Recognition: unknown
A Mechanistic Analysis of Looped Reasoning Language Models
Pith reviewed 2026-05-10 15:50 UTC · model grok-4.3
The pith
Looped language models repeat the same inference stages as feedforward models inside each recurrent cycle.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Recurrent blocks learn stages of inference that closely mirror those of feedforward models, repeating these stages in depth with each iteration. For many studied models, each layer in the cycle converges to a distinct fixed point, so the recurrent block follows a consistent cyclic trajectory in the latent space. As these fixed points are reached, attention-head behavior stabilizes and produces constant behavior across recurrences.
What carries the argument
Cyclic recurrence of latent states, in which each layer converges to its own fixed point and produces a stable repeating trajectory.
If this is right
- Larger recurrent blocks tend to produce more stable fixed points and clearer cyclic trajectories.
- Input injection and normalization choices control how quickly and reliably the fixed points emerge.
- Once attention stabilizes, the model applies the same reasoning steps on every loop iteration.
- These dynamics offer practical rules for choosing loop depth and architectural details in new models.
Where Pith is reading between the lines
- The mirroring effect implies that adding more loop iterations could increase reasoning depth without enlarging the underlying model.
- Disrupting the fixed-point convergence might serve as a test for whether a looped model truly benefits from recurrence.
- The same cyclic structure could appear in other recurrent designs outside language models, offering a general principle for iterative computation.
Load-bearing premise
The convergence to distinct per-layer fixed points and the stabilization of attention are general properties of looped architectures rather than artifacts of the specific models or training procedures studied.
What would settle it
Train a looped model with a different block size or normalization scheme and check whether the per-layer fixed points and mirroring of feedforward stages still appear in the latent trajectories.
Figures






















































read the original abstract
Reasoning has become a central capability in large language models. Recent research has shown that reasoning performance can be improved by looping an LLM's layers in the latent dimension, resulting in looped reasoning language models. Despite promising results, few works have investigated how their internal dynamics differ from those of standard feedforward models. In this paper, we conduct a mechanistic analysis of the latent states in looped language models, focusing in particular on how the stages of inference observed in feedforward models compare to those observed in looped ones. To this end, we analyze cyclic recurrence and show that for many of the studied models each layer in the cycle converges to a distinct fixed point; consequently, the recurrent block follows a consistent cyclic trajectory in the latent space. We provide evidence that as these fixed points are reached, attention-head behavior stabilizes, leading to constant behavior across recurrences. Empirically, we discover that recurrent blocks learn stages of inference that closely mirror those of feedforward models, repeating these stages in depth with each iteration. We study how recurrent block size, input injection, and normalization influence the emergence and stability of these cyclic fixed points. We believe these findings help translate mechanistic insights into practical guidance for architectural design.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper conducts a mechanistic analysis of looped reasoning language models, showing that recurrent blocks converge to distinct per-layer fixed points in latent space, producing consistent cyclic trajectories. Attention-head behavior stabilizes upon reaching these points, and the blocks learn inference stages that mirror those in feedforward models, repeating the stages across iterations. The work includes ablations examining the effects of recurrent block size, input injection, and normalization on fixed-point emergence and stability.
Significance. If the empirical observations hold, the results offer concrete mechanistic understanding of why looped architectures improve reasoning performance and supply practical guidance for architectural choices. The paper earns credit for grounding claims in direct measurements of latent trajectories and attention patterns rather than indirect performance metrics, along with targeted ablations that test sensitivity to block size and normalization.
major comments (2)
- [§4] §4 (latent trajectory analysis): the assertion that recurrent blocks 'closely mirror' feedforward inference stages requires an explicit quantitative metric (e.g., layer-wise activation similarity or stage-transition clustering) and reporting of variance across seeds; without it the mirroring claim rests on qualitative description and cannot be evaluated for robustness.
- [§5.2] §5.2 (ablations on block size and normalization): while the experiments show influence on fixed-point stability, the paper does not report statistical tests (e.g., t-tests or bootstrap confidence intervals) comparing convergence rates across conditions, leaving open whether observed differences are reliable or could be artifacts of the specific training runs examined.
minor comments (2)
- [Abstract] Abstract: the phrase 'for many of the studied models' should be accompanied by the exact count and identities of models examined to allow readers to assess scope.
- [Figures] Figure captions (e.g., those showing cyclic trajectories): add explicit labels for iteration count and fixed-point convergence threshold so that the stabilization behavior is immediately interpretable without cross-referencing the main text.
