Recognition: unknown
Beyond Prompt: Fine-grained Simulation of Cognitively Impaired Standardized Patients via Stochastic Steering
Pith reviewed 2026-05-10 15:52 UTC · model grok-4.3
The pith
Steering vectors extracted from contrastive responses plus stochastic token modulation let AI simulate cognitively impaired standardized patients with controllable severity.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
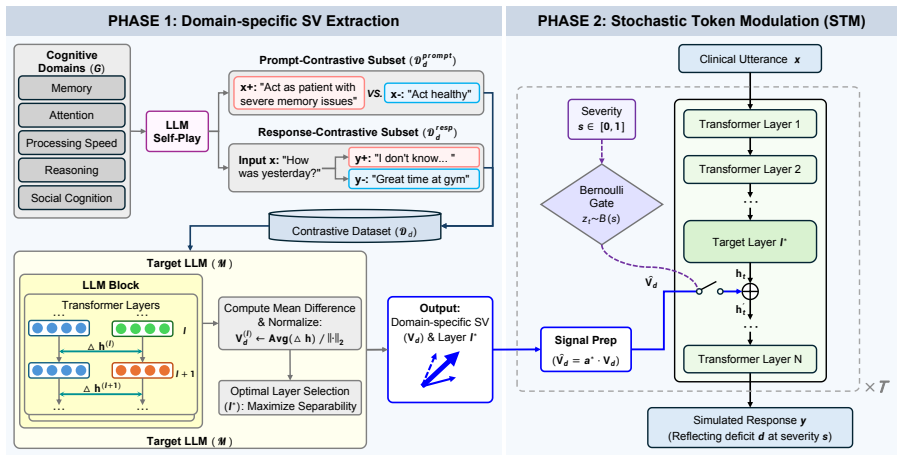
Domain-specific features of cognitive impairment can be isolated as steering vectors drawn from contrastive instruction-response pairs, and these vectors can be applied through Stochastic Token Modulation that regulates intervention probability at the token level, yielding simulations that surpass prompt-based baselines in both authenticity and the ability to set precise severity levels across impairment domains.
What carries the argument
Steering vectors extracted from contrastive pairs of instructions and responses, applied under Stochastic Token Modulation that sets the probability of intervening at each token during generation.
If this is right
- Training programs gain access to patient cases that vary systematically in both impairment domain and severity without additional human participants.
- Severity can be adjusted continuously during a single simulation session rather than through repeated prompt redesign.
- Consistency across multiple cognitive domains becomes measurable because the steering mechanism targets specific features.
- Ethical barriers to repeated exposure of real impaired individuals drop because the same base model can generate varied cases on demand.
Where Pith is reading between the lines
- The same contrastive-vector approach might transfer to simulating other patient conditions such as chronic pain or sensory loss.
- Embedding the modulation step inside interactive platforms could let trainee decisions dynamically shift the simulated patient's displayed impairment level.
- Comparison against longitudinal patient records could test whether severity settings align with observable progression patterns in real cognitive decline.
Load-bearing premise
That vectors taken from contrastive healthy versus impaired response pairs capture genuine domain features of cognitive deficits without injecting artifacts or flattening real clinical variation.
What would settle it
Blind ratings by clinicians showing no reliable difference between the model's generated dialogues and transcripts from actual patients at the same documented severity level on standard cognitive tests.
Figures













read the original abstract
Simulating Standardized Patients with cognitive impairment offers a scalable and ethical solution for clinical training. However, existing methods rely on discrete prompt engineering and fail to capture the heterogeneity of deficits across varying domains and severity levels. To address this limitation, we propose StsPatient for the fine-grained simulation of cognitively impaired patients. We innovatively capture domain-specific features by extracting steering vectors from contrastive pairs of instructions and responses. Furthermore, we introduce a Stochastic Token Modulation (STM) mechanism to regulate the intervention probability. STM enables precise control over impairment severity while mitigating the instability of conventional vector methods. Comprehensive experiments demonstrate that StsPatient significantly outperforms baselines in both clinical authenticity and severity controllability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes StsPatient for simulating cognitively impaired standardized patients. It extracts steering vectors from contrastive pairs of instructions and responses to capture domain-specific impairment features across domains and severity levels, and introduces Stochastic Token Modulation (STM) to stochastically regulate intervention probability for precise severity control. The central claim is that this outperforms prompt-engineering baselines in clinical authenticity and controllability, as shown by comprehensive experiments.
