Recognition: unknown
HDR Video Generation via Latent Alignment with Logarithmic Encoding
Pith reviewed 2026-05-10 15:26 UTC · model grok-4.3
The pith
Logarithmic encoding aligns HDR imagery with the latent space of pretrained generative models, enabling lightweight fine-tuning for high-quality HDR video generation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that a logarithmic encoding maps HDR imagery into a distribution naturally aligned with the latent space of pretrained generative models. This alignment permits direct adaptation via lightweight fine-tuning without retraining an encoder. When combined with a training strategy that applies camera-mimicking degradations, the model learns to infer missing high-dynamic-range content from its priors, producing high-quality HDR video across diverse scenes and challenging lighting conditions.
What carries the argument
Logarithmic encoding that remaps HDR radiance values into a distribution matching pretrained model latents, paired with camera-mimicking degradations that force inference of unobserved content from visual priors.
If this is right
- Pretrained video models can generate HDR footage after only lightweight fine-tuning once the input is logarithmically encoded.
- Camera-mimicking degradations during training enable the model to recover high-dynamic-range details not present in the input.
- The method produces strong results on diverse scenes and challenging lighting without redesigning the generative architecture.
- HDR can be handled effectively by aligning representations to existing priors rather than learning entirely new ones.
Where Pith is reading between the lines
- The same log-alignment step could simplify HDR adaptation for still-image generators or editing tools that share similar latent spaces.
- Real captured HDR video sequences could serve as a direct test set to check whether the simulated degradations match actual camera behavior.
- Other perceptual encodings used in imaging pipelines might offer similar alignment benefits for radiance data in generative tasks.
Load-bearing premise
That logarithmic encoding naturally aligns HDR distributions with the latent space of pretrained models and that the models' priors can reliably infer unobserved high dynamic range content when trained with camera-mimicking degradations.
What would settle it
Fine-tune the same pretrained video model on identical HDR data but replace the logarithmic encoding with a linear or standard tone-mapped representation; if the outputs show clipping, color shifts, or loss of detail in extreme lighting, the alignment claim is weakened.
Figures





read the original abstract
High dynamic range (HDR) imagery offers a rich and faithful representation of scene radiance, but remains challenging for generative models due to its mismatch with the bounded, perceptually compressed data on which these models are trained. A natural solution is to learn new representations for HDR, which introduces additional complexity and data requirements. In this work, we show that HDR generation can be achieved in a much simpler way by leveraging the strong visual priors already captured by pretrained generative models. We observe that a logarithmic encoding widely used in cinematic pipelines maps HDR imagery into a distribution that is naturally aligned with the latent space of these models, enabling direct adaptation via lightweight fine-tuning without retraining an encoder. To recover details that are not directly observable in the input, we further introduce a training strategy based on camera-mimicking degradations that encourages the model to infer missing high dynamic range content from its learned priors. Combining these insights, we demonstrate high-quality HDR video generation using a pretrained video model with minimal adaptation, achieving strong results across diverse scenes and challenging lighting conditions. Our results indicate that HDR, despite representing a fundamentally different image formation regime, can be handled effectively without redesigning generative models, provided that the representation is chosen to align with their learned priors.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a method for generating high dynamic range (HDR) videos by applying logarithmic encoding to map HDR content into the latent space of pretrained video generative models. This alignment allows for adaptation through lightweight fine-tuning without retraining the encoder. Additionally, a training strategy using camera-mimicking degradations is introduced to enable the model to infer unobserved high dynamic range details from its priors. The authors claim this leads to high-quality HDR video generation across diverse scenes and challenging lighting conditions with minimal adaptation.
