Recognition: unknown
SMolLM: Small Language Models Learn Small Molecular Grammar
Pith reviewed 2026-05-08 12:54 UTC · model grok-4.3
The pith
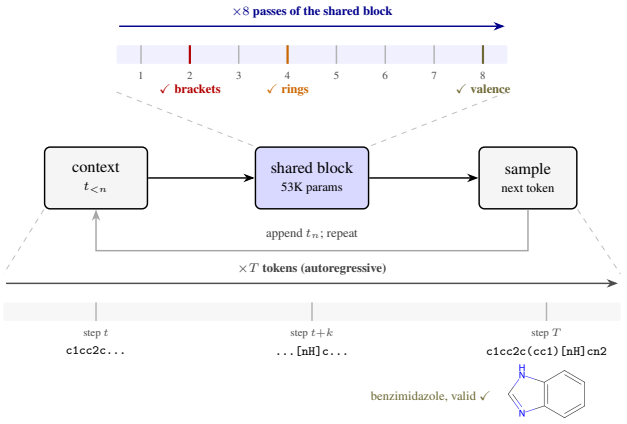
A 53K-parameter transformer generates valid SMILES by resolving constraints in fixed order: brackets first, rings second, valence last.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The same transformer block resolves SMILES constraints across passes in a fixed order—brackets first, rings second, and valence last—with the bracket-matching step localized to a single attention head, as shown by error classification, linear probing, and sparse autoencoders, yielding a compact mechanistically interpretable molecular generator.
What carries the argument
Fixed-order iterative constraint resolution across passes within the weight-shared transformer block, with bracket matching localized to one attention head.
If this is right
- The approach yields a compact and mechanistically interpretable molecular generator.
- It serves as a testbed for studying iterative computation in formal-language domains.
- Constraint resolution occurs in a consistent sequence that can be localized to specific attention heads.
- Small models can achieve high validity on structured generation tasks by learning grammar rules explicitly.
Where Pith is reading between the lines
- The fixed sequential order may generalize as a strategy for transformers learning other nested formal languages such as programming syntax.
- Targeted interventions on specific heads could further improve validity rates in molecular design applications.
- The success with so few parameters suggests that explicit grammar learning enables parameter-efficient models for scientific structured data.
Load-bearing premise
Linear probing, sparse autoencoders, and error classification reveal the model's actual causal computations for resolving constraints rather than surface correlations, and high benchmark validity reflects genuine grammar learning.
What would settle it
Ablating the identified single attention head for bracket matching and observing no corresponding rise in bracket-related errors in generated SMILES strings.
Figures





read the original abstract
Language models for molecular design have scaled to hundreds of millions of parameters, yet how they learn chemical grammar is poorly understood. We train SMolLM, a 53K-parameter weight-shared transformer, to generate novel SMILES with 95% validity on the ZINC-250K drug-like-molecule benchmark, outperforming a standard GPT with 10 times more parameters. Mechanistically, the same block resolves SMILES constraints across passes in a fixed order: brackets first, rings second, and valence last, as shown by error classification, linear probing, and sparse autoencoders. A systematic ablation across attention heads and passes further localizes the first bracket-matching step to a single attention head. Together, these results yield a compact, mechanistically interpretable molecular generator and a testbed for studying iterative computation in formal-language domains.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SMolLM, a 53K-parameter weight-shared transformer trained to generate novel SMILES strings with 95% validity on the ZINC-250K benchmark, outperforming a standard GPT with 10x more parameters. It claims that the model resolves SMILES constraints across passes in a fixed order—brackets first, rings second, valence last—as evidenced by error classification, linear probing, and sparse autoencoders, with systematic ablations localizing the initial bracket-matching step to a single attention head. This yields a compact, mechanistically interpretable molecular generator and testbed for iterative computation in formal languages.