Significance. If the empirical claims hold with proper validation, the work could advance scalable, ethical tools for clinical training by enabling continuous rather than discrete control over simulated patient deficits. The STM mechanism offers a potential improvement over deterministic vector steering by addressing instability, representing a targeted technical contribution in LLM-based simulation.
major comments (3)
- [Abstract and §4] Abstract and §4 (Experiments): The claim that 'comprehensive experiments demonstrate that StsPatient significantly outperforms baselines in both clinical authenticity and severity controllability' is unsupported by any quantitative metrics, baseline descriptions, evaluation protocols, statistical tests, or result tables in the manuscript. This directly undermines assessment of the central empirical claim.
- [§3] §3 (Method): The construction of contrastive instruction-response pairs for steering vector extraction is unspecified (e.g., whether responses derive from real clinical transcripts, clinician-authored examples, or LLM outputs under different prompts). This is load-bearing for the claim that vectors capture authentic domain-specific cognitive impairment features without prompt artifacts or oversimplification of clinical heterogeneity.
- [§3.2] §3.2 (STM mechanism): The intervention probability in STM is listed as a free parameter without ablation or sensitivity analysis, which risks reducing the claimed 'precise control' to a tunable hyperparameter rather than a robust, generalizable mechanism.
minor comments (1)
- [Abstract] Abstract: The acronym 'STM' is used before its expansion as 'Stochastic Token Modulation', which should be corrected for readability.
Simulated Author's Rebuttal
We thank the referee for their thorough and constructive review of our manuscript. We address each major comment point by point below, providing clarifications where possible and outlining specific revisions to strengthen the presentation of our methods and results.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experiments): The claim that 'comprehensive experiments demonstrate that StsPatient significantly outperforms baselines in both clinical authenticity and severity controllability' is unsupported by any quantitative metrics, baseline descriptions, evaluation protocols, statistical tests, or result tables in the manuscript. This directly undermines assessment of the central empirical claim.
Authors: We acknowledge that the abstract and the high-level summary in §4 do not explicitly reference the quantitative results, which makes the central claim difficult to assess from those sections alone. The full experimental section does describe the baselines (prompt-engineering variants), evaluation protocols (clinician ratings for authenticity and severity correlation measures), and comparative results, but we agree these elements require clearer highlighting and explicit ties to the claim. We will revise the abstract to concisely summarize the key experimental outcomes and ensure §4 includes prominent references to all protocols, tables, and any statistical analyses performed. This will directly address the gap in presentation without changing the underlying experiments. revision: yes
-
Referee: [§3] §3 (Method): The construction of contrastive instruction-response pairs for steering vector extraction is unspecified (e.g., whether responses derive from real clinical transcripts, clinician-authored examples, or LLM outputs under different prompts). This is load-bearing for the claim that vectors capture authentic domain-specific cognitive impairment features without prompt artifacts or oversimplification of clinical heterogeneity.
Authors: The referee correctly identifies that the precise sourcing and generation process for the contrastive pairs is not described in adequate detail in §3. We will expand this section with a dedicated explanation of the pair construction pipeline, including the use of clinician-authored examples as the primary source for authenticity, supplementation with de-identified real clinical transcripts where available, and controlled LLM generation for coverage across severity levels. We will also detail the expert review process used to mitigate prompt artifacts and ensure clinical heterogeneity is preserved. This addition will make the method fully reproducible and strengthen the validity argument. revision: yes
-
Referee: [§3.2] §3.2 (STM mechanism): The intervention probability in STM is listed as a free parameter without ablation or sensitivity analysis, which risks reducing the claimed 'precise control' to a tunable hyperparameter rather than a robust, generalizable mechanism.
Authors: We agree that presenting the intervention probability solely as a free parameter without supporting analysis weakens the claim of precise and robust control. While we selected values through preliminary validation to target specific severity levels, no systematic ablation or sensitivity study across parameter ranges was included. We will add such an analysis to the revised manuscript, reporting how different probability settings affect controllability metrics, output stability, and consistency with clinical expectations. This will demonstrate that the STM mechanism provides meaningful control beyond simple tuning. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper proposes StsPatient as a new method that extracts steering vectors from contrastive instruction-response pairs and introduces an independent Stochastic Token Modulation (STM) mechanism for severity control. These components are presented as novel constructions rather than reductions of prior fitted parameters, self-definitions, or self-citation chains. No equations or derivations are shown that equate outputs to inputs by construction; the central claims rest on experimental comparisons to baselines, which are external to the method definition itself. The derivation is self-contained as an engineering proposal with no load-bearing self-referential steps.
