Recognition: no theorem link
LLM-Based Automated Diagnosis Of Integration Test Failures At Google
Pith reviewed 2026-05-10 15:29 UTC · model grok-4.3
The pith
An LLM-based tool identifies root causes of integration test failures with 90 percent accuracy at Google.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
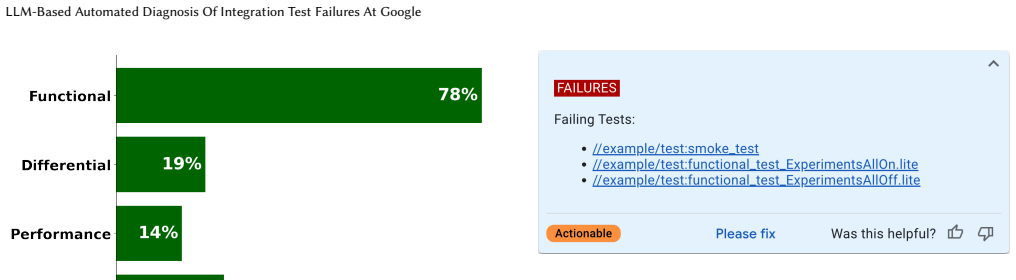
Auto-Diagnose processes failure logs with an LLM to extract the most relevant lines, generate a short summary, and state the likely root cause. On a manual review of 71 real-world integration test failures the diagnoses matched human judgment 90.14 percent of the time. After full deployment the system ran on 52,635 distinct failing tests; users marked it not helpful in only 5.8 percent of cases and ranked it fourteenth in helpfulness among 370 tools that post findings in Critique.
What carries the argument
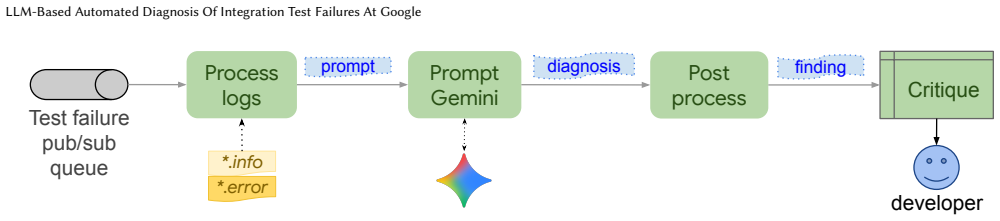
Auto-Diagnose, an LLM pipeline that turns raw integration-test logs into concise summaries and root-cause statements inside the Critique code-review interface.
If this is right
- Developers receive immediate, low-effort assistance while reviewing changes that trigger integration failures.
- The fraction of time spent interpreting logs drops for the subset of failures the tool handles correctly.
- Accuracy becomes the main driver of whether developers continue to use or ignore the assistance.
- LLMs prove capable of extracting signal from the high-volume, low-signal text that integration testing produces.
Where Pith is reading between the lines
- The same log-summarization pattern could be applied to other classes of failures whose logs are currently too large for quick human inspection.
- Over repeated use the tool may gradually change what information developers expect to see first when a test fails.
- Organizations with similar scale and testing volume could adopt comparable embeddings without rebuilding their review systems from scratch.
Load-bearing premise
The 71 manually checked failures are typical of all integration test failures and human judges can reliably determine the true root cause from the same logs the model receives.
What would settle it
A follow-up study that presents the same set of new failures to both the LLM tool and to independent developers who have full access to source code and environment details, then measures agreement between the two diagnoses.