Simulated Author's Rebuttal
We thank the referee for the positive assessment and recommendation for minor revision. We address the major comments point by point below.
read point-by-point responses
-
Referee: [§4] §4 (latent trajectory analysis): the assertion that recurrent blocks 'closely mirror' feedforward inference stages requires an explicit quantitative metric (e.g., layer-wise activation similarity or stage-transition clustering) and reporting of variance across seeds; without it the mirroring claim rests on qualitative description and cannot be evaluated for robustness.
Authors: We agree that a quantitative metric would make the mirroring claim more robust and reproducible. In the revised manuscript we will add a layer-wise cosine similarity metric between the fixed-point activations of each recurrent block and the corresponding layers of the feedforward baseline, together with standard deviations computed across five independent random seeds. We will also include a simple stage-transition clustering analysis based on k-means on the activation trajectories to quantify how consistently the inference stages repeat. revision: yes
-
Referee: [§5.2] §5.2 (ablations on block size and normalization): while the experiments show influence on fixed-point stability, the paper does not report statistical tests (e.g., t-tests or bootstrap confidence intervals) comparing convergence rates across conditions, leaving open whether observed differences are reliable or could be artifacts of the specific training runs examined.
Authors: We acknowledge that statistical quantification would strengthen the ablation results. In the revision we will report bootstrap confidence intervals (1,000 resamples) for the convergence rates and fixed-point stability metrics across block sizes and normalization variants, computed from five independent training runs per condition. revision: yes
Circularity Check
No significant circularity: claims rest on direct empirical measurements of activations and fixed-point convergence
full rationale
The paper's central claims—that recurrent blocks converge to per-layer fixed points, stabilize attention, and mirror feedforward inference stages—are supported by direct latent-state analysis, ablations on block size/input injection/normalization, and observation of cyclic trajectories. No equations define a quantity in terms of itself, no fitted parameters are relabeled as predictions, and no load-bearing steps reduce to self-citations or imported uniqueness theorems. The derivation chain consists of measurements on trained models rather than tautological redefinitions, making the analysis self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 3 Pith papers
-
SMolLM: Small Language Models Learn Small Molecular Grammar
A 53K-parameter model generates 95% valid SMILES on ZINC-250K, outperforming larger models, by resolving chemical constraints in fixed order: brackets first, rings second, valence last.
-
Memory-Efficient Looped Transformer: Decoupling Compute from Memory in Looped Language Models
MELT decouples reasoning depth from memory in looped LLMs by sharing a single gated KV cache per layer and using two-phase chunk-wise distillation from Ouro, delivering constant memory use while matching or beating st...
-
Hyperloop Transformers
Hyperloop Transformers outperform standard and mHC Transformers with roughly 50% fewer parameters by looping a middle block of layers and applying hyper-connections only after each loop.
Reference graph
Works this paper leans on
-
[1]
Alon, U. and Yahav, E. On the bottleneck of graph neural networks and its practical implications. arXiv preprint arXiv:2006.05205,
-
[2]
Arroyo, ´A., Gravina, A., Gutteridge, B., Barbero, F., Gal- licchio, C., Dong, X., Bronstein, M., and Vandergheynst, P. On vanishing gradients, over-smoothing, and over- squashing in gnns: Bridging recurrent and graph learning. arXiv preprint arXiv:2502.10818,
-
[3]
Mixture-of-recursions: Learning dynamic recursive depths for adaptive token-level computation