Axiom & Free-Parameter Ledger
free parameters (1)
- intervention probability in STM
axioms (1)
- domain assumption Steering vectors derived from contrastive instruction-response pairs capture the heterogeneous domain-specific features of cognitive impairment
invented entities (1)
-
Stochastic Token Modulation (STM)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
InProceedings of the 2025 CHI Confer- ence on Human Factors in Computing Systems, pages 1–22
Promoting cognitive health in elder care with large language model-powered socially assis- tive robots. InProceedings of the 2025 CHI Confer- ence on Human Factors in Computing Systems, pages 1–22. Ryan Louie, Ananjan Nandi, William Fang, Cheng Chang, Emma Brunskill, and Diyi Yang. 2024. Roleplay-doh: Enabling domain-experts to create llm-simulated patien...
2025
-
[2]
InProceedings of the 62nd Annual Meet- ing of the Association for Computational Linguistics (Volume 1: Long Papers), pages 7828–7840
Large language models are superpositions of all characters: Attaining arbitrary role-play via self- alignment. InProceedings of the 62nd Annual Meet- ing of the Association for Computational Linguistics (Volume 1: Long Papers), pages 7828–7840. Lauren McCollum and Jason Karlawish. 2020. Cog- nitive impairment evaluation and management.The Medical Clinics ...
2020
-
[3]
Huachuan Qiu and Zhenzhong Lan
Designing role vectors to improve llm infer- ence behaviour.arXiv preprint arXiv:2502.12055. Huachuan Qiu and Zhenzhong Lan. 2024. Interactive agents: Simulating counselor-client psychological counseling via role-playing llm-to-llm interactions. Preprint, arXiv:2408.15787. Daniel Reichenpfader and Kerstin Denecke. 2024. Sim- ulating diverse patient popula...
-
[4]
Qwen3 technical report.arXiv preprint arXiv:2505.09388. Stav Yosef, Moreah Zisquit, Ben Cohen, Anat Klomek Brunstein, Kfir Bar, and Doron Friedman
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Representation Engineering: A Top-Down Approach to AI Transparency
Assessing motivational interviewing sessions with AI-generated patient simulations. InProceed- ings of the 9th Workshop on Computational Linguis- tics and Clinical Psychology (CLPsych 2024), pages 1–11, St. Julians, Malta. Association for Computa- tional Linguistics. Runcong Zhao, Wenjia Zhang, Jiazheng Li, Lixing Zhu, Yanran Li, Yulan He, and Lin Gui. 20...
work page internal anchor Pith review arXiv 2024
-
[6]
What did you have for break- fast?
Output from Response Generation (Yields Re- sponse Subset) Neutral System Prompt: Name: John. Age: 72. Back- ground: Retired teacher. Clinician Prompt: “What did you have for break- fast?” Response (+) (Impaired): “Breakfast? I... well, maybe toast? Or was that yesterday?” Response (-) (Healthy): “I had oatmeal and a cup of coffee around 8 AM.”
-
[7]
Act as a patient
Derived Inputs (Yields Prompt Subset) System Prompt (+): [Neutral Profile]... Act as a patient with memory loss. System Prompt (-): [Neutral Profile]... Act as a healthy individual. (Both use the same Clinician Prompt as above) Figure 4: Illustrative example showing the outputs from the unified generation pipeline and the subsequent derivation of prompt i...
2025
-
[8]
For detailed prompts, see Figure 13
Static System Prompt.This component estab- lishes the clinical persona and enforces a natural, non-judgmental conversational style. For detailed prompts, see Figure 13
-
[9]
For THIS reply only, gently lean in the following direction
Dynamic Domain Guidance.To systematically verify specific deficits, we inject a targeted instruc- tion into the user prompt at each turn:“For THIS reply only, gently lean in the following direction... ”. Table 5 details the specific guidance used for each domain. Collectively, the LLM Therapist generated 600 dialogue transcripts for each simulation method...
2004
-
[10]
breaks character
before aggregating them into a final score on a 5-point Likert scale. This rigorous, granular an- notation process proved to exceed the capabilities of current LLM-based evaluators. Our preliminary experiments revealed that the LLM struggles to provide discriminative scores across specific di- mensions, leading to unreliable aggregation. Con- sequently, t...
