Recognition: 2 theorem links
· Lean TheoremSingle-Shot HDR Recovery via a Video Diffusion Prior
Pith reviewed 2026-05-13 01:41 UTC · model grok-4.3
The pith
Single-shot HDR reconstruction works by generating an exposure video sequence from a diffusion model and fusing the frames.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
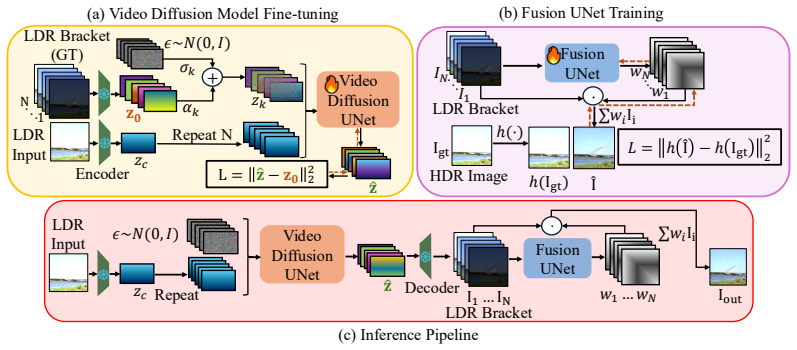
We address these limitations by re-casting single-shot HDR reconstruction as conditional video generation and fusing the generated frames into an HDR image. We finetune a video diffusion model to generate an exposure bracket, conditioned on a low dynamic range (LDR) input. We fuse this image bracket using per-pixel weights predicted by a light-weight UNet. This formulation is simple, interpretable, and effective. Rather than directly hallucinating an HDR image, it explicitly reconstructs the intermediate exposure stack and fuses it into the final output. Our method eliminates the need for separate models across exposure regimes and produces HDR reconstructions with high input fidelity. On量化性
What carries the argument
Conditional video diffusion model that generates an exposure bracket from an LDR input, followed by lightweight UNet fusion of per-pixel weights.
If this is right
- No separate models are required for different exposure regimes such as highlights and shadows.
- Reconstruction maintains higher fidelity to the original LDR input than direct prediction methods.
- Quantitative metrics on benchmarks exceed those of comparable generative baselines.
- Human raters prefer the outputs in 72 percent of pairwise comparisons.
- The same input-conditioned sequence generation and fusion extends to other tasks such as all-in-focus recovery from a defocused input.
Where Pith is reading between the lines
- The framework suggests video diffusion priors can supply consistent multi-frame outputs for any single-image inverse problem that benefits from explicit intermediate states.
- Similar conditioning and fusion could be tested on other image restoration tasks where generating a short sequence enforces physical or geometric consistency.
Load-bearing premise
Fine-tuning a video diffusion model on LDR inputs will produce an exposure bracket whose frames are consistent and accurate enough for a simple UNet to fuse them into high-fidelity HDR without new artifacts or lost detail.
What would settle it
A side-by-side test on standard HDR benchmarks where the generated frames show visible misalignment or detail loss and the final PSNR or SSIM falls below direct generative baselines of similar capacity.
Figures











read the original abstract
Recent generative methods for single-shot high dynamic range (HDR) image reconstruction show promising results, but often struggle with preserving fidelity to the input image. They require separate models to handle highlights and shadows, or sacrifice interpretability by directly predicting the final HDR image. We address these limitations by re-casting single-shot HDR reconstruction as conditional video generation and fusing the generated frames into an HDR image. We finetune a video diffusion model to generate an exposure bracket, conditioned on a low dynamic range (LDR) input. We fuse this image bracket using per-pixel weights predicted by a light-weight UNet. This formulation is simple, interpretable, and effective. Rather than directly hallucinating an HDR image, it explicitly reconstructs the intermediate exposure stack and fuses it into the final output. Our method eliminates the need for separate models across exposure regimes and produces HDR reconstructions with high input fidelity. On quantitative benchmarks, we outperform state-of-the-art generative baselines with comparable model capacity on several reconstruction metrics. Human evaluators further prefer our results in 72% of pairwise comparisons against existing methods. Finally, we show that this input-conditioned sequence generation and fusion framework extends beyond HDR to other image reconstruction tasks, such as all-in-focus image recovery from a single defocus-blurred input.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper re-casts single-shot HDR reconstruction as conditional video generation: a video diffusion model is fine-tuned to produce an exposure bracket conditioned on a single LDR input, after which a lightweight UNet predicts per-pixel fusion weights to recover the final HDR image. The approach is presented as simple and interpretable because it explicitly reconstructs the intermediate bracket rather than directly hallucinating HDR values. The manuscript reports quantitative outperformance over generative baselines of comparable capacity on several reconstruction metrics and states that human evaluators prefer the results in 72% of pairwise comparisons; it also claims the framework extends to other reconstruction tasks such as all-in-focus recovery.