Significance. If the central claims hold, this work could have significant impact by demonstrating that existing generative models can be adapted for HDR tasks without substantial redesign, leveraging established cinematic practices like log encoding. This simplifies the pipeline and reduces data requirements, which is valuable for the computer vision and graphics communities working on video synthesis and HDR imaging. The approach credits the strength of pretrained priors and provides a practical alternative to learning new representations from scratch.
major comments (1)
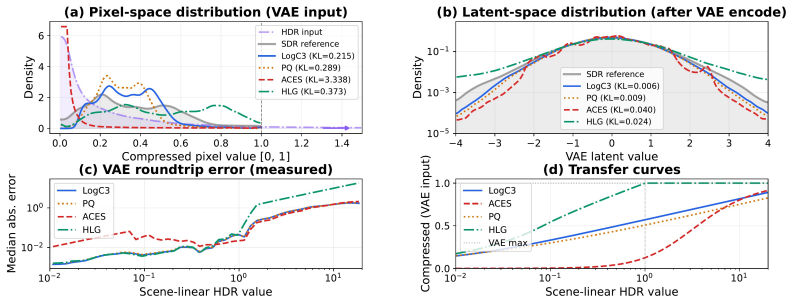
- [Abstract] The central claim in the abstract that logarithmic encoding 'maps HDR imagery into a distribution that is naturally aligned with the latent space of these models' enabling 'direct adaptation via lightweight fine-tuning without retraining an encoder' is load-bearing but unsupported by any direct verification. No latent-space statistics (e.g., distribution moments, histograms, or divergence measures such as KL divergence between log-encoded HDR frames and the pretrained model's training distribution) are reported to confirm the alignment assumption versus the possibility that camera-mimicking degradations are doing the compensatory work.
minor comments (1)
- [Abstract] The abstract states that the method achieves 'strong results' and 'high-quality HDR video generation' but provides no quantitative metrics, ablation details, or baseline comparisons, making it difficult to evaluate the practical gains over existing approaches.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the potential impact of our approach. We address the major comment point-by-point below and will revise the manuscript accordingly to strengthen the presentation of our central claim.
read point-by-point responses
-
Referee: [Abstract] The central claim in the abstract that logarithmic encoding 'maps HDR imagery into a distribution that is naturally aligned with the latent space of these models' enabling 'direct adaptation via lightweight fine-tuning without retraining an encoder' is load-bearing but unsupported by any direct verification. No latent-space statistics (e.g., distribution moments, histograms, or divergence measures such as KL divergence between log-encoded HDR frames and the pretrained model's training distribution) are reported to confirm the alignment assumption versus the possibility that camera-mimicking degradations are doing the compensatory work.
Authors: We agree that direct statistical verification of the distribution alignment would strengthen the manuscript and make the claim more robust. The original submission relied on the well-established use of logarithmic encoding in cinematic pipelines (which is designed to produce perceptually uniform representations within bounded bit depths) together with the empirical success of lightweight fine-tuning as indirect evidence. However, we acknowledge that this leaves open the question of whether the degradations alone could suffice. In the revised version, we will add a dedicated analysis subsection (likely in Section 3 or 4) that includes: (1) histograms and first- and second-order moments of log-encoded HDR frames versus frames from the pretrained model's training distribution; (2) a quantitative comparison using a divergence measure such as approximated KL divergence or Wasserstein distance between the two distributions; and (3) an expanded ablation that trains the same model with linear (instead of log) encoding while keeping the degradation pipeline identical. These additions will allow readers to assess the relative contributions of the encoding choice versus the degradation strategy. We believe the new analysis will confirm that the log mapping is the key enabler of the observed alignment and minimal adaptation. revision: yes
Circularity Check
No circularity; derivation relies on external pretrained priors and empirical representation choice
full rationale
The paper's central steps—selecting logarithmic encoding to align HDR with pretrained latent spaces, then applying lightweight fine-tuning plus camera-mimicking degradations—rest on external pretrained generative models (whose priors are independent of this work) and an observational claim about cinematic log encoding. No equations or claims reduce by construction to fitted parameters, self-definitions, or self-citation chains. The alignment is presented as an empirical observation enabling adaptation, not as a derived result from the paper's own outputs. This is a standard non-circular use of prior models.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Logarithmic encoding maps HDR imagery into a distribution naturally aligned with pretrained generative model latent spaces
- domain assumption Pretrained visual priors can infer missing HDR content when trained with camera-mimicking degradations
Forward citations
Cited by 2 Pith papers
-
Generating HDR Video from SDR Video
A multi-exposure video model predicts bracketed linear SDR sequences from single nonlinear SDR input, which a merging model combines into HDR video preserving shadow and highlight detail.
