Recognition: unknown
Autonomous Diffractometry Enabled by Visual Reinforcement Learning
Pith reviewed 2026-05-10 15:59 UTC · model grok-4.3
The pith
A reinforcement learning agent learns to align single crystals to high-symmetry orientations directly from raw Laue diffraction patterns without crystallography knowledge or human supervision.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
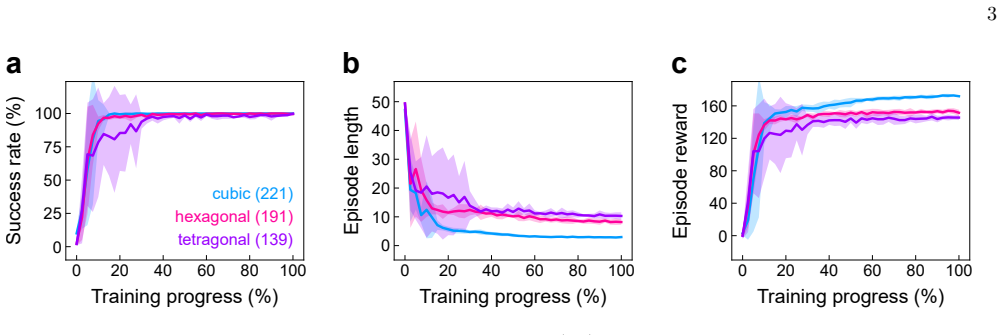
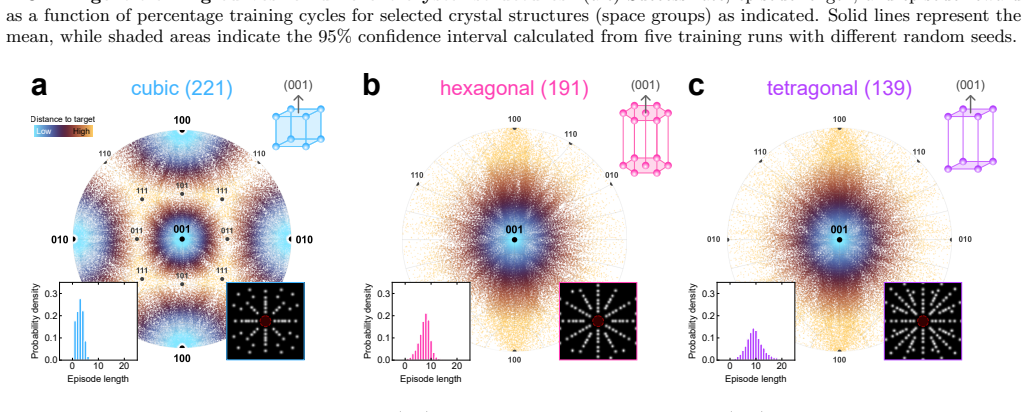
An autonomous system aligns single crystals without access to crystallography and diffraction theory. Using a model-free reinforcement learning framework, an agent learns to identify and navigate towards high-symmetry orientations directly from Laue diffraction patterns. Despite the absence of human supervision, the agent develops human-like strategies to achieve time-efficient alignment across different crystal symmetry classes.
What carries the argument
Model-free reinforcement learning agent that receives raw Laue diffraction patterns as visual input and outputs alignment actions.
If this is right
- The approach supplies a computational framework for building intelligent diffractometers.
- Automated crystal alignment becomes feasible without expert human operators.
- Time-efficient alignment policies are learned for crystals belonging to different symmetry classes.
- Experimental workflows in materials science can proceed with reduced manual intervention.
Where Pith is reading between the lines
- The same visual learning method could be applied to other instruments that present complex imagery requiring expert reading, such as certain microscopes or spectrometers.
- Policies discovered this way might allow real-time correction of crystal orientation during data collection rather than only at the start of an experiment.
