Recognition: unknown
TIPSv2: Advancing Vision-Language Pretraining with Enhanced Patch-Text Alignment
Pith reviewed 2026-05-10 15:55 UTC · model grok-4.3
The pith
Patch-level distillation lets student vision-language models surpass their teachers in dense patch-text alignment.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
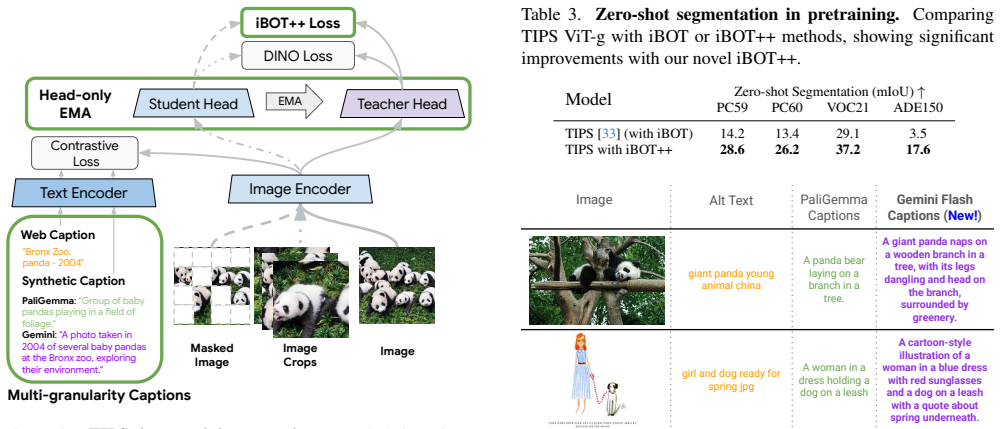
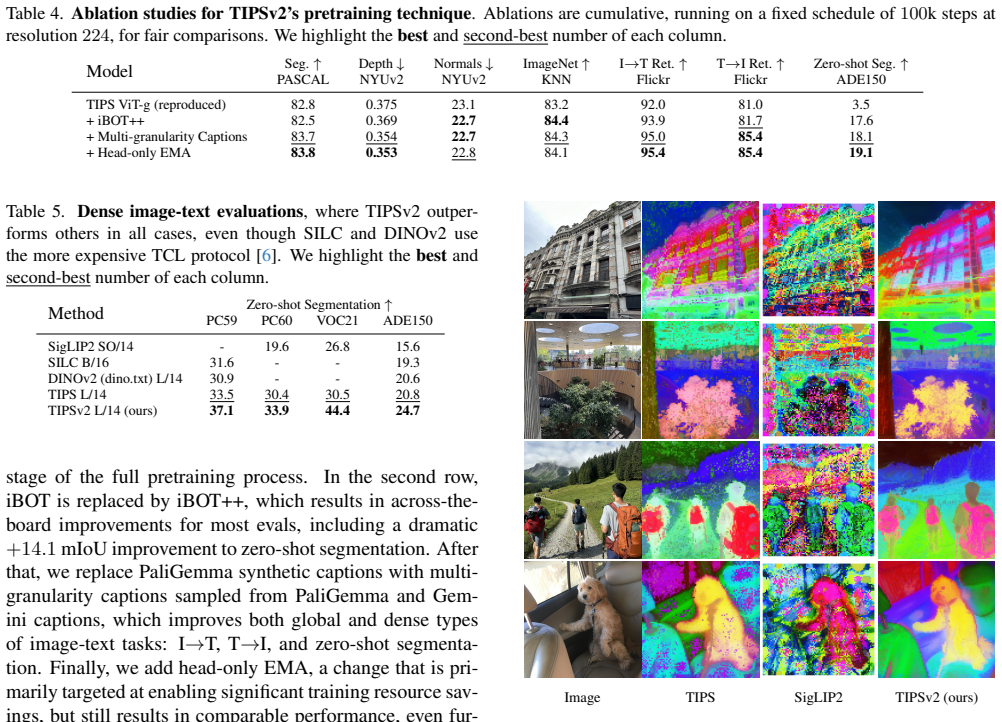
A patch-level distillation procedure significantly boosts dense patch-text alignment, with the distilled student model strongly surpassing the teacher. This observation leads to iBOT++, an upgrade to the standard iBOT masked-image objective in which unmasked tokens contribute directly to the loss and thereby enhance alignment. Combined with modifications to the exponential moving average and a caption sampling strategy that exploits synthetic captions at different granularities, the resulting TIPSv2 image-text encoder models achieve strong performance on a wide range of downstream applications.
