Recognition: unknown
Self-Distillation Zero: Self-Revision Turns Binary Rewards into Dense Supervision
Pith reviewed 2026-05-10 15:34 UTC · model grok-4.3
The pith
A single language model can convert binary rewards into dense token-level supervision by revising its own generations and distilling the revisions back into itself.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SD-Zero trains a single model to play two roles: a Generator, which produces an initial response, and a Reviser, which conditions on that response and its binary reward to produce an improved response. We then perform on-policy self-distillation to distill the reviser into the generator, using the reviser's token distributions conditioned on the generator's response and its reward as supervision. In effect, SD-Zero trains the model to transform binary rewards into dense token-level self-supervision.
What carries the argument
The dual-role model with Generator producing responses and Reviser improving them based on binary reward, followed by on-policy self-distillation of the reviser's distributions.
If this is right
- Performance on math and code reasoning benchmarks improves by at least 10% over base models using the same training samples.
- The method outperforms Rejection Fine-Tuning, GRPO, and Self-Distillation Fine-Tuning under identical question sets and sample budgets.
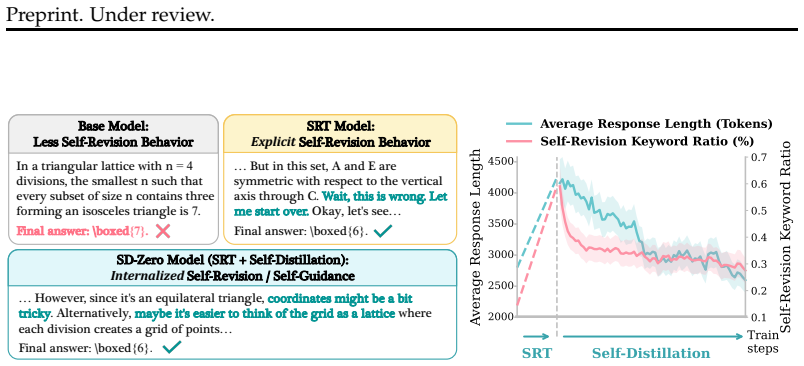
- The reviser identifies key tokens needing revision based on the reward signal.
- Iterative self-evolution occurs as revision ability is distilled back to generation with teacher synchronization.
Where Pith is reading between the lines
- This approach could be extended to other verifiable tasks where binary outcomes are easy to check but dense labels are hard to obtain.
- Continuous loops of generation-revision-distillation might enable ongoing model improvement without additional human data.
- Token-level self-localization might help in debugging model reasoning errors more precisely than global rewards.
- Reducing reliance on external teachers could lower costs for post-training large models.
Load-bearing premise
The reviser's outputs, produced by conditioning on the generator's response and binary reward, supply high-quality dense supervision that can be distilled back into the generator without introducing systematic errors or reward hacking.
What would settle it
Training the model with SD-Zero on a benchmark and finding that the generator's accuracy does not increase or that it fails to match the reviser's behavior on new examples would disprove the central claim.