ISSN 2835-8856. Bae, S., Kim, Y ., Bayat, R., Kim, S., Ha, J., Schuster, T., Fisch, A., Harutyunyan, H., Ji, Z., Courville, A., et al. Mixture-of-recursions: Learning dynamic recur- sive depths for adaptive token-level computation. arXiv preprint arXiv:2507.10524,
-
[4]
Banino, A., Balaguer, J., and Blundell, C. Pondernet: Learn- ing to ponder. arXiv preprint arXiv:2107.05407,
-
[5]
Bronstein and Petar Velickovic and Razvan Pascanu , title =
Barbero, F., Arroyo, A., Gu, X., Perivolaropoulos, C., Bron- stein, M., Veliˇckovi´c, P., and Pascanu, R. Why do llms at- tend to the first token? arXiv preprint arXiv:2504.02732,
- [6]
-
[7]
Cai, C. and Wang, Y . A note on over-smoothing for graph neural networks. arXiv preprint arXiv:2006.13318,
-
[8]
Training Verifiers to Solve Math Word Problems
Cobbe, K., Kosaraju, V ., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., Hesse, C., and Schulman, J. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Darlow, L., Regan, C., Risi, S., Seely, J., and Jones, L. Continuous thought machines. arXiv preprint arXiv:2505.05522,
-
[10]
Dehghani, M., Gouws, S., Vinyals, O., Uszkoreit, J., and Kaiser, Ł. Universal transformers. arXiv preprint arXiv:1807.03819,
work page internal anchor Pith review arXiv
-
[11]
Scaling up Test-Time Compute with Latent Reasoning: A Recurrent Depth Approach
Geiping, J., McLeish, S., Jain, N., Kirchenbauer, J., Singh, S., Bartoldson, B. R., Kailkhura, B., Bhatele, A., and Goldstein, T. Scaling up test-time compute with latent reasoning: A recurrent depth approach. arXiv preprint arXiv:2502.05171,
work page internal anchor Pith review arXiv
-
[12]
Adaptive Computation Time for Recurrent Neural Networks
Graves, A. Adaptive computation time for recurrent neural networks. arXiv preprint arXiv:1603.08983,
work page internal anchor Pith review arXiv
-
[13]
When attention sink emerges in language models: An empirical view.arXiv preprint arXiv:2410.10781,
9 A Mechanistic Analysis of Looped Language Models Gu, X., Pang, T., Du, C., Liu, Q., Zhang, F., Du, C., Wang, Y ., and Lin, M. When attention sink emerges in language models: An empirical view. arXiv preprint arXiv:2410.10781,
-
[14]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Guo, D., Yang, D., Zhang, H., Song, J., Zhang, R., Xu, R., Zhu, Q., Ma, S., Wang, P., Bi, X., et al. Deepseek-r1: In- centivizing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
ISSN 2835-8856. Hariri, A., Arroyo, ´A., Gravina, A., Eliasof, M., Sch¨onlieb, C.-B., Bacciu, D., Azizzadenesheli, K., Dong, X., and Vandergheynst, P. Return of chebnet: Understanding and improving an overlooked gnn on long range tasks. arXiv preprint arXiv:2506.07624,
-
[16]
Less is More: Recursive Reasoning with Tiny Networks
Jolicoeur-Martineau, A. Less is more: Recursive reasoning with tiny networks. arXiv preprint arXiv:2510.04871 ,
work page internal anchor Pith review arXiv
-
[17]
Ke, Y ., Li, X., Liang, Y ., Shi, Z., and Song, Z
URL https://github.com/karpathy/ nanochat. Ke, Y ., Li, X., Liang, Y ., Shi, Z., and Song, Z. Advancing the understanding of fixed point iterations in deep neural networks: A detailed analytical study. arXiv preprint arXiv:2410.11279,
-
[18]
Koishekenov, Y ., Lipani, A., and Cancedda, N. Encode, think, decode: Scaling test-time reasoning with recursive latent thoughts. arXiv preprint arXiv:2510.07358,
-
[19]
arXiv preprint arXiv:2406.19384 , year=
Lad, V ., Lee, J. H., Gurnee, W., and Tegmark, M. The re- markable robustness of llms: Stages of inference? arXiv preprint arXiv:2406.19384,
-
[20]
arXiv preprint arXiv:2507.02199 , year=
Lu, W., Yang, Y ., Lee, K., Li, Y ., and Liu, E. Latent chain- of-thought? decoding the depth-recurrent transformer. arXiv preprint arXiv:2507.02199,
-
[21]
Bartoldson, Bhavya Kailkhura, Avi Schwarzschild, Jonas Geiping, Tom Goldstein, and Micah Goldblum
McLeish, S., Li, A., Kirchenbauer, J., Kalra, D. S., Bartold- son, B. R., Kailkhura, B., Schwarzschild, A., Geiping, J., Goldstein, T., and Goldblum, M. Teaching pretrained lan- guage models to think deeper with retrofitted recurrence. arXiv preprint arXiv:2511.07384,
-
[22]
Softmax is 1/2-lipschitz: A tight bound across all ℓ𝑝 norms
Nair, P. Softmax is 1/2-lipschitz: A tight bound across all ℓ𝑝 norms. arXiv preprint arXiv:2510.23012,
