Recognition: no theorem link
Beyond GRPO and On-Policy Distillation: An Empirical Sparse-to-Dense Reward Principle for Language-Model Post-Training
Pith reviewed 2026-05-13 05:01 UTC · model grok-4.3
The pith
Sparse sequence-level rewards work best on larger teacher models; dense token-level rewards then compress their behavior into smaller students.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
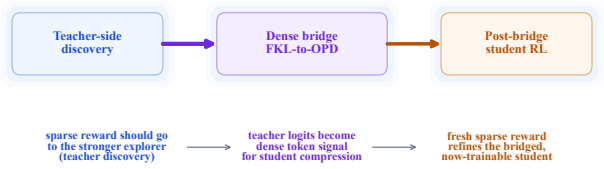
In verifiable math post-training, sparse sequence-level reward should train the strongest available model to produce reward-shaped behavior, after which dense token-level teacher supervision transfers that behavior to the smaller deployment model. At fixed 1.7B student size, RL on the 8B teacher followed by the dense bridge outperforms direct GRPO on the student, while pre-RL teacher transfer underperforms. The bridge is the strongest route: forward-KL warmup on teacher rollouts then OPD on student rollouts yields top MATH scores before any further student RL and also improves later GRPO effectiveness by 3.1 points over a matched control.
What carries the argument
The sparse-to-dense reward allocation rule, realized through a dense bridge of forward-KL divergence warmup on teacher rollouts followed by on-policy distillation (OPD) on student rollouts.
If this is right
- An RL-improved larger teacher plus dense bridge beats direct sparse RL on the same small student.
- Transferring from the teacher before any RL underperforms the bridged route.
- The forward-KL-plus-OPD bridge produces the strongest MATH scores and best pre-Stage-3 AIME endpoints among tested teachers.
- Student-side sparse RL becomes effective only after the bridge, lifting MATH from 75.4% to 78.5% and beating a replay control by 2.8 points.
Where Pith is reading between the lines
- The principle suggests reordering training stages by model capacity whenever verifiable data is the bottleneck.
- Similar density-matching logic could be tested in other verifiable domains such as code or science question answering.
- Hybrid schedules that alternate sparse and dense phases might further reduce the data needed to reach a target student performance.
Load-bearing premise
That the observed performance gaps result from the choice of reward density allocation rather than differences in total compute, data volume, or hyperparameter tuning across the compared training pipelines.
What would settle it
A re-run of the 8B-teacher-to-1.7B-student comparisons in which every pipeline is matched for exact total FLOPs, total labeled examples seen, and identical hyperparameter search budgets, checking whether the dense-bridge advantage remains.
Figures
read the original abstract
In settings where labeled verifiable training data is the binding constraint, each checked example should be allocated carefully. The standard practice is to use this data directly on the model that will be deployed, for example by running GRPO on the deployment student. We argue that this is often an inefficient allocation because it overlooks a reward-density principle: sparse sequence-level reward should train models where exploration is productive, while dense token-level teacher reward should be used where the aim is to compress behavior into a smaller model. In this view, GRPO-style sparse RL and OPD-style dense teacher supervision are not separate recipes; they are different reward-density regimes. The allocation rule is simple: use scarce labeled training data upstream on the strongest model that can turn it into reward-shaped behavior, then transfer that behavior downstream as dense supervision. We evaluate this rule on verifiable math with Qwen3 and Llama models. At fixed Qwen3-1.7B deployment-student size, an RL-improved 8B teacher distilled through the dense bridge outperforms direct GRPO on the same student, while transfer from the same teacher before RL underperforms. The bridge is important: a forward-KL warmup on teacher rollouts followed by OPD on student rollouts is consistently strongest on MATH before any post-bridge student-side sparse RL, and also gives the best pre-Stage~3 AIME endpoints for the canonical 8B/14B teachers. The bridge also makes later student-side sparse RL effective: GRPO that is weak on a cold student lifts MATH from $75.4\%$ to $78.5\%$ after the bridge and outperforms a matched replay control by $2.8$ points. The operational principal is to avoid using scarce labeled data on the least prepared policy: use sparse reward for teacher-side discovery, dense transfer for student compression, and student-side sparse reward only after the bridge.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that scarce labeled verifiable data for LM post-training is best allocated according to a sparse-to-dense reward principle: apply sparse sequence-level rewards (GRPO-style) on larger teacher models to discover improved behavior, then transfer that behavior to smaller deployment students via dense token-level supervision (a forward-KL warmup on teacher rollouts followed by on-policy distillation). At fixed 1.7B student size, an RL-improved 8B teacher distilled through this bridge outperforms direct GRPO on the student (e.g., lifting MATH from 75.4% to 78.5% and outperforming replay by 2.8 points), while pre-RL teacher transfer underperforms; the bridge also enables effective later student-side sparse RL and yields strong AIME results for 8B/14B teachers.