What carries the argument
iBOT++, the modified masked-image modeling objective in which unmasked tokens also contribute directly to the loss, carrying the improved patch-text alignment signal into pretraining.
If this is right
- TIPSv2 models deliver improved results on classification, retrieval, segmentation, and depth prediction.
- Dense patch-text alignment becomes a stronger foundation for tasks that require pixel-level correspondence between vision and language.
- Pretraining efficiency rises from the revised EMA schedule and multi-granularity caption sampling.
- The same components can be combined with other vision encoders to produce families suitable for many downstream applications.
Where Pith is reading between the lines
- The student-surpassing-teacher phenomenon may appear in other distillation settings and could prompt broader re-examination of teacher-student dynamics in self-supervised learning.
- The caption sampling approach could be adapted to improve alignment when training on purely synthetic or noisy text sources in other multimodal domains.
- Extending the iBOT++ loss to video or 3D data might yield similar alignment gains for spatio-temporal or volumetric tasks.
Load-bearing premise
The measured gains in patch-text alignment and downstream performance are caused by the proposed distillation step, iBOT++ loss, EMA changes, and caption sampling rather than by other unstated training details or data choices.
What would settle it
Train an identical student without the patch-level distillation objective and measure whether its patch-text alignment still exceeds the teacher or whether the downstream gains on segmentation and depth tasks disappear.
Figures







read the original abstract
Recent progress in vision-language pretraining has enabled significant improvements to many downstream computer vision applications, such as classification, retrieval, segmentation and depth prediction. However, a fundamental capability that these models still struggle with is aligning dense patch representations with text embeddings of corresponding concepts. In this work, we investigate this critical issue and propose novel techniques to enhance this capability in foundational vision-language models. First, we reveal that a patch-level distillation procedure significantly boosts dense patch-text alignment -- surprisingly, the patch-text alignment of the distilled student model strongly surpasses that of the teacher model. This observation inspires us to consider modifications to pretraining recipes, leading us to propose iBOT++, an upgrade to the commonly-used iBOT masked image objective, where unmasked tokens also contribute directly to the loss. This dramatically enhances patch-text alignment of pretrained models. Additionally, to improve vision-language pretraining efficiency and effectiveness, we modify the exponential moving average setup in the learning recipe, and introduce a caption sampling strategy to benefit from synthetic captions at different granularities. Combining these components, we develop TIPSv2, a new family of image-text encoder models suitable for a wide range of downstream applications. Through comprehensive experiments on 9 tasks and 20 datasets, we demonstrate strong performance, generally on par with or better than recent vision encoder models. Code and models are released via our project page at https://gdm-tipsv2.github.io/ .
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces TIPSv2 for vision-language pretraining, emphasizing improved dense patch-text alignment. It proposes a patch-level distillation procedure (where the student reportedly surpasses the teacher), an iBOT++ objective that incorporates unmasked tokens into the loss, modifications to the EMA teacher setup, and a caption sampling strategy leveraging synthetic captions at varying granularities. Comprehensive experiments are reported across 9 tasks and 20 datasets, with performance generally on par with or exceeding recent vision encoders; code and pretrained models are released.
Significance. If the reported gains in patch-text alignment and downstream performance are attributable to the proposed components, the work could meaningfully advance fine-grained VL understanding for tasks such as segmentation and depth estimation. The release of code, weights, and ablation tables supporting reproducibility is a clear strength, as is the empirical consistency across multiple benchmarks.
major comments (2)
- [§4.2] §4.2 (patch-level distillation results): the central observation that the distilled student exceeds the teacher in patch-text alignment is load-bearing for the subsequent design choices (iBOT++, EMA, caption sampling). The manuscript should report the exact alignment metric (e.g., cosine similarity per patch or retrieval recall), the number of runs, and error bars or statistical significance tests; without these, it is difficult to rule out training variance as the source of the reported superiority.
