Recognition: unknown
Domain-Specific Latent Representations Improve the Fidelity of Diffusion-Based Medical Image Super-Resolution
Pith reviewed 2026-05-10 15:38 UTC · model grok-4.3
The pith
Replacing generic photo-trained autoencoders with one pretrained on 1.6 million medical images raises diffusion super-resolution PSNR by 2.9 to 3.3 dB on MRI and X-ray data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
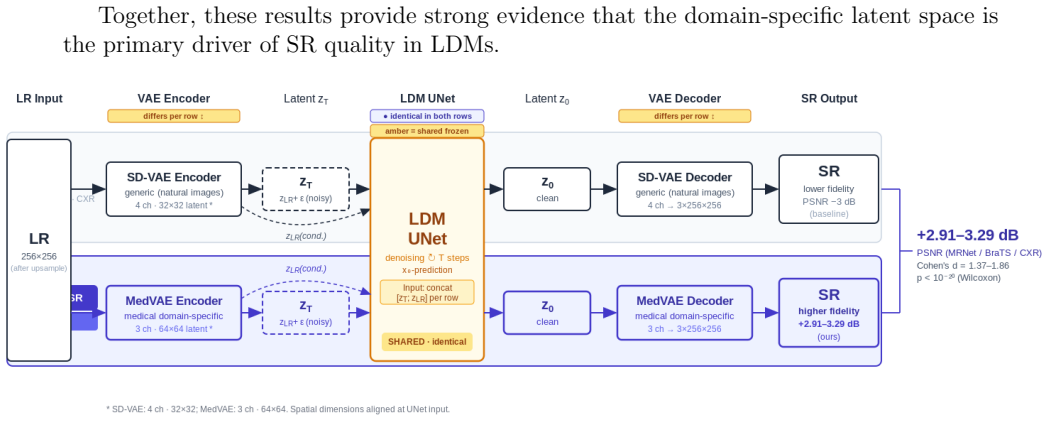
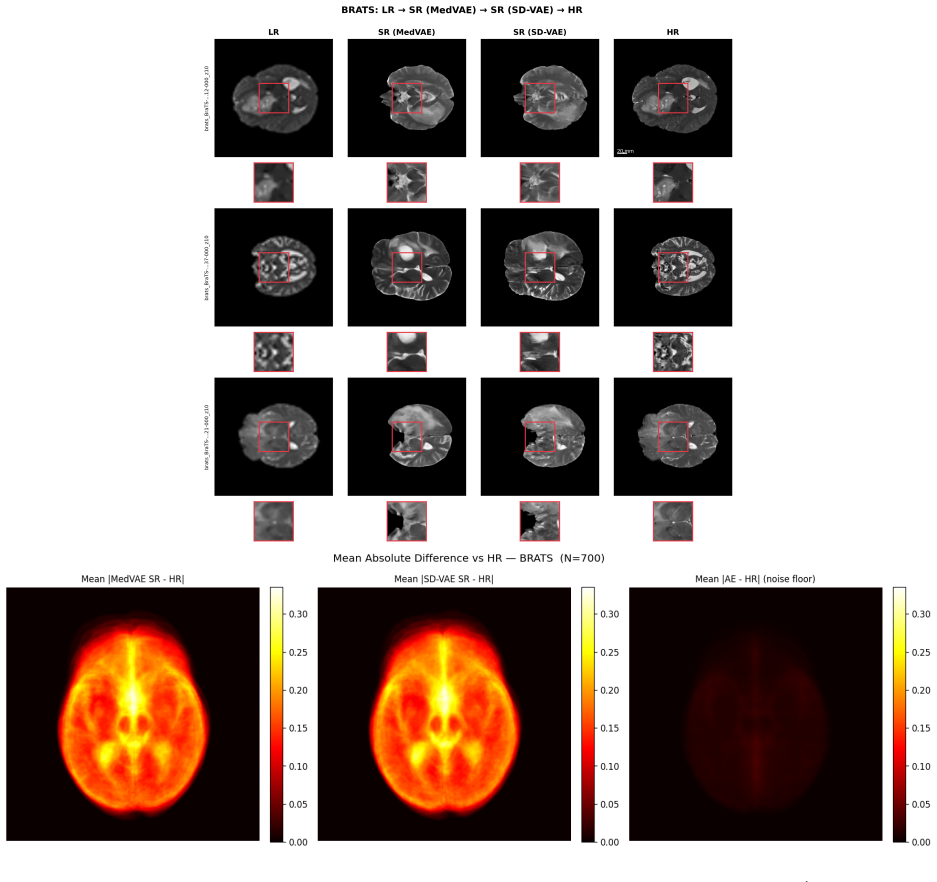
In controlled experiments that keep all other pipeline components identical, replacing the Stable Diffusion VAE with MedVAE pretrained on more than 1.6 million medical images produces +2.91 to +3.29 dB PSNR improvement across three clinical datasets totaling 1,820 images. The gain localizes to the highest-frequency wavelet bands, while hallucination rates remain statistically indistinguishable. The same performance gap stays within 0.15 dB across varied inference schedules, prediction targets, and generative backbones, and autoencoder reconstruction quality measured without diffusion training correlates with downstream super-resolution results at R² = 0.67.
