Recognition: unknown
HTDC: Hesitation-Triggered Differential Calibration for Mitigating Hallucination in Large Vision-Language Models
Pith reviewed 2026-05-10 15:07 UTC · model grok-4.3
The pith
Large vision-language models reduce hallucinations by calibrating only when token preferences fluctuate across layers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
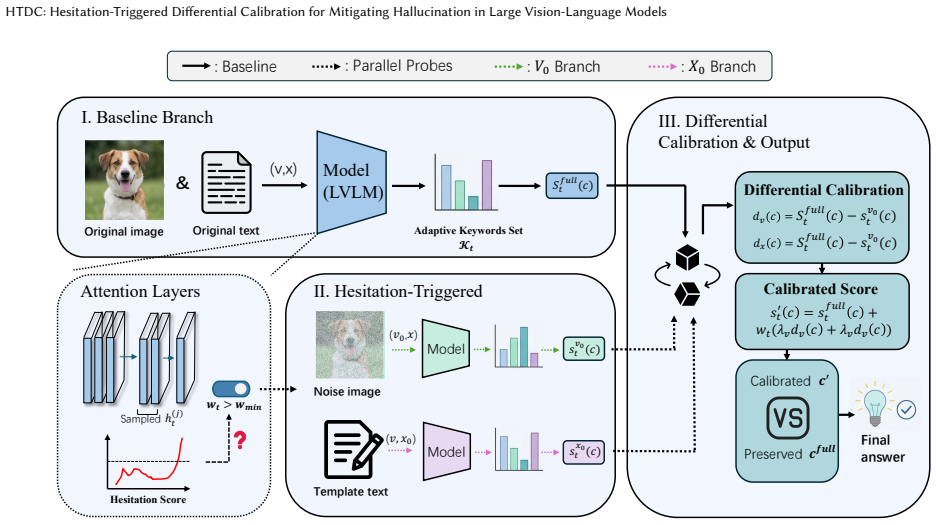
HTDC preserves standard full-branch inference and activates calibration only at hesitation-prone steps, where layer-wise token preference fluctuates; when triggered it contrasts the full branch against a visual-nullification probe and a semantic-nullification probe to suppress hallucination-prone candidates while leaving stable steps untouched.
What carries the argument
Layer-wise hesitation, the observable fluctuations in token preference across intermediate layers, which triggers differential calibration that contrasts the main branch with visual-nullification and semantic-nullification probes.
If this is right
- Hallucination rates drop on representative benchmarks while task accuracy stays high.
- Computational cost falls because calibration runs only on detected hesitant steps.
- Stable predictions are left intact because non-hesitant steps use unmodified full-branch inference.
- The method requires no retraining and can be added to existing large vision-language models.
Where Pith is reading between the lines
- The same hesitation signal could be tested as a trigger for other decoding interventions such as factuality checks or uncertainty-aware sampling.
- If hesitation proves a general marker of instability, the approach might extend to pure language models or other multimodal tasks beyond hallucination.
- Real-time applications could benefit from the reduced average compute, making selective calibration practical on edge devices.
- Combining the layer-fluctuation signal with other cheap uncertainty metrics might further tighten the effectiveness-overhead trade-off.
Load-bearing premise
Fluctuations in token preference across layers reliably mark grounding instability that produces hallucinations, and can be detected without missing hallucinated outputs or disturbing stable predictions.
What would settle it
An experiment that forces calibration at every step and shows further hallucination reduction, or a dataset where many hallucinations appear without preceding layer-wise hesitation, would falsify the selective-trigger claim.
Figures


read the original abstract
Large vision-language models (LVLMs) achieve strong multimodal performance, but still suffer from hallucinations caused by unstable visual grounding and over-reliance on language priors. Existing training-free decoding methods typically apply calibration at every decoding step, introducing unnecessary computation and potentially disrupting stable predictions. We address this problem by identifying layer-wise hesitation, a simple signal of grounding instability reflected by fluctuations in token preference across intermediate layers. Based on this observation, we propose Hesitation-Triggered Differential Calibration (HTDC), a training-free decoding framework that preserves standard full-branch inference and activates calibration only at hesitation-prone steps. When triggered, HTDC contrasts the full branch with two lightweight probes, a visual-nullification probe and a semantic-nullification probe, to suppress hallucination-prone candidates while avoiding unnecessary intervention on stable steps. Experiments on representative hallucination benchmarks show that HTDC consistently reduces hallucinations while maintaining strong task accuracy, achieving a favorable trade-off between effectiveness and computational overhead.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Hesitation-Triggered Differential Calibration (HTDC), a training-free decoding framework for large vision-language models. It identifies layer-wise hesitation—fluctuations in token preference across intermediate layers—as a signal of unstable visual grounding. HTDC applies standard full-branch inference by default and activates differential calibration (contrasting the full branch against visual-nullification and semantic-nullification probes) only at hesitation-prone steps to suppress hallucination-prone tokens while preserving stable predictions and reducing overhead relative to always-on calibration methods. Experiments on hallucination benchmarks are reported to show consistent hallucination reduction with maintained task accuracy.