Figures






read the original abstract
Integration testing is critical for the quality and reliability of complex software systems. However, diagnosing their failures presents significant challenges due to the massive volume, unstructured nature, and heterogeneity of logs they generate. These result in a high cognitive load, low signal-to-noise ratio, and make diagnosis difficult and time-consuming. Developers complain about these difficulties consistently and report spending substantially more time diagnosing integration test failures compared to unit test failures. To address these shortcomings, we introduce Auto-Diagnose, a novel diagnosis tool that leverages LLMs to help developers efficiently determine the root cause of integration test failures. Auto-Diagnose analyzes failure logs, produces concise summaries with the most relevant log lines, and is integrated into Critique, Google's internal code review system, providing contextual and in-time assistance. Based on our case studies, Auto-Diagnose is highly effective. A manual evaluation conducted on 71 real-world failures demonstrated 90.14% accuracy in diagnosing the root cause. Following its Google-wide deployment, Auto-Diagnose was used across 52, 635 distinct failing tests. User feedback indicated that the tool was deemed "Not helpful" in only 5.8% of cases, and it was ranked #14 in helpfulness among 370 tools that post findings in Critique. Finally, user interviews confirmed the perceived usefulness of Auto-Diagnose and positive reception of integrating automatic diagnostic assistance into existing workflows. We conclude that LLMs are highly successful in diagnosing integration test failures due to their capacity to process and summarize complex textual data. Integrating such AI-powered tooling automatically into developers' daily workflows is perceived positively, with the tool's accuracy remaining a critical factor in shaping developer perception and adoption.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Auto-Diagnose, an LLM-based tool integrated into Google's internal Critique code review system that analyzes integration test failure logs, extracts relevant lines, and generates concise root-cause summaries. It reports a manual evaluation showing 90.14% accuracy on 71 real-world failures, Google-wide deployment across 52,635 distinct failing tests, user feedback with only 5.8% 'Not helpful' ratings, a #14 helpfulness ranking among 370 tools, and positive interview feedback on workflow integration.
Significance. If the accuracy claim holds under rigorous validation, the work supplies concrete industrial evidence that LLMs can reduce cognitive load in diagnosing heterogeneous, high-volume integration test logs. Strengths include the scale of deployment data, direct integration into an existing developer tool, and collection of both quantitative usage metrics and qualitative user perceptions, which together offer a rare end-to-end view of AI tooling adoption inside a large organization.
major comments (2)
- [Abstract] Abstract: The headline 90.14% accuracy rests on a manual evaluation of 71 failures, yet the manuscript supplies no sampling protocol for selecting those cases, no description of how ground truth was established, no inter-rater reliability statistic, and no blinding procedure. Because the same logs are available to both the LLM and the human judges, the metric risks circularity or inflation if judges routinely consult unlogged context (prior commits, test history, or code inspection). This detail is load-bearing for the central effectiveness claim.
- [Abstract] Abstract and evaluation sections: No baseline comparison (e.g., keyword search, simple log heuristics, or non-LLM ML classifiers) is reported against which the LLM's incremental benefit can be measured. Without such controls, it is impossible to determine whether the observed accuracy and helpfulness ratings exceed what simpler methods already achieve on the same failure population.
minor comments (1)
- [Abstract] Abstract: The deployment figure is written as '52, 635' with an extraneous space; standardize to '52,635'.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and will revise the paper to improve clarity and transparency on the evaluation methodology.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline 90.14% accuracy rests on a manual evaluation of 71 failures, yet the manuscript supplies no sampling protocol for selecting those cases, no description of how ground truth was established, no inter-rater reliability statistic, and no blinding procedure. Because the same logs are available to both the LLM and the human judges, the metric risks circularity or inflation if judges routinely consult unlogged context (prior commits, test history, or code inspection). This detail is load-bearing for the central effectiveness claim.
Authors: We agree that the current description of the manual evaluation lacks sufficient methodological detail. In the revised manuscript we will add a dedicated subsection under Evaluation that specifies: the sampling protocol (random selection of 71 failures from those occurring during the study period), ground-truth establishment (independent root-cause identification by two authors with extensive experience in the relevant codebases, followed by discussion to resolve disagreements), inter-rater reliability (we will compute and report Cohen’s kappa), and blinding steps (judges first assessed the logs without seeing the LLM output). We will also explicitly state that judges were instructed to rely solely on the provided failure logs and not to consult unlogged context such as commit history. These additions will directly address concerns about circularity and strengthen the validity of the reported accuracy. revision: yes
-
Referee: [Abstract] Abstract and evaluation sections: No baseline comparison (e.g., keyword search, simple log heuristics, or non-LLM ML classifiers) is reported against which the LLM's incremental benefit can be measured. Without such controls, it is impossible to determine whether the observed accuracy and helpfulness ratings exceed what simpler methods already achieve on the same failure population.