What carries the argument
MedVAE, a variational autoencoder pretrained on more than 1.6 million medical images, which supplies domain-specific latent representations that replace the generic Stable Diffusion VAE inside the diffusion super-resolution pipeline.
If this is right
- Autoencoder reconstruction quality measured without diffusion training predicts final super-resolution performance with R² = 0.67.
- The PSNR advantage remains stable within plus or minus 0.15 dB across different inference schedules, prediction targets, and generative architectures.
- Reconstruction fidelity and generative hallucination are governed by independent pipeline components and can be optimized separately.
- Domain-specific VAE selection should precede diffusion architecture search in medical super-resolution pipelines.
Where Pith is reading between the lines
- The result suggests that large-scale domain pretraining of the latent encoder may deliver larger returns than further scaling of the diffusion model itself for specialized imaging tasks.
- Similar controlled swaps could be tested in CT, ultrasound, or histopathology to check whether the same encoder-first strategy applies beyond MRI and X-ray.
- It raises the possibility that existing general-purpose diffusion pipelines could be upgraded for medical use by fine-tuning or replacing only the VAE rather than retraining the entire model.
Load-bearing premise
The measured quality gap arises from the medical pretraining of the autoencoder rather than from any unmeasured differences in training procedure, data volume, or architecture details between the two encoders.
What would settle it
Train both the generic and the medical autoencoders from scratch with identical architectures, data volumes, and optimization procedures on their respective domains, then measure whether the PSNR gap in the downstream super-resolution task disappears.
Figures





read the original abstract
Latent diffusion models for medical image super-resolution universally inherit variational autoencoders designed for natural photographs. We show that this default choice, not the diffusion architecture, is the dominant constraint on reconstruction quality. In a controlled experiment holding all other pipeline components fixed, replacing the generic Stable Diffusion VAE with MedVAE, a domain-specific autoencoder pretrained on more than 1.6 million medical images, yields +2.91 to +3.29 dB PSNR improvement across knee MRI, brain MRI, and chest X-ray (n = 1,820; Cohen's d = 1.37 to 1.86, all p < 10^{-20}, Wilcoxon signed-rank). Wavelet decomposition localises the advantage to the finest spatial frequency bands encoding anatomically relevant fine structure. Ablations across inference schedules, prediction targets, and generative architectures confirm the gap is stable within plus or minus 0.15 dB, while hallucination rates remain comparable between methods (Cohen's h < 0.02 across all datasets), establishing that reconstruction fidelity and generative hallucination are governed by independent pipeline components. These results provide a practical screening criterion: autoencoder reconstruction quality, measurable without diffusion training, predicts downstream SR performance (R^2 = 0.67), suggesting that domain-specific VAE selection should precede diffusion architecture search. Code and trained model weights are publicly available at https://github.com/sebasmos/latent-sr.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that the choice of variational autoencoder is the dominant bottleneck in latent diffusion models for medical image super-resolution. In a controlled experiment, replacing the generic Stable Diffusion VAE with MedVAE (pretrained on >1.6M medical images) produces +2.91 to +3.29 dB PSNR gains across knee MRI, brain MRI, and chest X-ray (n=1820, Cohen's d=1.37–1.86, all p<10^{-20} by Wilcoxon signed-rank). Wavelet analysis localizes the benefit to fine-scale anatomical frequencies; ablations show the gap is stable across inference schedules and architectures; hallucination rates are statistically indistinguishable; and autoencoder reconstruction quality predicts downstream SR performance (R²=0.67). Code and weights are released.