Significance. If the central results hold, HTDC offers a practical advance in efficient, training-free hallucination mitigation for LVLMs by making calibration selective rather than uniform. The selective triggering mechanism directly addresses the computational and disruption drawbacks of prior decoding-time calibration approaches. Credit is due for the training-free design, the introduction of lightweight nullification probes, and the explicit focus on computational trade-offs. The approach could be impactful if the hesitation signal proves reliable, but its value is currently limited by insufficient validation of that signal.
major comments (2)
- [§3.2 and §4.1] §3.2 and §4.1: The central claim that layer-wise hesitation serves as a reliable, low-false-negative trigger for hallucination mitigation is load-bearing, yet the manuscript provides no per-step correlation analysis, precision/recall metrics, or ablation demonstrating that detected hesitation steps align with actual hallucinated outputs (or that non-hesitant steps are reliably hallucination-free). Without this, the selective mechanism's claimed favorable effectiveness-overhead trade-off cannot be verified and may under-mitigate or over-intervene.
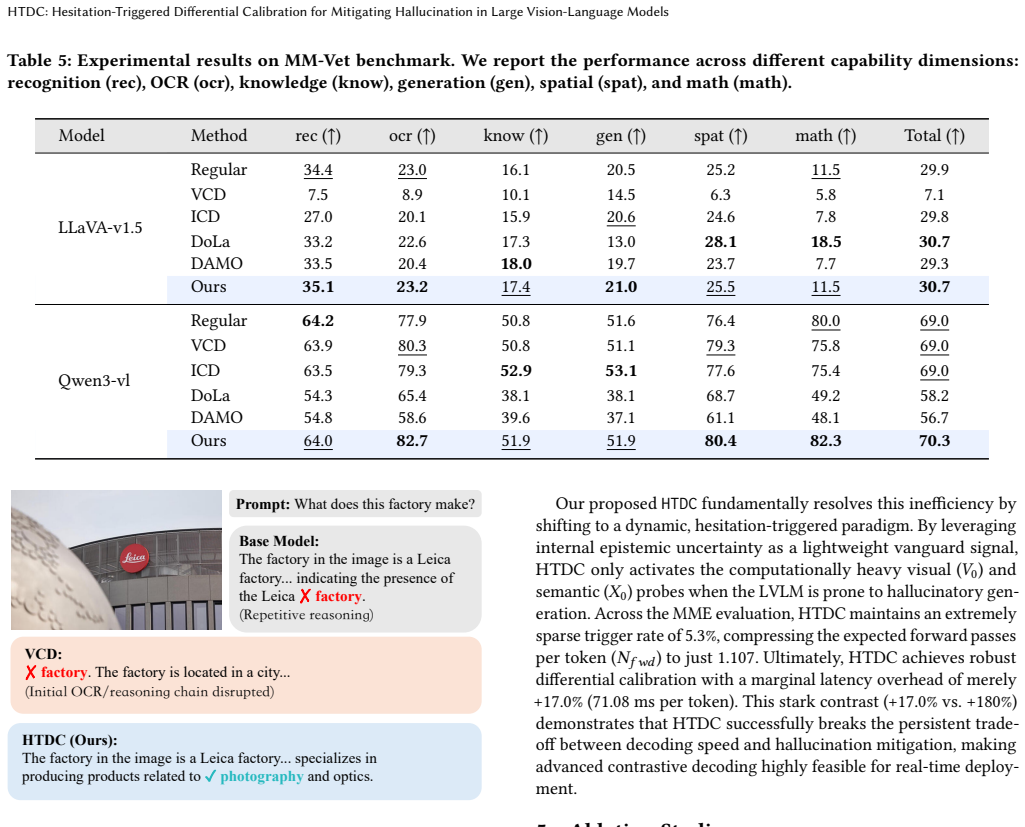
- [§5.2, Table 3] §5.2, Table 3: The reported benchmark improvements lack error bars, multiple random seeds, or statistical significance tests against baselines, making it impossible to assess whether the gains in hallucination metrics are robust or could be explained by variance in the selective triggering.
minor comments (3)
- [§3.1] §3.1: The exact implementation of the visual-nullification and semantic-nullification probes (e.g., whether via attention masking, input zeroing, or logit adjustment) is described at a high level; a precise algorithmic description or pseudocode would improve reproducibility.