-
Single-Shot HDR Recovery via a Video Diffusion Prior
Single-shot HDR is achieved by conditioning a video diffusion model on an LDR input to generate an exposure bracket and fusing the bracket with per-pixel weights from a lightweight UNet.
Reference graph
Works this paper leans on
-
[1]
ActionVFX stock footage library
ActionVFX. ActionVFX stock footage library. https://www.actionvfx.com, 2026. Ac- cessed: 2026-04-13. 9
2026
-
[2]
Camera sample footage and reference images
ARRI. Camera sample footage and reference images. https: //www.arri.com/en/learn-help/learn-help-camera-system/ camera-sample-footage-reference-image, 2026. Accessed: 2026-04-13
2026
-
[3]
Bracket diffusion: HDR image generation by consistent LDR denoising.Computer Graphics F orum, 2025
Mojtaba Bemana, Karol Myszkowski, Hans-Peter Seidel, and Tobias Ritschel. Bracket diffusion: HDR image generation by consistent LDR denoising.Computer Graphics F orum, 2025
2025
-
[4]
Matan Ben-Yosef, Tavi Halperin, Naomi Ken Korem, Mohammad Salama, Harel Cain, Asaf Joseph, Anthony Chen, Urska Jelercic, and Ofir Bibi. Avcontrol: Efficient framework for training audio-visual controls.arXiv preprint arXiv:2603.24793, 2026
-
[5]
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
Andreas Blattmann, Tim Dockhorn, Sumith Kulal, Daniel Mendelevitch, Maciej Kilian, Do- minik Lorber, Yam Levi, Zion English, Vikram V oleti, Adam Letts, Varun Jampani, and Robin Rombach. Stable video diffusion: Scaling latent video diffusion models to large datasets.arXiv preprint arXiv:2311.15127, 2023
work page internal anchor Pith review arXiv 2023
-
[6]
Tears of steel
Blender Foundation. Tears of steel. https://mango.blender.org/, 2012. Accessed: 2026- 04-13
2012
-
[7]
Wong, and Lei Zhang
Guanying Chen, Chaofeng Chen, Shi Guo, Zhetong Liang, Kwan-Yee K. Wong, and Lei Zhang. HDR video reconstruction: A coarse-to-fine network and a real-world benchmark dataset. In ICCV, 2021
2021
-
[8]
Ren, Lynhoo Tian, Yu Qiao, and Chao Dong
Xiangyu Chen, Zhengwen Zhang, Jimmy S. Ren, Lynhoo Tian, Yu Qiao, and Chao Dong. A new journey from SDRTV to HDRTV. InICCV, 2021
2021
-
[9]
Debevec and Jitendra Malik
Paul E. Debevec and Jitendra Malik. Recovering high dynamic range radiance maps from photographs. InACM SIGGRAPH, pages 369–378, 1997
1997
-
[10]
Mantiuk, and Jonas Unger
Gabriel Eilertsen, Joel Kronander, Gyorgy Denes, Rafał K. Mantiuk, and Jonas Unger. HDR image reconstruction from a single exposure using deep CNNs. InACM SIGGRAPH Asia, 2017
2017
-
[11]
Edge-preserving decom- positions for multi-scale tone and detail manipulation
Zeev Farbman, Raanan Fattal, Dani Lischinski, and Richard Szeliski. Edge-preserving decom- positions for multi-scale tone and detail manipulation. InACM SIGGRAPH, pages 67:1–67:10, 2008
2008
-
[12]
Gradient domain high dynamic range compression
Raanan Fattal, Dani Lischinski, and Michael Werman. Gradient domain high dynamic range compression. InACM SIGGRAPH, pages 249–256, 2002
2002
-
[13]
Yilun Guan, Yuhan Zhu, and Rafał K. Mantiuk. HDR-V-Diff: Latent diffusion-based HDR video reconstruction. InECCV Workshops, 2024
2024
-
[14]