Authors: We acknowledge that a baseline comparison would help quantify the LLM’s added value. The manuscript’s primary contribution, however, lies in the large-scale industrial deployment and user-adoption metrics rather than a controlled ablation study. Performing a full non-LLM baseline experiment on the identical 71 cases would require substantial additional effort. In the revision we will insert a discussion paragraph explaining why keyword-based or simple heuristic approaches are inadequate for the heterogeneous, high-volume integration-test logs we target, and we will list a comparative baseline evaluation as future work. This provides context for the results without overstating incremental benefit. revision: partial
Circularity Check
No circularity: purely empirical reporting of tool performance
full rationale
The paper presents an empirical description of Auto-Diagnose, an LLM-based tool, along with direct measurements of its accuracy (90.14% on 71 manually evaluated cases) and deployment outcomes (usage on 52,635 tests, 5.8% 'not helpful' rate). No equations, derivations, fitted parameters, or predictions are introduced that could reduce to the inputs by construction. Human judgment serves as the external ground truth for the accuracy metric, and deployment statistics are observational rather than model-derived. This satisfies the default expectation of no significant circularity for an applied systems paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Rui Abreu, Peter Zoeteweij, Rob Golsteijn, and Arjan JC Van Gemund. 2009. A practical evaluation of spectrum-based fault localization.Journal of Systems and Software82, 11 (2009), 1780–1792
2009
-
[2]
Earl T Barr, Yuriy Brun, Premkumar Devanbu, Mark Harman, and Federica Sarro
-
[3]
InProceedings of the 22nd ACM SIGSOFT International Symposium on Foundations of Software Engineering
The plastic surgery hypothesis. InProceedings of the 22nd ACM SIGSOFT International Symposium on Foundations of Software Engineering. 306–317
- [4]
-
[5]
Dong Chen, Shaoxin Lin, Muhan Zeng, Daoguang Zan, Jian-Gang Wang, Anton Cheshkov, Jun Sun, Hao Yu, Guoliang Dong, Artem Aliev, et al. 2024. Coder: Issue resolving with multi-agent and task graphs.arXiv preprint arXiv:2406.01304 (2024). LLM-Based Automated Diagnosis Of Integration Test Failures At Google
-
[6]
Lan Cheng, Emerson Murphy-Hill, Mark Canning, Ciera Jaspan, Collin Green, Andrea Knight, Nan Zhang, and Elizabeth Kammer. 2022. What improves devel- oper productivity at google? code quality. InProceedings of the 30th ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering. 1302–1313
2022
-
[7]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. 2025. Gemini 2.5: Pushing the frontier with advanced reasoning, multi- modality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [8]
-
[9]
Google Inc. 2025. Google Colab. https://colab.research.google.com. Accessed: 2025-09-24
2025
-
[10]
Google Inc. 2025. Google Gemini: Google’s AI Assistant. https://gemini.google. com. Accessed: 2025-09-24
2025
-
[11]
Muhammad Usman Hadi, Rizwan Qureshi, Abbas Shah, Muhammad Irfan, Anas Zafar, Muhammad Bilal Shaikh, Naveed Akhtar, Jia Wu, Seyedali Mirjalili, et al
-
[12]
Large language models: a comprehensive survey of its applications, chal- lenges, limitations, and future prospects.Authorea preprints1, 3 (2023), 1–26
2023
-
[13]
Shilin He, Pinjia He, Zhuangbin Chen, Tianyi Yang, Yuxin Su, and Michael R Lyu. 2021. A survey on automated log analysis for reliability engineering.ACM computing surveys (CSUR)54, 6 (2021), 1–37