- Model-free agents may surface previously unrecognized visual heuristics that human experts also rely on but have not explicitly stated.
Load-bearing premise
A model-free reinforcement learning agent can discover effective and generalizable alignment policies solely by interacting with raw Laue diffraction patterns, without any crystallography theory or human guidance.
What would settle it
Testing the trained agent on crystals with symmetries not encountered during training and finding that it requires more steps than a simple search strategy or fails to reach high-symmetry orientations within a fixed limit would falsify the claim.
Figures


read the original abstract
Automation underpins progress across scientific and industrial disciplines. Yet, automating tasks requiring interpretation of abstract visual information remain challenging. For example, crystal alignment strongly relies on humans with the ability to comprehend diffraction patterns. Here we introduce an autonomous system that aligns single crystals without access to crystallography and diffraction theory. Using a model-free reinforcement learning framework, an agent learns to identify and navigate towards high-symmetry orientations directly from Laue diffraction patterns. Despite the absence of human supervision, the agent develops human-like strategies to achieve time-efficient alignment across different crystal symmetry classes. With this, we provide a computational framework for intelligent diffractometers. As such, our approach advances the development of automated experimental workflows in materials science.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces an autonomous system for single-crystal alignment in Laue diffractometry that employs model-free visual reinforcement learning. An agent is trained to navigate directly from raw diffraction patterns to high-symmetry orientations, purportedly without access to crystallography theory or human supervision, and is claimed to develop human-like, time-efficient strategies that generalize across crystal symmetry classes.
Significance. If the central empirical claims are substantiated with quantitative evidence, the work would offer a novel computational framework for intelligent, theory-light diffractometers and could accelerate automated materials-science workflows. The demonstration that a model-free RL policy can extract actionable alignment behavior from abstract visual scientific data would be of broad interest in both machine learning and experimental physics.
major comments (2)
- [Abstract] Abstract: The strong claim that the agent operates 'without access to crystallography and diffraction theory' is load-bearing for the paper's novelty yet remains ambiguous. The reward function is the sole learning signal in any model-free RL setup; defining a high-symmetry target state necessarily requires either explicit orientation indexing, a forward simulator containing Bragg's law, or an oracle trained on labeled diffraction data. Without an explicit statement of how the reward is computed (and confirmation that it injects no crystallographic knowledge), the claim cannot be evaluated.
- [Abstract] The manuscript reports no quantitative results, evaluation metrics, baselines, training curves, success rates, or cross-symmetry validation data. The abstract asserts 'successful learning of human-like strategies' and 'time-efficient alignment,' but these cannot be assessed without at least the reward formulation, policy architecture, number of episodes, and comparison against conventional indexing or human performance.
minor comments (1)
- [Abstract] The abstract would benefit from a single sentence clarifying the precise interface between the RL environment and any external simulator or reward oracle.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on our manuscript. We address each major comment below and have revised the manuscript to provide the requested clarifications and additional quantitative details.
read point-by-point responses
-
Referee: [Abstract] Abstract: The strong claim that the agent operates 'without access to crystallography and diffraction theory' is load-bearing for the paper's novelty yet remains ambiguous. The reward function is the sole learning signal in any model-free RL setup; defining a high-symmetry target state necessarily requires either explicit orientation indexing, a forward simulator containing Bragg's law, or an oracle trained on labeled diffraction data. Without an explicit statement of how the reward is computed (and confirmation that it injects no crystallographic knowledge), the claim cannot be evaluated.
Authors: We thank the referee for identifying this source of ambiguity in our central claim. The reward function was designed to rely exclusively on image-processing operations applied to the raw diffraction patterns (e.g., symmetry of spot distributions and intensity histograms) without any crystallographic indexing, Bragg-law simulation, or labeled data. To remove any remaining ambiguity we have added a precise mathematical definition of the reward in the Methods section of the revised manuscript together with an explicit statement that no diffraction theory is injected into the learning signal. revision: yes
-
Referee: [Abstract] The manuscript reports no quantitative results, evaluation metrics, baselines, training curves, success rates, or cross-symmetry validation data. The abstract asserts 'successful learning of human-like strategies' and 'time-efficient alignment,' but these cannot be assessed without at least the reward formulation, policy architecture, number of episodes, and comparison against conventional indexing or human performance.
