
-
[36]
A-MEM: Agentic Memory for LLM Agents
Wujiang Xu, Zujie Liang, et al. A-MEM: Agentic memory for LLM agents.arXiv preprint arXiv:2502.12110, 2025. NeurIPS 2025
work page internal anchor Pith review arXiv 2025
-
[37]
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, et al. Judging LLM-as-a-judge with MT- Bench and chatbot arena. InAdvances in Neural Information Processing Systems, vol- ume 36, 2023. arXiv:2306.05685. A KOC Axis Specification The Knowledge Object Coordinate is a 7-axis structured identifier: [Entity]-[Domain]-[Class]-[Epoch]-[Depth]- [Author]-[Variant] Each a...
work page internal anchor Pith review arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.