- [Figure 2] Figure 2: The visualization of layer-wise token preference fluctuations would benefit from explicit annotation of the hesitation threshold used for triggering and a side-by-side comparison with ground-truth hallucination locations.
- [Related work section] Related work section: Prior contrastive decoding and calibration methods are cited, but the discussion could more explicitly contrast HTDC's selective activation against the always-on nature of the closest baselines to highlight the novelty.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on validating the hesitation signal and ensuring statistical robustness of the results. We address each major comment below and have revised the manuscript to incorporate the suggested analyses.
read point-by-point responses
-
Referee: [§3.2 and §4.1] §3.2 and §4.1: The central claim that layer-wise hesitation serves as a reliable, low-false-negative trigger for hallucination mitigation is load-bearing, yet the manuscript provides no per-step correlation analysis, precision/recall metrics, or ablation demonstrating that detected hesitation steps align with actual hallucinated outputs (or that non-hesitant steps are reliably hallucination-free). Without this, the selective mechanism's claimed favorable effectiveness-overhead trade-off cannot be verified and may under-mitigate or over-intervene.
Authors: We agree that a direct per-step validation of the hesitation signal against hallucination occurrences would strengthen the justification for selective triggering. The submitted manuscript supports the approach via end-to-end benchmark gains and component ablations, but does not include the requested correlation, precision/recall, or targeted ablation. In the revision, we have added a new analysis subsection under §4.1 that computes precision and recall of hesitation detection (using ground-truth hallucination labels on a held-out subset) and includes an ablation forcing calibration on non-hesitant steps to demonstrate that such intervention yields no additional benefit and can disrupt stable predictions. These results are now presented in an updated Figure and Table, confirming the signal's utility for the claimed trade-off. revision: yes
-
Referee: [§5.2, Table 3] §5.2, Table 3: The reported benchmark improvements lack error bars, multiple random seeds, or statistical significance tests against baselines, making it impossible to assess whether the gains in hallucination metrics are robust or could be explained by variance in the selective triggering.
Authors: We acknowledge that the absence of variability measures and significance testing limits assessment of result robustness. The original experiments used a single fixed seed. We have now re-executed the primary evaluations across three random seeds, updated Table 3 with means and standard deviations, and added paired statistical significance tests (t-tests) against baselines with reported p-values. The improvements remain consistent in direction and magnitude across seeds, supporting the reliability of the selective calibration gains. revision: yes
Circularity Check
No significant circularity detected in derivation chain
full rationale
The paper motivates HTDC from an empirical observation of layer-wise hesitation (fluctuations in token preference across layers) as a signal for grounding instability, then defines the framework to activate differential calibration (full branch vs. visual-nullification and semantic-nullification probes) only at those steps. No equations, definitions, or self-citations reduce the central claims or the hesitation trigger to tautologies, fitted parameters renamed as predictions, or self-referential loops. The derivation is self-contained with independent empirical motivation and does not rely on load-bearing self-citations or imported uniqueness theorems for its core logic.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Layer-wise fluctuations in token preference indicate grounding instability in LVLMs
invented entities (3)
-
Hesitation-Triggered Differential Calibration (HTDC)
no independent evidence
-
visual-nullification probe
no independent evidence
-
semantic-nullification probe
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al . 2025. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Zechen Bai, Pichao Wang, Tianjun Xiao, Tong He, Zongbo Han, Zheng Zhang, and Mike Zheng Shou. 2024. Hallucination of multimodal large language models: A survey.arXiv preprint arXiv:2404.18930(2024)
work page internal anchor Pith review arXiv 2024