Significance. If the performance gap is attributable to domain-specific pretraining rather than unmeasured architectural or training differences, the work supplies a low-cost screening criterion (VAE reconstruction quality) that precedes diffusion architecture search and separates fidelity from hallucination control. The large sample, strong non-parametric statistics, wavelet localization, and public artifacts are clear strengths that would make the result immediately actionable for medical imaging pipelines.
major comments (1)
- [Abstract and §3] Abstract and §3 (Methods/Experimental Setup): The manuscript asserts a 'controlled experiment holding all other pipeline components fixed' when swapping the VAE, yet provides no explicit confirmation (table, appendix, or text) that MedVAE and the Stable Diffusion VAE share identical encoder/decoder architecture, latent dimensionality, normalization layers, or training hyperparameters. Because the central claim attributes the 2.91–3.29 dB PSNR improvement specifically to domain-specific pretraining, the absence of an architecture-matched control or an ablation that retrains the exact SD-VAE architecture on the 1.6 M medical images leaves the causal attribution under-secured.
minor comments (2)
- [Figure 2 and §4.2] Figure 2 and §4.2: The wavelet energy plots would be clearer if the frequency-band labels were explicitly tied to the anatomical structures they encode (e.g., 'band 4–8: cortical detail').
- [§4.3] §4.3: The R²=0.67 correlation is reported transparently but lacks a cross-validation or bootstrap confidence interval that would quantify its stability across the three modalities.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive review. The major comment raises an important point about explicit documentation of experimental controls, which we address below by committing to additional details in the revision.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (Methods/Experimental Setup): The manuscript asserts a 'controlled experiment holding all other pipeline components fixed' when swapping the VAE, yet provides no explicit confirmation (table, appendix, or text) that MedVAE and the Stable Diffusion VAE share identical encoder/decoder architecture, latent dimensionality, normalization layers, or training hyperparameters. Because the central claim attributes the 2.91–3.29 dB PSNR improvement specifically to domain-specific pretraining, the absence of an architecture-matched control or an ablation that retrains the exact SD-VAE architecture on the 1.6 M medical images leaves the causal attribution under-secured.
Authors: We agree that the manuscript would be strengthened by explicit confirmation of architectural equivalence. In the revised version we will add a supplementary table (new Appendix B) that lists the shared specifications: both VAEs use the identical KL-regularized encoder/decoder architecture (4 downsampling blocks, latent dimension 4, same normalization and activation layers) originally introduced in Stable Diffusion. MedVAE differs solely in its pretraining corpus (1.6 M medical images) and resulting weights; all diffusion-model training hyperparameters, inference schedules, and prediction targets remain fixed as stated in §3. We acknowledge that a full ablation retraining the exact SD-VAE architecture from scratch on the 1.6 M medical images is not present; such an experiment would require substantial additional compute that exceeds the resources available for this study. The public release of both model weights nevertheless permits independent verification of the architectural match. These additions will make the causal attribution to domain-specific pretraining fully transparent. revision: yes
Circularity Check
No circularity; empirical results from controlled VAE swap on held-out data
full rationale
The paper reports measured PSNR gains (+2.91 to +3.29 dB) and statistical tests (Wilcoxon, Cohen's d) after replacing the Stable Diffusion VAE with MedVAE pretrained on 1.6M medical images, with ablations on inference schedules and architectures. No equations, predictions, or claims reduce the improvement to a fitted parameter, self-definition, or self-citation chain. The R^2=0.67 correlation between autoencoder quality and SR performance is a post-hoc empirical observation on the same test sets, not a derivation that forces the result. The derivation chain is self-contained experimental comparison with no load-bearing self-referential steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Medical images occupy a distinct distribution from natural photographs such that a VAE pretrained on the former yields superior latent codes for super-resolution.