Significance. If the generated brackets prove sufficiently consistent, the method supplies an interpretable route for transferring video diffusion priors to static multi-exposure problems without separate highlight/shadow models, while preserving input fidelity. The reported human preference and extension to other tasks would indicate practical utility beyond current generative HDR baselines.
major comments (3)
- [Method] Method section (exposure-bracket generation): the central assumption that fine-tuning a video diffusion model on LDR inputs yields frames differing only by exposure level and remaining scene-consistent is load-bearing, yet the manuscript provides no bracket-level consistency metrics (e.g., optical-flow error, feature-matching scores, or per-pixel variance across the generated stack) nor any ablation replacing the video prior with independent image diffusion.
- [Experiments] Experiments section: the claim of outperformance “on several reconstruction metrics” with “comparable model capacity” is stated without enumerating the exact metrics (PSNR, SSIM, HDR-VDP, etc.), the datasets, the precise baselines, or the capacity measurements, preventing verification that the quantitative superiority supports the central claim.
- [Experiments] Human evaluation: the 72% pairwise preference is reported without the number of evaluators, the protocol for selecting comparison pairs, or statistical significance testing, which is required to assess whether this result reliably corroborates the method’s advantage.
minor comments (2)
- [Abstract] The abstract refers to “several reconstruction metrics” without listing them; an explicit enumeration in the abstract or a table reference would improve clarity.
- [Method] Notation for the lightweight UNet fusion weights is introduced without an equation number or diagram; adding a simple equation or figure label would aid reproducibility.
Simulated Author's Rebuttal
We appreciate the referee's detailed review and constructive suggestions. Below, we provide point-by-point responses to the major comments and outline the revisions made to the manuscript.
read point-by-point responses
-
Referee: [Method] Method section (exposure-bracket generation): the central assumption that fine-tuning a video diffusion model on LDR inputs yields frames differing only by exposure level and remaining scene-consistent is load-bearing, yet the manuscript provides no bracket-level consistency metrics (e.g., optical-flow error, feature-matching scores, or per-pixel variance across the generated stack) nor any ablation replacing the video prior with independent image diffusion.
Authors: We concur that validating the scene consistency of the generated exposure brackets is essential for supporting the method's core premise. To address this, we have incorporated bracket-level consistency metrics into the revised manuscript, specifically reporting the average optical flow error between generated frames and the per-pixel standard deviation across the exposure stack. These additions demonstrate that the generated frames maintain high consistency, differing primarily in exposure levels. Additionally, we have included an ablation study comparing our video diffusion approach to independent image diffusion generations (using the same backbone but without temporal modeling), which shows a clear degradation in both consistency and final HDR quality, thereby justifying the use of the video prior. revision: yes
-
Referee: [Experiments] Experiments section: the claim of outperformance “on several reconstruction metrics” with “comparable model capacity” is stated without enumerating the exact metrics (PSNR, SSIM, HDR-VDP, etc.), the datasets, the precise baselines, or the capacity measurements, preventing verification that the quantitative superiority supports the central claim.
Authors: We regret the omission of these specifics in the initial submission, which indeed hinders verification. In the revised manuscript, we have detailed the exact metrics employed—PSNR, SSIM, HDR-VDP-2, and LPIPS—along with the evaluation datasets (HDR-Eye, the dataset from Kalantari et al., and a held-out test set from our training data). We also specify the baselines and capacity comparisons via parameter counts and inference FLOPs. These clarifications confirm that our approach achieves superior performance with comparable model capacity. revision: yes
-
Referee: [Experiments] Human evaluation: the 72% pairwise preference is reported without the number of evaluators, the protocol for selecting comparison pairs, or statistical significance testing, which is required to assess whether this result reliably corroborates the method’s advantage.