- [Table 7] Table 7 (component ablations): while each addition is isolated, the table does not control for total training compute or data composition across variants. Because the weakest assumption is that gains stem from the proposed changes rather than unstated hyper-parameters or data selection, an additional row or column showing matched-FLOP or matched-data ablations would be required to support the causal claim.
minor comments (3)
- [§3.1] §3.1: the description of the iBOT++ loss would benefit from an explicit equation contrasting it with the original iBOT formulation (e.g., showing the additional term for unmasked tokens) to aid reproducibility.
- [Figure 3] Figure 3 (alignment visualizations): the color scale and patch overlay are difficult to interpret at the printed resolution; adding quantitative per-patch scores alongside the qualitative examples would improve clarity.
- [Related Work] Related work section: several recent dense VL alignment papers (e.g., on patch-level contrastive losses) are cited only in passing; a short paragraph situating TIPSv2 against them would strengthen the positioning.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and positive overall assessment of TIPSv2. We address each major comment below with clarifications and plans for revision.
read point-by-point responses
-
Referee: [§4.2] §4.2 (patch-level distillation results): the central observation that the distilled student exceeds the teacher in patch-text alignment is load-bearing for the subsequent design choices (iBOT++, EMA, caption sampling). The manuscript should report the exact alignment metric (e.g., cosine similarity per patch or retrieval recall), the number of runs, and error bars or statistical significance tests; without these, it is difficult to rule out training variance as the source of the reported superiority.
Authors: We agree that more precise reporting is needed to substantiate the key observation in §4.2. We will revise this section to explicitly define the alignment metric as the average cosine similarity between patch embeddings and corresponding text embeddings over a held-out set of densely annotated image-text pairs. We will also report the number of runs conducted and include error bars (or note variance across checkpoints) to demonstrate robustness against training stochasticity. These changes will be incorporated in the revised manuscript. revision: yes
-
Referee: [Table 7] Table 7 (component ablations): while each addition is isolated, the table does not control for total training compute or data composition across variants. Because the weakest assumption is that gains stem from the proposed changes rather than unstated hyper-parameters or data selection, an additional row or column showing matched-FLOP or matched-data ablations would be required to support the causal claim.
Authors: We appreciate this point on strengthening the causal interpretation of Table 7. All ablation variants were trained with identical data composition, hyperparameters, and training steps, differing only in the isolated component. In revision we will add a column to Table 7 reporting relative FLOPs for each variant (confirming they are matched by design) and add clarifying text on the controlled data setup. A full new row of matched-data ablations would require substantial additional compute that is not currently available, but the existing controls already isolate the proposed changes; we will note this limitation explicitly. revision: partial
Circularity Check
No significant circularity; empirical claims are self-contained
full rationale
The manuscript is an empirical contribution that introduces patch-level distillation, an iBOT++ objective variant, EMA modifications, and caption sampling, then validates them via ablations and benchmarks on 9 tasks across 20 datasets. No equations, predictions, or first-principles derivations appear that reduce outputs to quantities defined by the paper's own fitted parameters or self-referential inputs. Prior methods such as iBOT are cited as external baselines rather than load-bearing self-citations that close the argument. Performance gains are presented as measured results, not as logical necessities derived from the inputs themselves.
Axiom & Free-Parameter Ledger
free parameters (1)
- training hyperparameters
axioms (1)
- domain assumption Distillation and masked image modeling objectives transfer alignment benefits from teacher to student and from unmasked tokens.
Forward citations
Cited by 4 Pith papers
-
MulTaBench: Benchmarking Multimodal Tabular Learning with Text and Image
MulTaBench is a new collection of 40 image-tabular and text-tabular datasets designed to test target-aware representation tuning in multimodal tabular models.