Reference graph
Works this paper leans on
-
[1]
Sanjana Murali, Hao Ding, Fope Adedeji, Cathy Qin, Johnes Obungoloch, Iris Asllani, Udunna Anazodo, Ntobeko A. B. Ntusi, Regina Mammen, Thoralf Niendorf, and Sola Adeleke. Bringing MRI to low- and middle-income countries: Directions, challenges and potential solutions.NMR in Biomedicine, 37(7):e4992, 2024. ISSN 1099-1492. doi: 10.1002/nbm.4992
-
[2]
Thomas Campbell Arnold, Colbey W Freeman, Brian Litt, and Joel M Stein. Low-field MRI: Clinical promise and challenges.Journal of Magnetic Resonance Imaging, 57(1): 25–44, 2023. doi: 10.1002/jmri.28408
-
[3]
Udunna C Anazodo et al. A framework for advancing sustainable magnetic resonance imaging access in Africa.NMR in Biomedicine, 36(3):e4846, 2023. doi: 10.1002/nbm.4846. Published version of 2022 medRxiv preprint (10.1101/2022.05.02.22274588)
-
[4]
Low field, high impact: Democratizing MRI for clinical and research innovation.BJR |Open, 7(1):tzaf022, 2025
Derek K Jones, Daniel C Alexander, Karen Chetcuti, Mara Cercignani, Kirsten A Donald, Mark A Griswold, Emre Kopanoglu, Ikeoluwa Lagunju, Johnes Obungoloch, Godwin Ogbole, Marco Palombo, and Andrew G Webb. Low field, high impact: Democratizing MRI for clinical and research innovation.BJR |Open, 7(1):tzaf022, 2025. doi: 10.1093/ bjro/tzaf022
2025
-
[5]
Temporal and spatial super resolution with latent diffusion model in medical MRI images, 2024
Vishal Dubey. Temporal and spatial super resolution with latent diffusion model in medical MRI images, 2024
2024
-
[6]
InverseSR: 3D brain MRI super-resolution using a latent diffusion model
Jueqi Wang, Jacob Levman, Walter Hugo Lopez Pinaya, Petru-Daniel Tudosiu, M Jorge Cardoso, and Razvan Marinescu. InverseSR: 3D brain MRI super-resolution using a latent diffusion model. InMedical Image Computing and Computer-Assisted Intervention – MICCAI 2023, volume 14229 ofLecture Notes in Computer Science, pages 441–450. Springer, 2023. doi: 10.1007/9...
-
[7]
sFRC for assessing hallucinations in medical image restoration, 2026
Prabhat Kc, Rongping Zeng, Nirmal Soni, and Aldo Badano. sFRC for assessing hallucinations in medical image restoration, 2026
2026
-
[8]
Hallucination score: Towards mitigating hallucinations in generative image super-resolution, 2025
Weiming Ren, Raghav Goyal, Zhiming Hu, Tristan Ty Aumentado-Armstrong, Iqbal Mohomed, and Alex Levinshtein. Hallucination score: Towards mitigating hallucinations in generative image super-resolution, 2025
2025
-
[9]
Jones, Jonathan Lee, and Meng Law
Stephen E. Jones, Jonathan Lee, and Meng Law. Neuroimaging at 3T vs 7T: Is It Really Worth It?Magnetic Resonance Imaging Clinics of North America, 29(1):1–12, February
-
[10]
doi: 10.1016/j.mric.2020.09.001
ISSN 1064-9689. doi: 10.1016/j.mric.2020.09.001
-
[11]
Ladd, Peter Bachert, Martin Meyerspeer, Ewald Moser, Armin M
Mark E. Ladd, Peter Bachert, Martin Meyerspeer, Ewald Moser, Armin M. Nagel, David G. Norris, Sebastian Schmitter, Oliver Speck, Sina Straub, and Moritz Zaiss. Pros and cons of ultra-high-field MRI/MRS for human application.Progress in Nuclear Magnetic Resonance Spectroscopy, 109:1–50, December 2018. ISSN 0079-6565. doi: 10.1016/j.pnmrs.2018.06.001. 22
-
[12]
Zhihao Wang, Jian Chen, and Steven C. H. Hoi. Deep learning for image super-resolution: A survey.IEEE Transactions on Pattern Analysis and Machine Intelligence, 43(10): 3365–3387, 2021. doi: 10.1109/TPAMI.2020.2982166
-
[13]
Linwei Yue, Huanfeng Shen, Jie Li, Qiangqiang Yuan, Hongyan Zhang, and Liangpei Zhang. Image super-resolution: The techniques, applications, and future.Signal Processing, 128:389–408, November 2016. ISSN 01651684. doi: 10.1016/j.sigpro.2016.05. 002
