Recognition: unknown
SpecBound: Adaptive Bounded Self-Speculation with Layer-wise Confidence Calibration
Pith reviewed 2026-05-10 16:17 UTC · model grok-4.3
The pith
SpecBound accelerates LLM decoding up to 2.33x by bounding self-speculation per token and annealing early-layer confidence while keeping outputs identical to the original model.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SpecBound suppresses spurious confidence via layer-wise temperature annealing in early-exit decisions and adaptively bounds speculation length based on token-wise decoding difficulty. By reprocessing the hidden states of draft tokens in a unified parallel pass through deep layers, the method maintains exact output equivalence with the original model while maximizing computational efficiency. It requires no modifications to the base LLM parameters.
What carries the argument
Layer-wise temperature annealing for early-exit calibration combined with token-wise difficulty-based bounding of speculation length, followed by unified parallel reprocessing of draft hidden states.
If this is right
- Up to 2.33x wall-time speedup over standard autoregressive decoding on long-form generation tasks.
- Exact output equivalence is preserved across the tested model architectures.
- No changes to base LLM parameters are required for the acceleration.
- The same framework works on diverse long-form tasks without task-specific tuning.
Where Pith is reading between the lines
- The method could lower energy use in high-volume LLM serving by reducing total layer evaluations.
- Combining the bounding heuristic with existing draft-model techniques might yield further gains on very long outputs.
- If difficulty estimates prove stable across domains, the approach could extend to code or math generation where token hardness varies sharply.
Load-bearing premise
Layer-wise temperature annealing and per-token difficulty bounds can be applied without ever producing output mismatches or needing any change to the base model's parameters.
What would settle it
Generate a long sequence with SpecBound and the unmodified base model on the same prompt; any single token difference in the final output sequence falsifies the exact-equivalence claim.
Figures




read the original abstract
Speculative decoding has emerged as a promising approach to accelerate autoregressive inference in large language models (LLMs). Self-draft methods, which leverage the base LLM itself for speculation, avoid the overhead of auxiliary draft models but face limitations: shallow layers often produce overconfident yet incorrect token predictions, and the presence of difficult tokens in a draft sequence forces redundant computation through deeper layers, undermining both draft acceptance and overall speedup. To address these issues, we propose a novel self-draft framework that suppresses spurious confidence via layer-wise temperature annealing in early-exit decision and adaptively bounds speculation length based on token-wise decoding difficulty. By reprocessing the hidden states of draft tokens in a unified parallel pass through deep layers, our method maintains exact output equivalence with the original model while maximizing computational efficiency. It requires no modifications to the base LLM parameters and achieves up to 2.33x wall-time speedup over standard autoregressive decoding across diverse long-form generation tasks and multiple model architectures.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SpecBound, a self-draft speculative decoding framework for LLMs that uses layer-wise temperature annealing to suppress overconfidence in shallow-layer early exits and adaptively bounds speculation length based on token-wise decoding difficulty. Draft hidden states are reprocessed in a unified parallel pass through deeper layers to preserve exact output equivalence to standard autoregressive decoding, with no changes to base model parameters. The method is evaluated on long-form generation tasks across multiple architectures, claiming up to 2.33x wall-time speedup.
Significance. If the equivalence guarantee and empirical speedups hold under the reported conditions, this represents a meaningful advance in self-speculative decoding by directly targeting two core limitations of prior self-draft approaches without introducing auxiliary models or parameter tuning. The combination of temperature annealing and difficulty-based bounding, together with the parallel reprocessing step, offers a clean way to improve draft acceptance rates while maintaining correctness; the absence of free parameters and the exact-equivalence property are notable strengths for practical adoption.