Yilun Guan, Yuhan Zhu, and Rafał K. Mantiuk. GM-Diffusion: Gain-map guided diffusion model for high dynamic range image generation. InICCV, 2025
2025
-
[15]
LTX-Video: Realtime Video Latent Diffusion
Yoav HaCohen, Nisan Chiprut, Benny Brazowski, Daniel Shalem, Dudu Moshe, Eitan Richard- son, Eran Levin, Guy Shiran, Nir Zabari, Ori Gordon, Poriya Panet, Sapir Weissbuch, Victor Kulikov, Yaki Bitterman, Zeev Melumian, and Ofir Bibi. LTX-Video: Realtime video latent diffusion.arXiv preprint arXiv:2501.00103, 2024
work page internal anchor Pith review arXiv 2024
-
[16]
Jonathan Ho, Tim Salimans, Alexey Gritsenko, William Chan, Mohammad Norouzi, and David J. Fleet. Video diffusion models. InNeurIPS, 2022
2022
-
[17]
Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-rank adaptation of large language models. InICLR, 2022
2022
-
[18]
Deep HDR video from sequences with alternating exposures
Nima Khademi Kalantari and Ravi Ramamoorthi. Deep HDR video from sequences with alternating exposures. InEurographics, 2019
2019
-
[19]
LuxDiT: Lighting estimation with video diffusion transformer
Zhihao Liang et al. LuxDiT: Lighting estimation with video diffusion transformer. InAdvances in Neural Information Processing Systems (NeurIPS), 2025
2025
-
[20]
GMNet: Learning gain map for inverse tone mapping
Jiyuan Liao et al. GMNet: Learning gain map for inverse tone mapping. InInternational Conference on Learning Representations (ICLR), 2025
2025
-
[21]
Mantiuk and Maliha Ashraf
Rafał K. Mantiuk and Maliha Ashraf. PU21: A novel perceptually uniform encoding for adapting existing quality metrics for HDR. InPicture Coding Symposium (PCS), 2021
2021
-
[22]
Rafał K. Mantiuk, Rajitha Weerakkody, Saverio Andriani, and Marta Mrak. HDR-VDP-3: A multi-metric for predicting image differences, quality and contrast distortions in high dynamic range and normal content.arXiv preprint arXiv:2304.13625, 2023. 10
-
[23]
Mantiuk, Aliaksei Chubarau, et al
Rafał K. Mantiuk, Aliaksei Chubarau, et al. ColorVideoVDP: A visual difference predictor for image, video and display distortions. InACM SIGGRAPH, 2024
2024
-
[24]
Ex- pandNet: A deep convolutional neural network for high dynamic range expansion from low dynamic range content.Computer Graphics F orum, 2018
Demetris Marnerides, Thomas Bashford-Rogers, Jonathan Hatchett, and Kurt Debattista. Ex- pandNet: A deep convolutional neural network for high dynamic range expansion from low dynamic range content.Computer Graphics F orum, 2018
2018
-
[25]
Deep HDR hallucination for inverse tone mapping.Sensors, 21(12):4032, 2021
Demetris Marnerides, Thomas Bashford-Rogers, and Kurt Debattista. Deep HDR hallucination for inverse tone mapping.Sensors, 21(12):4032, 2021
2021
-
[26]
Aliaksei Mikhailiuk, Maria Perez-Ortiz, Dingcheng Yue, Wilson Suen, and Rafał K. Mantiuk. Consolidated dataset and metrics for high-dynamic-range image quality.IEEE Transactions on Multimedia, 24:2125–2138, 2021
2021
-
[27]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InICCV, 2023
2023
-
[28]
Poly haven hdri library
Poly Haven. Poly haven hdri library. https://polyhaven.com/hdris, 2026. Accessed: 2026-04-13
