Recognition: 2 theorem links
· Lean TheoremLookWhen? Fast Video Recognition by Learning When, Where, and What to Compute
Pith reviewed 2026-05-11 01:32 UTC · model grok-4.3
The pith
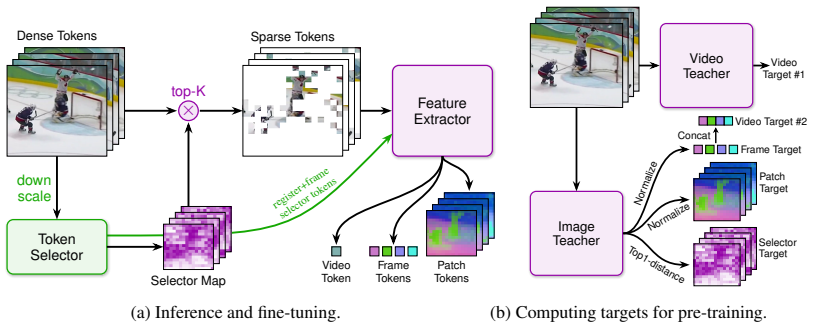
LookWhen selects unique tokens from downscaled videos to approximate full recognition at lower computation cost.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
LookWhen is a selector-extractor framework that factorizes video recognition into learning when, where, and what to compute. The shallow selector scores all tokens across space-time from a scaled-down video using nearest-neighbor uniqueness ranking, and the deep extractor processes only the top-K selected tokens to approximate full-video representations. Selection is pre-trained with uniqueness scores, and extraction uses distillation from both a video teacher and a normalized image teacher to capture changes within videos, yielding general representations for downstream use.
What carries the argument
The selector-extractor framework, where the selector ranks tokens by nearest-neighbor uniqueness on downscaled video input and the extractor approximates full representations through video and image teacher distillation.
If this is right
- Achieves a better accuracy-computation trade-off than efficient models and upgraded baselines of similar size.
- Pareto-dominates accuracy-FLOPs on 9 of 12 cases across 6 tasks and 2 settings.
- Matches or exceeds performance on the remaining cases while delivering higher throughput.
- Yields general representations usable for feature extraction or fine-tuning to specific tasks.
- Applies across diverse video recognition benchmarks including Kinetics-400, SSv2, Epic-Kitchens, Diving48, Jester, and Charades.
Where Pith is reading between the lines
- The downscaling-plus-uniqueness approach may extend to other redundant sequential data such as long audio clips or time-series sensor streams.
- Separating a cheap selector from the heavy extractor opens the possibility of reusing one selector across multiple extractors or tasks.
- Performance on videos of widely varying length or frame rate would test whether the scaled-down uniqueness ranking remains stable.
- Real-time edge-device video analysis could benefit if the selector overhead stays negligible relative to the savings in the extractor.
Load-bearing premise
That ranking tokens by nearest-neighbor uniqueness in a scaled-down video and distilling from video and normalized image teachers produces selections that reliably approximate full-video representations without task-specific supervision.
What would settle it
If, on a held-out video dataset, LookWhen accuracy falls below full-video baselines at matched FLOPs levels or if selected tokens systematically miss key motion events in qualitative review.