Figures





read the original abstract
Current post-training methods in verifiable settings fall into two categories. Reinforcement learning (RLVR) relies on binary rewards, which are broadly applicable and powerful, but provide only sparse supervision during training. Distillation provides dense token-level supervision, typically obtained from an external teacher or using high-quality demonstrations. Collecting such supervision can be costly or unavailable. We propose Self-Distillation Zero (SD-Zero), a method that is substantially more training sample-efficient than RL and does not require an external teacher or high-quality demonstrations. SD-Zero trains a single model to play two roles: a Generator, which produces an initial response, and a Reviser, which conditions on that response and its binary reward to produce an improved response. We then perform on-policy self-distillation to distill the reviser into the generator, using the reviser's token distributions conditioned on the generator's response and its reward as supervision. In effect, SD-Zero trains the model to transform binary rewards into dense token-level self-supervision. On math and code reasoning benchmarks with Qwen3-4B-Instruct and Olmo-3-7B-Instruct, SD-Zero improves performance by at least 10% over the base models and outperforms strong baselines, including Rejection Fine-Tuning (RFT), GRPO, and Self-Distillation Fine-Tuning (SDFT), under the same question set and training sample budget. Extensive ablation studies show two novel characteristics of our proposed algorithm: (a) token-level self-localization, where the reviser can identify the key tokens that need to be revised in the generator's response based on reward, and (b) iterative self-evolution, where the improving ability to revise answers can be distilled back into generation performance with regular teacher synchronization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Self-Distillation Zero (SD-Zero), a technique where a single model is trained to serve as both a Generator for initial responses and a Reviser that conditions on the initial response and its binary reward to generate improved responses. Through on-policy self-distillation, the reviser's token-level distributions are used to supervise the generator, effectively converting binary rewards into dense supervision. Experiments on math and code reasoning tasks with Qwen3-4B-Instruct and Olmo-3-7B-Instruct demonstrate at least 10% performance gains over base models and superiority over baselines like RFT, GRPO, and SDFT under matched training budgets, supported by ablations on token-level self-localization and iterative self-evolution.
Significance. If the central claims hold, this work provides a promising sample-efficient method for post-training language models on verifiable tasks by turning sparse binary rewards into dense self-supervision without external teachers or demonstrations. The identification of self-localization and self-evolution behaviors adds to understanding of self-improvement mechanisms in LLMs. It could influence RL-free approaches in reasoning model training.
major comments (2)
- The core mechanism involves the reviser p(· | question, generator_response, binary_reward) providing targets for the generator p(· | question). This conditioning mismatch is not fully addressed; while on-policy distillation is used, there is no explicit analysis or experiment demonstrating that the generator internalizes the reward-derived improvements without access to the response or reward at test time. If this transfer does not occur, the gains may be attributable to additional training steps rather than the self-distillation of revision behavior. (Method section and ablation studies)
- The reported improvements lack details on statistical significance testing, variance across multiple runs, or precise matching of training sample budgets and compute with baselines. This weakens the strength of the claim that SD-Zero outperforms RFT, GRPO, and SDFT. (Experiments and ablation studies)
minor comments (2)
- The abstract mentions 'at least 10%' improvement; specifying the exact gains per benchmark and model would improve clarity.
- The two novel characteristics (token-level self-localization and iterative self-evolution) are interesting, but quantitative metrics or examples for self-localization beyond qualitative description would strengthen the ablation section.
Simulated Author's Rebuttal
Thank you for your thorough review and constructive feedback on our manuscript. We have carefully considered the major comments and provide point-by-point responses below. We believe the suggested revisions will improve the clarity and rigor of the paper.
read point-by-point responses
-
Referee: The core mechanism involves the reviser p(· | question, generator_response, binary_reward) providing targets for the generator p(· | question). This conditioning mismatch is not fully addressed; while on-policy distillation is used, there is no explicit analysis or experiment demonstrating that the generator internalizes the reward-derived improvements without access to the response or reward at test time. If this transfer does not occur, the gains may be attributable to additional training steps rather than the self-distillation of revision behavior. (Method section and ablation studies)