- [3]
-
[4]
Alessandro Favero, Luca Zancato, Matthew Trager, Siddharth Choudhary, Pra- muditha Perera, Alessandro Achille, Ashwin Swaminathan, and Stefano Soatto
-
[5]
InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Multi-modal hallucination control by visual information grounding. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 14303–14312
-
[6]
Chaoyou Fu, Peixian Chen, Yunhang Shen, Yulei Qin, Mengdan Zhang, Xu Lin, Jinrui Yang, Xiawu Zheng, Ke Li, Xing Sun, et al. 2023. Mme: A comprehensive evaluation benchmark for multimodal large language models.arXiv preprint arXiv:2306.13394(2023)
work page internal anchor Pith review arXiv 2023
-
[7]
Paul Hager, Friederike Jungmann, Robbie Holland, Kunal Bhagat, Inga Hubrecht, Manuel Knauer, Jakob Vielhauer, Marcus Makowski, Rickmer Braren, Georgios Kaissis, et al. 2024. Evaluation and mitigation of the limitations of large language models in clinical decision-making.Nature medicine30, 9 (2024), 2613–2622
2024
-
[8]
Iryna Hartsock and Ghulam Rasool. 2024. Vision-language models for medical report generation and visual question answering: A review.Frontiers in artificial intelligence7 (2024), 1430984
2024
-
[9]
Lei Huang, Weijiang Yu, Weitao Ma, Weihong Zhong, Zhangyin Feng, Haotian Wang, Qianglong Chen, Weihua Peng, Xiaocheng Feng, Bing Qin, et al. 2025. A survey on hallucination in large language models: Principles, taxonomy, chal- lenges, and open questions.ACM Transactions on Information Systems43, 2 (2025), 1–55
2025
-
[10]
Zhangqi Jiang, Junkai Chen, Beier Zhu, Tingjin Luo, Yankun Shen, and Xu Yang
-
[11]
InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Devils in middle layers of large vision-language models: Interpreting, detecting and mitigating object hallucinations via attention lens. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 25004– 25014
- [12]
-
[13]
Junho Kim, Hyun J Kim, Yeon J Kim, and Yong M Ro. 2024. Code: Contrasting self-generated description to combat hallucination in large multi-modal models. Advances in Neural Information Processing Systems37 (2024), 133571–133599
2024
-
[14]
Wonkyun Kim, Changin Choi, Wonseok Lee, and Wonjong Rhee. 2024. An image grid can be worth a video: Zero-shot video question answering using a vlm.IEEE Access12 (2024), 193057–193075
2024
-
[15]
JDMCK Lee and K Toutanova. 2018. Pre-training of deep bidirectional trans- formers for language understanding.arXiv preprint arXiv:1810.048053, 8 (2018), 4171–4186
work page internal anchor Pith review Pith/arXiv arXiv 2018
- [16]
-
[17]
Sicong Leng, Hang Zhang, Guanzheng Chen, Xin Li, Shijian Lu, Chunyan Miao, and Lidong Bing. 2024. Mitigating object hallucinations in large vision-language models through visual contrastive decoding. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 13872–13882
2024
-
[18]
Xiaoqi Li, Mingxu Zhang, Yiran Geng, Haoran Geng, Yuxing Long, Yan Shen, Ren- rui Zhang, Jiaming Liu, and Hao Dong. 2024. Manipllm: Embodied multimodal large language model for object-centric robotic manipulation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 18061– 18070
2024
-
[19]
Yifan Li, Yifan Du, Kun Zhou, Jinpeng Wang, Wayne Xin Zhao, and Ji-Rong Wen. 2023. Evaluating object hallucination in large vision-language models. InProceedings of the 2023 conference on empirical methods in natural language processing. 292–305
2023
-
[20]
Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. 2024. Improved baselines with visual instruction tuning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 26296–26306
2024
-
[21]
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. 2023. Visual in- struction tuning.Advances in neural information processing systems36 (2023), 34892–34916
2023
-
[22]
Hanchao Liu, Wenyuan Xue, Yifei Chen, Dapeng Chen, Xiutian Zhao, Ke Wang, Liping Hou, Rongjun Li, and Wei Peng. 2024. A survey on hallucination in large vision-language models.arXiv preprint arXiv:2402.00253(2024)
work page internal anchor Pith review arXiv 2024
-
[23]
Sheng Liu, Haotian Ye, and James Zou. 2025. Reducing hallucinations in large vision-language models via latent space steering. InThe Thirteenth International Conference on Learning Representations
2025
-
[24]
Xinbei Ma, Zhuosheng Zhang, and Hai Zhao. 2024. Coco-agent: A comprehen- sive cognitive mllm agent for smartphone gui automation. InFindings of the Association for Computational Linguistics: ACL 2024. 9097–9110
2024
-
[25]
Avshalom Manevich and Reut Tsarfaty. 2024. Mitigating hallucinations in large vision-language models (lvlms) via language-contrastive decoding (lcd). InFind- ings of the Association for Computational Linguistics: ACL 2024. 6008–6022