-
[14]
A deep journey into super-resolution: A survey.ACM Computing Surveys, 53(3):60:1–60:34, 2021
Saeed Anwar, Salman Khan, and Nick Barnes. A deep journey into super-resolution: A survey.ACM Computing Surveys, 53(3):60:1–60:34, 2021. doi: 10.1145/3390462
-
[15]
Yiping P. Du, Dennis L. Parker, Wayne L. Davis, and Guang Cao. Reduction of partial- volume artifacts with zero-filled interpolation in three-dimensional MR angiography. Journal of Magnetic Resonance Imaging, 4(5):733–741, 1994. ISSN 1522-2586. doi: 10.1002/jmri.1880040517
-
[16]
H. Greenspan, G. Oz, N. Kiryati, and S. Peled. MRI inter-slice reconstruction using super- resolution.Magnetic Resonance Imaging, 20(5):437–446, June 2002. ISSN 0730-725X. doi: 10.1016/S0730-725X(02)00511-8
-
[17]
Amir Pasha Mahmoudzadeh and Nasser H. Kashou. Interpolation-based super-resolution reconstruction: Effects of slice thickness.Journal of Medical Imaging, 1(3):034007, December 2014. ISSN 2329-4302, 2329-4310. doi: 10.1117/1.JMI.1.3.034007
-
[18]
Chi-Hieu Pham, Carlos Tor-D´ ıez, H´ el` ene Meunier, Nathalie Bednarek, Ronan Fablet, Nicolas Passat, and Fran¸ cois Rousseau. Multiscale brain MRI super-resolution using deep 3D convolutional networks.Computerized Medical Imaging and Graphics, 77:101647, October 2019. ISSN 0895-6111. doi: 10.1016/j.compmedimag.2019.101647
-
[19]
Real-time automatic fetal brain extraction in fetal MRI by deep learning
Yuhua Chen, Yibin Xie, Zhengwei Zhou, Feng Shi, Anthony G. Christodoulou, and Debiao Li. Brain MRI Super Resolution Using 3D Deep Densely Connected Neural Networks. In2018 IEEE 15th International Symposium on Biomedical Imaging (ISBI 2018), pages 739–742, April 2018. doi: 10.1109/ISBI.2018.8363679
-
[20]
Masutani, Naeim Bahrami, and Albert Hsiao
Evan M. Masutani, Naeim Bahrami, and Albert Hsiao. Deep Learning Single-Frame and Multiframe Super-Resolution for Cardiac MRI.Radiology, 295(3):552–561, June
-
[21]
doi: 10.1148/radiol.2020192173
ISSN 0033-8419. doi: 10.1148/radiol.2020192173
-
[22]
Christodoulou, Yibin Xie, Zhengwei Zhou, and Debiao Li
Yuhua Chen, Feng Shi, Anthony G. Christodoulou, Yibin Xie, Zhengwei Zhou, and Debiao Li. Efficient and accurate MRI super-resolution using a generative adversarial network and 3D multi-level densely connected network. InMedical Image Computing and Computer-Assisted Intervention – MICCAI 2018, volume 11070 ofLecture Notes in Computer Science, pages 91–99. ...
-
[23]
ESRGAN: Enhanced Super-Resolution Generative Adversarial Networks, September 2018
Xintao Wang, Ke Yu, Shixiang Wu, Jinjin Gu, Yihao Liu, Chao Dong, Chen Change Loy, Yu Qiao, and Xiaoou Tang. ESRGAN: Enhanced Super-Resolution Generative Adversarial Networks, September 2018. 23
2018
-
[24]
M. L. de Leeuw den Bouter, G. Ippolito, T. P. A. O’Reilly, R. F. Remis, M. B. van Gijzen, and A. G. Webb. Deep learning-based single image super-resolution for low-field MR brain images.Scientific Reports, 12(1):6362, April 2022. ISSN 2045-2322. doi: 10.1038/s41598-022-10298-6
-
[25]
Human Brain Map- ping15(2), 95–111 (2002).https://doi.org/https://doi.org/10.1002/hbm
Levente Baljer, Yiqi Zhang, Niall J. Bourke, Kirsten A. Donald, Layla E. Bradford, Jessica E. Ringshaw, Simone R. Williams, Sean C. L. Deoni, Steven C. R. Williams, Khula SA Study Team, Frantiˇ sek V´ aˇ sa, and Rosalyn J. Moran. Ultra-Low-Field Paediatric MRI in Low- and Middle-Income Countries: Super-Resolution Using a Multi-Orientation U-Net.Human Brai...