Authors: We appreciate the referee's observation regarding the conditioning mismatch. In SD-Zero, the self-distillation is on-policy, meaning the generator is trained to mimic the reviser's token-level predictions for the same input questions, but the reviser uses additional context during training. At inference, only the generator is used with the question. The ablation studies demonstrate token-level self-localization, where the reviser identifies and corrects specific tokens based on the binary reward, and iterative self-evolution, showing that distillation leads to better generation over iterations. To directly address whether the generator internalizes the improvements, we will add to the revised manuscript an analysis of the generator's output distributions before and after distillation, as well as a controlled experiment isolating the effect of distillation versus additional training steps on the same data. This will be included in the Method and Experiments sections to show that the performance gains stem from the distilled revision capabilities. revision: yes
-
Referee: The reported improvements lack details on statistical significance testing, variance across multiple runs, or precise matching of training sample budgets and compute with baselines. This weakens the strength of the claim that SD-Zero outperforms RFT, GRPO, and SDFT. (Experiments and ablation studies)
Authors: We acknowledge that the current manuscript does not include statistical significance tests or variance reports across multiple runs. The experiments were designed with matched training sample budgets using the same question sets for all methods, as described in Section 4. However, due to the high computational cost, we reported single-run results. In the revision, we will conduct additional runs with different random seeds (at least 3), report means and standard deviations for the benchmark scores, and perform statistical significance tests (e.g., Wilcoxon signed-rank test or t-test) to compare SD-Zero against the baselines. We will also provide more detailed matching information on training compute, such as total training tokens and approximate FLOPs. These updates will be added to the Experiments section and tables. revision: yes
Circularity Check
No significant circularity in the derivation chain
full rationale
The paper's method relies on external binary rewards from verification on math and code tasks as an independent grounding signal. The generator-reviser setup and on-policy self-distillation define a training procedure that produces dense token-level targets from the reviser (conditioned on generator output plus reward), but this does not reduce by construction to a fitted parameter renamed as prediction, a self-definition, or a self-citation chain. The claimed conversion of binary rewards into usable supervision and the reported benchmark gains are presented as empirical outcomes, not tautological necessities. No load-bearing self-citations, ansatz smuggling, or uniqueness theorems imported from prior author work appear in the derivation. The chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- training hyperparameters
axioms (1)
- domain assumption Binary rewards obtained from external verification are reliable and unbiased signals of response quality.
Forward citations
Cited by 4 Pith papers
-
RubricRefine: Improving Tool-Use Agent Reliability with Training-Free Pre-Execution Refinement
RubricRefine raises average tool-use reliability to 0.86 on M3ToolEval across seven models by scoring candidate code against generated contract rubrics before execution, beating prior inference-time methods at 2.6X lo...
-
SOD: Step-wise On-policy Distillation for Small Language Model Agents
SOD reweights on-policy distillation strength step-by-step using divergence to stabilize tool use in small language model agents, yielding up to 20.86% gains and 26.13% on AIME 2025 for a 0.6B model.
-
D-OPSD: On-Policy Self-Distillation for Continuously Tuning Step-Distilled Diffusion Models
D-OPSD enables continuous supervised fine-tuning of few-step diffusion models via on-policy self-distillation where the model acts as both teacher (multimodal context) and student (text-only context) on its own roll-outs.
-
Beyond GRPO and On-Policy Distillation: An Empirical Sparse-to-Dense Reward Principle for Language-Model Post-Training
Sparse RL on a strong teacher followed by dense distillation to the student outperforms direct GRPO on the student for math tasks, with a forward-KL + OPD bridge enabling further gains.
Reference graph
Works this paper leans on
-
[1]
Initial sampling:Select the first 10K questions in OpenR1-Math (or Codeforces), and sample 1 initial model responsesy initial per questionx,
-
[2]
The 10K initial responses are roughly split into 5K correct and 5K incorrect responses
Verification:Verify the binary reward r∈ { 0, 1} for each yinitial, and build self- revision promptP r. The 10K initial responses are roughly split into 5K correct and 5K incorrect responses
-
[3]
Self-Revision:For each correct initial response, prompt the model to generate 3 rephrased responses yrevised; For each incorrect initial response, prompt the model to generate 3 corrected responsesy revised,
-
[4]
wait,” “hold on
Filtering:Keep traces (x, yinitial, Pr, yrevised) where yrevised reaches a correct final answer. The resulting training data contain 6K self-revision traces. In Self-Distillation phase, we directly sample an additional 9K question-answer pairs from OpenR1-Math (or Codeforces) as training data. C.2 Comparing Sampling Budgets One feature of SD-ZEROis sample...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.