Figures












read the original abstract
Transformers dominate video recognition. They split videos into tokens, and processing them has expensive superlinear computational cost. Yet videos are filled with redundancy, so we can question the need for this expense. We introduce LookWhen, a selector-extractor framework that factorizes video recognition into learning when, where, and what to compute. Our shallow selector gets a scaled-down video and quickly scores all tokens across space-time, while our deep extractor gets the top-K selected tokens to approximate full-video representations without actually processing all the tokens. A key challenge is defining effective supervision for selection and extraction. For selection pre-training, we introduce a score on representations that ranks tokens by uniqueness using a simple nearest-neighbor distance. For extraction pre-training, we distill both a video teacher and an image teacher, for which we normalize its frame-wise representations to learn what changes within videos. Through these strategies, our selector-extractor learns general and efficient representations for feature extraction or fine-tuning to a task. Through experiments on Kinetics-400, SSv2, Epic-Kitchens, Diving48, Jester, and Charades, we show that LookWhen achieves a better accuracy-computation trade-off than efficient models and upgraded baselines of similar size. LookWhen Pareto-dominates in accuracy-FLOPs on 9 of 12 cases (6 tasks x 2 settings) and roughly matches on 3. In accuracy-throughput, measuring time in practice, LookWhen is more efficient still at 6.7x faster than InternVideo2-B at equal accuracy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces LookWhen, a selector-extractor framework for efficient video recognition with transformers. A shallow selector processes a scaled-down video and ranks tokens via nearest-neighbor uniqueness to select top-K tokens; a deep extractor then processes only those tokens. Selection is pre-trained unsupervised via the uniqueness score, while extraction uses distillation from a video teacher and a frame-normalized image teacher. Experiments across Kinetics-400, SSv2, Epic-Kitchens, Diving48, Jester, and Charades report that LookWhen Pareto-dominates accuracy-FLOPs trade-offs in 9 of 12 cases (6 tasks × 2 settings) and achieves 6.7× higher throughput than InternVideo2-B at matched accuracy.
Significance. If the empirical trade-offs hold under rigorous validation, the factorization into when/where/what computation offers a practical route to lower inference cost in video transformers without task-specific supervision during pre-training. The combination of unsupervised token ranking and dual-teacher distillation is a concrete contribution that could influence follow-on work on adaptive computation, provided the selected tokens prove reliably informative across domains.
major comments (3)
- [§3] §3 (Selector pre-training): The central claim that nearest-neighbor uniqueness on a scaled-down video produces top-K tokens whose extractor outputs approximate full-video representations rests on an unverified assumption. No ablation or visualization shows that the ranked tokens correlate with motion or action cues rather than static backgrounds or artifacts; this directly affects whether the reported 9/12 Pareto dominance generalizes.
- [Experiments] Experiments section (results tables): The accuracy-FLOPs and accuracy-throughput comparisons lack error bars, multiple random seeds, or statistical tests. Without these, it is impossible to determine whether the claimed dominance over upgraded baselines of similar size is robust or sensitive to post-hoc choices in baseline implementations.
- [§4] §4 (Extraction pre-training): The frame-wise normalization of the image teacher is presented as enabling learning of intra-video changes, yet no controlled comparison quantifies its contribution versus a standard image teacher. This detail is load-bearing for the extraction stage that underpins the efficiency gains.
minor comments (2)
- [Abstract and §3] The abstract and method sections use 'scaled-down video' without specifying the exact spatial or temporal downsampling factors or the resulting token count; adding these numbers would improve reproducibility.
- [Tables in Experiments] Table captions for the 12-case Pareto results should explicitly list the two settings (e.g., fine-tuning vs. linear probing) to avoid ambiguity when comparing to baselines.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive feedback. We address each major comment below, providing clarifications and committing to revisions that strengthen the empirical support for our claims without altering the core contributions.
read point-by-point responses
-
Referee: [§3] §3 (Selector pre-training): The central claim that nearest-neighbor uniqueness on a scaled-down video produces top-K tokens whose extractor outputs approximate full-video representations rests on an unverified assumption. No ablation or visualization shows that the ranked tokens correlate with motion or action cues rather than static backgrounds or artifacts; this directly affects whether the reported 9/12 Pareto dominance generalizes.