Significance. If the central empirical ordering holds under matched compute, the work supplies a practical, testable allocation heuristic that separates exploration (sparse reward on capable models) from compression (dense transfer to students). It offers concrete pipeline comparisons on MATH and AIME with Qwen3 and Llama models, showing that the distillation bridge is load-bearing for the reported gains and that student-side GRPO becomes effective only after the bridge.
major comments (2)
- [Abstract] Abstract and experimental results: The headline ordering (RL-improved 8B teacher + dense bridge > direct GRPO on 1.7B student; pre-RL transfer underperforms) is presented with specific lifts (75.4% → 78.5% MATH, +2.8 over replay) but without explicit confirmation that total FLOPs, number of gradient steps, labeled examples processed, or hyperparameter search budgets were equalized across the GRPO-only, teacher-RL, and bridge pipelines. This equality is load-bearing for attributing gains to the sparse-to-dense allocation rather than unequal training effort.
- [Experiments] The manuscript reports that the forward-KL warmup + OPD bridge is consistently strongest and enables later student-side GRPO, yet provides no variance estimates, data-split details, or ablation isolating the bridge from differences in rollout volume or learning-rate schedules. Without these controls, the claim that the reward-density principle itself drives the pre- vs. post-bridge ordering cannot be fully evaluated.
minor comments (1)
- [Method] The description of the dense bridge (forward-KL warmup on teacher rollouts followed by OPD on student rollouts) would benefit from an explicit equation or pseudocode block showing the combined loss and the exact point at which student rollouts begin.
Simulated Author's Rebuttal
We are grateful to the referee for the insightful review and the recommendation for major revision. The two major comments focus on experimental controls and reporting, which we will fully address in the revised manuscript. Our point-by-point responses follow.
read point-by-point responses
-
Referee: [Abstract] Abstract and experimental results: The headline ordering (RL-improved 8B teacher + dense bridge > direct GRPO on 1.7B student; pre-RL transfer underperforms) is presented with specific lifts (75.4% → 78.5% MATH, +2.8 over replay) but without explicit confirmation that total FLOPs, number of gradient steps, labeled examples processed, or hyperparameter search budgets were equalized across the GRPO-only, teacher-RL, and bridge pipelines. This equality is load-bearing for attributing gains to the sparse-to-dense allocation rather than unequal training effort.
Authors: The referee correctly identifies that the manuscript does not currently include explicit confirmation of equalized total FLOPs, gradient steps, labeled examples, or hyperparameter budgets across the compared pipelines. We will revise the paper to add a compute analysis section that reports these quantities for the GRPO-only, teacher-RL, and bridge methods, ensuring they are matched. This will substantiate that the observed gains stem from the sparse-to-dense allocation. revision: yes
-
Referee: [Experiments] The manuscript reports that the forward-KL warmup + OPD bridge is consistently strongest and enables later student-side GRPO, yet provides no variance estimates, data-split details, or ablation isolating the bridge from differences in rollout volume or learning-rate schedules. Without these controls, the claim that the reward-density principle itself drives the pre- vs. post-bridge ordering cannot be fully evaluated.