-
LookWhen? Fast Video Recognition by Learning When, Where, and What to Compute
LookWhen factorizes video recognition into learning when, where, and what to compute via uniqueness-based token selection and dual-teacher distillation, achieving better accuracy-FLOPs trade-offs than baselines on mul...
-
Image Generators are Generalist Vision Learners
Image generation pretraining produces generalist vision models that reframe perception tasks as image synthesis and reach SOTA results on segmentation, depth estimation, and other 2D/3D tasks.
-
Image Generators are Generalist Vision Learners
Image generation pretraining builds generalist vision models that reach SOTA on 2D and 3D perception tasks by reframing them as RGB image outputs.
Reference graph
Works this paper leans on
-
[1]
Alabdulmohsin, X
I. Alabdulmohsin, X. Zhai, A. Kolesnikov, and L. Beyer. Getting ViT in Shape: Scaling Laws for Compute-Optimal Model Design. InProc. NeurIPS, 2023. 11
2023
-
[2]
Assran, Q
M. Assran, Q. Duval, I. Misra, P. Bojanowski, P. Vincent, M. Rabbat, Y . LeCun, and N. Ballas. Self-Supervised Learning from Images with a Joint-Embedding Predictive Architec- ture. InProc. ICCV, 2023. 2
2023
-
[3]
PaliGemma: A versatile 3B VLM for transfer
L. Beyer, A. Steiner, A. Pinto, A. Kolesnikov, X. Wang, D. Salz, M. Neumann, I. Alabdulmohsin, M. Tschannen, E. Bugliarello, T. Unterthiner, D. Keysers, S. Koppula, F. Liu, A. Grycner, A. Gritsenko, N. Houlsby, M. Kumar, K. Rong, J. Eisenschlos, R. Kabra, M. Bauer, M. Boˇsnjak, X. Chen, M. Minderer, P. V oigtlaender, I. Bica, I. Balazevic, J. Puigcerver, ...
work page internal anchor Pith review arXiv 2024
-
[4]
Perception Encoder: The best visual embeddings are not at the output of the network
D. Bolya, P. Huang, P. Sun, J. Cho, A. Madotto, C. Wei, T. Ma, J. Zhi, J. Rajasegaran, H. Rasheed, J. Wang, M. Mon- teiro, H. Xu, S. Dong, N. Ravi, D. Li, P. Doll ´ar, and C. Fe- ichtenhofer. Perception Encoder: The best visual embed- dings are not at the output of the network.arXiv:2504.13181,
work page internal anchor Pith review arXiv
-
[5]
Caron, H
M. Caron, H. Touvron, I. Misra, H. Jegou, J. Mairal, P. Bojanowski, and A. Joulin. Emerging Properties in Self- Supervised Vision Transformers. InProc. ICCV, 2021. 1, 2, 3, 5
2021
-
[6]
J. Cha, J. Mun, and B. Roh. Learning to generate text- grounded mask for open-world semantic segmentation from only image-text pairs. InProc. CVPR, 2023. 6, 7, 8
2023
-
[7]
T. Chen, S. Kornblith, M. Norouzi, and G. Hinton. A Simple Framework for Contrastive Learning of Visual Representa- tions. InProc. ICML, 2020. 2
2020
-
[8]
X. Chen, H. Fang, T.-Y . Lin, R. Vedantam, S. Gupta, P. Dol- lar, and C. L. Zitnick. Microsoft COCO Captions: Data Col- lection and Evaluation Server.arXiv:1504.00325, 2015. 6
work page internal anchor Pith review arXiv 2015
-
[9]
X. Chen, X. Wang, S. Changpinyo, AJ Piergiovanni, P. Padlewski, D. Salz, S. Goodman, A. Grycner, B. Mustafa, L. Beyer, A. Kolesnikov, J. Puigcerver, N. Ding, K. Rong, H. Akbari, G. Mishra, L. Xue, A. Thapliyal, J. Bradbury, W. Kuo, M. Seyedhosseini, C. Jia, B. Karagol Ayan, C. Riquelme, A. Steiner, A. Angelova, X. Zhai, N. Houlsby, and R. Soricut. PaLI: A...