Authors: The uniqueness score is defined as the nearest-neighbor distance in the representation space of the downscaled video, which by construction identifies tokens that deviate from their local spatio-temporal context. In practice, this tends to surface dynamic elements because static regions produce low uniqueness scores. While the submitted manuscript does not include explicit token visualizations or an ablation against motion heuristics, the consistent Pareto dominance across six datasets with varying background complexity (including Epic-Kitchens and Charades) provides indirect support. In the revision we will add (i) qualitative visualizations of selected tokens on representative videos and (ii) a quantitative ablation comparing uniqueness selection to random and optical-flow-based alternatives, reporting the resulting accuracy-FLOPs curves. revision: yes
-
Referee: [Experiments] Experiments section (results tables): The accuracy-FLOPs and accuracy-throughput comparisons lack error bars, multiple random seeds, or statistical tests. Without these, it is impossible to determine whether the claimed dominance over upgraded baselines of similar size is robust or sensitive to post-hoc choices in baseline implementations.
Authors: We agree that variability estimates are necessary to substantiate robustness. The reported numbers were obtained from single training runs per configuration due to the high computational cost of video transformer training. In the revised manuscript we will re-train the primary LookWhen variants and the strongest baselines with three independent random seeds, report mean accuracy together with standard deviation, add error bars to all tables and figures, and include a brief note on statistical significance where differences exceed one standard deviation. revision: yes
-
Referee: [§4] §4 (Extraction pre-training): The frame-wise normalization of the image teacher is presented as enabling learning of intra-video changes, yet no controlled comparison quantifies its contribution versus a standard image teacher. This detail is load-bearing for the extraction stage that underpins the efficiency gains.
Authors: Frame-wise normalization subtracts the per-video mean from each frame's representation, thereby directing the image teacher toward temporal differences rather than absolute appearance. Although the current version does not isolate this component with a controlled ablation, the dual-teacher objective (video teacher + normalized image teacher) demonstrably improves the accuracy-FLOPs frontier relative to video-only distillation. We will add an explicit ablation table in the revision that compares the normalized image teacher against an un-normalized image teacher while keeping all other factors fixed, thereby quantifying its isolated contribution to the reported efficiency gains. revision: yes
Circularity Check
No significant circularity; empirical results independent of pre-training definitions
full rationale
The paper defines a selector via nearest-neighbor uniqueness ranking on downscaled video inputs and an extractor via distillation from external video and frame-normalized image teachers; these are explicit design choices with independent supervision signals. The central performance claims (Pareto dominance on 9/12 accuracy-FLOPs cases and 6.7x throughput gain) are established through direct experiments on Kinetics-400, SSv2, Epic-Kitchens and other benchmarks rather than by algebraic reduction or renaming of the pre-training quantities. No equations equate the final recognition accuracy to the uniqueness scores or distillation losses by construction, no fitted parameters are relabeled as predictions, and no load-bearing self-citations appear in the derivation. The method is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- top-K
axioms (1)
- domain assumption Video tokens can be ranked by uniqueness using nearest-neighbor distance in representation space without task labels.
invented entities (1)
-
LookWhen selector-extractor framework
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanbare_distinguishability_of_absolute_floor echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
