Recognition: unknown
Disposition Distillation at Small Scale: A Three-Arc Negative Result
Pith reviewed 2026-05-10 16:05 UTC · model grok-4.3
The pith
No tested method adds self-verification or uncertainty acknowledgment to small language models without harming content or reducing to stylistic mimicry.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Across SFT/DPO LoRA fine-tuning on three model families, inference-time attention-head tempering on the o_proj matrix, and a training-free frozen-base sidecar reading the final-token hidden state h_last, no operator moves judge-measured disposition without damaging content or collapsing into stylistic mimicry; the failure is consistent across Qwen3-0.6B, Qwen3-1.7B, Qwen3.5-0.8B, Gemma 4 E2B, and SmolLM2-1.7B-Instruct, with within-distribution probes collapsing to chance on fresh prompts.
What carries the argument
The three-arc negative-result pipeline that systematically tests LoRA alignment, attention-head tempering, and linear h_last probes after an initial result was falsified by truncation and scoring artifacts.
If this is right
- Standard alignment recipes such as SFT and DPO with LoRA do not transfer behavioral dispositions at the tested scales.
- Linear probes on the final hidden state fail to generalize disposition prediction beyond the training distribution.
- Initial positive distillation results must be subjected to apples-to-apples re-scoring and longer generation lengths to rule out truncation artifacts.
- At least one small model exhibits near-complete confidence-correctness decoupling on particular domains.
Where Pith is reading between the lines
- The observed failure modes may indicate a capacity limit in small models for representing dispositions separately from surface style.
- Non-linear or multi-layer probes could be tested to determine whether the linear h_last approach itself is the limiting factor.
- The honest falsification pipeline used here offers a template for converting self-discovered false positives into publishable negative findings.
Load-bearing premise
Judge-measured disposition scores reliably capture the intended behavioral traits independently of content quality and stylistic mimicry.
What would settle it
A concrete demonstration of any method, whether training-based or inference-based, that raises disposition scores on fresh prompts while preserving content quality and avoiding repetitive stylistic patterns.
Figures


read the original abstract
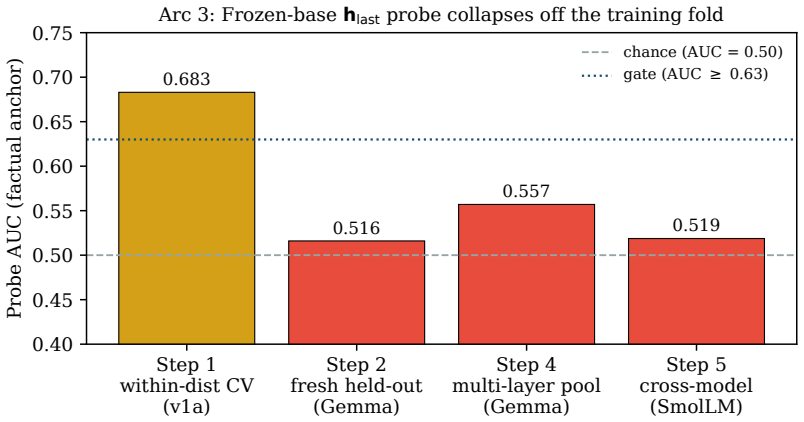
We set out to train behavioral dispositions (self-verification, uncertainty acknowledgment, feedback integration) into small language models (0.6B to 2.3B effective parameters) through a four-stage all-MIT distillation pipeline, with follow-on experiments on inference-time attention-head interventions and a frozen-base confidence-gated sidecar. An internal draft reported +33.9-point MCAS and +15.3-point HumanEval gains on a Qwen3-0.6B student; a second-pass sanity check falsified both numbers before publication. The HumanEval delta was a truncation artifact (n_predict=512) that inverted to -8.0 points at n_predict=1024; the