2026
-
[29]
Photographic tone reproduc- tion for digital images
Erik Reinhard, Michael Stark, Peter Shirley, and James Ferwerda. Photographic tone reproduc- tion for digital images. InACM SIGGRAPH, pages 267–276, 2002
2002
-
[30]
Real-HDRV: A large-scale high-quality dataset for HDR video reconstruction
Hao Shu, Chenming Liu, Kai Zhong, Wenhao Wu, and Tong Lu. Real-HDRV: A large-scale high-quality dataset for HDR video reconstruction. InCVPR, 2024
2024
-
[31]
RoFormer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063, 2024
Jianlin Su, Yu Lu, Shengfeng Pan, Ahmed Murtadha, Bo Wen, and Yunfeng Liu. RoFormer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063, 2024
2024
-
[32]
Wan2.1: A comprehensive and multitask video foundation model.arXiv preprint, 2025
Ang Wang, Zhiyu Gao, Cong Chen, Teng Xiao, Di He, et al. Wan2.1: A comprehensive and multitask video foundation model.arXiv preprint, 2025
2025
-
[33]
GlowGAN: Unsupervised learning of HDR images from LDR images in the wild
Chao Wang, Ana Serrano, Xingang Pan, Dongdong Chen, Guillaume Gilet, Christian Theobalt, Karol Myszkowski, and Thomas Leimkühler. GlowGAN: Unsupervised learning of HDR images from LDR images in the wild. InICCV, 2023
2023
-
[34]
LEDiff: Latent exposure diffusion for HDR generation
Chao Wang, Ana Serrano, Xingang Pan, Karol Myszkowski, and Thomas Leimkühler. LEDiff: Latent exposure diffusion for HDR generation. InCVPR, 2025
2025
- [35]
-
[36]
HDRFlow: Real-time HDR video reconstruction with large motions
Gangwei Xu, Hao Ye, Xinyu Wang, Junda Liu, and Xin Xu. HDRFlow: Real-time HDR video reconstruction with large motions. InCVPR, 2024
2024
-
[37]
Dual frequency transformer for efficient SDR-to-HDR translation.Machine Intelligence Research, 2024
Jie Xu, Mingze Jiang, Mao Ye, and Yanwei Pang. Dual frequency transformer for efficient SDR-to-HDR translation.Machine Intelligence Research, 2024
2024
-
[38]
Toward high-quality HDR deghosting with conditional diffusion models.IEEE TCSVT, 2023
Qingsen Yan, Tao Hu, Yuan Sun, Hao Tang, Yu Zhu, Wei Dong, Luc Van Gool, and Yanning Zhang. Toward high-quality HDR deghosting with conditional diffusion models.IEEE TCSVT, 2023
2023
-
[39]
HDRev-Net: Event-guided high dynamic range video reconstruction
Yunhao Yang, Jin Ye, Jingye He, Conghui Wang, and Yizhen Han. HDRev-Net: Event-guided high dynamic range video reconstruction. InCVPR, 2023
2023
-
[40]
CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer
Zhuoyi Yang, Jiayan Teng, Wendi Zheng, Ming Ding, Shiyu Huang, Jiazheng Xu, Yuanming Yang, Wenyi Hong, Xiaohan Zhang, Guanyu Feng, et al. CogVideoX: Text-to-video diffusion models with an expert transformer.arXiv preprint arXiv:2408.06072, 2024
work page internal anchor Pith review arXiv 2024
-
[41]
Video inverse tone mapping with temporal clues
Hao Ye, Gangwei Xu, Xinyu Wang, Junda Liu, and Xin Xu. Video inverse tone mapping with temporal clues. InCVPR, 2024
2024
-
[42]
Yuhan Zhu, Yilun Guan, and Rafał K. Mantiuk. Zero-shot high dynamic range imaging via diffusion models. InCVPR, 2024. Highlight. 11
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.