work page doi:10.1002/hbm 2025
-
[26]
Akshay S. Chaudhari et al. Super-resolution musculoskeletal MRI: Feasibility and application to T2 mapping.Magnetic Resonance in Medicine, 80(5):2139–2154, 2018. doi: 10.1002/mrm.27178
-
[27]
Ye Tian and Krishna S. Nayak. New clinical opportunities of low-field MRI: Heart, lung, body, and musculoskeletal.Magnetic Resonance Materials in Physics, Biology and Medicine, 37(1):1–14, February 2024. ISSN 1352-8661. doi: 10.1007/s10334-023-01123-w
-
[28]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj¨ orn Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 10684–10695, 2022
2022
-
[29]
Medical image super-resolution reconstruc- tion algorithms based on deep learning: A survey.Comput
Defu Qiu, Yuhu Cheng, and Xuesong Wang. Medical image super-resolution reconstruc- tion algorithms based on deep learning: A survey.Comput. Methods Prog. Biomed., 238 (C), August 2023. ISSN 0169-2607. doi: 10.1016/j.cmpb.2023.107590
-
[30]
Esben Plenge, Dirk H. J. Poot, Monique Bernsen, Gyula Kotek, Gavin Houston, Piotr Wielopolski, Louise van der Weerd, Wiro J. Niessen, and Erik Meijering. Super-resolution methods in MRI: Can they improve the trade-off between resolution, signal-to-noise ratio, and acquisition time?Magnetic Resonance in Medicine, 68(6):1983–1993, 2012. ISSN 1522-2594. doi:...
-
[31]
Walter H. L. Pinaya, Petru-Daniel Tudosiu, Jessica Dafflon, Pedro F. da Costa, Virginia Fernandez, Parashkev Nachev, Sebastien Ourselin, and M. Jorge Cardoso. Brain imaging generation with latent diffusion models. InMICCAI Workshop on Deep Generative Models, volume 13609 ofLecture Notes in Computer Science, pages 117–126, 2022. doi: 10.1007/978-3-031-18576-2 12
-
[32]
Score-based diffusion models for accelerated MRI
Hyungjin Chung and Jong Chul Ye. Score-based diffusion models for accelerated MRI. Medical Image Analysis, 80:102479, 2022. doi: 10.1016/j.media.2022.102479
-
[33]
Solving inverse problems in medical imaging with score-based generative models
Yang Song, Liyue Shen, Lei Xing, and Stefano Ermon. Solving inverse problems in medical imaging with score-based generative models. InInternational Conference on Learning Representations (ICLR), 2022. 24
2022
-
[34]
Muzaffer ¨Ozbey, Onat Dalmaz, Salman U. H. Dar, Hasan A. Bedel, S ¸aban ¨Ozturk, Alper G¨ ung¨ or, and TolgaC ¸ukur. Unsupervised medical image translation with adversarial diffusion models.IEEE Transactions on Medical Imaging, 42(12):3524–3539, 2023. doi: 10.1109/TMI.2023.3290149
-
[35]
SwinIR: Image restoration using Swin transformer
Jingyun Liang, Jiezhang Cao, Guolei Sun, Kai Zhang, Luc Van Gool, and Radu Timo- fte. SwinIR: Image restoration using Swin transformer. InIEEE/CVF International Conference on Computer Vision Workshops (ICCVW), pages 1833–1844, 2021
2021
-
[36]