2023
-
[10]
Cherti, R
M. Cherti, R. Beaumont, R. Wightman, M. Wortsman, G. Ilharco, C. Gordon, C. Schuhmann, L. Schmidt, and J. Jitsev. Reproducible Scaling Laws for Contrastive Language-Image Learning. InProc. CVPR, 2023. 2, 3, 7
2023
-
[11]
Chuang, Y
Y . Chuang, Y . Li, D. Wang, C. Yeh, K. Lyu, R. Raghavendra, J. Glass, L. Huang, J. Weston, L. Zettlemoyer, X. Chen, Z. Liu, S. Xie, W. Yih, S. Li, and H. Xu. Meta CLIP 2: A Worldwide Scaling Recipe. InProc. NeurIPS, 2025. 3
2025
-
[12]
Darcet, M
T. Darcet, M. Oquab, J. Mairal, and P. Bojanowski. Vision Transformers Need Registers. InProc. ICLR, 2024. 7, 10
2024
-
[13]
Dosovitskiy, L
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, J. Uszkoreit, and N. Houlsby. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. InProc. ICLR, 2021. 3
2021
-
[14]
Everingham and J
M. Everingham and J. Winn. The Pascal Visual Ob- ject Classes Challenge 2012 (VOC2012) Development Kit. Pattern Analysis, Statistical Modelling and Computational Learning, Tech. Rep, 2011. 6
2012
-
[15]
Everingham, L
M. Everingham, L. Van Gool, C. Williams, J. Winn, and A. Zisserman. The Pascal Visual Object Classes (VOC) Chal- lenge.IJCV, 2010. 4, 6
2010
- [16]
-
[17]
L. Fan, D. Krishnan, P. Isola, D. Katabi, and Y . Tian. Im- proving CLIP Training with Language Rewrites. InProc. NeurIPS, 2023. 3
2023
-
[18]
Y . Fang, W. Wang, B. Xie, Q. Sun, L. Wu, X. Wang, T. Huang, X. Wang, and Y . Cao. EV A: Exploring the Limits of Masked Visual Representation Learning at Scale. InProc. CVPR, 2023. 3
2023
-
[19]
Y . Fang, Q. Sun, X. Wang, T. Huang, X. Wang, and Y . Cao. EV A-02: A Visual Representation for Neon Genesis.Image and Vision Computing, 2024. 3
2024
-
[20]
E. Fini, M. Shukor, X. Li, P. Dufter, M. Klein, D. Haldimann, S. Aitharaju, V . Costa, L. B ´ethune, Z. Gan, A. Toshev, M. Eichner, M. Nabi, Y . Yang, J. Susskind, and A. El-Nouby. Multimodal Autoregressive Pre-training of Large Vision En- coders. InProc. CVPR, 2025. 2
2025
-
[21]
P. Gao, Z. Lin, R. Zhang, R. Fang, H. Li, H. Li, and Y . Qiao. Mimic before Reconstruct: Enhancing Masked Au- toencoders with Feature Mimicking.IJCV, 2023. 2
2023
-
[22]
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Gemini Team, Google. Gemini 1.5: Unlocking Multi- modal Understanding Across Millions of Tokens of Context. arXiv:2403.05530, 2024. 2, 6
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
Grill, F
J.-B. Grill, F. Strub, F. Altch ´e, C. Tallec, P. Richemond, E. Buchatskaya, C. Doersch, B. Avila Pires, Z. Guo, and M. Gheshlaghi Azar. Bootstrap Your Own Latent - A New Ap- proach to Self-Supervised Learning. InProc. NeurIPS, 2020. 5
2020
-
[24]
K. He, H. Fan, Y . Wu, S. Xie, and R. Girshick. Momentum Contrast for Unsupervised Visual Representation Learning. InProc. CVPR, 2020. 2, 3
2020
-
[25]
K. He, X. Chen, S. Xie, Y . Li, P. Doll ´ar, and R. Girshick. Masked Autoencoders Are Scalable Vision Learners. In Proc. CVPR, 2022. 2, 5