MCAS gain disappeared under apples-to-apples scoring. That falsification triggered three subsequent arcs. Across (1) SFT/DPO LoRA on three model families and two domains, (2) inference-time attention-head tempering on o_proj, and (3) a training-free frozen-base sidecar reading the final-token hidden state h_last, we find no operator that moves judge-measured disposition without damaging content or collapsing into stylistic mimicry. The failure is consistent across five models (Qwen3-0.6B, Qwen3-1.7B, Qwen3.5-0.8B, Gemma 4 E2B, and SmolLM2-1.7B-Instruct). A within-distribution cross-validation pass (AUC=0.683) collapsed to chance on fresh prompts (AUC=0.516). We contribute a three-arc negative result with mechanism, a two-failure-mode taxonomy for linear h_last probes, and an honest falsification pipeline that converts the class of false positives we ourselves produced into publishable negatives. As an independent finding, Gemma 4 E2B exhibits near-complete confidence-correctness decoupling on the Chef domain (assertion asymmetry -0.009; the model asserts at 91% regardless of correctness).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
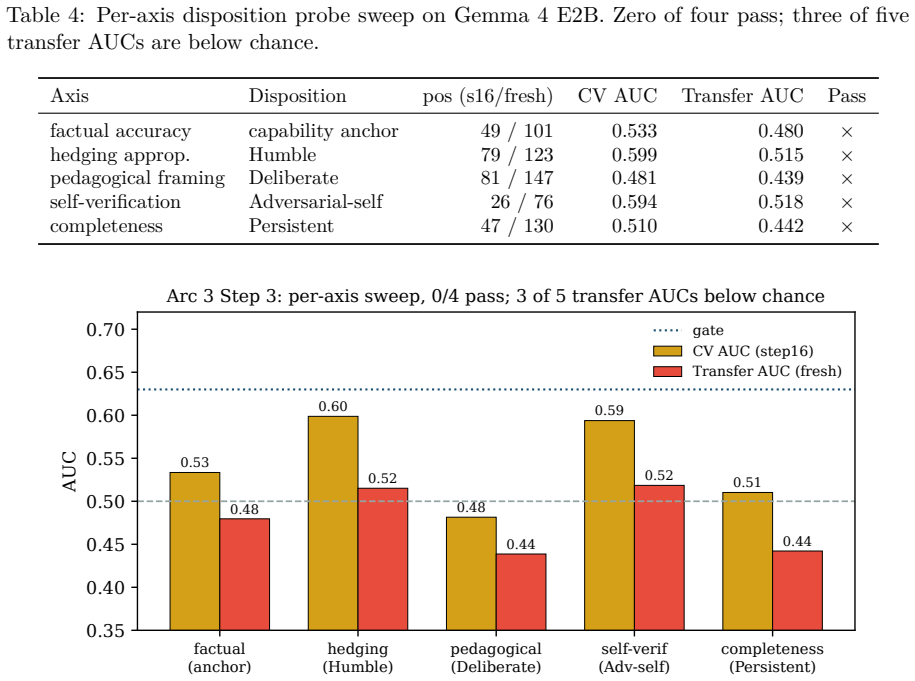
Summary. The manuscript reports a three-arc negative result on distilling behavioral dispositions (self-verification, uncertainty acknowledgment, feedback integration) into small LMs (0.6B–2.3B parameters). Initial positive findings on Qwen3-0.6B were falsified as artifacts of n_predict=512 truncation and non-apples-to-apples scoring; subsequent experiments with SFT/DPO LoRA on three families/two domains, o_proj attention-head tempering, and a frozen-base h_last sidecar find no operator that improves judge-measured disposition without content damage or stylistic mimicry. Results are consistent across five models; the h_last probe shows within-distribution AUC 0.683 collapsing to 0.516 on fresh prompts. Additional finding: Gemma 4 E2B exhibits near-complete confidence-correctness decoupling on the Chef domain.
Significance. If the disposition judge isolates the target traits, the work supplies a credible negative result at small scale, a falsification pipeline that converts self-produced false positives into publishable negatives, and a two-failure-mode taxonomy for linear h_last probes. These elements are valuable for the field even if the absolute claim is scoped to the tested operators and judge.
major comments (1)
- The central claim that no operator moves disposition without side effects rests on the judge reliably scoring the intended traits independently of content quality and stylistic mimicry. While the sidecar probe's AUC drop (0.683 to 0.516) is reported, the manuscript does not provide equivalent cross-prompt or cross-domain validation for the primary disposition judge; without it the consistent 'no movement' finding risks being an artifact of correlated scoring rather than evidence that no effective operator exists.
minor comments (2)
- The abstract and main text use 'Gemma 4 E2B' without a precise model identifier or citation; add the exact checkpoint name and reference for reproducibility.