We propose 'top1-distance', which ranks each token by its distance to its nearest neighbor in feature space... U_{x,y,t}=1−max_{(x',y',t')≠(x,y,t)} cos(z^{DINOv3}_{x,y,t}, z^{DINOv3}_{x',y',t'})
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
LookWhen Pareto-dominates in accuracy-FLOPs on 9 of 12 cases... 6.7× faster than InternVideo2-B
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Attention is all you need.Advances in neural information processing systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017
work page 2017
-
[2]
Vivit: A video vision transformer
Anurag Arnab, Mostafa Dehghani, Georg Heigold, Chen Sun, Mario Lu ˇci´c, and Cordelia Schmid. Vivit: A video vision transformer. InInternational Conference on Computer Vision (ICCV), 2021
work page 2021
-
[3]
Zhan Tong, Yibing Song, Jue Wang, and Limin Wang. Videomae: Masked autoencoders are data-efficient learners for self-supervised video pre-training.Advances in neural information processing systems, 35:10078–10093, 2022
work page 2022
-
[4]
Anticipative video transformer
Rohit Girdhar and Kristen Grauman. Anticipative video transformer. InProceedings of the IEEE/CVF international conference on computer vision, pages 13505–13515, 2021
work page 2021
-
[5]
Videomae v2: Scaling video masked autoencoders with dual masking
Limin Wang, Bingkun Huang, Zhiyu Zhao, Zhan Tong, Yinan He, Yi Wang, Yali Wang, and Yu Qiao. Videomae v2: Scaling video masked autoencoders with dual masking. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 14549–14560, 2023
work page 2023
-
[6]
Anthony Fuller, Yousef Yassin, Junfeng Wen, Tarek Ibrahim, Daniel Kyrollos, James R Green, and Evan Shelhamer. Lookwhere? efficient visual recognition by learning where to look and what to see from self-supervision. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems
-
[7]
Vision transformers need registers
Timothée Darcet, Maxime Oquab, Julien Mairal, and Piotr Bojanowski. Vision transformers need registers. InThe Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[8]
Rohan Choudhury, Guanglei Zhu, Sihan Liu, Koichiro Niinuma, Kris M Kitani, and László A Jeni. Don’t look twice: Faster video transformers with run-length tokenization.Advances in Neural Information Processing Systems, 37:28127–28149, 2024
work page 2024
-
[9]
K-centered patch sampling for efficient video recognition
Seong Hyeon Park, Jihoon Tack, Byeongho Heo, Jung-Woo Ha, and Jinwoo Shin. K-centered patch sampling for efficient video recognition. InEuropean Conference on Computer Vision, pages 160–176. Springer, 2022
work page 2022
-
[10]
Token Merging: Your ViT But Faster
Daniel Bolya, Cheng-Yang Fu, Xiaoliang Dai, Peizhao Zhang, Christoph Feichtenhofer, and Judy Hoffman. Token merging: Your vit but faster.arXiv preprint arXiv:2210.09461, 2022
work page internal anchor Pith review arXiv 2022
-
[11]
vid-tldr: Training free token merging for light-weight video transformer
Joonmyung Choi, Sanghyeok Lee, Jaewon Chu, Minhyuk Choi, and Hyunwoo J Kim. vid-tldr: Training free token merging for light-weight video transformer. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18771–18781, 2024
work page 2024
-
[12]
The kinetics human action video dataset, 2017
Will Kay, Joao Carreira, Karen Simonyan, Brian Zhang, Chloe Hillier, Sudheendra Vijaya- narasimhan, Fabio Viola, Tim Green, Trevor Back, Paul Natsev, Mustafa Suleyman, and Andrew Zisserman. The kinetics human action video dataset, 2017
work page 2017
-
[13]
Raghav Goyal, Samira Ebrahimi Kahou, Vincent Michalski, Joanna Materzynska, Susanne Westphal, Heuna Kim, Valentin Haenel, Ingo Fruend, Peter Yianilos, Moritz Mueller-Freitag, et al. The" something something" video database for learning and evaluating visual common sense. InProceedings of the IEEE international conference on computer vision, pages 5842– 5850, 2017
work page 2017
-
[14]
Scaling egocentric vision: The epic-kitchens dataset
Dima Damen, Hazel Doughty, Giovanni Maria Farinella, Sanja Fidler, Antonino Furnari, Evangelos Kazakos, Davide Moltisanti, Jonathan Munro, Toby Perrett, Will Price, and Michael Wray. Scaling egocentric vision: The epic-kitchens dataset. InEuropean Conference on Computer Vision (ECCV), 2018