-
[23]
Two-scale latent dynamics for recurrent-depth transformers.arXiv preprint arXiv:2509.23314,
Pappone, F., Crisostomi, D., and Rodol `a, E. Two-scale latent dynamics for recurrent-depth transformers. arXiv preprint arXiv:2509.23314,
-
[24]
Queipo-de Llano, E., Arroyo, ´A., Barbero, F., Dong, X., Bronstein, M., LeCun, Y ., and Shwartz-Ziv, R. Attention sinks and compression valleys in llms are two sides of the same coin. arXiv preprint arXiv:2510.06477,
-
[25]
Using attention sinks to identify and evaluate dormant heads in pretrained llms
Sandoval-Segura, P., Wang, X., Panda, A., Goldblum, M., Basri, R., Goldstein, T., and Jacobs, D. Using attention sinks to identify and evaluate dormant heads in pretrained llms. arXiv preprint arXiv:2504.03889,
- [26]
-
[27]
Tan, S., Shen, Y ., Chen, Z., Courville, A., and Gan, C. Sparse universal transformer. arXiv preprint arXiv:2310.07096,
-
[28]
Softmax is not enough (for sharp size generali- sation)
Veliˇckovi´c, P., Perivolaropoulos, C., Barbero, F., and Pas- canu, R. Softmax is not enough (for sharp size generali- sation). arXiv preprint arXiv:2410.01104,
-
[29]
Wang, G., Li, J., Sun, Y ., Chen, X., Liu, C., Wu, Y ., Lu, M., Song, S., and Yadkori, Y . A. Hierarchical reasoning model. arXiv preprint arXiv:2506.21734,
work page internal anchor Pith review arXiv
-
[30]
Efficient Streaming Language Models with Attention Sinks
Xiao, G., Tian, Y ., Chen, B., Han, S., and Lewis, M. Ef- ficient streaming language models with attention sinks. arXiv preprint arXiv:2309.17453,
work page internal anchor Pith review arXiv
-
[31]
Xu, K. and Sato, I. On expressive power of looped transformers: Theoretical analysis and enhancement via timestep encoding. arXiv preprint arXiv:2410.01405 ,
-
[32]
Looped transformers are better at learning learning algorithms
Yang, L., Lee, K., Nowak, R., and Papailiopoulos, D. Looped transformers are better at learning learning al- gorithms. arXiv preprint arXiv:2311.12424,
-
[33]
Pay attention to attention distribution: A new lo- cal lipschitz bound for transformers
Yudin, N., Gaponov, A., Kudriashov, S., and Rakhuba, M. Pay attention to attention distribution: A new lo- cal lipschitz bound for transformers. arXiv preprint arXiv:2507.07814,
-
[34]
Scaling Latent Reasoning via Looped Language Models
Zhu, R.-J., Wang, Z., Hua, K., Zhang, T., Li, Z., Que, H., Wei, B., Wen, Z., Yin, F., Xing, H., et al. Scaling latent reasoning via looped language models. arXiv preprint arXiv:2510.25741,
work page internal anchor Pith review arXiv
-
[35]
B 𝑓 𝑗+1 (0) (Y )
Therefore B 𝑓 𝑗+1 (𝑘−1) (B 𝑓 𝑗+1 (𝑘−2) (. . . B 𝑓 𝑗+1 (0) (Y ) . . . )) = B 𝑓 𝑗 (𝑘 ) (B 𝑓 𝑗 (𝑘−1) (. . . B 𝑓 𝑗 (1) (Y ) . . . )) (9) = B 𝑓 𝑗 (0) (B 𝑓 𝑗 (𝑘−1) (. . . B 𝑓 𝑗 (1) (Y ) . . . )) (10) Now take Eq. (8) and apply B 𝑓 𝑗 (0) to both sides, defining a new fixed pointZ ′′ = B 𝑓 𝑗 (0) (Z ′): B 𝑓 𝑗 (0) (B 𝑓 𝑗 (𝑘−1) (B 𝑓 𝑗 (𝑘−2) (. . . B 𝑓 𝑗 (0) (Z ′) . ...
2025
-
[36]
Hello! I’ve been well. I hope that you’re doing well
dataset. A few illustrative plots (for example, latent space trajectories) are instead produced with a test sequence that we obtain from Barbero et al. (2025): “Hello! I’ve been well. I hope that you’re doing well.” Additional results targetting non-reasoning behavior using the HellaSwag dataset (following an identical setup of running inference on the sa...
2025
-
[37]
Our small training runs in Sec
We use standard settings for the tokenizers of each model, and as such some models prepend a BOS token whereas others do not: we make this clear in the ‘Prepends BOS’ column of the same table. Our small training runs in Sec. 5.1 are performed by adapting a publicly available fork of Nanochat (Karpathy, 2025), https://github.com/TrelisResearch/nanochat/tre...
2025
-
[38]
and train for 3.7B tokens. As discussed in the main text, loss is the same as that of a regular feedforward model: cross entropy loss on the final output representation (as opposed to the summed loss of Zhu et al. (2025)). Each model is trained for a constant 4 recurrences (as opposed to the Poisson sampling of Geiping et al. (2025)). All models use pre-n...