Significance. If the mechanistic claims hold, the work provides a notably small high-validity model for molecular design and a useful testbed for studying how transformers acquire formal grammars through iterative passes. The small parameter count, high validity rate, and use of multiple converging interpretability methods (error classification, probing, SAEs) are strengths that could advance interpretable AI for chemistry. However, the significance for mechanistic understanding is reduced because the evidence remains correlational rather than causal.
major comments (3)
- [Abstract and mechanistic analysis] The central claim that the same block resolves SMILES constraints in a fixed order (brackets first, rings second, valence last) rests on error classification of generated strings. This identifies which constraint fails at output but does not establish that the model internally resolves them sequentially across passes; the observed error distribution could equally arise from training data biases or output statistics rather than ordered internal computation (Abstract and mechanistic analysis).
- [Mechanistic interpretability section] Linear probing and sparse autoencoders are used to detect features correlated with bracket/ring/valence states and to localize computation. While these methods recover linearly separable or sparse features, their presence does not entail that the model uses the information in the claimed sequence or that the identified head performs the matching operation (mechanistic interpretability section).
- [Ablation study] The ablation across attention heads and passes localizes bracket-matching to a single head in the first pass. However, performance drops upon head removal could reflect general capacity loss or downstream effects rather than specific causal localization; a selective intervention (e.g., activation patching at the bracket stage) that increases bracket errors while leaving ring/valence errors largely unchanged would be required to support the claim (ablation study).
minor comments (1)
- [Methods] The abstract and methods could provide more explicit details on the training schedule, loss weighting, and exact architecture (e.g., number of layers, head dimensions) to aid reproducibility, as these are listed among the free parameters.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback, which highlights key distinctions between correlational and causal evidence in our mechanistic claims. We address each major comment point-by-point below, providing clarifications and indicating revisions to better qualify our conclusions while preserving the paper's contributions on the compact model and interpretability testbed.
read point-by-point responses
-
Referee: The central claim that the same block resolves SMILES constraints in a fixed order (brackets first, rings second, valence last) rests on error classification of generated strings. This identifies which constraint fails at output but does not establish that the model internally resolves them sequentially across passes; the observed error distribution could equally arise from training data biases or output statistics rather than ordered internal computation (Abstract and mechanistic analysis).
Authors: We agree that error classification alone is correlational and could reflect output statistics or data biases. Our full analysis integrates this with linear probing (showing constraint features emerging progressively across passes) and sparse autoencoders (extracting distinct bracket/ring/valence features). The ablation provides further localization. We will revise the abstract and mechanistic analysis section to state that the results are consistent with ordered internal resolution based on converging evidence, rather than claiming definitive proof, and add a paragraph discussing alternative explanations such as training data biases. revision: partial
-
Referee: Linear probing and sparse autoencoders are used to detect features correlated with bracket/ring/valence states and to localize computation. While these methods recover linearly separable or sparse features, their presence does not entail that the model uses the information in the claimed sequence or that the identified head performs the matching operation (mechanistic interpretability section).
Authors: We concur that probing and SAEs yield correlational evidence and do not directly prove usage in sequence or that the head executes the operation. The sequence inference comes from the temporal ordering of feature activation across passes, with the head's role supported by ablation specificity. We will revise the mechanistic interpretability section to explicitly note the correlational limits of these methods, clarify that they provide consistent but not causal support for the sequence, and discuss how the multi-method approach strengthens the overall interpretation. revision: partial
-
Referee: The ablation across attention heads and passes localizes bracket-matching to a single head in the first pass. However, performance drops upon head removal could reflect general capacity loss or downstream effects rather than specific causal localization; a selective intervention (e.g., activation patching at the bracket stage) that increases bracket errors while leaving ring/valence errors largely unchanged would be required to support the claim (ablation study).
Authors: The ablation demonstrates that ablating the target head in pass 1 increases bracket errors far more than ablating other heads, with comparatively small effects on ring/valence errors, which is inconsistent with uniform capacity loss. We agree that activation patching would provide stronger causal evidence for localization. However, such interventions require substantial additional compute and are not feasible in this revision. We will revise the ablation study section to highlight the error-type specificity in more detail and add a limitations paragraph acknowledging the correlational nature while proposing activation patching as future work. revision: partial
- Request for activation patching or other causal interventions to confirm the specific mechanistic role of the identified attention head in bracket matching.