2021
-
[14]
Shilin He, Jieming Zhu, Pinjia He, Zibin Li, and Rui Liu. 2017. Log-based anom- aly detection: A survey. In2017 IEEE 24th International Conference on Software Analysis, Evolution and Reconfiguration (SANER). IEEE, 520–529
2017
-
[15]
Xinyi Hou, Yanjie Zhao, Yue Liu, Zhou Yang, Kailong Wang, Li Li, Xiapu Luo, David Lo, John Grundy, and Haoyu Wang. 2024. Large language models for software engineering: A systematic literature review.ACM Transactions on Software Engineering and Methodology33, 8 (2024), 1–79
2024
-
[16]
2010.Continuous Delivery: Reliable Software Releases Through Build, Test, and Deployment Automation
Jez Humble and David Farley. 2010.Continuous Delivery: Reliable Software Releases Through Build, Test, and Deployment Automation. Addison-Wesley Professional
2010
-
[17]
Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. 2023. Swe-bench: Can language models resolve real-world github issues?arXiv preprint arXiv:2310.06770(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[18]
James A Jones, Mary Jean Harrold, and John Stasko. 2002. Visualization of test information to assist fault localization. InProceedings of the 24th international conference on Software engineering. 467–477
2002
-
[19]
René Just, Darioush Jalali, and Michael D. Ernst. 2014. Defects4J: a database of existing faults to enable controlled testing studies for Java programs. In Proceedings of the 2014 International Symposium on Software Testing and Analysis (ISSTA). ACM, 437–440. doi:10.1145/2610384.2628055 Accessed: 2025-09-22
-
[20]
Sungmin Kang, Gabin An, and Shin Yoo. 2024. A quantitative and qualitative evaluation of LLM-based explainable fault localization.Proceedings of the ACM on Software Engineering1, FSE (2024), 1424–1446
2024
-
[21]
Baris Kasikci, Cristiano Pereira, Gilles Pokam, Benjamin Schubert, Malandal Musuvathi, and George Candea. 2015. Failure sketches: A better way to debug. In15th Workshop on Hot Topics in Operating Systems (HotOS XV)
2015
-
[22]
1994.LaTeX: A Document Preparation System(2nd ed.)
Leslie Lamport. 1994.LaTeX: A Document Preparation System(2nd ed.). Addison- Wesley
1994
- [23]
- [24]
-
[25]
Yi Li, Shaohua Wang, and Tien Nguyen. 2021. Fault localization with code coverage representation learning. In2021 IEEE/ACM 43rd International Conference on Software Engineering (ICSE). IEEE, 661–673
2021
-
[26]
Ben Liblit, Mayur Naik, Alice X Zheng, Alex Aiken, and Michael I Jordan. 2005. Scalable statistical bug isolation.Acm Sigplan Notices40, 6 (2005), 15–26
2005
-
[27]
Chao Liu, Long Fei, Xifeng Yan, Jiawei Han, and Samuel P Midkiff. 2006. Statistical debugging: A hypothesis testing-based approach.IEEE Transactions on software engineering32, 10 (2006), 831–848
2006
- [28]
-
[29]
Yiling Lou, Qihao Zhu, Jinhao Dong, Xia Li, Zeyu Sun, Dan Hao, Lu Zhang, and Lingming Zhang. 2021. Boosting coverage-based fault localization via graph- based representation learning. InProceedings of the 29th ACM joint meeting on european software engineering conference and symposium on the foundations of software engineering. 664–676
2021
-
[30]
Chandra Maddila, Adam Tait, Claire Chang, Daniel Cheng, Nauman Ahmad, Vijayaraghavan Murali, Marshall Roch, Arnaud Avondet, Aaron Meltzer, Victor Montalvao, et al. 2025. Agentic Program Repair from Test Failures at Scale: A Neuro-symbolic approach with static analysis and test execution feedback.arXiv preprint arXiv:2507.18755(2025)
-
[31]