Authors: We acknowledge that additional details on the human study are necessary for proper assessment. The revised paper now specifies the number of evaluators, the protocol for selecting comparison pairs (random sampling from the test set with balanced conditions), and the results of statistical significance testing, confirming the reliability of the 72% preference rate. revision: yes
Circularity Check
No circularity: standard fine-tuning of video diffusion prior plus separate lightweight fusion network
full rationale
The paper's derivation consists of (1) re-casting HDR recovery as conditional video generation, (2) fine-tuning an off-the-shelf video diffusion model on LDR-to-exposure-bracket pairs, and (3) training a separate lightweight UNet to predict per-pixel fusion weights. None of these steps reduce to self-definition, fitted parameters renamed as predictions, or load-bearing self-citations. The central claims are empirical (quantitative metrics and human preference) and rest on the external video diffusion architecture plus the added fusion module; they are not forced by construction from the inputs or prior self-work. This is a conventional ML pipeline with no detectable circular reduction.
Axiom & Free-Parameter Ledger
free parameters (1)
- UNet fusion weights
axioms (1)
- domain assumption Video diffusion models, when conditioned on an LDR image, can generate a temporally consistent exposure bracket suitable for HDR fusion.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquationwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We fine-tune a video diffusion model to generate an exposure bracket, conditioned on a low dynamic range (LDR) input. We fuse this image bracket using per-pixel weights predicted by a light-weight UNet.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
FirstName Alpher , title =
-
[2]
Journal of Foo , volume = 13, number = 1, pages =
FirstName Alpher and FirstName Fotheringham-Smythe , title =. Journal of Foo , volume = 13, number = 1, pages =
-
[3]
Journal of Foo , volume = 14, number = 1, pages =
FirstName Alpher and FirstName Fotheringham-Smythe and FirstName Gamow , title =. Journal of Foo , volume = 14, number = 1, pages =
-
[4]
FirstName Alpher and FirstName Gamow , title =
-
[5]
Computer Vision -- ECCV 2022 , year =
work page 2022
-
[6]
In: Proceedings of the 24th Annual Conference on Computer Graphics and Interactive Techniques
Debevec, Paul E. and Malik, Jitendra , title =. Proceedings of the 24th Annual Conference on Computer Graphics and Interactive Techniques , pages =. 1997 , isbn =. doi:10.1145/258734.258884 , abstract =
-
[7]
15th Pacific Conference on Computer Graphics and Applications (PG'07) , pages=
Exposure fusion , author=. 15th Pacific Conference on Computer Graphics and Applications (PG'07) , pages=. 2007 , organization=
work page 2007
-
[8]
ACM transactions on graphics (TOG) , volume=
HDR image reconstruction from a single exposure using deep CNNs , author=. ACM transactions on graphics (TOG) , volume=. 2017 , publisher=
work page 2017
-
[9]
Computer graphics forum , volume=
Expandnet: A deep convolutional neural network for high dynamic range expansion from low dynamic range content , author=. Computer graphics forum , volume=. 2018 , organization=
work page 2018
-
[10]
High Dynamic Range Imaging , booktitle =
Mantiuk, Rafa. High Dynamic Range Imaging , booktitle =. doi:https://doi.org/10.1002/047134608X.W8265 , url =. https://onlinelibrary.wiley.com/doi/pdf/10.1002/047134608X.W8265 , year =
-
[11]
Advances in neural information processing systems , volume=
Improved distribution matching distillation for fast image synthesis , author=. Advances in neural information processing systems , volume=
-
[12]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Single-image HDR reconstruction by learning to reverse the camera pipeline , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[13]
Proceedings of the IEEE/CVF winter conference on applications of computer vision , pages=
Single-image hdr reconstruction by multi-exposure generation , author=. Proceedings of the IEEE/CVF winter conference on applications of computer vision , pages=
-
[14]
ACM Transactions on Graphics , volume=
Single-shot HDR using conventional image sensor shutter functions and optical randomization , author=. ACM Transactions on Graphics , volume=. 2025 , publisher=
work page 2025
-
[15]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Lediff: Latent exposure diffusion for hdr generation , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[16]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
UltraFusion: Ultra high dynamic imaging using exposure fusion , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[17]
arXiv preprint arXiv:2602.04814 , year=