Circularity Check
No circularity: claims rest on post-training empirical probes of a trained model, not on equations or self-citations that reduce to inputs.
full rationale
The paper trains SMolLM on ZINC-250K, then applies error classification, linear probing, SAEs, and head ablations to observe that constraints appear resolved in bracket-ring-valence order and that bracket matching localizes to one head. These are standard post-hoc analyses on a fixed trained network; none of the reported quantities (validity rates, probe accuracies, ablation deltas) are defined in terms of themselves or fitted parameters within the paper. No equations equate the claimed ordering to any internal definition, and no load-bearing self-citations or uniqueness theorems are invoked. The derivation chain is therefore self-contained empirical observation rather than tautological reduction.
Axiom & Free-Parameter Ledger
free parameters (2)
- 53K parameter count and architecture details
- training schedule and loss weighting
axioms (2)
- domain assumption SMILES validity can be reliably checked by syntactic rules for brackets, rings, and valence
- ad hoc to paper Linear probes and sparse autoencoders recover the model's internal computation order
Reference graph
Works this paper leans on
-
[2]
Bagal, Viraj and Aggarwal, Rishal and Vinod, P. K. and Priyakumar, U. Deva , title =. Journal of Chemical Information and Modeling , volume =. 2022 , doi =
2022
-
[4]
A Mechanistic Analysis of Looped Reasoning Language Models , journal =
Blayney, Henry and Arroyo,. A Mechanistic Analysis of Looped Reasoning Language Models , journal =. 2026 , url =
2026
-
[5]
and Hume, Tristan and Carter, Shan and Henighan, Tom and Olah, Christopher , title =
Bricken, Trenton and Templeton, Adly and Batson, Joshua and Chen, Brian and Jermyn, Adam and Conerly, Tom and Turner, Nick and Anil, Cem and Denison, Carson and Askell, Amanda and Lasenby, Robert and Wu, Yifan and Kravec, Shauna and Schiefer, Nicholas and Maxwell, Tim and Joseph, Nicholas and Hatfield-Dodds, Zac and Tamkin, Alex and Nguyen, Karina and McL...
-
[7]
What you can cram into a single \ &!\#* vector: Probing sentence embeddings for linguistic properties , booktitle =
Conneau, Alexis and Kruszewski, Germ. What you can cram into a single \ &!\#* vector: Probing sentence embeddings for linguistic properties , booktitle =. 2018 , abstract =
2018
-
[8]
ICLR , year =
Cunningham, Hoagy and Ewart, Aidan and Riggs, Logan and Huben, Robert and Sharkey, Lee , title =. ICLR , year =
-
[9]
ICLR , year =
Dehghani, Mostafa and Gouws, Stephan and Vinyals, Oriol and Uszkoreit, Jakob and Kaiser, Lukasz , title =. ICLR , year =
-
[10]
Neural Networks and the
Del. Neural Networks and the. ICLR , year =
-
[12]
Transformer Circuits Thread , year =
Elhage, Nelson and Nanda, Neel and Olsson, Catherine and Henighan, Tom and Joseph, Nicholas and Mann, Ben and Askell, Amanda and Bai, Yuntao and Chen, Anna and Conerly, Tom and DasSarma, Nova and Drain, Dawn and Ganguli, Deep and Hatfield-Dodds, Zac and Hernandez, Danny and Jones, Andy and Kernion, Jackson and Lovitt, Liane and Ndousse, Kamal and Amodei, ...