work page 2018
-
[15]
Resound: Towards action recognition without representation bias
Yingwei Li, Yi Li, and Nuno Vasconcelos. Resound: Towards action recognition without representation bias. InProceedings of the European conference on computer vision (ECCV), pages 513–528, 2018. 10
work page 2018
-
[16]
The jester dataset: A large-scale video dataset of human gestures
Joanna Materzynska, Guillaume Berger, Ingo Bax, and Roland Memisevic. The jester dataset: A large-scale video dataset of human gestures. InProceedings of the IEEE/CVF international conference on computer vision workshops, pages 0–0, 2019
work page 2019
-
[17]
Sigurdsson, Gül Varol, Xiaolong Wang, Ivan Laptev, Ali Farhadi, and Abhinav Gupta
Gunnar A. Sigurdsson, Gül Varol, Xiaolong Wang, Ivan Laptev, Ali Farhadi, and Abhinav Gupta. Hollywood in homes: Crowdsourcing data collection for activity understanding.ArXiv e-prints, 2016
work page 2016
-
[18]
Internvideo2: Scaling foundation models for multimodal video understanding
Yi Wang, Kunchang Li, Xinhao Li, Jiashuo Yu, Yinan He, Guo Chen, Baoqi Pei, Rongkun Zheng, Zun Wang, Yansong Shi, et al. Internvideo2: Scaling foundation models for multimodal video understanding. InEuropean conference on computer vision, pages 396–416. Springer, 2024
work page 2024
-
[19]
Emerging properties in self-supervised vision transformers
Mathilde Caron, Hugo Touvron, Ishan Misra, Hervé Jégou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerging properties in self-supervised vision transformers. InProceedings of the International Conference on Computer Vision (ICCV), 2021
work page 2021
-
[20]
Spiros Baxevanakis, Platon Karageorgis, Ioannis Dravilas, and Konrad Szewczyk. Do all vision transformers need registers? a cross-architectural reassessment.arXiv preprint arXiv:2603.25803, 2026
-
[21]
Guibas, Dilip Krishnan, Kilian Q Weinberger, Yonglong Tian, and Yue Wang
Jiawei Yang, Katie Z Luo, Jiefeng Li, Congyue Deng, Leonidas J. Guibas, Dilip Krishnan, Kilian Q Weinberger, Yonglong Tian, and Yue Wang. Dvt: Denoising vision transformers. arXiv preprint arXiv:2401.02957, 2024
-
[22]
Vision Transformers Need More Than Registers
Cheng Shi, Yizhou Yu, and Sibei Yang. Vision transformers need more than registers.arXiv preprint arXiv:2602.22394, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[23]
Vision transformers with self-distilled registers
Zipeng Yan, Yinjie Chen, Chong Zhou, Bo Dai, and Andrew Luo. Vision transformers with self-distilled registers. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026
work page 2026
-
[24]
Thicker and quicker: The jumbo token for fast plain vision transformers
Anthony Fuller, Yousef Yassin, Daniel Kyrollos, Evan Shelhamer, and James R Green. Thicker and quicker: The jumbo token for fast plain vision transformers. InThe Fourteenth International Conference on Learning Representations, 2026
work page 2026
-
[25]
V-jepa 2: Self-supervised video models enable understanding, prediction and planning, 2025
Mido Assran, Adrien Bardes, David Fan, Quentin Garrido, Russell Howes, Mojtaba, Komeili, Matthew Muckley, Ammar Rizvi, Claire Roberts, Koustuv Sinha, Artem Zholus, Sergio Arnaud, Abha Gejji, Ada Martin, Francois Robert Hogan, Daniel Dugas, Piotr Bojanowski, Vasil Khalidov, Patrick Labatut, Francisco Massa, Marc Szafraniec, Kapil Krishnakumar, Yong Li, Xia...
work page 2025
-
[26]
Principles of visual tokens for efficient video understanding
Xinyue Hao, Gen Li, Shreyank N Gowda, Robert B Fisher, Jonathan Huang, Anurag Arnab, and Laura Sevilla-Lara. Principles of visual tokens for efficient video understanding. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 21254–21264, 2025
work page 2025
-
[27]
Oriane Siméoni, Huy V . V o, Maximilian Seitzer, Federico Baldassarre, Maxime Oquab, Cijo Jose, Vasil Khalidov, Marc Szafraniec, Seungeun Yi, Michaël Ramamonjisoa, Francisco Massa, Daniel Haziza, Luca Wehrstedt, Jianyuan Wang, Timothée Darcet, Théo Moutakanni, Leonel Sentana, Claire Roberts, Andrea Vedaldi, Jamie Tolan, John Brandt, Camille Couprie, Julie...