2022
-
[26]
Hinton, O
G. Hinton, O. Vinyals, and J. Dean. Distilling the Knowledge in a Neural Networ. InProc. NeurIPS Workshops, 2015. 3
2015
-
[27]
Jampani, K.-K
V . Jampani, K.-K. Maninis, A. Engelhardt, A. Karpur, K. Truong, K. Sargent, S. Popov, A. Araujo, R. Martin-Brualla, K. Patel, D. Vlasic, V . Ferrari, A. Makadia, C. Liu, Y . Li, and H. Zhou. Navi: Category-agnostic image collections with high-quality 3d shape and pose annotations. InProc. NeurIPS Datasets and Benchmarks, 2023. 6
2023
-
[28]
C. Jia, Y . Yang, Y . Xia, Y . Chen, Z. Parekh, H. Pham, Q. Le, Y . Sung, Z. Li, and T. Duerig. Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision. InProc. ICML, 2021. 2, 3
2021
-
[29]
C. Jose, T. Moutakanni, D. Kang, F. Baldassarre, T. Darcet, H. Xu, D. Li, M. Szafraniec, M. Ramamonjisoa, M. Oquab, O. Sim´eoni, H. V o, P. Labatut, and P. Bojanowski. DINOv2 Meets Text: A Unified Framework for Image-and Pixel- Level Vision-Language Alignment. InProc. CVPR, 2025. 2, 6, 7
2025
-
[30]
Krause, M
J. Krause, M. Stark, J. Deng, and L. Fei-Fei. 3D Object Representations for Fine-Grained Categorization. InProc. ICCV Workshops, 2013. 6
2013
-
[31]
Z. Lai, H. Zhang, B. Zhang, W. Wu, H. Bai, A. Timofeev, X. Du, Z. Gan, J. Shan, C. Chuah, Y . Yang, and M. Cao. VeCLIP: Improving CLIP Training via Visual-enriched Cap- tions. InProc. ECCV, 2024. 3
2024
-
[32]
Z. Liu, P. Luo, S. Qiu, X. Wang, and X. Tang. DeepFash- ion: Powering Robust Clothes Recognition and Retrieval with Rich Annotations. InProc. CVPR, 2016. 6
2016
-
[33]
Maninis, K
K. Maninis, K. Chen, S. Ghosh, A. Karpur, K. Chen, Y . Xia, B. Cao, D. Salz, G. Han, J. Dlabal, D. Gnanapragasam, M. Seyedhosseini, H. Zhou, and A. Araujo. TIPS: Text-Image Pretraining with Spatial Awareness. InProc. ICLR, 2025. 2, 3, 4, 5, 6, 7, 9, 10, 11
2025
-
[34]
W. Min, Z. Wang, Y . Liu, M. Luo, L. Kang, X. Wei, X. Wei, and S. Jiang. Large Scale Visual Food Recognition.IEEE TPAMI, 2023. 6
2023
-
[35]
Mottaghi, X
R. Mottaghi, X. Chen, P. Liu, S. Fidler, R. Urtasun, and A. Yuille. The Role of Context for Object Detection and Se- mantic Segmentation in the Wild. InProc. CVPR, 2014. 4
2014
-
[36]
M. F. Naeem, Y . Xian, X. Zhai, L. Hoyer, L. Van Gool, and F. Tombari. SILC: Improving Vision Language Pretraining with Self-Distillation. InProc. ECCV, 2024. 3, 6, 7
2024
-
[37]
Y . Onoe, S. Rane, Z. Berger, Y . Bitton, J. Cho, R. Garg, A. Ku, Z. Parekh, J. Pont-Tuset, G. Tanzer, S. Wang, and J. Baldridge. DOCCI: Descriptions of Connected and Con- trasting Images. InProc. ECCV, 2024. 6
2024
-
[38]
Oquab, T
M. Oquab, T. Darcet, T. Moutakanni, H. V o, M. Szafraniec, V . Khalidov, P. Fernandez, D. Haziza, F. Massa, A. El- Nouby, R. Howes, P. Huang, H. Xu, V . Sharma, S. Li, W. Galuba, M. Rabbat, M. Assran, N. Ballas, G. Synnaeve, I. Misra, H. Jegou, J. Mairal, P. Labatut, A. Joulin, and P. Bo- janowski. DINOv2: Learning Robust Visual Features with- out Supervi...