X2HDR: HDR Image Generation in a Perceptually Uniform Space , author=. arXiv preprint arXiv:2602.04814 , year=
-
[18]
arXiv preprint arXiv:2510.07741 , year=
Ultraled: Learning to see everything in ultra-high dynamic range scenes , author=. arXiv preprint arXiv:2510.07741 , year=
-
[19]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Repurposing pre-trained video diffusion models for event-based video interpolation , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[20]
ACM Transactions on Graphics (TOG) , volume=
Generating the Past, Present and Future from a Motion-Blurred Image , author=. ACM Transactions on Graphics (TOG) , volume=. 2025 , publisher=
work page 2025
-
[21]
DiffHDR: Re-Exposing LDR Videos with Video Diffusion Models
DiffHDR: Re-Exposing LDR Videos with Video Diffusion Models , author=. arXiv preprint arXiv:2604.06161 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
International Conference on Medical image computing and computer-assisted intervention , pages=
U-net: Convolutional networks for biomedical image segmentation , author=. International Conference on Medical image computing and computer-assisted intervention , pages=. 2015 , organization=
work page 2015
-
[23]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Training neural networks on RAW and HDR images for restoration tasks , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[24]
Proceedings of the SIGGRAPH Asia 2025 Conference Papers , pages=
Learning to Refocus with Video Diffusion Models , author=. Proceedings of the SIGGRAPH Asia 2025 Conference Papers , pages=
work page 2025
- [25]
-
[26]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Attention-guided network for ghost-free high dynamic range imaging , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[27]
IEEE Transactions on Image Processing , volume=
HDR-GAN: HDR image reconstruction from multi-exposed LDR images with large motions , author=. IEEE Transactions on Image Processing , volume=. 2021 , publisher=
work page 2021
-
[28]
Advances in neural information processing systems , volume=
Elucidating the design space of diffusion-based generative models , author=. Advances in neural information processing systems , volume=
-
[29]
European Conference on computer vision , pages=
Ghost-free high dynamic range imaging with context-aware transformer , author=. European Conference on computer vision , pages=. 2022 , organization=
work page 2022
-
[30]
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
Stable video diffusion: Scaling latent video diffusion models to large datasets , author=. arXiv preprint arXiv:2311.15127 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[31]
Wan: Open and Advanced Large-Scale Video Generative Models
Wan: Open and advanced large-scale video generative models , author=. arXiv preprint arXiv:2503.20314 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[32]
HDR-VDP-3: A multi-metric for predicting image differences, quality and contrast distortions in high dynamic range and regular content , author=. arXiv preprint arXiv:2304.13625 , year=
-
[33]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Perceptual assessment and optimization of HDR image rendering , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[34]
Color and imaging conference , volume=
The HDR photographic survey , author=. Color and imaging conference , volume=. 2007 , organization=
work page 2007
-
[35]
Classifier-Free Diffusion Guidance
Classifier-free diffusion guidance , author=. arXiv preprint arXiv:2207.12598 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[36]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Rawhdr: High dynamic range image reconstruction from a single raw image , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[37]
ACM SIGGRAPH 2022 conference proceedings , pages=
Comparison of single image HDR reconstruction methods—the caveats of quality assessment , author=. ACM SIGGRAPH 2022 conference proceedings , pages=
work page 2022
-
[38]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Repurposing diffusion-based image generators for monocular depth estimation , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[39]
Computer Graphics Forum , volume=
Bracket diffusion: Hdr image generation by consistent ldr denoising , author=. Computer Graphics Forum , volume=. 2025 , organization=
work page 2025
-
[40]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
High-resolution image synthesis with latent diffusion models , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[41]
Silberman, Nathan and Hoiem, Derek and Kohli, Pushmeet and Fergus, Rob , title=. ECCV , year =
-
[42]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Gcc: Generative color constancy via diffusing a color checker , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[43]