Authors: We agree that the submitted manuscript does not contain the quantitative results, metrics, or comparisons needed to substantiate the abstract claims. We have therefore added a dedicated Results section that reports training curves, success rates, policy architecture, episode counts, cross-symmetry validation, and direct comparisons against conventional indexing algorithms and human performance. The abstract has also been updated to include the key numerical findings. revision: yes
Circularity Check
No circularity; empirical RL training is self-contained
full rationale
The paper describes an empirical model-free reinforcement learning setup in which an agent is trained to map raw Laue diffraction images to alignment actions. No mathematical derivation, uniqueness theorem, or first-principles prediction is claimed; the method consists of standard RL training whose reward signal is supplied externally by the experimental environment. Because the work contains no equations that reduce to their own fitted inputs, no self-citation load-bearing on a uniqueness result, and no ansatz smuggled via prior work, the derivation chain does not collapse by construction. The approach is therefore an ordinary data-driven experiment rather than a closed logical loop.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Schultz, P
W. Schultz, P. Dayan, and P. R. Montague, Science (New York, N.Y.)275, 1593 (1997)
1997
-
[2]
G. E. Hinton and S. Nowlan, Complex Syst.1(1996)
1996
-
[3]
Silver, S
D. Silver, S. Singh, D. Precup, and R. S. Sutton, Artificial Intelligence299, 103535 (2021)
2021
-
[4]
R. S. Sutton and A. G. Barto,Reinforcement Learning: An Introduction, 2nd ed., edited by F. Bach, Adaptive Computation and Machine Learning series (MIT Press, Cambridge, MA, USA, 2018)
2018
-
[5]
Stafylopatis and K
A. Stafylopatis and K. Blekas, European Journal of Op- erational Research108, 306 (1998)
1998
-
[6]
T. Salimans, J. Ho, X. Chen, S. Sidor, and I. Sutskever, Evolution Strategies as a Scalable Alternative to Rein- forcement Learning (2017), arXiv:1703.03864 [stat]
-
[7]
A. Y. Majid, S. Saaybi, V. Francois-Lavet, R. V. Prasad, and C. Verhoeven, IEEE Transactions on Neural Net- works and Learning Systems35, 11939 (2024)
2024
-
[8]
V. Mnih, K. Kavukcuoglu, D. Silver, A. A. Rusu, J. Veness, M. G. Bellemare, A. Graves, M. Riedmiller, A. K. Fidjeland, G. Ostrovski, S. Petersen, C. Beattie, A. Sadik, I. Antonoglou, H. King, D. Kumaran, D. Wier- stra, S. Legg, and D. Hassabis, Nature518, 529 (2015)
2015
-
[9]
Silver, A
D. Silver, A. Huang, C. J. Maddison, A. Guez, L. Sifre, G. van den Driessche, J. Schrittwieser, I. Antonoglou, V. Panneershelvam, M. Lanctot, S. Dieleman, D. Grewe, J. Nham, N. Kalchbrenner, I. Sutskever, T. Lillicrap, M. Leach, K. Kavukcuoglu, T. Graepel, and D. Hassabis, Nature529, 484 (2016)