- The two-failure-mode taxonomy for h_last probes is a useful contribution; consider a short table or diagram that maps the modes to the observed AUC collapse and mimicry cases.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. The concern about validating the primary disposition judge is well-taken and directly relevant to the strength of our negative result. We address it below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: The central claim that no operator moves disposition without side effects rests on the judge reliably scoring the intended traits independently of content quality and stylistic mimicry. While the sidecar probe's AUC drop (0.683 to 0.516) is reported, the manuscript does not provide equivalent cross-prompt or cross-domain validation for the primary disposition judge; without it the consistent 'no movement' finding risks being an artifact of correlated scoring rather than evidence that no effective operator exists.
Authors: We agree that the absence of reported cross-validation for the primary disposition judge is a limitation in the current manuscript. The judge was prompted to isolate the three target traits (self-verification, uncertainty acknowledgment, feedback integration) with explicit instructions to ignore content quality, factual accuracy, and stylistic mimicry; our three-arc design further tested this by showing that operators either damaged content or produced only stylistic changes without trait movement. However, we did not perform the same systematic cross-prompt and cross-domain checks we applied to the h_last sidecar. In the revised manuscript we will add an equivalent validation section for the judge, including (1) cross-prompt consistency on held-out prompt sets and (2) cross-domain transfer between the two domains tested. These results will be reported alongside the existing sidecar analysis and will be used to qualify the strength of the 'no movement' claim. We view this as a necessary strengthening rather than a refutation of the negative result. revision: yes
Circularity Check
No circularity; self-contained empirical negative result
full rationale
The paper reports direct experimental outcomes across SFT/DPO LoRA, inference-time attention tempering, and a frozen-base h_last sidecar on five models. Central claims rest on observed performance deltas, judge scores, and AUC measurements (e.g., within-distribution 0.683 collapsing to 0.516 out-of-distribution) rather than any derived quantities. Explicit self-falsification of the authors' own prior positive results (MCAS/HumanEval artifacts) is presented transparently without re-deriving those positives. No equations, fitted parameters, uniqueness theorems, or self-citations appear as load-bearing steps. The work is a straightforward empirical falsification pipeline with no reduction of outputs to inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Judge models provide a valid and stable measurement of behavioral dispositions independent of content and style.
Reference graph
Works this paper leans on
-
[1]
[Allal et al.(2024)]L. B. Allal, A. Lozhkov, G. Penedo, T. Wolf, and L. von Werra. SmolLM: A family of small language models. Technical report, Hugging Face,
2024
-
[2]
Belinkov
[Belinkov(2022)] Y. Belinkov. Probing classifiers: Promises, shortcomings, and advances.Com- putational Linguistics, 48(1):207–219,
2022
-
[3]
[Chen et al.(2021)]M. Chen, J. Tworek, H. Jun, Q. Yuan, H. Pinto de Oliveira, J. Kaplan, H. Edwards, Y. Burda, N. Joseph, G. Brockman, A. Ray, R. Puri, G. Krueger, M. Petrov, H. Khlaaf, G. Sastry, P. Mishkin, B. Chan, S. Gray, N. Ryder, M. Pavlov, A. Power, L. Kaiser, M. Bavarian, C. Winter, P. Tillet, F. P. Such, D. Cummings, M. Plappert, F. Chantzis, E....