2025
-
[39]
orbits” and “sliders
Additional Huggingface details on pretrained Looped models used. C. Non-Fixed-Point Limiting Behavior C.1. How Frequent is Non-Fixed-Point Behavior? In this section we investigate more closely the “orbits” and “sliders” initially observed by Geiping et al. (2025). These are important as they appear to represent stable limiting behavior that are not fixed ...
2025
-
[40]
Using this algorithm, we classify the limiting behavior over all tokens in the GSM8k test set for the Huginn-0125 and Retrofitted Llama models
We set threshold 15 A Mechanistic Analysis of Looped Language Models 𝜏 = 0.05 and fixed-point fraction 𝜌 = 0.9. Using this algorithm, we classify the limiting behavior over all tokens in the GSM8k test set for the Huginn-0125 and Retrofitted Llama models. We discover that the system prompt used before presenting the GSM8k question has a large impact on th...
2025
-
[41]
This percentage can be significantly increased with the longer system prompt, but these behaviors remain rare at 0.14%
These results reveal that these non-fixed-point limiting behaviors appear to be extremely rare in practice: without a system prompt (the setting used throughout this paper) only approximately 0.02% of tokens exhibit non-fixed-point behavior. This percentage can be significantly increased with the longer system prompt, but these behaviors remain rare at 0....
2025
-
[42]
Long Persona
The input sequence (cosine similarities for the residual streams of a given token and layer and successive recursions, as compared to their final residual stream) is visualized in the leftmost column. The center column visualizes the effect of windowing and de-trending, and the rightmost column shows the FFT magnitudes. The top row visualizes the detected...
2025
-
[43]
worst case
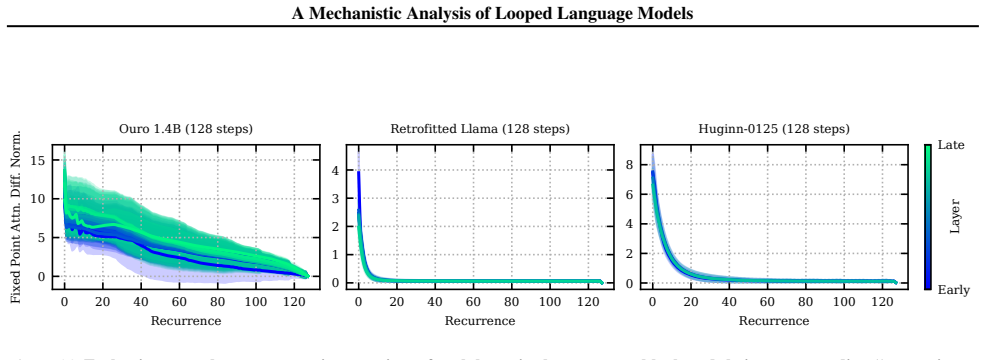
PCA trajectories in the intermediate layers of Huginn-0125: this reproduces the leftmost column of Fig. 16 in Geiping et al. (2025) (the first two principal components) and additionally plots the latent trajectories for the intermediate layers in the recurrent block. 20 A Mechanistic Analysis of Looped Language Models C.3. How Does Non-Fixed-Point Behavio...
2025
-
[44]
Left: Ouro 1.4B (Zhu et al., 2025)
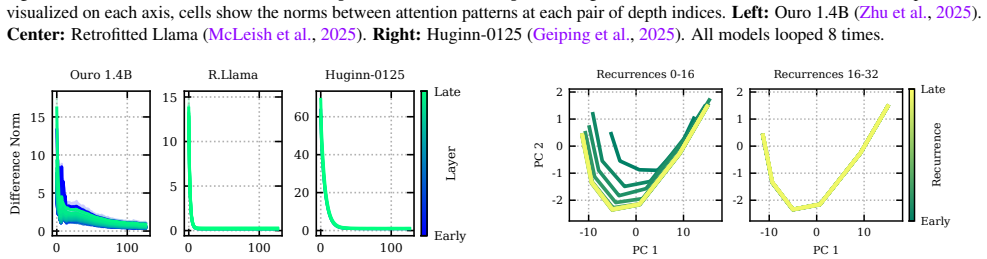
Cosine similarity between residual streams after every pair of layers for different Transformer models, averaged across the batch and sequence dimensions. Left: Ouro 1.4B (Zhu et al., 2025). Center: Retrofitted Llama (McLeish et al., 2025). Right: Huginn-0125 (Geiping et al., 2025). All models looped 8 times. Diagonal patterns indicate that the residual s...