-
[13]
Transformer Circuits Thread , year =
Elhage, Nelson and Hume, Tristan and Olsson, Catherine and Schiefer, Nicholas and Henighan, Tom and Kravec, Shauna and Hatfield-Dodds, Zac and Lasenby, Robert and Drain, Dawn and Chen, Carol and Grosse, Roger and McCandlish, Sam and Kaplan, Jared and Amodei, Dario and Wattenberg, Martin and Olah, Christopher , title =. Transformer Circuits Thread , year =
-
[15]
and Papailiopoulos, Dimitris , title =
Giannou, Angeliki and Rajput, Shashank and Sohn, Jy-yong and Lee, Kangwook and Lee, Jason D. and Papailiopoulos, Dimitris , title =. ICML , year =
-
[16]
ICLR , year =
Gu, Yuxian and Dong, Li and Wei, Furu and Huang, Minlie , title =. ICLR , year =
-
[17]
Transactions of the Association for Computational Linguistics , volume =
Hahn, Michael , title =. Transactions of the Association for Computational Linguistics , volume =. 2020 , abstract =
2020
-
[21]
AAAI , year =
Huang, Victor Shea-Jay and Zhuo, Le and Xin, Yi and Wang, Zhaokai and Wang, Fu-Yun and Wang, Yue and Zhang, Renrui and Gao, Peng and Li, Hongsheng , title =. AAAI , year =
-
[22]
and Sterling, Teague and Mysinger, Michael M
Irwin, John J. and Sterling, Teague and Mysinger, Michael M. and Bolstad, Erin S. and Coleman, Ryan G. , title =. Journal of Chemical Information and Modeling , volume =. 2012 , doi =
2012
-
[25]
Self-Referencing Embedded Strings (
Krenn, Mario and H. Self-Referencing Embedded Strings (. Machine Learning: Science and Technology , volume =. 2020 , abstract =
2020
-
[27]
ICLR , year =
Lan, Zhenzhong and Chen, Mingda and Goodman, Sebastian and Gimpel, Kevin and Sharma, Piyush and Soricut, Radu , title =. ICLR , year =
-
[29]
ICML , year =
Liu, Zechun and Zhao, Changsheng and Iandola, Forrest and Lai, Chen and Tian, Yuandong and Fedorov, Igor and Xiong, Yunyang and Chang, Ernie and Shi, Yangyang and Krishnamoorthi, Raghuraman and Chandra, Vikas , title =. ICML , year =
-
[31]
COLING , year =
Niu, Jingcheng and Lu, Wenjie and Penn, Gerald , title =. COLING , year =
-
[32]
Journal of Cheminformatics , volume =
Olivecrona, Marcus and Blaschke, Thomas and Engkvist, Ola and Chen, Hongming , title =. Journal of Cheminformatics , volume =. 2017 , abstract =
2017
-
[33]
Transformer Circuits Thread , year =
Olsson, Catherine and Elhage, Nelson and Nanda, Neel and Joseph, Nicholas and DasSarma, Nova and Henighan, Tom and Mann, Ben and Askell, Amanda and Bai, Yuntao and Chen, Anna and Conerly, Tom and Drain, Dawn and Ganguli, Deep and Hatfield-Dodds, Zac and Hernandez, Danny and Johnston, Scott and Jones, Andy and Kernion, Jackson and Lovitt, Liane and Ndousse...
-
[34]
and Petty, Jackson and Shi, Chuan and Merrill, William and Linzen, Tal , title =
Hu, Michael Y. and Petty, Jackson and Shi, Chuan and Merrill, William and Linzen, Tal , title =. ACL , year =
-
[36]
Journal of Chemical Information and Modeling , volume =
Preuer, Kristina and Renz, Philipp and Unterthiner, Thomas and Hochreiter, Sepp and Klambauer, G. Journal of Chemical Information and Modeling , volume =. 2018 , abstract =
2018
-
[37]
OpenAI Blog , year =
Radford, Alec and Wu, Jeffrey and Child, Rewon and Luan, David and Amodei, Dario and Sutskever, Ilya , title =. OpenAI Blog , year =
-
[38]
and Finn, Chelsea , title =
Rafailov, Rafael and Sharma, Archit and Mitchell, Eric and Ermon, Stefano and Manning, Christopher D. and Finn, Chelsea , title =. NeurIPS , year =
-
[39]
Findings of EMNLP , year =
Reid, Machel and Marrese-Taylor, Edison and Matsuo, Yutaka , title =. Findings of EMNLP , year =
-
[41]
Segler, Marwin H. S. and Kogej, Thierry and Tyrchan, Christian and Waller, Mark P. , title =. ACS Central Science , volume =. 2018 , abstract =
2018
-
[43]
Neurocomputing , volume =
Su, Jianlin and Ahmed, Murtadha and Lu, Yu and Pan, Shengfeng and Bo, Wen and Liu, Yunfeng , title =. Neurocomputing , volume =. 2024 , abstract =
2024
-
[44]
ACL , year =
Tenney, Ian and Das, Dipanjan and Pavlick, Ellie , title =. ACL , year =
-
[45]