Denoising diffusion probabilistic models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. InAdvances in Neural Information Processing Systems (NeurIPS), volume 33, pages 6840–6851, 2020
2020
-
[37]
Denoising diffusion implicit models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models. InInternational Conference on Learning Representations (ICLR), 2021
2021
-
[38]
Inversion by direct iteration: An alternative to denoising diffusion for image restoration.Transactions on Machine Learning Research (TMLR), 2023
Mauricio Delbracio and Peyman Milanfar. Inversion by direct iteration: An alternative to denoising diffusion for image restoration.Transactions on Machine Learning Research (TMLR), 2023
2023
-
[39]
Kleinberg, and Samy Bengio
Maithra Raghu, Chiyuan Zhang, Jon M. Kleinberg, and Samy Bengio. Transfusion: Understanding transfer learning for medical imaging. InAd- vances in Neural Information Processing Systems 32 (NeurIPS 2019), pages 3342–3352, 2019. URL https://proceedings.neurips.cc/paper/2019/hash/ eb1e78328c46506b46a4ac4a1e378b91-Abstract.html
2019
-
[40]
MedVAE: Efficient Automated Interpretation of Medical Images with Large-Scale Generalizable Autoencoders, June 2025
Maya Varma, Ashwin Kumar, Rogier van der Sluijs, Sophie Ostmeier, Louis Blankemeier, Pierre Chambon, Christian Bluethgen, Jip Prince, Curtis Langlotz, and Akshay Chaud- hari. MedVAE: Efficient Automated Interpretation of Medical Images with Large-Scale Generalizable Autoencoders, June 2025
2025
-
[41]
Quantum processor-inspired machine learning in the biomedical sciences
Omid Nejati Manzari, Hamid Ahmadabadi, Hossein Kashiani, Shahriar B Shokouhi, and Ahmad Ayatollahi. MedViT: A robust vision transformer for generalized medical image classification.Computers in Biology and Medicine, 157:106791, 2023. doi: 10.1016/j. compbiomed.2023.106791
work page doi:10.1016/j 2023
-
[42]
Castro, Benedikt Boecking, Harshita Sharma, Kenza Bouzid, Anton Schwaighofer, Maria Teodora Wetscherek, Anja Thieme, Matthew P
Shruthi Bannur, Stephanie Hyland, Qianchu Liu, Fernando P´ erez-Garc´ ıa, Maximilian Ilse, Daniel C. Castro, Benedikt Boecking, Harshita Sharma, Kenza Bouzid, Anton Schwaighofer, Maria Teodora Wetscherek, Anja Thieme, Matthew P. Lungren, Javier Alvarez-Valle, and Ozan Oktay. Learning to exploit temporal structure for biomedical vision-language processing....
2023
-
[43]
Castro, Shruthi Bannur, Anton Schwaighofer, Maria Teodora Wetscherek, Noel Codella, Matthew P
Fernando P´ erez-Garc´ ıa, Harshita Sharma, Sam Bond-Taylor, Kenza Bouzid, Valentina Salvatelli, Maximilian Ilse, Daniel C. Castro, Shruthi Bannur, Anton Schwaighofer, Maria Teodora Wetscherek, Noel Codella, Matthew P. Lungren, Javier Alvarez-Valle, Ozan Oktay, and Stephanie L. Hyland. RadDINO: Exploring scalable medical image encoders beyond text supervi...