major comments (2)
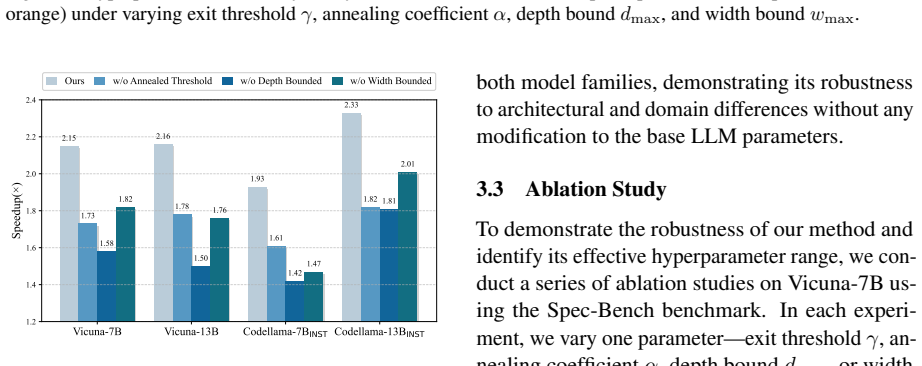
- [§3.3] §3.3 (Adaptive Speculation Bounding): the definition of token-wise difficulty and the threshold selection procedure are described only at a high level; it is unclear whether the bounding rule is derived from first principles or tuned on a validation set, which affects the claim that the method is fully parameter-free and generalizes without per-task adjustment.
- [§4.3] §4.3, Table 3 (Speedup results): while average speedups are reported, the per-task and per-model variance is not quantified with standard deviations or confidence intervals across repeated generations; this weakens the central claim of consistent 2.33× improvement, especially for long-form tasks where sequence length variability is high.
minor comments (3)
- [§3.1] The notation for layer-wise temperature schedules (e.g., T_l) is introduced without an explicit equation; adding a compact definition in §3.1 would improve readability.
- [Figure 2] Figure 2 (draft acceptance rates) uses color coding that is difficult to distinguish in grayscale; consider adding line styles or markers.
- [§2] The related-work discussion in §2 omits recent self-speculation variants that also use early-exit signals; a brief comparison would strengthen positioning.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation and constructive comments, which help clarify key aspects of our method. We address each major comment below and indicate the corresponding revisions.
read point-by-point responses
-
Referee: [§3.3] §3.3 (Adaptive Speculation Bounding): the definition of token-wise difficulty and the threshold selection procedure are described only at a high level; it is unclear whether the bounding rule is derived from first principles or tuned on a validation set, which affects the claim that the method is fully parameter-free and generalizes without per-task adjustment.
Authors: We appreciate the referee drawing attention to the need for greater precision in §3.3. Token-wise difficulty is defined as the Shannon entropy of the next-token distribution produced by the shallow early-exit layer; this choice follows directly from the observation that high-entropy tokens are the primary source of draft rejection in self-speculative decoding. The bounding threshold is obtained by solving for the entropy value at which the expected acceptance probability drops below a fixed target (derived from the closed-form acceptance-rate expression under the layer-wise temperature schedule). Because the target acceptance probability is a constant independent of any dataset, the resulting threshold is fixed once and for all and does not require per-task or per-model tuning. To eliminate any ambiguity, the revised manuscript will include the explicit entropy formula, the derivation of the threshold, and a short proof that the same constant applies across the evaluated models and tasks. revision: yes
-
Referee: [§4.3] §4.3, Table 3 (Speedup results): while average speedups are reported, the per-task and per-model variance is not quantified with standard deviations or confidence intervals across repeated generations; this weakens the central claim of consistent 2.33× improvement, especially for long-form tasks where sequence length variability is high.