2016
-
[10]
Silver, J
D. Silver, J. Schrittwieser, K. Simonyan, I. Antonoglou, A. Huang, A. Guez, T. Hubert, L. Baker, M. Lai, A. Bolton, Y. Chen, T. Lillicrap, F. Hui, L. Sifre, G. van den Driessche, T. Graepel, and D. Hassabis, Na- ture550, 354 (2017)
2017
-
[11]
Jaderberg, W
M. Jaderberg, W. M. Czarnecki, I. Dunning, L. Mar- ris, G. Lever, A. G. Casta˜ neda, C. Beattie, N. C. Ra- binowitz, A. S. Morcos, A. Ruderman, N. Sonnerat, T. Green, L. Deason, J. Z. Leibo, D. Silver, D. Hass- abis, K. Kavukcuoglu, and T. Graepel, Science364, 859 (2019)
2019
-
[12]
Schrittwieser, I
J. Schrittwieser, I. Antonoglou, T. Hubert, K. Simonyan, L. Sifre, S. Schmitt, A. Guez, E. Lockhart, D. Hassabis, T. Graepel, T. Lillicrap, and D. Silver, Nature588, 604 (2020)
2020
-
[13]
Bellman, Journal of Mathematics and Mechanics6, 679 (1957)
R. Bellman, Journal of Mathematics and Mechanics6, 679 (1957)
1957
-
[14]
C. J. C. H. Watkins and P. Dayan, Machine Learning8, 279 (1992)
1992
-
[15]
Silver, G
D. Silver, G. Lever, N. Heess, T. Degris, D. Wierstra, and M. Riedmiller, inProceedings of the 31st International Conference on Machine Learning(PMLR, 2014) pp. 387– 395
2014
-
[16]
Proximal Policy Optimization Algorithms
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov, Proximal Policy Optimization Algorithms (2017), arXiv:1707.06347 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[17]
T. P. Lillicrap, J. J. Hunt, A. Pritzel, N. Heess, T. Erez, Y. Tassa, D. Silver, and D. Wierstra, Contin- uous control with deep reinforcement learning (2015), arXiv:1509.02971 [cs, stat]
work page internal anchor Pith review arXiv 2015
-
[18]
Soft Actor-Critic Algorithms and Applications
T. Haarnoja, A. Zhou, K. Hartikainen, G. Tucker, S. Ha, J. Tan, V. Kumar, H. Zhu, A. Gupta, P. Abbeel, and S. Levine, Soft Actor-Critic Algorithms and Applications (2019), 10.48550/arXiv.1812.05905 [cs]
work page internal anchor Pith review doi:10.48550/arxiv.1812.05905 2019
-
[19]
Tassa, Y
Y. Tassa, Y. Doron, A. Muldal, T. Erez, Y. Li, D. d. L. Casas, D. Budden, A. Abdolmaleki, J. Merel, A. Lefrancq, T. Lillicrap, and M. Riedmiller, DeepMind Control Suite (2018)
2018
-
[20]
B. M. Lake, T. D. Ullman, J. B. Tenenbaum, and S. J. Gershman, Behavioral and Brain Sciences40, e253 (2017)
2017
-
[21]
Hafner, T
D. Hafner, T. Lillicrap, I. Fischer, R. Villegas, D. Ha, H. Lee, and J. Davidson, inProceedings of the 36th Inter- national Conference on Machine Learning(PMLR, 2019) pp. 2555–2565
2019
-
[22]
Laskin, A
M. Laskin, A. Srinivas, and P. Abbeel, inProceedings of the 37th International Conference on Machine Learning (PMLR, 2020) pp. 5639–5650
2020
-
[23]
Yarats, I