2025
-
[45]
Left: Huginn-0125 (Geiping et al., 2025)
Cosine similarity between residual streams after every pair of layers for different Transformer models, averaged across the batch and sequence dimensions. Left: Huginn-0125 (Geiping et al., 2025). Center Left: Retrofitted Llama. Center Right: Retrofitted OLMo. Right: Retrofitted TinyLlama (McLeish et al., 2025). All models looped 32 times. Extended version of Fig
2025
-
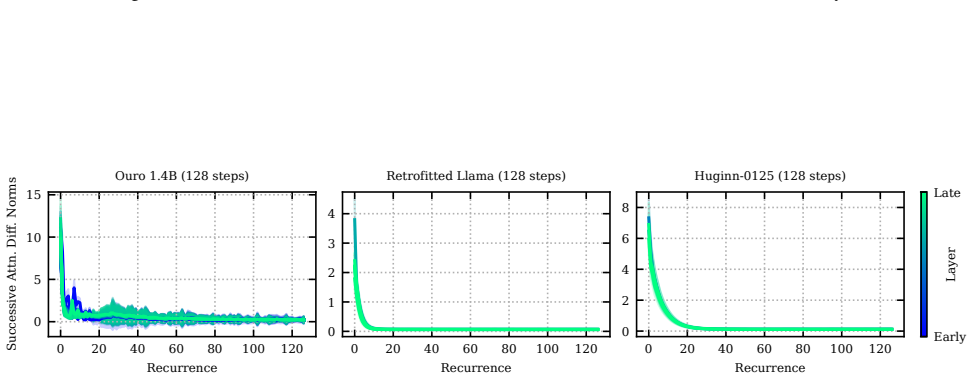
[46]
Left: Huginn-0125 (Geiping et al., 2025)
Frobenius norm between attention matrices for different Transformer models, averaged across the batch and head dimensions. Left: Huginn-0125 (Geiping et al., 2025). Center Left: Retrofitted Llama. Center Right: Retrofitted OLMo. Right: Retrofitted TinyLlama (McLeish et al., 2025). All models looped 32 times. Extended version of Fig
2025
-
[47]
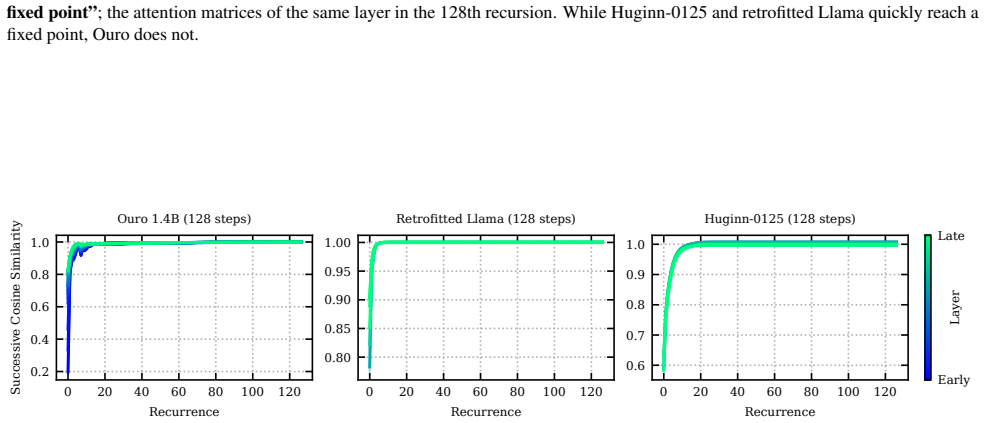
approximate fixed point
Cosine similarity between the residual stream after the first layer in the recurrent block for successive recurrences and an “approximate fixed point” – the residual stream in the 128th recurrence. Two fixed point differences are visualized: the difference to the fixed point of the same (first) layer (blue) and the difference to the fixed point which has ...
2024
-
[48]
Fraction of prediction and suppression neurons in a selection of looped models used throughout the paper. E.2. Input Dependent Metrics One well-studied phenomenon by which Transformers drastically reduce the mixing in given layer is that of the attention sink (Xiao et al., 2023; Barbero et al., 2025), whereby the layer focuses the majority of the attentio...
2023
-
[49]
Stages of inference for a selection of Looped transformers, all using 8 recurrences: Huginn-0125 (Geiping et al., 2025), Ouro 1.4B (Zhu et al.,
2025
-
[50]
Note Huginn-0125 and Retrofitted Llama have prelude and coda layers too: each 2 layers in Huginn-0125 and each 4 in Retrofitted Llama
and Llama with retrofitted recurrences (McLeish et al., 2025). Note Huginn-0125 and Retrofitted Llama have prelude and coda layers too: each 2 layers in Huginn-0125 and each 4 in Retrofitted Llama. For completeness, we plot these stages of inference for all other models referenced in the paper. See Fig. 35 (Ouro 1.4B), Fig. 36 (Huginn-0125), Figs. 37 to 3...