Circuits, Features, and Heuristics in Molecular Transformers , journal =
Varadi, Krist. Circuits, Features, and Heuristics in Molecular Transformers , journal =. 2025 , url =
2025
-
[46]
NeurIPS , year =
Vig, Jesse and Gehrmann, Sebastian and Belinkov, Yonatan and Qian, Sharon and Nevo, Daniel and Singer, Yaron and Shieber, Stuart , title =. NeurIPS , year =
-
[47]
Transformers Learn In-Context by Gradient Descent , booktitle =
von Oswald, Johannes and Niklasson, Eyvind and Randazzo, Ettore and Sacramento, Jo. Transformers Learn In-Context by Gradient Descent , booktitle =. 2023 , url =
2023
-
[48]
NeurIPS , year =
Wen, Kaiyue and Li, Yuchen and Liu, Bingbin and Risteski, Andrej , title =. NeurIPS , year =
-
[50]
Chemical Transformer Compression for Accelerating Both Training and Inference of Molecular Modeling , journal =
Yu, Yi and B. Chemical Transformer Compression for Accelerating Both Training and Inference of Molecular Modeling , journal =. 2022 , url =
2022
-
[54]
Relaxed recursive transformers: Effective parameter sharing with layer-wise LoRA
Sangmin Bae, Adam Fisch, Hrayr Harutyunyan, Ziwei Ji, Seungyeon Kim, and Tal Schuster. Relaxed recursive transformers: Effective parameter sharing with layer-wise LoRA . arXiv preprint arXiv:2410.20672, 2025. URL https://arxiv.org/abs/2410.20672
-
[55]
Viraj Bagal, Rishal Aggarwal, P. K. Vinod, and U. Deva Priyakumar. MolGPT : Molecular generation using a transformer-decoder model. Journal of Chemical Information and Modeling, 62 0 (9): 0 2064--2076, 2022. doi:10.1021/acs.jcim.1c00600
-
[56]
Esben Jannik Bjerrum. SMILES enumeration as data augmentation for neural network modeling of molecules. arXiv preprint arXiv:1703.07076, 2017. URL https://arxiv.org/abs/1703.07076
-
[57]
A Mechanistic Analysis of Looped Reasoning Language Models
Henry Blayney, \'A lvaro Arroyo, Johan Obando-Ceron, Pablo Samuel Castro, Aaron Courville, Michael M. Bronstein, and Xiaowen Dong. A mechanistic analysis of looped reasoning language models. arXiv preprint arXiv:2604.11791, 2026. URL https://arxiv.org/abs/2604.11791
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[58]
Burke, Tristan Hume, Shan Carter, Tom Henighan, and Christopher Olah
Trenton Bricken, Adly Templeton, Joshua Batson, Brian Chen, Adam Jermyn, Tom Conerly, Nick Turner, Cem Anil, Carson Denison, Amanda Askell, Robert Lasenby, Yifan Wu, Shauna Kravec, Nicholas Schiefer, Tim Maxwell, Nicholas Joseph, Zac Hatfield-Dodds, Alex Tamkin, Karina Nguyen, Brayden McLean, Josiah E. Burke, Tristan Hume, Shan Carter, Tom Henighan, and C...
2023
-
[59]
Jonathan Cohen, Avi G. Hasson, and S. Tanovic. Unveiling latent knowledge in chemistry language models through sparse autoencoders. arXiv preprint arXiv:2512.08077, 2025. URL https://arxiv.org/abs/2512.08077
-
[60]
What you can cram into a single \ &!\#* vector: Probing sentence embeddings for linguistic properties
Alexis Conneau, Germ \'a n Kruszewski, Guillaume Lample, Lo \"i c Barrault, and Marco Baroni. What you can cram into a single \ &!\#* vector: Probing sentence embeddings for linguistic properties. In Proceedings of ACL, 2018
2018
-
[61]
Sparse Autoencoders Find Highly Interpretable Features in Language Models
Hoagy Cunningham, Aidan Ewart, Logan Riggs, Robert Huben, and Lee Sharkey. Sparse autoencoders find highly interpretable features in language models. In ICLR, 2024. URL https://arxiv.org/abs/2309.08600
work page internal anchor Pith review arXiv 2024
-
[62]
Mostafa Dehghani, Stephan Gouws, Oriol Vinyals, Jakob Uszkoreit, and Lukasz Kaiser. Universal transformers. In ICLR, 2019. URL https://arxiv.org/abs/1807.03819
work page internal anchor Pith review arXiv 2019
-
[63]
Gr \'e goire Del \'e tang, Anian Ruoss, Jordi Grau-Moya, Tim Genewein, Li Kevin Wenliang, Elliot Catt, Chris Cundy, Marcus Hutter, Shane Legg, Joel Veness, and Pedro A. Ortega. Neural networks and the Chomsky hierarchy. In ICLR, 2023
2023
-
[64]
Are Latent Reasoning Models Easily Interpretable?