2024
-
[26]
Joshua Maynez, Shashi Narayan, Bernd Bohnet, and Ryan McDonald. 2020. On faithfulness and factuality in abstractive summarization. InProceedings of the 58th annual meeting of the association for computational linguistics. 1906–1919
2020
- [27]
-
[28]
Yeji Park, Deokyeong Lee, Junsuk Choe, and Buru Chang. 2025. Convis: Con- trastive decoding with hallucination visualization for mitigating hallucinations in multimodal large language models. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 39. 6434–6442
2025
-
[29]
Anna Rohrbach, Lisa Anne Hendricks, Kaylee Burns, Trevor Darrell, and Kate Saenko. 2018. Object hallucination in image captioning. InProceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. 4035–4045
2018
-
[30]
Rico Sennrich, Jannis Vamvas, and Alireza Mohammadshahi. 2024. Mitigating hallucinations and off-target machine translation with source-contrastive and language-contrastive decoding. InProceedings of the 18th Conference of the Euro- pean Chapter of the Association for Computational Linguistics (Volume 2: Short Papers). 21–33
2024
-
[31]
Chonghao Sima, Katrin Renz, Kashyap Chitta, Li Chen, Hanxue Zhang, Chen- gen Xie, Jens Beißwenger, Ping Luo, Andreas Geiger, and Hongyang Li. 2024. Drivelm: Driving with graph visual question answering. InEuropean conference on computer vision. Springer, 256–274
2024
-
[32]
Wei Suo, Lijun Zhang, Mengyang Sun, Lin Yuanbo Wu, Peng Wang, and Yanning Zhang. 2025. Octopus: Alleviating hallucination via dynamic contrastive decod- ing. InProceedings of the Computer Vision and Pattern Recognition Conference. 29904–29914
2025
- [33]
- [34]
- [35]
-
[36]
Kaishen Wang, Hengrui Gu, Meijun Gao, and Kaixiong Zhou. 2025. Damo: Decoding by accumulating activations momentum for mitigating hallucinations in vision-language models. InThe Thirteenth International Conference on Learning Representations
2025
- [37]
-
[38]
Lei Wang, Jiabang He, Shenshen Li, Ning Liu, and Ee-Peng Lim. 2024. Mitigating fine-grained hallucination by fine-tuning large vision-language models with caption rewrites. InInternational Conference on Multimedia Modeling. Springer, 32–45
2024
-
[39]
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, et al. 2024. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[40]
Junfei Wu, Yue Ding, Guofan Liu, Tianze Xia, Ziyue Huang, Dianbo Sui, Qiang Liu, Shu Wu, Liang Wang, and Tieniu Tan. 2025. Sharp: Steering hallucination in lvlms via representation engineering. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 14357–14372
2025
- [41]
-
[42]
Xu Yang, Yongliang Wu, Mingzhuo Yang, Haokun Chen, and Xin Geng. 2023. Exploring diverse in-context configurations for image captioning.Advances in Neural Information Processing Systems36 (2023), 40924–40943
2023
-
[43]
Zhihe Yang, Xufang Luo, Dongqi Han, Yunjian Xu, and Dongsheng Li. 2025. Mitigating hallucinations in large vision-language models via dpo: On-policy data hold the key. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 10610–10620
2025
-
[44]
Shukang Yin, Chaoyou Fu, Sirui Zhao, Ke Li, Xing Sun, Tong Xu, and Enhong Chen. 2024. A survey on multimodal large language models.National Science Review11, 12 (2024), nwae403
2024
-
[45]
Shukang Yin, Chaoyou Fu, Sirui Zhao, Tong Xu, Hao Wang, Dianbo Sui, Yunhang Shen, Ke Li, Xing Sun, and Enhong Chen. 2024. Woodpecker: Hallucination correction for multimodal large language models.Science China Information Sciences67, 12 (2024), 220105. Xinyun Liu
2024
-
[46]
Le Yu, Kaishen Wang, Jianlong Xiong, Yue Cao, Lei Zhang, and Zhang Yi Tao He
- [47]
-
[48]
Tianyu Yu, Yuan Yao, Haoye Zhang, Taiwen He, Yifeng Han, Ganqu Cui, Jinyi Hu, Zhiyuan Liu, Hai-Tao Zheng, Maosong Sun, et al . 2024. Rlhf-v: Towards trustworthy mllms via behavior alignment from fine-grained correctional human feedback. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 13807–13816
2024
-
[49]
Weihao Yu, Zhengyuan Yang, Linjie Li, Jianfeng Wang, Kevin Lin, Zicheng Liu, Xinchao Wang, and Lijuan Wang. 2023. Mm-vet: Evaluating large multimodal models for integrated capabilities.arXiv preprint arXiv:2308.02490(2023)
work page internal anchor Pith review arXiv 2023
-
[50]
Hongxiang Zhang, Hao Chen, Muhao Chen, and Tianyi Zhang. 2025. Active layer- contrastive decoding reduces hallucination in large language model generation. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 3028–3046
2025
- [51]
- [52]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.