2025
-
[51]
upcycles
This model is interesting due to the training regime followed by Zhu et al. (2025), which “upcycles” a 48 layer model from the 24 layer 1.4B parameter model. As a consequence, the first and second half of each recurrent block each independently align with the Llama feedforward stages of inference. In Sec. 5 we suggested that the lack of stages of inferenc...
2025
-
[52]
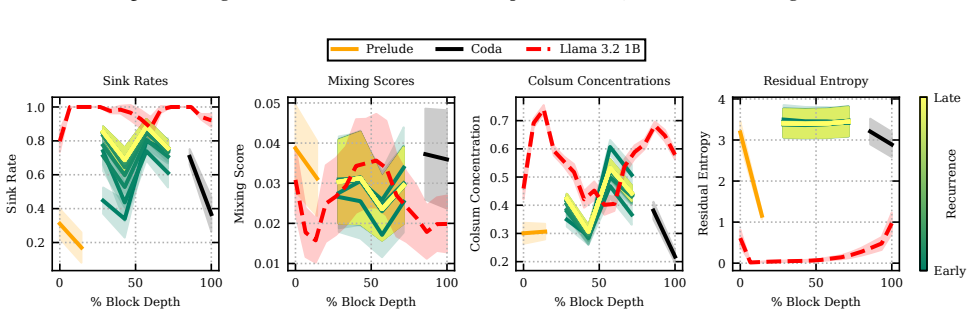
Stages of inference for each recurrent loop in the retrofitted Llama model (McLeish et al., 2025).Each block demonstrates very similar stages of inference to Llama, the base model from which pretrained layers are taken. 0 50 100 % Block Depth 0.0 0.2 0.4 0.6 0.8 1.0 Sink Rate Sink Rates 0 50 100 % Block Depth 0.010 0.015 0.020 Mixing Score Mixing Scores 0...
2025
-
[53]
Similarly, each block demonstrates very similar stages of inference to OLMo, the base model from which pretrained layers are taken
Stages of inference for each recurrent loop in the retrofitted OLMo model (McLeish et al., 2025). Similarly, each block demonstrates very similar stages of inference to OLMo, the base model from which pretrained layers are taken. 30 A Mechanistic Analysis of Looped Language Models 0 50 100 % Block Depth 0.0 0.2 0.4 0.6 0.8 1.0 Sink Rate Sink Rates 0 50 10...
2025
-
[54]
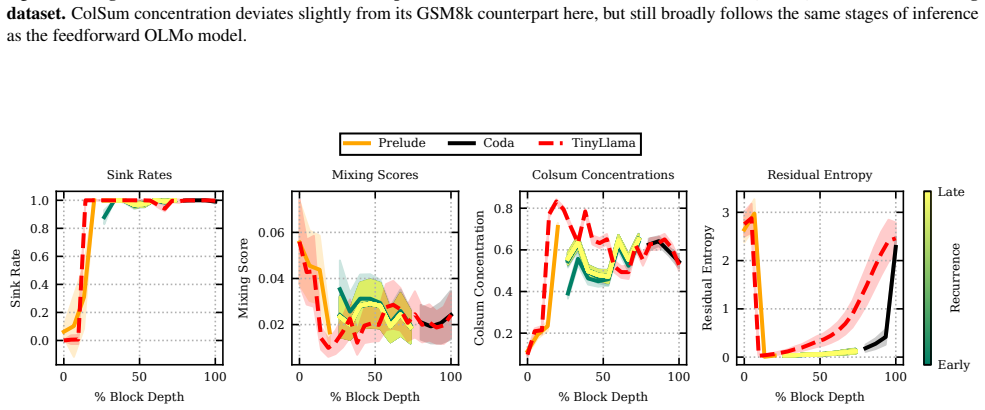
Stages of inference for each recurrent loop in the retrofitted TinyLlama model (McLeish et al., 2025).Similarly, each block demonstrates very similar stages of inference to TinyLlama, the base model from which pretrained layers are taken. 0 20 40 60 80 100 % Recurrent Depth 0.0 0.2 0.4 0.6 0.8 1.0 Sink Rate 0 20 40 60 80 100 % Recurrent Depth 0.0025 0.005...
2025
-
[55]
upcycles
Stages of inference for each recurrent loop in Ouro 2.6B.For this model we separate out the first and second half of the recurrent block and overlay them, demonstrating that both halves have close alignment with the Llama feedforward stages of inference. We suggest that this likely arises due to the training regime of Zhu et al. (2025), which first trains...