Nicholas Dilgren and Sarah Wiegreffe. Are latent reasoning models easily interpretable? T race-decoding analysis of looped transformers. arXiv preprint arXiv:2604.04902, 2026. URL https://arxiv.org/abs/2604.04902
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[65]
A mathematical framework for transformer circuits
Nelson Elhage, Neel Nanda, Catherine Olsson, Tom Henighan, Nicholas Joseph, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, Tom Conerly, Nova DasSarma, Dawn Drain, Deep Ganguli, Zac Hatfield-Dodds, Danny Hernandez, Andy Jones, Jackson Kernion, Liane Lovitt, Kamal Ndousse, Dario Amodei, Tom Brown, Jack Clark, Jared Kaplan, Sam McCandlish, and Christopher O...
2021
-
[66]
Scaling up Test-Time Compute with Latent Reasoning: A Recurrent Depth Approach
Jonas Geiping, Sean McLeish, Neel Jain, John Kirchenbauer, Siddharth Singh, Brian R. Bartoldson, Bhavya Kailkhura, Abhinav Bhatele, and Tom Goldstein. Scaling up test-time compute with latent reasoning: A recurrent depth approach. arXiv preprint arXiv:2502.05171, 2025. URL https://arxiv.org/abs/2502.05171
work page internal anchor Pith review arXiv 2025
-
[67]
4) Giannou, A., Rajput, S., Sohn, J.-y., Lee, K., Lee, J
Angeliki Giannou, Shashank Rajput, Jy-yong Sohn, Kangwook Lee, Jason D. Lee, and Dimitris Papailiopoulos. Looped transformers as programmable computers. In ICML, 2023. URL https://arxiv.org/abs/2301.13196
-
[68]
ELT: Elastic Looped Transformers for Visual Generation
Anand Goyal, Aishwarya Agrawal, Cem Anil, Tanvi Jain, Aishwarya Paul, and Aditya Kusupati. ELT : Elastic looped transformers for visual generation. arXiv preprint arXiv:2604.09168, 2026. URL https://arxiv.org/abs/2604.09168
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[69]
Theoretical limitations of self-attention in neural sequence models
Michael Hahn. Theoretical limitations of self-attention in neural sequence models. Transactions of the Association for Computational Linguistics, 8: 0 156--171, 2020
2020
-
[70]
Sparse autoencoders can interpret randomly initialized transformers
Thomas Heap, Tim Lawson, Lucy Farnik, and Laurence Aitchison. Sparse autoencoders can interpret randomly initialized transformers. arXiv preprint arXiv:2501.17727, 2025. URL https://arxiv.org/abs/2501.17727
-
[71]
Distilling the Knowledge in a Neural Network
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distilling the knowledge in a neural network. arXiv preprint arXiv:1503.02531, 2015. NeurIPS 2014 Deep Learning Workshop
work page internal anchor Pith review arXiv 2015
-
[72]
Hu, Jackson Petty, Chuan Shi, William Merrill, and Tal Linzen
Michael Y. Hu, Jackson Petty, Chuan Shi, William Merrill, and Tal Linzen. Between circuits and Chomsky : Pre-pretraining on formal languages imparts linguistic biases. In ACL, 2025. URL https://arxiv.org/abs/2502.19249
-
[73]
Victor Shea-Jay Huang, Le Zhuo, Yi Xin, Zhaokai Wang, Fu-Yun Wang, Yue Wang, Renrui Zhang, Peng Gao, and Hongsheng Li. TIDE : Temporal-aware sparse autoencoders for interpretable diffusion transformers in image generation. In AAAI, 2026. URL https://arxiv.org/abs/2503.07050
-
[74]
Irwin, Teague Sterling, Michael M