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[4]
[DeepSeek-AI(2024)] DeepSeek-AI. DeepSeek-V3 technical report.arXiv preprint arXiv:2412.19437,
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
Gemma 3 and Gemma 4 technical report
[Gemma Team(2025)]Gemma Team, Google DeepMind. Gemma 3 and Gemma 4 technical report. Technical report, Google DeepMind,
2025
-
[6]
[Geva et al.(2021)]M. Geva, R. Schuster, J. Berant, and O. Levy. Transformer feed-forward layers are key-value memories. InProceedings of EMNLP,
2021
-
[7]
ChatGLM: A Family of Large Language Models from GLM-130B to GLM-4 All Tools
15 [GLM Team(2024)]GLM Team, Zhipu AI. ChatGLM: A family of large language models from GLM-130B to GLM-4 all tools.arXiv preprint arXiv:2406.12793,
work page internal anchor Pith review arXiv 2024
-
[8]
Hewitt and C
[Hewitt and Liang(2019)]J. Hewitt and C. D. Liang. Designing and interpreting probes with control tasks. InProceedings of EMNLP,
2019
-
[9]
Distilling the Knowledge in a Neural Network
[Hinton et al.(2015)]G. Hinton, O. Vinyals, and J. Dean. Distilling the knowledge in a neural network.arXiv preprint arXiv:1503.02531,
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[10]
Hsieh, C.-L
[Hsieh et al.(2023)]C.-Y. Hsieh, C.-L. Li, C.-K. Yeh, H. Nakhost, Y. Fujii, A. Ratner, R. Krishna, C.-Y. Lee, and T. Pfister. Distilling step-by-step! Outperforming larger language models with less training data and smaller model sizes. InFindings of ACL,
2023
-
[11]
[Hu et al.(2022)]E. J. Hu, Y. Shen, P. Wallis, Z. Allen-Zhu, Y. Li, S. Wang, L. Wang, and W. Chen. LoRA: Low-rank adaptation of large language models. InProceedings of ICLR,
2022
-
[12]
Kimi k1.5: Scaling Reinforcement Learning with LLMs
[Kimi Team(2025)]Kimi Team, Moonshot AI. Kimi K1.5: Scaling reinforcement learning with LLMs.arXiv preprint arXiv:2501.12599,
work page internal anchor Pith review arXiv 2025
-
[13]
[MiniMax(2025)] MiniMax. MiniMax-01: Scaling foundation models with lightning attention. arXiv preprint arXiv:2501.08313,
-
[14]
Rafailov, A
[Rafailov et al.(2023)]R. Rafailov, A. Sharma, E. Mitchell, S. Ermon, C. D. Manning, and C. Finn. Direct preference optimization: Your language model is secretly a reward model. InAdvances in NeurIPS,
2023
-
[15]
Steering Llama 2 via Contrastive Activation Addition
[Rimsky et al.(2023)]N.Rimsky, N.Gabrieli, J.Schulman, M.Turner, A.Chan, andE.Hubinger. Steering Llama 2 via contrastive activation addition.arXiv preprint arXiv:2312.06681,
work page internal anchor Pith review arXiv 2023
-
[16]
Steering Language Models With Activation Engineering
[Turner et al.(2023)]A. Turner, L. Thiergart, D. Udell, G. Leech, U. Mini, and M. Macdi- armid. Activation addition: Steering language models without optimization.arXiv preprint arXiv:2308.10248,
work page internal anchor Pith review arXiv 2023
-
[17]
Zelikman, Y
[Zelikman et al.(2022)]E. Zelikman, Y. Wu, J. Mu, and N. Goodman. STaR: Bootstrapping reasoning with reasoning. InAdvances in NeurIPS,
2022
-
[18]
arXiv preprint arXiv:2505.22954 , year=
[Zhang et al.(2025)]J. Zhang, J. Lehman, K. Stanley, and J. Clune. The Darwin Gödel Machine. arXiv preprint arXiv:2505.22954,
- [19]
-
[20]
[Zou et al.(2023)]A. Zou, L. Phan, S. Chen, J. Campbell, P. Guo, R. Ren, A. Pan, X. Yin, M. Mazeika, A.-K. Dombrowski, S. Goel, N. Li, M. J. Byun, Z. Wang, A. Mallen, S. Basart, S. Koyejo, D. Song, M. Fredrikson, J. Z. Kolter, and D. Hendrycks. Representation engineering: A top-down approach to AI transparency.arXiv preprint arXiv:2310.01405,
work page internal anchor Pith review arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.