Authors: The referee is correct that variance estimates, data-split details, and isolating ablations are missing. We will revise to include standard deviation from repeated runs, clarify the data splits used, and provide ablations that control for rollout volume and learning rate schedules. These additions will strengthen the evaluation of the reward-density principle. revision: yes
Circularity Check
No circularity: purely empirical evaluation of training pipelines
full rationale
The paper advances an empirical principle for allocating sparse versus dense rewards in LM post-training by comparing concrete pipelines (GRPO on student, RL on teacher then dense bridge via forward-KL + OPD, pre-RL transfer) on MATH and AIME with Qwen3/Llama models. Performance deltas such as 75.4% to 78.5% MATH after bridge are reported as experimental outcomes, not as outputs of any derivation, equation, or fitted parameter that is defined in terms of the target result. No self-definitional steps, fitted inputs renamed as predictions, load-bearing self-citations, uniqueness theorems, or ansatzes appear in the provided text. The argument rests on direct measurement of training sequences rather than any chain that reduces to its own inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
Yuntao Bai, Andy Jones, Kamal Ndousse, Amanda Askell, Anna Chen, Nova DasSarma, Dawn Drain, Stanislav Fort, Deep Ganguli, Tom Henighan, et al. Training a helpful and harmless assistant with reinforcement learning from human feedback.arXiv preprint arXiv:2204.05862,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Rubric-based On-policy Distillation
Junfeng Fang, Zhepei Hong, Mao Zheng, Mingyang Song, Gengsheng Li, Houcheng Jiang, Dan Zhang, Haiyun Guo, Xiang Wang, and Tat-Seng Chua. Rubric-based on-policy distillation.arXiv preprint arXiv:2605.07396, 2026a. 9 Zhen Fang, Wenxuan Huang, Yu Zeng, Yiming Zhao, Shuang Chen, Kaituo Feng, Yunlong Lin, Lin Chen, Zehui Chen, Shaosheng Cao, and Feng Zhao. Flo...
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, et al. The Llama 3 herd of models.arXiv preprint arXiv:2407.21783,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Self-Distillation Zero: Self-Revision Turns Binary Rewards into Dense Supervision
Yinghui He, Simran Kaur, Adithya Bhaskar, Yongjin Yang, Jiarui Liu, Narutatsu Ri, Liam Fowl, Abhishek Panigrahi, Danqi Chen, et al. Self-distillation zero: Self-revision turns binary rewards into dense supervision.arXiv preprint arXiv:2604.12002,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Distilling the Knowledge in a Neural Network
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distilling the knowledge in a neural network.arXiv preprint arXiv:1503.02531,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Uni-OPD: Unifying On-Policy Distillation with a Dual-Perspective Recipe
Wenjin Hou, Shangpin Peng, Weinong Wang, Zheng Ruan, Yue Zhang, Zhenglin Zhou, Mingqi Gao, Yifei Chen, Kaiqi Wang, et al. Uni-OPD: Unifying on-policy distillation with a dual-perspective recipe.arXiv preprint arXiv:2605.03677,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Cheng-Yu Hsieh, Chun-Liang Li, Chih-Kuan Yeh, Hootan Nakhost, Yasuhisa Fujii, Alexander Ratner, Ranjay Krishna, Chen-Yu Lee, and Tomas Pfister. Distilling step-by-step! Outperforming larger language models with less training data and smaller model sizes. InFindings of the Association for Computational Linguistics: ACL 2023,
work page 2023
-
[8]
Beyond correctness: Learning robust reasoning via transfer.arXiv preprint arXiv:2602.08489,
Hyunseok Lee, Soheil Abbasloo, Jihoon Tack, and Jinwoo Shin. Beyond correctness: Learning robust reasoning via transfer.arXiv preprint arXiv:2602.08489,
-
[9]
Explanations from large language models make small reasoners better.arXiv preprint arXiv:2210.06726,
Shiyang Li, Jianshu Chen, Yelong Shen, Zhiyu Chen, Xinlu Zhang, Zekun Li, Hong Wang, Jing Qian, Baolin Peng, Yi Mao, Wenhu Chen, and Xin Xie. Explanations from large language models make small reasoners better.arXiv preprint arXiv:2210.06726,
-
[10]
Rethinking On-Policy Distillation of Large Language Models: Phenomenology, Mechanism, and Recipe
Yaxuan Li, Yuxin Zuo, Bingxiang He, Jinqian Zhang, Chaojun Xiao, Cheng Qian, Tianyu Yu, Huan-ang Gao, et al. Rethinking on-policy distillation of large language models: Phenomenology, mechanism, and recipe.arXiv preprint arXiv:2604.13016,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
ORBIT: On-policy Exploration-Exploitation for Controllable Multi-Budget Reasoning