Yacine Majdoub and Eya Ben Charrada. 2024. Debugging with open-source large language models: An evaluation. InProceedings of the 18th ACM/IEEE International Symposium on Empirical Software Engineering and Measurement. 510–516
2024
-
[32]
Atif Memon, Zebao Gao, Bao Nguyen, Sanjeev Dhanda, Eric Nickell, Rob Siem- borski, and John Micco. 2017. Taming Google-Scale Continuous Testing. In Proceedings of the 39th International Conference on Software Engineering: Software Engineering in Practice Track. IEEE Press, 233–242
2017
-
[33]
Samuel Miserendino, Michele Wang, Tejal Patwardhan, and Johannes Heidecke
- [34]
-
[35]
Niklas Muennighoff, Qian Liu, Armel Zebaze, Qinkai Zheng, Binyuan Hui, Terry Yue Zhuo, Swayam Singh, Xiangru Tang, Leandro Von Werra, and Shayne Longpre. 2023. Octopack: Instruction tuning code large language models. In NeurIPS 2023 workshop on instruction tuning and instruction following
2023
-
[36]
Md Nakhla Rafi, Dong Jae Kim, Tse-Hsun Chen, and Shaowei Wang. 2024. En- hancing Fault Localization Through Ordered Code Analysis with LLM Agents and Self-Reflection.arXiv e-prints(2024), arXiv–2409
2024
-
[37]
OpenAI. 2022. ChatGPT-3.5. Large language model. https://chat.openai.com/ Accessed: 2025-09-22
2022
-
[38]
OpenAI. 2023. ChatGPT-4. Large language model. https://chat.openai.com/ Accessed: 2025-09-22
2023
-
[39]
2023.GPT-4 Technical Report
OpenAI. 2023.GPT-4 Technical Report. Technical Report. OpenAI. https: //cdn.openai.com/papers/gpt-4.pdf Accessed: 2025-09-22
2023
-
[40]
Rachel Potvin and Josh Levenberg. 2016. Why Google stores billions of lines of code in a single repository.Commun. ACM59, 7 (2016), 78–87
2016
-
[41]
Pressman and Bruce R
Roger S. Pressman and Bruce R. Maxim. 2014.Software Engineering: A Practi- tioner’s Approach. McGraw-Hill Education
2014
- [42]
-
[43]
Jie Qian, Xiaolin Ju, and Xiang Chen. 2023. GNet4FL: effective fault localization via graph convolutional neural network.Automated Software Engineering30, 2 (2023), 16
2023
- [44]
-
[45]
Baptiste Rozière, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xiao- qing Ellen Tan, Yossi Adi, Jingyu Liu, Romain Sauvestre, Tal Remez, Jérémy Rapin, Artyom Kozhevnikov, Ivan Evtimov, Joanna Bitton, Manish Bhatt, Cristian Can- ton Ferrer, Aaron Grattafiori, Wenhan Xiong, Alexandre Défossez, Jade Copet, Faisal Azhar, Hugo Touvron, Louis Martin, ...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2308.12950 2023
-
[46]
Paul Rozin and Edward B Royzman. 2001. Negativity bias, negativity dominance, and contagion.Personality and social psychology review5, 4 (2001), 296–320
2001
- [47]
-
[49]
Caitlin Sadowski, Emma Söderberg, Luke Church, Michal Sipko, and Alberto Bacchelli. 2018. Modern code review: a case study at Google. InProceedings of the 40th International Conference on Software Engineering: Software Engineering in Practice. ACM, 181–190
2018
-
[50]
Caitlin Sadowski, Jeffrey Van Gogh, Ciera Jaspan, Emma Soderberg, and Collin Winter. 2015. Tricorder: Building a program analysis ecosystem. In2015 IEEE/ACM 37th IEEE International Conference on Software Engineering, Vol. 1. IEEE, 598–608
2015
-
[51]
Kensen Shi, Deniz Altınbüken, Saswat Anand, Mihai Christodorescu, Katja Grün- wedel, Alexa Koenings, Sai Naidu, Anurag Pathak, Marc Rasi, Fredde Ribeiro, et al. 2025. Natural language outlines for code: Literate programming in the llm era. InProceedings of the 33rd ACM International Conference on the Foundations of Software Engineering. 150–161
2025
-
[52]