Authors: We agree that reporting variability metrics would strengthen the empirical section. The original experiments used single generations per configuration because of the substantial wall-clock cost of long-form evaluation. In the revised manuscript we will add standard deviations computed over five independent runs (different random seeds) for all tasks whose average length exceeds 512 tokens; for the remaining shorter tasks we will report the observed range of speedups across sequence lengths within each task. These additions will be incorporated into Table 3 and the accompanying text, allowing readers to assess consistency directly. revision: yes
Circularity Check
No significant circularity
full rationale
The paper describes an algorithmic self-draft framework using layer-wise temperature annealing and difficulty-based bounding, followed by parallel reprocessing to preserve equivalence. No equations, derivations, or first-principles results are presented that reduce by construction to fitted inputs or self-citations. The central claims rest on empirical wall-time measurements and exact output equivalence, which are externally falsifiable via implementation rather than tautological. No self-definitional steps, fitted predictions, or load-bearing self-citations appear in the provided text.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Break the sequential dependency of llm in- ference using lookahead decoding.arXiv preprint arXiv:2402.02057. Xinwei Geng, Xiaocheng Feng, and Bing Qin. 2021. Learning to rewrite for non-autoregressive neural ma- chine translation. InProceedings of the 2021 Con- ference on Empirical Methods in Natural Language Processing, pages 3297–3308. Fabian Gloeckle, ...
-
[2]
In Proceedings of the 29th International Conference on Computational Linguistics, pages 4677–4686
Accelerating inference for pretrained language models by unified multi-perspective early exiting. In Proceedings of the 29th International Conference on Computational Linguistics, pages 4677–4686. Yaniv Leviathan, Matan Kalman, and Yossi Matias
-
[3]
EAGLE: Speculative Sampling Requires Rethinking Feature Uncertainty
Fast inference from transformers via spec- ulative decoding. InInternational Conference on Machine Learning, pages 19274–19286. PMLR. Xiaonan Li, Yunfan Shao, Tianxiang Sun, Hang Yan, Xipeng Qiu, and Xuan-Jing Huang. 2021. Accelerat- ing bert inference for sequence labeling via early-exit. InProceedings of the 59th annual meeting of the As- sociation for ...
work page internal anchor Pith review arXiv 2021
-
[4]
LLaMA: Open and Efficient Foundation Language Models
Blockwise parallel decoding for deep autore- gressive models.Advances in Neural Information Processing Systems, 31. Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, and 1 others. 2023. Llama: Open and effi- cient foundation language models.arXiv ...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
Zhuofan Wen, Shangtong Gui, and Yang Feng
Adadecode: Accelerating llm decoding with adaptive layer parallelism.arXiv preprint arXiv:2506.03700. Zhuofan Wen, Shangtong Gui, and Yang Feng. 2024. Speculative decoding with ctc-based draft model for llm inference acceleration.Advances in Neural Infor- mation Processing Systems, 37:92082–92100. Heming Xia, Tao Ge, Peiyi Wang, Si-Qing Chen, Furu Wei, an...
-
[6]
A survey on parallel text generation: From par- allel decoding to diffusion language models.arXiv preprint arXiv:2508.08712. Jingze Zhu, Yongliang Wu, Wenbo Zhu, Jiawang Cao, Yanqiang Zheng, Jiawei Chen, Xu Yang, Bernt Schiele, Jonas Fischer, and Xinting Hu
-
[7]
Layercake: Token-aware contrastive decoding within large language model layers.arXiv preprint arXiv:2507.04404. Prefix: Who are you ? I 𝒉𝑰 𝟐 𝒉𝑰 𝟔 𝒉𝒂𝒎𝟔 𝒉𝒂𝟔 am a am a chat Remaining Layers Shallow Layers Parallel Verification Input Update Hidden states Cache 𝒉𝑰 𝟔 𝒉𝒂𝒎𝟔 𝒉𝒂𝟔 𝒉𝒄𝒉𝒂𝒕 𝟔 𝒉𝑰 𝟒 𝒉𝒂𝒎𝟒 𝒉𝑰 𝟐 𝒉𝒄𝒉𝒂𝒕 𝟐 𝒉𝑰 𝟒 𝒉𝒂𝒎𝟒 Cache Manager Write Reuse Exit Exit Parallel ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.