2025
-
[56]
31 A Mechanistic Analysis of Looped Language Models E.4
Stages of inference for each recurrent loop in Retrofitted Llama for which the massive activations have been ablated. 31 A Mechanistic Analysis of Looped Language Models E.4. Non-Reasoning Stages of Inference Throughout the rest of the paper, experiments are conducted on the GSM8k dataset. In this appendix we verify that the stages of inference we observe...
2019
-
[57]
Stages of inference for each recurrent loop in the retrofitted Llama model (McLeish et al., 2025), run on the HellaSwag dataset. 0 50 100 % Block Depth 0.0 0.2 0.4 0.6 0.8 1.0 Sink Rate Sink Rates 0 50 100 % Block Depth 0.02 0.03 0.04 0.05 0.06 Mixing Score Mixing Scores 0 50 100 % Block Depth 0.1 0.2 0.3 0.4 0.5 0.6 0.7 Colsum Concentration Colsum Concen...
2025
-
[58]
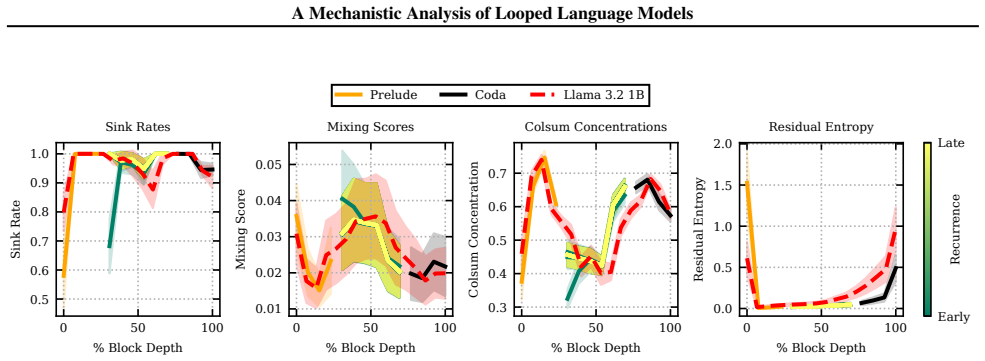
ColSum concentration deviates slightly from its GSM8k counterpart here, but still broadly follows the same stages of inference as the feedforward OLMo model
Stages of inference for each recurrent loop in the retrofitted OLMo model (McLeish et al., 2025), run on the HellaSwag dataset. ColSum concentration deviates slightly from its GSM8k counterpart here, but still broadly follows the same stages of inference as the feedforward OLMo model. 0 50 100 % Block Depth 0.0 0.2 0.4 0.6 0.8 1.0 Sink Rate Sink Rates 0 5...
2025
-
[59]
33 A Mechanistic Analysis of Looped Language Models E.5
Stages of inference for each recurrent loop in the retrofitted TinyLlama model (McLeish et al., 2025), run on the HellaSwag dataset. 33 A Mechanistic Analysis of Looped Language Models E.5. Stability To Unseen Test-Time Recurrences This section extends the results presented in Sec. 5.2. We supplement Fig. 11 by plotting how stages of inference change per-...
2025
-
[60]
The large standard deviations in Huginn-0125 and retrofitted Llama mixing scores reflect the fact that these models tend to reach different, but still stable, constant states. 0 1000 2000 3000 Recurrent Position 0.00 0.25 0.50 0.75 1.00 Sink Rate 0 1000 2000 3000 Recurrent Position 0.005 0.010 0.015 0.020 Mixing Score 0 1000 2000 3000 Recurrent Position 0...
2000
-
[61]
These consistently change throughout the realized depth of the model, reaching no clear fixed point
Stages of inference for each of the distinct blocks in Ouro (Zhu et al., 2025), as they are reapplied throughout the model for 128 recurrences. These consistently change throughout the realized depth of the model, reaching no clear fixed point. Mean and standard deviation are over separate inputs to the model, taken over the GSM8k subset. 0 200 400 Recurr...
2025
-
[62]
These converge to constant behavior
Stages of inference for each of the distinct blocks in Huginn-0125 (Geiping et al., 2025), as they are reapplied throughout the model for 128 recurrences. These converge to constant behavior. Mean and standard deviation are over separate inputs to the model, taken over the GSM8k subset. 0 250 500 750 Recurrent Position 0.5 0.6 0.7 0.8 0.9 1.0 Sink Rate 0 ...
2025
-
[63]
These converge to constant behavior
Stages of inference for each of the distinct blocks in retrofitted Llama (McLeish et al., 2025), as they are reapplied throughout the model for 128 recurrences. These converge to constant behavior. Mean and standard deviation are over separate inputs to the model, taken over the GSM8k subset. We additionally plot the extended versions of Fig. 12 in Figs. 50 to
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.