Jeongju Sohn and Shin Yoo. 2017. Fluccs: Using code and change metrics to improve fault localization. InProceedings of the 26th ACM SIGSOFT International Symposium on Software Testing and Analysis. 273–283
2017
-
[53]
Manu Sridharan, Stephen J Fink, and Rastislav Bodik. 2007. Thin slicing. In Proceedings of the 28th ACM SIGPLAN conference on programming language design and implementation. 112–122
2007
-
[54]
Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, Katie Millican, et al. 2023. Gemini: a family of highly capable multimodal models.arXiv preprint arXiv:2312.11805(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [55]
-
[56]
Chunqiu Steven Xia, Yinlin Deng, Soren Dunn, and Lingming Zhang. 2024. Agentless: Demystifying llm-based software engineering agents.arXiv preprint arXiv:2407.01489(2024)
work page internal anchor Pith review arXiv 2024
-
[57]
Chunqiu Steven Xia, Yuxiang Wei, and Lingming Zhang. 2023. Automated program repair in the era of large pre-trained language models. In2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE). IEEE, 1482–1494
2023
-
[58]
Chunqiu Steven Xia and Lingming Zhang. 2022. Less training, more repairing please: revisiting automated program repair via zero-shot learning. InProceedings of the 30th ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering. 959–971
2022
-
[59]
Chunqiu Steven Xia and Lingming Zhang. 2024. Automated program repair via conversation: Fixing 162 out of 337 bugs for $0.42 each using chatgpt. In Proceedings of the 33rd ACM SIGSOFT International Symposium on Software Testing and Analysis. 819–831
2024
-
[60]
John Yang, Carlos E Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press. 2024. Swe-agent: Agent-computer interfaces enable automated software engineering.Advances in Neural Information Processing Systems37 (2024), 50528–50652
2024
-
[61]
John Yang, Kilian Lieret, Carlos E Jimenez, Alexander Wettig, Kabir Khand- pur, Yanzhe Zhang, Binyuan Hui, Ofir Press, Ludwig Schmidt, and Diyi Yang
-
[62]
Swe-smith: Scaling data for software engineering agents.arXiv preprint arXiv:2504.21798(2025)
work page internal anchor Pith review arXiv 2025
-
[63]
Weiqing Yang, Hanbin Wang, Zhenghao Liu, Xinze Li, Yukun Yan, Shuo Wang, Yu Gu, Minghe Yu, Zhiyuan Liu, and Ge Yu. 2024. Enhancing the code debugging ability of llms via communicative agent based data refinement.language30 (2024), 31
2024
-
[64]
Dixin Yuan, Sunghun Park, and Yuanyuan Zhou. 2012. Characterizing logging practices in open-source software. InProceedings of the 34th International Con- ference on Software Engineering (ICSE). IEEE Press, 1–11
2012
-
[65]
Andreas Zeller and Ralf Hildebrandt. 2002. Simplifying and isolating failure- inducing input.IEEE Transactions on software engineering28, 2 (2002), 183–200
2002
-
[66]
Yuntong Zhang, Haifeng Ruan, Zhiyu Fan, and Abhik Roychoudhury. 2024. Autocoderover: Autonomous program improvement. InProceedings of the 33rd ACM SIGSOFT International Symposium on Software Testing and Analysis. 1592– 1604
2024
-
[67]
Zhuo Zhang, Yan Lei, Xiaoguang Mao, and Panpan Li. 2019. CNN-FL: An effective approach for localizing faults using convolutional neural networks. In2019 IEEE 26th International Conference on Software Analysis, Evolution and Reengineering (SANER). IEEE, 445–455
2019
-
[68]
Yintong Zhao, Shilin He, Pinjia He, Zhekang Chen, Hongyu Zhang, and Renzhi Duan. 2023. Log-based Anomaly Detection and Diagnosis for Software Systems: A Survey.Comput. Surveys56, 4 (2023), 1–37
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.