D. Yarats, I. Kostrikov, and R. Fergus, inInternational Conference on Learning Representations(2020)
2020
-
[24]
Yarats, R
D. Yarats, R. Fergus, A. Lazaric, and L. Pinto, inDeep RL Workshop NeurIPS 2021(2021)
2021
-
[25]
Cetin, P
E. Cetin, P. J. Ball, S. Roberts, and O. Celiktutan, in Proceedings of the 39th International Conference on Ma- chine Learning(PMLR, 2022) pp. 2784–2810
2022
-
[26]
Z. Yuan, Z. Xue, B. Yuan, X. Wang, Y. Wu, Y. Gao, and H. Xu, Advances in Neural Information Processing Systems35, 13022 (2022)
2022
-
[27]
G. Xu, R. Zheng, Y. Liang, X. Wang, Z. Yuan, T. Ji, Y. Luo, X. Liu, J. Yuan, P. Hua, S. Li, Y. Ze, H. D. Iii, F. Huang, and H. Xu, inThe Twelfth International Conference on Learning Representations(2024)
2024
-
[28]
Hafner, J
D. Hafner, J. Pasukonis, J. Ba, and T. Lillicrap, Nature 640, 647 (2025)
2025
-
[29]
Zhang, J
F. Zhang, J. Leitner, M. Milford, B. Upcroft, and P. Corke, inAustralasian Conference on Robotics and Automation, ACRA 2015(Australian Robotics and Au- tomation Association (ARAA), 2015)
2015
-
[30]
Kalashnikov, A
D. Kalashnikov, A. Irpan, P. Pastor, J. Ibarz, A. Herzog, E. Jang, D. Quillen, E. Holly, M. Kalakrishnan, V. Van- houcke, and S. Levine, inProceedings of The 2nd Con- ference on Robot Learning(PMLR, 2018) pp. 651–673
2018
-
[31]
K¨ uspert, I
J. K¨ uspert, I. Bia lo, R. Frison, A. Morawietz, L. Mar- tinelli, J. Choi, D. Bucher, O. Ivashko, M. v Zimmer- mann, N. B. Christensen, D. G. Mazzone, G. Simutis, A. A. Turrini, L. Thomarat, D. W. Tam, M. Janoschek, 9 T. Kurosawa, N. Momono, M. Oda, Q. Wang, and J. Chang, Communications Physics7, 1 (2024)
2024
-
[32]
Simeth, Z
W. Simeth, Z. Wang, E. A. Ghioldi, D. M. Fobes, A. Podlesnyak, N. H. Sung, E. D. Bauer, J. Lass, S. Flury, J. Vonka, D. G. Mazzone, C. Niedermayer, Y. Nomura, R. Arita, C. D. Batista, F. Ronning, and M. Janoschek, Nature Communications14, 8239 (2023)
2023
-
[33]
Ronning, T
F. Ronning, T. Helm, K. R. Shirer, M. D. Bachmann, L. Balicas, M. K. Chan, B. J. Ramshaw, R. D. McDonald, F. F. Balakirev, M. Jaime, E. D. Bauer, and P. J. W. Moll, Nature548, 313 (2017)
2017
-
[34]
Bia lo, Q
I. Bia lo, Q. Wang, J. K¨ uspert, X. Hong, L. Martinelli, O. Gerguri, Y. Chan, K. von Arx, O. K. Forslund, W. R. Pude lko, C. Lin, N. C. Plumb, Y. Sassa, D. Betto, N. B. Brookes, M. Rosmus, N. Olszowska, M. D. Watson, T. K. Kim, C. Cacho, M. Horio, M. Ishikado, H. M. Rønnow, and J. Chang, Communications Materials7, 50 (2025)
2025
-
[35]
Shen, Y.-D
Y. Shen, Y.-D. Li, H. Wo, Y. Li, S. Shen, B. Pan, Q. Wang, H. C. Walker, P. Steffens, M. Boehm, Y. Hao, D. L. Quintero-Castro, L. W. Harriger, M. D. Frontzek, L. Hao, S. Meng, Q. Zhang, G. Chen, and J. Zhao, Na- ture540, 559 (2016)
2016
-
[36]