work page 2025
-
[28]
Masked autoencoders as spatiotemporal learners.arXiv:2205.09113, 2022
Christoph Feichtenhofer, Haoqi Fan, Yanghao Li, and Kaiming He. Masked autoencoders as spatiotemporal learners.arXiv:2205.09113, 2022
-
[29]
Unmasked teacher: Towards training-efficient video foundation models
Kunchang Li, Yali Wang, Yizhuo Li, Yi Wang, Yinan He, Limin Wang, and Yu Qiao. Unmasked teacher: Towards training-efficient video foundation models. InProceedings of the IEEE/CVF international conference on computer vision, pages 19948–19960, 2023
work page 2023
-
[30]
Video- mamba: State space model for efficient video understanding
Kunchang Li, Xinhao Li, Yi Wang, Yinan He, Yali Wang, Limin Wang, and Yu Qiao. Video- mamba: State space model for efficient video understanding. InEuropean conference on computer vision, pages 237–255. Springer, 2024. 11
work page 2024
-
[31]
Snakes and ladders: Two steps up for videomamba
Hui Lu, Albert A Salah, and Ronald Poppe. Snakes and ladders: Two steps up for videomamba. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 24234– 24244, 2025
work page 2025
-
[32]
Efficient video transformers with spatial-temporal token selection
Junke Wang, Xitong Yang, Hengduo Li, Li Liu, Zuxuan Wu, and Yu-Gang Jiang. Efficient video transformers with spatial-temporal token selection. InEuropean Conference on Computer Vision, pages 69–86. Springer, 2022
work page 2022
-
[33]
FlashAttention-2: Faster attention with better parallelism and work partitioning
Tri Dao. FlashAttention-2: Faster attention with better parallelism and work partitioning. In International Conference on Learning Representations (ICLR), 2024
work page 2024
-
[34]
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, et al. Pytorch: An imperative style, high-performance deep learning library.Advances in neural information processing systems, 32, 2019
work page 2019
-
[35]
Charles Ruizhongtai Qi, Li Yi, Hao Su, and Leonidas J Guibas. Pointnet++: Deep hierarchical feature learning on point sets in a metric space.Advances in neural information processing systems, 30
-
[36]
Agglomerative token clustering
Joakim Bruslund Haurum, Sergio Escalera, Graham W Taylor, and Thomas B Moeslund. Agglomerative token clustering. InEuropean Conference on Computer Vision, pages 200–218. Springer, 2024
work page 2024
-
[37]
Learning to merge tokens via decoupled embedding for efficient vision transformers
Dong Hoon Lee and Seunghoon Hong. Learning to merge tokens via decoupled embedding for efficient vision transformers. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024
work page 2024
-
[38]
Hoai-Chau Tran, Duy M Nguyen, TrungTin Nguyen, Ngan Le, Pengtao Xie, Daniel Sonntag, James Zou, Binh T Nguyen, and Mathias Niepert. Accelerating transformers with spectrum- preserving token merging.Advances in Neural Information Processing Systems, 37:30772– 30810, 2024
work page 2024
-
[39]
Prune spatio-temporal tokens by semantic-aware temporal accumulation
Shuangrui Ding, Peisen Zhao, Xiaopeng Zhang, Rui Qian, Hongkai Xiong, and Qi Tian. Prune spatio-temporal tokens by semantic-aware temporal accumulation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 16945–16956, 2023
work page 2023
-
[40]
Everest: Efficient masked video autoencoder by removing redundant spatiotemporal tokens
Sunil Hwang, Jaehong Yoon, Youngwan Lee, and Sung Ju Hwang. Everest: Efficient masked video autoencoder by removing redundant spatiotemporal tokens. InInternational Conference on Machine Learning, 2024
work page 2024
-
[41]