2024
- [39]
-
[40]
Radford, J
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, G. Krueger, and I. Sutskever. Learning Transferable Visual Models from Natural Language Supervision. InProc. ICML,
-
[41]
Ranftl, A
R. Ranftl, A. Bochkovskiy, and V . Koltun. Vision Transform- ers for Dense Prediction. InProc. ICCV, 2021. 6
2021
-
[42]
Russakovsky, J
O. Russakovsky, J. Deng, H. Su, J. Krause, S. Satheesh, S. Ma, Z. Huang, A. Karpathy, A. Khosla, M. Bernstein, A. Berg, and L. Fei-Fei. ImageNet Large Scale Visual Recog- nition Challenge.IJCV, 2015. 6
2015
-
[43]
Shazeer and M
N. Shazeer and M. Stern. Adafactor: Adaptive Learning Rates with Sublinear Memory Cost. InProc. ICML, 2018. 12
2018
-
[44]
Silberman, D
N. Silberman, D. Hoiem, P. Kohli, and R. Fergus. Indoor Segmentation and Support Inference from RGBD Images. In Proc. ECCV, 2012. 6
2012
-
[45]
O. Sim ´eoni, H. V o, M. Seitzer, F. Baldassarre, M. Oquab, C. Jose, V . Khalidov, M. Szafraniec, S. Yi, M. Ramamonjisoa, F. Massa, D. Haziza, L. Wehrstedt, J. Wang, T. Darcet, T. Moutakanni, L. Sentana, C. Roberts, A. Vedaldi, J. Tolan, J. Brandt, C. Couprie, J. Mairal, H. J ´egou, P. Labatut, and P. Bojanowski. DINOv3.arXiv:2508.10104, 2025. 1, 2, 4, 7, 8, 10
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[46]
H. Song, Y . Xiang, S. Jegelka, and S. Savarese. Deep Metric Learning via Lifted Structured Feature Embedding. InProc. CVPR, 2016. 6
2016
-
[47]
Stone, H
A. Stone, H. Soltau, R. Geirhos, X. Yi, Y . Xia, B. Cao, K. Chen, A. Ogale, and J. Shlens. Learning Visual Composition through Improved Semantic Guidance. InProc. CVPR, 2025. 3
2025
-
[48]
Q. Sun, Y . Fang, L. Wu, X. Wang, and Y . Cao. EV A- CLIP: Improved Training Techniques for CLIP at Scale. arXiv:2303.15389, 2023. 3
work page internal anchor Pith review arXiv 2023
-
[49]
Tschannen, M
M. Tschannen, M. Kumar, A. Steiner, X. Zhai, N. Houlsby, and L. Beyer. Image Captioners Are Scalable Vision Learn- ers Too. InProc. NeurIPS, 2023. 2
2023
-
[50]
M. Tschannen, A. Gritsenko, X. Wang, M. Naeem, I. Al- abdulmohsin, N. Parthasarathy, T. Evans, L. Beyer, Y . Xia, B. Mustafa, O. H´enaff, J. Harmsen, A. Steiner, and X. Zhai. SigLIP 2: Multilingual Vision-Language Encoders with Im- proved Semantic Understanding, Localization, and Dense Features.arXiv:2502.14786, 2025. 2, 3, 7
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[51]
Representation Learning with Contrastive Predictive Coding
A. van den Oord, Y . Li, and O. Vinyals. Repre- sentation Learning with Contrastive Predictive Coding. arXiv:1807.03748, 2018. 3
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[52]
Van Horn, O
G. Van Horn, O. Mac Aodha, Y . Song, Y . Cui, C. Sun, A. Shepard, H. Adam, P. Perona, and S. Belongie. The iNatu- ralist Species Classification and Detection Dataset. InProc. CVPR, 2018. 6
2018
-
[53]
Vaswani, N