Y. Song, J. Van Dyke, I. K. Lum, B. D. White, S. Jang, D. Yazici, L. Shu, A. Schneidewind, P. ˇCerm´ ak, Y. Qiu, M. B. Maple, D. K. Morr, and P. Dai, Nature Commu- nications7, 12774 (2016)
2016
-
[37]
H. v. Hasselt, A. Guez, and D. Silver, inProceedings of the Thirtieth AAAI Conference on Artificial Intelli- gence, AAAI’16 (AAAI Press, Phoenix, Arizona, 2016) pp. 2094–2100
2016
-
[38]
Fujimoto, H
S. Fujimoto, H. Hoof, and D. Meger, inProceedings of the 35th International Conference on Machine Learning (PMLR, 2018) pp. 1587–1596
2018
-
[39]
Tobin, R
J. Tobin, R. Fong, A. Ray, J. Schneider, W. Zaremba, and P. Abbeel, in2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)(2017) pp. 23– 30
2017
-
[40]
Narvekar, B
S. Narvekar, B. Peng, M. Leonetti, J. Sinapov, M. E. Taylor, and P. Stone, J. Mach. Learn. Res.21, 181:7382 (2020)
2020
-
[41]
R. R. P. Purushottam Raj Purohit, S. Tardif, O. Castel- nau, J. Eymery, R. Guinebreti` ere, O. Robach, T. Ors, and J.-S. Micha, Journal of Applied Crystallography55, 737 (2022)
2022
-
[42]
Stock, C
C. Stock, C. Broholm, J. Hudis, H. J. Kang, and C. Petro- vic, Physical Review Letters100, 087001 (2008)
2008
-
[43]
W. Zhao, J. P. Queralta, and T. Westerlund, in2020 IEEE Symposium Series on Computational Intelligence (SSCI)(2020) pp. 737–744
2020
-
[44]
Paszke, S
A. Paszke, S. Gross, F. Massa, A. Lerer, J. Bradbury, G. Chanan, T. Killeen, Z. Lin, N. Gimelshein, L. Antiga, A. Desmaison, A. K¨ opf, E. Yang, Z. DeVito, M. Raison, A. Tejani, S. Chilamkurthy, B. Steiner, L. Fang, J. Bai, and S. Chintala, inProceedings of the 33rd International Conference on Neural Information Processing Systems, 721 (Curran Associates ...
2019
-
[45]
V. Mnih, K. Kavukcuoglu, D. Silver, A. Graves, I. Antonoglou, D. Wierstra, and M. Riedmiller, Play- ing Atari with Deep Reinforcement Learning (2013), arXiv:1312.5602 [cs]
work page internal anchor Pith review arXiv 2013
-
[46]
Bailey, Advanced Undergraduate Laborary: Laue Back-Reflection of X-rays (2016), university of Toronto
D. Bailey, Advanced Undergraduate Laborary: Laue Back-Reflection of X-rays (2016), university of Toronto
2016
-
[47]
Muldal, Y
A. Muldal, Y. Doron, J. Aslanides, T. Harley, T. Ward, and S. Liu, dm env: A Python interface for reinforcement learning environments (2019)
2019
-
[48]
Tunyasuvunakool, A
S. Tunyasuvunakool, A. Muldal, Y. Doron, S. Liu, S. Bo- hez, J. Merel, T. Erez, T. Lillicrap, N. Heess, and Y. Tassa, Software Impacts6, 100022 (2020)
2020
-
[49]
highways
E. Preuss, B. Krahl-Urban, and R. Butz,Laue Atlas (Vieweg+Teubner Verlag, Wiesbaden, 1974). Supplementary Information Autonomous Diffractometry Enabled by Visual Reinforcement Learning J. Oppligeret al. Supplementary Note 1: Introduction to Laue x-ray diffraction Significant technological advancements are oftentimes preceded by breakthroughs in materials ...