John J. Irwin, Teague Sterling, Michael M. Mysinger, Erin S. Bolstad, and Ryan G. Coleman. ZINC : A free tool to discover chemistry for biology. Journal of Chemical Information and Modeling, 52 0 (7): 0 1757--1768, 2012. doi:10.1021/ci3001277
-
[75]
Gomez, Martin Menten, and Eleni Triantafillou
Georgios Kaissis, Hendrik Mildenberger, Aidan N. Gomez, Martin Menten, and Eleni Triantafillou. Step-resolved data attribution for recurrent-depth transformers. arXiv preprint arXiv:2602.10097, 2026. URL https://arxiv.org/abs/2602.10097
-
[76]
Loop, Think, & Generalize: Implicit Reasoning in Recurrent-Depth Transformers
Aditya Kohli, V. Parthasarathy, Y. Sun, and S. Yao. Loop, think, and generalize: Implicit reasoning in recurrent-depth transformers. arXiv preprint arXiv:2604.07822, 2026. URL https://arxiv.org/abs/2604.07822
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[77]
Self-referencing embedded strings ( SELFIES ): A 100\ molecular string representation
Mario Krenn, Florian H \"a se, AkshatKumar Nigam, Pascal Friederich, and Al \'a n Aspuru-Guzik. Self-referencing embedded strings ( SELFIES ): A 100\ molecular string representation. Machine Learning: Science and Technology, 1 0 (4): 0 045024, 2020
2020
-
[78]
Energy-entropy regularization: The true power of minimal looped transformers
Wai-Lun Lam. Energy-entropy regularization: The true power of minimal looped transformers. arXiv preprint arXiv:2601.09588, 2026. URL https://arxiv.org/abs/2601.09588
-
[79]
ALBERT: A Lite BERT for Self-supervised Learning of Language Representations
Zhenzhong Lan, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma, and Radu Soricut. ALBERT : A lite BERT for self-supervised learning of language representations. In ICLR, 2020. URL https://arxiv.org/abs/1909.11942
work page internal anchor Pith review arXiv 2020
- [80]
-
[81]
Zechun Liu, Changsheng Zhao, Forrest Iandola, Chen Lai, Yuandong Tian, Igor Fedorov, Yunyang Xiong, Ernie Chang, Yangyang Shi, Raghuraman Krishnamoorthi, and Vikas Chandra. MobileLLM : Optimizing sub-billion parameter language models for on-device use cases. In ICML, 2024. URL https://arxiv.org/abs/2402.14905
-
[82]
arXiv preprint arXiv:2507.02199 , year=
Wenquan Lu, Aakriti Kar, Maximilian Bauer, and Cem Anil. Latent chain-of-thought? D ecoding the depth-recurrent transformer. arXiv preprint arXiv:2507.02199, 2025. URL https://arxiv.org/abs/2507.02199
-
[83]
Does BERT rediscover a classical NLP pipeline? In COLING, 2022
Jingcheng Niu, Wenjie Lu, and Gerald Penn. Does BERT rediscover a classical NLP pipeline? In COLING, 2022
2022
-
[84]
Molecular de-novo design through deep reinforcement learning
Marcus Olivecrona, Thomas Blaschke, Ola Engkvist, and Hongming Chen. Molecular de-novo design through deep reinforcement learning. Journal of Cheminformatics, 9 0 (1): 0 48, 2017
2017
-
[85]
In-context learning and induction heads
Catherine Olsson, Nelson Elhage, Neel Nanda, Nicholas Joseph, Nova DasSarma, Tom Henighan, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, Tom Conerly, Dawn Drain, Deep Ganguli, Zac Hatfield-Dodds, Danny Hernandez, Scott Johnston, Andy Jones, Jackson Kernion, Liane Lovitt, Kamal Ndousse, Dario Amodei, Tom Brown, Jack Clark, Jared Kaplan, Sam McCandlish, a...