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. Gomez, L. Kaiser, and I. Polosukhin. Attention is All You Need. InProc. NeurIPS, 2017. 3
2017
-
[54]
Franca: Nested Matryoshka Clustering for Scalable Visual Representation Learning
S. Venkataramanan, V . Pariza, M. Salehi, L. Knobel, S. Gidaris, E. Ramzi, A. Bursuc, and Y . Asano. Franca: Nested matryoshka clustering for scalable visual represen- tation learning.arXiv:2507.14137, 2025. 7
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[55]
B. Wan, M. Tschannen, Y . Xian, F. Pavetic, I. Alabdul- mohsin, X. Wang, A. Pinto, A. Steiner, L. Beyer, and X. Zhai. LocCa: Visual Pretraining with Location-aware Cap- tioners. InProc. NeurIPS, 2024. 2
2024
-
[56]
Weyand, A
T. Weyand, A. Araujo, B. Cao, and J. Sim. Google Land- marks Dataset v2 - A Large-Scale Benchmark for Instance- Level Recognition and Retrieval. InProc. CVPR, 2020. 6
2020
-
[57]
Q. Wu, H. Ye, Y . Gu, H. Zhang, L. Wang, and D He. De- noising Masked AutoEncoders Help Robust Classification. InProc. ICLR, 2023. 2
2023
-
[58]
Z. Xie, Z. Zhang, Y . Cao, Y . Lin, J. Bao, Z. Yao, Q. Dai, and H. Hu. SimMIM: A Simple Framework for Masked Image Modeling. InProc. CVPR, 2022. 2
2022
-
[59]
H. Xu, S. Xie, X.Tan, P. Huang, R. Howes, V . Sharma, S. Li, G. Ghosh, L. Zettlemoyer, and C. Feichtenhofer. Demystify- ing CLIP Data. InProc. ICLR, 2025. 3
2025
-
[60]
H. Xue, P. Gao, H. Li, Y . Qiao, H. Sun, H. Li, and J. Luo. Stare at What You See: Masked Image Modeling without Reconstruction. InProc. CVPR, 2023. 2
2023
-
[61]
Young, A
P. Young, A. Lai, M. Hodosh, and J. Hockenmaier. From Im- age Descriptions to Visual Denotations: New Similarity Met- rics for Semantic Inference over Event Descriptions.TACL,
-
[62]
Ypsilantis, N
N.-A. Ypsilantis, N. Garcia, G. Han, S. Ibrahimi, N. Van No- ord, and G. Tolias. The Met Dataset: Instance-level Recog- nition for Artworks. InProc. NeurIPS Datasets and Bench- marks Track, 2021. 6
2021
-
[63]
Ypsilantis, K
N.-A. Ypsilantis, K. Chen, B. Cao, M. Lipovsk ´y, P. Dogan- Sch¨onberger, G. Makosa, B. Bluntschli, M. Seyedhosseini, O. Chum, and A. Araujo. Towards Universal Image Em- beddings: A Large-Scale Dataset and Challenge for Generic Image Representations. InPro. ICCV, 2023. 6
2023
-
[64]
X. Zhai, B. Mustafa, A. Kolesnikov, and L. Beyer. Sig- moid Loss for Language Image Pre-Training. InProc. ICCV,
-
[65]
B. Zhou, H. Zhao, X. Puig, S. Fidler, A. Barriuso, and A. Torralba. Scene Parsing Through ADE20k Dataset. InProc. CVPR, 2017. 4, 6
2017
-
[66]
B. Zhou, H. Zhao, X. Puig, T. Xiao, S. Fidler, A. Barriuso, and A. Torralba. Semantic Understanding of Scenes through the ADE20K Dataset.IJCV, 2019. 4
2019
-
[67]
C. Zhou, C. Loy, and B. Dai. Extract Free Dense Labels from CLIP. InProc. ECCV, 2022. 6
2022
-
[68]
J. Zhou, C. Wei, H. Wang, W. Shen, C. Xie, A. Yuille, and T. Kong. Image Bert Pre-training with Online Tokenizer. In Proc. ICLR, 2022. 1, 2, 3, 4, 5
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.