Baifeng Shi, Stephanie Fu, Long Lian, Hanrong Ye, David Eigen, Aaron Reite, Boyi Li, Jan Kautz, Song Han, David M Chan, et al. Attend before attention: Efficient and scalable video understanding via autoregressive gazing.arXiv preprint arXiv:2603.12254, 2026
-
[42]
Is space-time attention all you need for video understanding
Gedas Bertasius, Heng Wang, and Lorenzo Torresani. Is space-time attention all you need for video understanding?arXiv preprint arXiv:2102.05095, 2021
-
[43]
Space-time mixing attention for video transformer
Adrian Bulat, Juan-Manuel Perez-Rua, Swathikiran Sudhakaran, Brais Martinez, and Georgios Tzimiropoulos. Space-time mixing attention for video transformer. InAdvances in Neural Information Processing Systems
-
[44]
Video-focalnets: Spatio-temporal focal modulation for video action recognition
Syed Talal Wasim, Muhammad Uzair Khattak, Muzammal Naseer, Salman Khan, Mubarak Shah, and Fahad Shahbaz Khan. Video-focalnets: Spatio-temporal focal modulation for video action recognition. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 13778–13789, 2023
work page 2023
-
[45]
X3d: Expanding architectures for efficient video recognition
Christoph Feichtenhofer. X3d: Expanding architectures for efficient video recognition. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 203–213, 2020
work page 2020
-
[46]
Slowfast networks for video recognition
Christoph Feichtenhofer, Haoqi Fan, Jitendra Malik, and Kaiming He. Slowfast networks for video recognition. InProceedings of the IEEE/CVF international conference on computer vision, pages 6202–6211, 2019. 12
work page 2019
-
[47]
Memvit: Memory-augmented multiscale vision transformer for efficient long-term video recognition
Chao-Yuan Wu, Yanghao Li, Karttikeya Mangalam, Haoqi Fan, Bo Xiong, Jitendra Malik, and Christoph Feichtenhofer. Memvit: Memory-augmented multiscale vision transformer for efficient long-term video recognition. InProceedings of the ieee/cvf conference on computer vision and pattern recognition, pages 13587–13597, 2022
work page 2022
-
[48]
Nvila: Efficient frontier visual language models
Zhijian Liu, Ligeng Zhu, Baifeng Shi, Zhuoyang Zhang, Yuming Lou, Shang Yang, Haocheng Xi, Shiyi Cao, Yuxian Gu, Dacheng Li, et al. Nvila: Efficient frontier visual language models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4122–4134, 2025
work page 2025
-
[49]
Pumer: Pruning and merging tokens for efficient vision language models
Qingqing Cao, Bhargavi Paranjape, and Hannaneh Hajishirzi. Pumer: Pruning and merging tokens for efficient vision language models. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 12890–12903, 2023
work page 2023
-
[50]
Storm: Token-efficient long video understanding for multimodal llms
Jindong Jiang, Xiuyu Li, Zhijian Liu, Muyang Li, Guo Chen, Zhiqi Li, De-An Huang, Guilin Liu, Zhiding Yu, Kurt Keutzer, et al. Storm: Token-efficient long video understanding for multimodal llms. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 5830–5841, 2025
work page 2025
-
[51]
Xiaoqian Shen, Yunyang Xiong, Changsheng Zhao, Lemeng Wu, Jun Chen, Chenchen Zhu, Zechun Liu, Fanyi Xiao, Balakrishnan Varadarajan, Florian Bordes, et al. Longvu: Spa- tiotemporal adaptive compression for long video-language understanding.arXiv preprint arXiv:2410.17434, 2024
-
[52]
Peng Jin, Ryuichi Takanobu, Wancai Zhang, Xiaochun Cao, and Li Yuan. Chat-univi: Unified visual representation empowers large language models with image and video understanding. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13700–13710, 2024
work page 2024
-
[53]
Testa: Temporal-spatial token aggregation for long-form video-language understanding