Proceedings of the European Conference on Computer Vision (ECCV) , pages=
Deep High Dynamic Range Imaging with Large Foreground Motions , author=. Proceedings of the European Conference on Computer Vision (ECCV) , pages=
-
[44]
European Conference on Computer Vision (ECCV) , pages=
Ghost-free High Dynamic Range Imaging with Context-aware Transformer , author=. European Conference on Computer Vision (ECCV) , pages=. 2022 , organization=
work page 2022
-
[45]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Single image depth estimation trained via depth from defocus cues , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[46]
Journal of graphics tools , volume=
Parameter estimation for photographic tone reproduction , author=. Journal of graphics tools , volume=. 2002 , publisher=
work page 2002
-
[47]
Proceedings of the European Conference on Computer Vision (ECCV) , year=
SAFNet: Selective Alignment Fusion Network for Efficient HDR Imaging , author=. Proceedings of the European Conference on Computer Vision (ECCV) , year=
-
[48]
Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , year=
AFUNet: Cross-Iterative Alignment-Fusion Synergy for HDR Reconstruction via Deep Unfolding Paradigm , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , year=
-
[49]
Proceedings of the IEEE International Conference on Computer Vision (ICCV) , pages=
DeepFuse: A Deep Unsupervised Approach for Exposure Fusion with Extreme Exposure Image Pairs , author=. Proceedings of the IEEE International Conference on Computer Vision (ICCV) , pages=
-
[50]
Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , pages=
MEFLUT: Unsupervised 1D Lookup Tables for Multi-exposure Image Fusion , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , pages=
-
[51]
IEEE Transactions on Computational Imaging , volume=
Robust estimation of exposure ratios in multi-exposure image stacks , author=. IEEE Transactions on Computational Imaging , volume=. 2023 , publisher=
work page 2023
-
[52]
ACM SIGGRAPH Computer Graphics , volume=
A lens and aperture camera model for synthetic image generation , author=. ACM SIGGRAPH Computer Graphics , volume=. 1981 , publisher=
work page 1981
-
[53]
HDR Video Generation via Latent Alignment with Logarithmic Encoding
HDR Video Generation via Latent Alignment with Logarithmic Encoding , author=. arXiv preprint arXiv:2604.11788 , year=
work page internal anchor Pith review Pith/arXiv arXiv
- [54]
-
[55]
Vision system with high dynamic range for optical surface defect inspection , volume =
Zhaolou Cao and Fenping Cui and Chunjie Zhai , journal =. Vision system with high dynamic range for optical surface defect inspection , volume =. 2018 , url =
work page 2018
-
[56]
Proceedings IEEE Conference on Computer Vision and Pattern Recognition
High dynamic range imaging: Spatially varying pixel exposures , author=. Proceedings IEEE Conference on Computer Vision and Pattern Recognition. CVPR 2000 (Cat. No. PR00662) , volume=. 2000 , organization=
work page 2000
-
[57]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Deep optics for single-shot high-dynamic-range imaging , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[58]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Learning rank-1 diffractive optics for single-shot high dynamic range imaging , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[59]
ACM Transactions on Graphics (TOG) , volume=
Split-aperture 2-in-1 computational cameras , author=. ACM Transactions on Graphics (TOG) , volume=. 2024 , publisher=
work page 2024
-
[60]
2022 IEEE International Conference on Computational Photography (ICCP) , pages=
Mantissacam: Learning snapshot high-dynamic-range imaging with perceptually-based in-pixel irradiance encoding , author=. 2022 IEEE International Conference on Computational Photography (ICCP) , pages=. 2022 , organization=
work page 2022
- [61]
-
[62]
a talk at the Stanford Artificial Project in , volume=
A 3x3 isotropic gradient operator for image processing , author=. a talk at the Stanford Artificial Project in , volume=
-
[63]
CoRR abs/2004.07728(2020),https://arxiv.org/abs/ 2004.07728
Keyan Ding and Kede Ma and Shiqi Wang and Eero P. Simoncelli , title =. CoRR , volume =. 2020 , url =. 2004.07728 , timestamp =
-
[64]
IEEE Transactions on Image processing , volume=
Image fusion with guided filtering , author=. IEEE Transactions on Image processing , volume=. 2013 , publisher=
work page 2013
-
[65]
IEEE Transactions on Image Processing , volume=
Robust all-in-focus super-resolution for focal stack photography , author=. IEEE Transactions on Image Processing , volume=. 2016 , publisher=
work page 2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.