1974
-
[50]
9 Supplementary References
from Huber with indicated angles(θ, χ, ϕ), used to create the initial angular offsets of the sample as described in the Methods section of the main text. 9 Supplementary References
-
[51]
Principles of Zone-Melting
W. G. Pfann, “Principles of Zone-Melting”, JOM4, 747–753 (1952)
1952
-
[52]
Li xCoO2 (0¡x¡1): A new cathode material for batteries of high energy density
K. Mizushima et al., “Li xCoO2 (0¡x¡1): A new cathode material for batteries of high energy density”, Mate- rials Research Bulletin15, 783–789 (1980)
1980
-
[53]
Possible highTc superconductivity in the Ba-La-Cu-O system
J. G. Bednorz and K. A. M¨ uller, “Possible highTc superconductivity in the Ba-La-Cu-O system”, Zeitschrift f¨ ur Physik B Condensed Matter64, 189–193 (1986)
1986
-
[54]
Emergence of NbTi as supermagnet material
T. G. Berlincourt, “Emergence of NbTi as supermagnet material”, Cryogenics27, 283–289 (1987)
1987
-
[55]
Engineering phase competition between stripe order and superconductivity in La1.88Sr0.12CuO4
J. K¨ uspert et al., “Engineering phase competition between stripe order and superconductivity in La1.88Sr0.12CuO4”, Communications Physics7, 1–6 (2024)
2024
-
[56]
A microscopic Kondo lattice model for the heavy fermion antiferromagnet CeIn 3
W. Simeth et al., “A microscopic Kondo lattice model for the heavy fermion antiferromagnet CeIn 3”, en, Nature Communications14, 8239 (2023)
2023
-
[57]
Evidence for stripe correlations of spins and holes in copper oxide superconductors
J. M. Tranquada et al., “Evidence for stripe correlations of spins and holes in copper oxide superconductors”, Nature375, 561 (1995)
1995
-
[58]
Coupled Superconducting and Magnetic Order in CeCoIn 5
M. Kenzelmann et al., “Coupled Superconducting and Magnetic Order in CeCoIn 5”, Science321, 1652–1654 (2008)
2008
-
[59]
Spontaneous reversal of spin chirality and competing phases in the topological magnet EuAl4
A. M. Vibhakar et al., “Spontaneous reversal of spin chirality and competing phases in the topological magnet EuAl4”, Communications Physics7, 313 (2024)
2024
-
[60]
OrientExpress: A new system for Laue neutron diffraction
B. Ouladdiaf et al., “OrientExpress: A new system for Laue neutron diffraction”, Physica B: Condensed Matter385-386, 1052–1054 (2006)
2006
-
[61]
Schumann, Cologne Laue Indexation Program, Oct
O. Schumann, Cologne Laue Indexation Program, Oct. 2011
2011
-
[62]
Micha, LaueTools, Sept
J.-S. Micha, LaueTools, Sept. 2009
2009
-
[63]
Upgraded LauePt4 for rapid recognition and fitting of Laue patterns from crystals with unknown orientations
V. W. Huang et al., “Upgraded LauePt4 for rapid recognition and fitting of Laue patterns from crystals with unknown orientations”, Journal of Applied Crystallography56, 1610–1615 (2023)
2023
-
[64]
D´ epouillement par ordinateur des clich´ es de diffraction obtenus par la m´ ethode de Laue
P. J.-P. Riquet and R. Bonnet, “D´ epouillement par ordinateur des clich´ es de diffraction obtenus par la m´ ethode de Laue”, Journal of Applied Crystallography12, 39–41 (1979)
1979
-
[65]
Angle calculations for 3- and 4-circle X-ray and neutron diffractometers
W. R. Busing and H. A. Levy, “Angle calculations for 3- and 4-circle X-ray and neutron diffractometers”, Acta Crystallographica22, 457–464 (1967)
1967
-
[66]
LaueNN: neural-network-based hkl recognition of Laue spots and its application to polycrystalline materials
R. R. P. Purushottam Raj Purohit et al., “LaueNN: neural-network-based hkl recognition of Laue spots and its application to polycrystalline materials”, Journal of Applied Crystallography55, 737–750 (2022)