-
[44]
Chitwan Saharia, Jonathan Ho, William Chan, Tim Salimans, David J. Fleet, and Mohammad Norouzi. Image super-resolution via iterative refinement.IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(4):4713–4726, 2023. doi: 10.1109/ TPAMI.2022.3204461
-
[45]
DiffIR: Efficient diffusion model for image restoration
Bin Xia, Yulun Zhang, Shiyin Wang, Yitong Wang, Xinglong Wu, Yapeng Tian, Wenming Yang, and Luc Van Gool. DiffIR: Efficient diffusion model for image restoration. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 13095–13105, 2023
2023
-
[46]
The perception-distortion tradeoff
Yochai Blau and Tomer Michaeli. The perception-distortion tradeoff. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 6228–6237, 2018
2018
-
[47]
Generative modelling with inverse heat dissipation
Severi Rissanen, Markus Heinonen, and Arno Solin. Generative modelling with inverse heat dissipation. InInternational Conference on Learning Representations (ICLR), 2023
2023
-
[48]
Flow straight and fast: Learning to generate and transfer data with rectified flow
Xingchao Liu, Chengyue Gong, and Qiang Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow. InInternational Conference on Learning Representations (ICLR), 2023
2023
-
[49]
Ziad Obermeyer, Brian Powers, Christine Vogeli, and Sendhil Mullainathan. Dissecting racial bias in an algorithm used to manage the health of populations.Science, 366(6464): 447–453, October 2019. doi: 10.1126/science.aax2342
-
[50]
McCradden, Kathleen Creel, Ronald Boellaard, Eliza- beth C
Jonathan Herington, Melissa D. McCradden, Kathleen Creel, Ronald Boellaard, Eliza- beth C. Jones, Abhinav K. Jha, Arman Rahmim, Peter J. H. Scott, John J. Sunderland, Richard L. Wahl, Sven Zuehlsdorff, and Babak Saboury. Ethical Considerations for Artificial Intelligence in Medical Imaging: Data Collection, Development, and Evalua- tion.Journal of Nuclear...
-
[51]
Practical and Ethical Considerations for Generative AI in Medical Imaging
Debesh Jha, Ashish Rauniyar, Desta Haileselassie Hagos, Vanshali Sharma, Nikhil Kumar Tomar, Zheyuan Zhang, Ilkin Isler, Gorkem Durak, Michael Wallace, Cemal Yazici, Tyler Berzin, Koushik Biswas, and Ulas Bagci. Practical and Ethical Considerations for Generative AI in Medical Imaging. In Esther Puyol-Ant´ on, Ghada Zamzmi, Aasa Feragen, Andrew P. King, V...
-
[52]
Ball, Jeremy Irvin, Allison Park, Erik Jones, Michael Bereket, Bhavik N
Nicholas Bien, Pranav Rajpurkar, Robyn L. Ball, Jeremy Irvin, Allison Park, Erik Jones, Michael Bereket, Bhavik N. Patel, Kristen W. Yeom, Katie Shpanskaya, Safwan Halabi, Evan Zucker, Gary Fanton, Derek F. Amanatullah, Christopher F. Beaulieu, Geoffrey M. Riley, Russell J. Stewart, Francis G. Blankenberg, David B. Larson, Ricky H. Jones, Curtis P. Langlo...
-
[53]
Ujjwal Baid et al. The RSNA-ASNR-MICCAI BraTS 2021 benchmark on brain tumor segmentation and radiogenomic classification, 2021. arXiv preprint arXiv:2107.02314
work page internal anchor Pith review arXiv 2021
- [54]
-
[55]
Mukhriddin Arabboev, Shohruh Begmatov, Mokhirjon Rikhsivoev, Khabibullo Nosirov, and Saidakmal Saydiakbarov. A comprehensive review of image super-resolution metrics: Classical and AI-based approaches.Acta IMEKO, 13(1):1–8, March 2024. ISSN 2221- 870X. doi: 10.21014/actaimeko.v13i1.1679
-
[56]
Melanie Dohmen, Mark A. Klemens, Ivo M. Baltruschat, Tuan Truong, and Matthias Lenga. Similarity and quality metrics for MR image-to-image translation.Scientific Reports, 15(1):3853, January 2025. ISSN 2045-2322. doi: 10.1038/s41598-025-87358-0
-
[57]
Efros, Eli Shechtman, and Oliver Wang
Richard Zhang, Phillip Isola, Alexei A. Efros, Eli Shechtman, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 586–595, 2018
2018
-
[58]
GANs trained by a two time-scale update rule converge to a local Nash equi- librium
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. GANs trained by a two time-scale update rule converge to a local Nash equi- librium. InAdvances in Neural Information Processing Systems (NeurIPS), volume 30, 2017
2017
-
[59]
Progressive Distillation for Fast Sampling of Diffusion Models, June 2022
Tim Salimans and Jonathan Ho. Progressive Distillation for Fast Sampling of Diffusion Models, June 2022. A Supplementary Tables This Supplementary Information accompanies the main manuscript. It contains Supplemen- tary Tables S1–S13, Supplementary Figures S1–S6, Supplementary Methods, and Supplemen- tary Notes S1–S4. 27 Table S1:Supplementary Table S1.In...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.