Shuhuai Ren, Sishuo Chen, Shicheng Li, Xu Sun, and Lu Hou. Testa: Temporal-spatial token aggregation for long-form video-language understanding. InFindings of the Association for Computational Linguistics: EMNLP 2023, pages 932–947, 2023
work page 2023
-
[54]
Mingze Xu, Mingfei Gao, Shiyu Li, Jiasen Lu, Zhe Gan, Zhengfeng Lai, Meng Cao, Kai Kang, Yinfei Yang, and Afshin Dehghan. Slowfast-llava-1.5: A family of token-efficient video large language models for long-form video understanding.arXiv preprint arXiv:2503.18943, 2025
-
[55]
Shaolei Zhang, Qingkai Fang, Zhe Yang, and Yang Feng. Llava-mini: Efficient image and video large multimodal models with one vision token.arXiv preprint arXiv:2501.03895, 2025
-
[56]
Dycoke: Dynamic compression of tokens for fast video large language models
Keda Tao, Can Qin, Haoxuan You, Yang Sui, and Huan Wang. Dycoke: Dynamic compression of tokens for fast video large language models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 18992–19001, 2025
work page 2025
-
[57]
Efficient universal perception encoder.arXiv preprint arXiv:2603.22387, 2026
Chenchen Zhu, Saksham Suri, Cijo Jose, Maxime Oquab, Marc Szafraniec, Wei Wen, Yunyang Xiong, Patrick Labatut, Piotr Bojanowski, Raghuraman Krishnamoorthi, et al. Efficient universal perception encoder.arXiv preprint arXiv:2603.22387, 2026
-
[58]
T-REN: Learning Text-Aligned Region Tokens Improves Dense Vision-Language Alignment and Scalability
Savya Khosla, Sethuraman TV , Aryan Chadha, Alex Schwing, and Derek Hoiem. T-ren: Learning text-aligned region tokens improves dense vision-language alignment and scalability. arXiv preprint arXiv:2604.18573, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[59]
TIPSv2: Advancing Vision-Language Pretraining with Enhanced Patch-Text Alignment
Bingyi Cao, Koert Chen, Kevis-Kokitsi Maninis, Kaifeng Chen, Arjun Karpur, Ye Xia, Sahil Dua, Tanmaya Dabral, Guangxing Han, Bohyung Han, et al. Tipsv2: Advancing vision-language pretraining with enhanced patch-text alignment.arXiv preprint arXiv:2604.12012, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[60]
arXiv preprint arXiv:2603.14482 (2026)
Lorenzo Mur-Labadia, Matthew Muckley, Amir Bar, Mido Assran, Koustuv Sinha, Mike Rabbat, Yann LeCun, Nicolas Ballas, and Adrien Bardes. V-jepa 2.1: Unlocking dense features in video self-supervised learning.arXiv preprint arXiv:2603.14482, 2026
-
[61]
mixup: Beyond Empirical Risk Minimization
Hongyi Zhang, Moustapha Cisse, Yann N Dauphin, and David Lopez-Paz. mixup: Beyond empirical risk minimization.arXiv preprint arXiv:1710.09412, 2017. 13
work page internal anchor Pith review arXiv 2017
-
[62]
Xiaolong Wang, Ross Girshick, Abhinav Gupta, and Kaiming He. Non-local neural networks. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 7794–7803, 2018
work page 2018
-
[63]
A large-scale study on unsupervised spatiotemporal representation learning
Christoph Feichtenhofer, Haoqi Fan, Bo Xiong, Ross Girshick, and Kaiming He. A large-scale study on unsupervised spatiotemporal representation learning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 3299–3309, 2021
work page 2021
-
[64]
Limin Wang, Yuanjun Xiong, Zhe Wang, Yu Qiao, Dahua Lin, Xiaoou Tang, and Luc Van Gool. Temporal segment networks for action recognition in videos.IEEE transactions on pattern analysis and machine intelligence, 41(11):2740–2755, 2018. 14 A Technical Appendices and Supplementary Material A.1 Efficiency in Practice: Throughput and Memory Measurements 0 500 ...
work page 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.