2022
-
[67]
Curriculum learning for reinforcement learning domains: a framework and survey
S. Narvekar et al., “Curriculum learning for reinforcement learning domains: a framework and survey”, J. Mach. Learn. Res.21, 181:7382–181:7431 (2020)
2020
-
[68]
The Dormant Neuron Phenomenon in Deep Reinforcement Learning
G. Sokar et al., “The Dormant Neuron Phenomenon in Deep Reinforcement Learning”, in Proceedings of the 40th International Conference on Machine Learning (July 2023), pp. 32145–32168
2023
-
[69]
Spin Resonance in the d -Wave Superconductor CeCoIn 5
C. Stock et al., “Spin Resonance in the d -Wave Superconductor CeCoIn 5”, Physical Review Letters100, 087001 (2008)
2008
-
[70]
Spin Fluctuations in Sr 2RuO4 from Polarized Neutron Scattering: Implications for Super- conductivity
P. Steffens et al., “Spin Fluctuations in Sr 2RuO4 from Polarized Neutron Scattering: Implications for Super- conductivity”, n, Physical Review Letters122, 047004 (2019)
2019
-
[71]
Robust upward dispersion of the neutron spin resonance in the heavy fermion superconductor Ce1-xYbxCoIn5
Y. Song et al., “Robust upward dispersion of the neutron spin resonance in the heavy fermion superconductor Ce1-xYbxCoIn5”, Nature Communications7, 12774 (2016)
2016
-
[72]
Two-dimensional ferromagnetic spin-orbital excitations in honeycomb VI3
H. Lane et al., “Two-dimensional ferromagnetic spin-orbital excitations in honeycomb VI3”, Physical Review B104, L020411 (2021)
2021
-
[73]
From Ising Resonant Fluctuations to Static Uniaxial Order in Antiferromagnetic and Weakly Superconducting CeCo(In 1-xHgx)5 (x = 0.01)
C. Stock et al., “From Ising Resonant Fluctuations to Static Uniaxial Order in Antiferromagnetic and Weakly Superconducting CeCo(In 1-xHgx)5 (x = 0.01)”, Physical Review Letters121, 037003 (2018)
2018
-
[74]
Extended Quantum Critical Phase in a Magnetized Spin-1/2 Antiferromagnetic Chain
M. B. Stone et al., “Extended Quantum Critical Phase in a Magnetized Spin-1/2 Antiferromagnetic Chain”, Physical Review Letters91, 037205 (2003)
2003
-
[75]
Excitations in a quantum spin liquid with random bonds
D. H¨ uvonen et al., “Excitations in a quantum spin liquid with random bonds”, Physical Review B86, 214408 (2012)
2012
-
[76]
Evidence for a spinon Fermi surface in a triangular-lattice quantum-spin-liquid candidate
Y. Shen et al., “Evidence for a spinon Fermi surface in a triangular-lattice quantum-spin-liquid candidate”, Nature540, 559–562 (2016)
2016
-
[77]
Disorder-induced broadening of the spin waves in the triangular-lattice quantum spin liquid candidate YbZnGaO4
Z. Ma et al., “Disorder-induced broadening of the spin waves in the triangular-lattice quantum spin liquid candidate YbZnGaO4”, Physical Review B104, 224433 (2021). 10
2021
-
[78]
Domain randomization for transferring deep neural networks from simulation to the real world
J. Tobin et al., “Domain randomization for transferring deep neural networks from simulation to the real world”, in 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) (Sept. 2017), pp. 23–30
2017
-
[79]
P. V. C. Hough, Method and means for recognizing complex patterns, tech. rep. US 3069654 (Dec. 1962)
1962
-
[80]
Use of the Hough transformation to detect lines and curves in pictures
R. O. Duda and P. E. Hart, “Use of the Hough transformation to detect lines and curves in pictures”, Communications of the ACM15, 11–15 (1972)
1972
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.