Kun Liang, Clive Bai, Xin Xu, Chenming Tang, Sanwoo Lee, Weijie Liu, Saiyong Yang, and Yunfang Wu. ORBIT: On-policy exploration-exploitation for controllable multi-budget reasoning.arXiv preprint arXiv:2601.08310,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Knowledge distillation with training wheels.arXiv preprint arXiv:2502.17717,
Guanlin Liu, Anand Ramachandran, Tanmay Gangwani, Yan Fu, and Abhinav Sethy. Knowledge distillation with training wheels.arXiv preprint arXiv:2502.17717,
-
[13]
doi: 10.64434/tml.20251026. https://thinkingmachines.ai/blog/ on-policy-distillation/. Trung Quoc Luong, Xinbo Zhang, Zhanming Jie, Peng Sun, Xiaoran Jin, and Hang Li. ReFT: Rea- soning with reinforced fine-tuning. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics,
-
[14]
CRISP: Compressed Reasoning via Iterative Self-Policy Distillation
Hejian Sang, Yuanda Xu, Zhengze Zhou, Ran He, Zhipeng Wang, and Jiachen Sun. CRISP: Compressed reasoning via iterative self-policy distillation.arXiv preprint arXiv:2603.05433,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y .K. Li, Y . Wu, and Daya Guo. DeepSeekMath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
HybridFlow: A Flexible and Efficient RLHF Framework
Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, and Chuan Wu. HybridFlow: A flexible and efficient RLHF framework.arXiv preprint arXiv:2409.19256,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
A Survey of On-Policy Distillation for Large Language Models
Mingyang Song and Mao Zheng. A survey of on-policy distillation for large language models.arXiv preprint arXiv:2604.00626,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Skill-SD: Skill-Conditioned Self-Distillation for Multi-turn LLM Agents
Hao Wang, Guozhi Wang, Han Xiao, Yufeng Zhou, Yue Pan, Jichao Wang, Ke Xu, Yafei Wen, Xiaohu Ruan, Xiaoxin Chen, and Honggang Qi. Skill-SD: Skill-conditioned self-distillation for multi-turn LLM agents.arXiv preprint arXiv:2604.10674, 2026a. Jiaqi Wang, Wenhao Zhang, Weijie Shi, Yaliang Li, and James Cheng. TCOD: Exploring tem- poral curriculum in on-poli...
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
MiMo-V2-Flash Technical Report
URL https://arxiv.org/ abs/2601.02780. Yuanda Xu, Hejian Sang, Zhengze Zhou, Ran He, and Zhipeng Wang. PACED: Distillation and on-policy self-distillation at the frontier of student competence.arXiv preprint arXiv:2603.11178, 2026a. Yuanda Xu, Hejian Sang, Zhengze Zhou, Ran He, Zhipeng Wang, and Alborz Geramifard. TIP: Token importance in on-policy distil...
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388,
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Chenxu Yang, Chuanyu Qin, Qingyi Si, Minghui Chen, Naibin Gu, Dingyu Yao, Zheng Lin, Weiping Wang, Jiaqi Wang, et al. Self-distilled RLVR.arXiv preprint arXiv:2604.03128,
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
Black-box on-policy distillation of large language models.arXiv preprint arXiv:2511.10643,
11 Tianzhu Ye, Li Dong, Zewen Chi, Xun Wu, Shaohan Huang, and Furu Wei. Black-box on-policy distillation of large language models.arXiv preprint arXiv:2511.10643,
-
[24]
On-Policy Context Distillation for Language Models
Tianzhu Ye, Li Dong, Xun Wu, Shaohan Huang, and Furu Wei. On-policy context distillation for language models.arXiv preprint arXiv:2602.12275,
work page internal anchor Pith review arXiv
-
[25]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu, Zheng Sun, Xiang Shen, Liang Gao, Ziyi Pan, et al. DAPO: An open-source llm reinforcement learning system.arXiv preprint arXiv:2503.14476,
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
The Illusion of Certainty: Decoupling Capability and Calibration in On-Policy Distillation
Jiaxin Zhang, Xiangyu Peng, Qinglin Chen, Qinyuan Ye, Caiming Xiong, and Chien-Sheng Wu. The illusion of certainty: Decoupling capability and calibration in on-policy distillation.arXiv preprint arXiv:2604.16830, 2026a. Zhaoyang Zhang, Shuli Jiang, Yantao Shen, Yuting Zhang, Dhananjay Ram, Shuo Yang, Zhuowen Tu, Wei Xia, and Stefano Soatto. Reinforcement-...
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[27]
formulate KD as entropy-regularized value optimization with on-policy and off-policy demonstrations, while Zhang et al. [2026b] propose RL-aware distillation through advantage-aware selective imitation during PPO/GRPO-style updates. Further OPD work studies a forward-then-reverse KL schedule [Xu et al., 2026a], analyzes which student-state tokens carry th...
work page 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.