2024
-
[11]
Yeah, I think I remember... I got a pill organizer, but I’m not sure if I even used it. I tried to remember, but I got confused. I guess I just forgot
Memory Only (vmem) “Yeah, I think I remember... I got a pill organizer, but I’m not sure if I even used it. I tried to remember, but I got confused. I guess I just forgot. ”
-
[12]
I, uh, I’ve been putting the pills in the organizer every night after dinner
Processing Speed Only (vproc) “Yeah, I think so. I, uh, I’ve been putting the pills in the organizer every night after dinner. I tried to remember, but I guess I didn’t really keep the instruction sheet on the fridge. I’m sorry. I’ll do better. ”
-
[13]
Moderate Impair- ment
Dual Injection (vmem +v proc) “Yeah, I think I did. I remember something about it... I guess I tried to remember to take my pills after dinner. But I got a little confused, like, when exactly was it? I think I... I don’t know, maybe I missed a few days? I’m sorry. ” The results demonstrate distinct behavioral phe- notypes. TheMemory-steered response exhib...
2024
-
[14]
Ignore other cognitive problems
Memory Deficit Patterns Y ou are assessingonly memory-related cognitive defects. Ignore other cognitive problems. Y ou mainly look for these patterns: • Pattern 1: N-Step Instruction Failure.Doctor gives a multi-part request; patient recalls only some parts or stays vague. •Pattern 2: Intra-visit Working-Memory Loss.Patient can’t hold what was just said d...
-
[15]
I think
Critical Diversity Requirement (response_positive) Y ou MUST vary thetype of failure. Do NOT just use "I think...". Randomly select one of these styles: •Total Blanking:Direct admission of failure ("I honestly don’t remember"). •Vague Guessing:Uncertain, low-detail attempts ("Maybe the red one?"). •Fragmentation:Getting part of it but trailing off ("I tak...
-
[16]
I take... [uhh, maybe the white one?]
Bracketing Rule •Pos:Enclose theentire spanthat exhibits the deficit, including hesitation markers. Example:"I take... [uhh, maybe the white one?]" • Neg:For each bracketed failure in response_positive, provide thecorrect, factual equivalentin response_negative. Example:"I take [10mg twice a day]."
-
[17]
pattern":
Output Format and Requirements Y ou must generate a JSON list containing[N]JSON objects. Each object must follow this precise format: { "pattern": "Selected Pattern Name", "system_prompt": "String describing the patient (Name, Age, Gender, Education...).", "history": [ { "role": "user", "content": "..." }, { "role": "assistant", "content": "..." } ], "pro...
-
[18]
pattern":
Example Data Point (Reference) Pattern: Background Amnesia { "pattern": "Background Amnesia", "system_prompt": "Name: Gene. Age: 74. History: Alzheimer’s diagnosed 1 year ago.", "history": [ { "role": "user", "content": "Hi Gene, how have things been going?" }, { "role": "assistant", "content": "Pretty good. My son says I’m tracking stuff better." } ], "p...
-
[19]
Memory 6
Processing speed 5. Memory 6. None
-
[20]
•Single Label:Strong, consistent evidence for one domain; no meaningful evidence for others
Selection Rules (Very Important) Y ou may outputONEorTWOlabels (never more). •Single Label:Strong, consistent evidence for one domain; no meaningful evidence for others. • Two Labels:If two domains both show clear signs, output both (prominent one first). If genuinely unsure between A and B, output both. •None:Only if the patient’s thinking appears broadl...
-
[21]
Breakdowns in turning known tasks into a coherent, workable plan
High-level Meanings & Cues • Reasoning & Problem solving:Issue with working out plans or logical relationships. Breakdowns in turning known tasks into a coherent, workable plan. • Social cognition:Issue with reading people. Misses emotional messages; blunt/tactless; fails to interpret social signals. • Attention:Issue with staying focused. Focus jumps aro...
-
[22]
Important Distinctions •Plan/Conclusion difficulty→Reasoning & Problem solving •Feelings/Social cues difficulty→Social cognition •Focus drifting/Wrong topic→Attention •Slow/Laggy but retains info→Processing speed •Forgetting recent info→Memory •Note:Stress/Mood do NOT decide the label; base choice on cognitive thinking patterns
-
[23]
reflection
Output Format Requirements Output a single JSON object. Do NOT include any extra keys or text outside the JSON. { "reflection": "Briefly explain reasoning (2-5 sentences), pointing to key behaviors.", "labels": ["Category Name"]OR["Category A", "Category B"] } Command:Now read the conversation and produce your JSON. Figure 8: The clinical rater instructio...
-
[24]
Synthesize the input demographics into a clinical summary
-
[25]
Inject a specific, plausible memory deficit that conflicts with the patient’s lifestyle or personality
-
[26]
domains”, “deficits
Derive the psychological profile (beliefs, thoughts, behaviors) resulting from this deficit. Output Specification (JSON Only) Return a single JSON object containing the following fields. •nameA short first name. •historyA clinical summary including exactly ONE sentence describing a realistic memory deficit. •core_beliefsFundamental beliefs activated by th...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.