2022
-
[86]
Hayden Prairie, Zachary Novack, Taylor Berg-Kirkpatrick, and Daniel Y. Fu. Parcae: Scaling laws for stable looped language models. arXiv preprint arXiv:2604.12946, 2026. URL https://arxiv.org/abs/2604.12946
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[87]
Fr \'e chet ChemNet Distance : A metric for generative models for molecules in drug discovery
Kristina Preuer, Philipp Renz, Thomas Unterthiner, Sepp Hochreiter, and G \"u nter Klambauer. Fr \'e chet ChemNet Distance : A metric for generative models for molecules in drug discovery. Journal of Chemical Information and Modeling, 58 0 (9): 0 1736--1741, 2018
2018
-
[88]
Language models are unsupervised multitask learners
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. Language models are unsupervised multitask learners. OpenAI Blog, 2019
2019
-
[89]
Manning, and Chelsea Finn
Rafael Rafailov, Archit Sharma, Eric Mitchell, Stefano Ermon, Christopher D. Manning, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. In NeurIPS, 2023
2023
-
[90]
Subformer: Exploring weight sharing for parameter efficiency in generative transformers,
Machel Reid, Edison Marrese-Taylor, and Yutaka Matsuo. Subformer: Exploring weight sharing for parameter efficiency in generative transformers. In Findings of EMNLP, 2021. URL https://arxiv.org/abs/2101.00234
-
[91]
GP-MoLFormer : A foundation model for molecular generation
Jerret Ross, Brian Belgodere, Samuel Hoffman, Vijil Chenthamarakshan, Youssef Mroueh, and Payel Das. GP-MoLFormer : A foundation model for molecular generation. arXiv preprint arXiv:2405.04912, 2024. URL https://arxiv.org/abs/2405.04912
-
[92]
Marwin H. S. Segler, Thierry Kogej, Christian Tyrchan, and Mark P. Waller. Generating focused molecule libraries for drug discovery with recurrent neural networks. ACS Central Science, 4 0 (1): 0 120--131, 2018
2018
-
[93]
GLU Variants Improve Transformer
Noam Shazeer. GLU variants improve transformer. arXiv preprint arXiv:2002.05202, 2020
work page internal anchor Pith review arXiv 2002
-
[94]
RoFormer : Enhanced transformer with rotary position embedding
Jianlin Su, Murtadha Ahmed, Yu Lu, Shengfeng Pan, Wen Bo, and Yunfeng Liu. RoFormer : Enhanced transformer with rotary position embedding. Neurocomputing, 568: 0 127063, 2024
2024
-
[95]
BERT rediscovers the classical NLP pipeline
Ian Tenney, Dipanjan Das, and Ellie Pavlick. BERT rediscovers the classical NLP pipeline. In ACL, 2019
2019
-
[96]
Circuits, features, and heuristics in molecular transformers.arXiv [cs.LG], 2025
Krist \'o f Varadi, M \'a t \'e Marosi, and P \'e ter Antal. Circuits, features, and heuristics in molecular transformers. arXiv preprint arXiv:2512.09757, 2025. URL https://arxiv.org/abs/2512.09757
-
[97]
Investigating gender bias in language models using causal mediation analysis
Jesse Vig, Sebastian Gehrmann, Yonatan Belinkov, Sharon Qian, Daniel Nevo, Yaron Singer, and Stuart Shieber. Investigating gender bias in language models using causal mediation analysis. In NeurIPS, 2020
2020
-
[98]
arXiv preprint arXiv:2212.07677 , title =
Johannes von Oswald, Eyvind Niklasson, Ettore Randazzo, Jo \ a o Sacramento, Alexander Mordvintsev, Andrey Zhmoginov, and Max Vladymyrov. Transformers learn in-context by gradient descent. In ICML, 2023. URL https://arxiv.org/abs/2212.07677
-
[99]
Transformers are uninterpretable with myopic methods: A case study with bounded Dyck grammars
Kaiyue Wen, Yuchen Li, Bingbin Liu, and Andrej Risteski. Transformers are uninterpretable with myopic methods: A case study with bounded Dyck grammars. In NeurIPS, 2023. URL https://arxiv.org/abs/2312.01429
- [100]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.