Recognition: unknown
ARGen: Affect-Reinforced Generative Augmentation towards Vision-based Dynamic Emotion Perception
Pith reviewed 2026-05-10 14:51 UTC · model grok-4.3
The pith
ARGen generates synthetic dynamic facial expression videos by injecting affective priors into diffusion models to improve recognition of scarce emotions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ARGen establishes an interpretable and generalizable generative augmentation paradigm for vision-based affective computing by operating in two stages: Affective Semantic Injection establishes affective knowledge alignment through facial Action Units and retrieval-augmented prompt generation to synthesize fine-grained emotional descriptions; Adaptive Reinforcement Diffusion then integrates text-conditioned image-to-video diffusion with reinforcement learning, adding inter-frame guidance and a multi-objective reward to optimize naturalness, facial integrity, and efficiency.
What carries the argument
Two-stage Affect-Reinforced Generative Augmentation: the ASI stage uses facial Action Units and retrieval-augmented prompts from visual-language models to inject emotional priors, while the ARD stage applies reinforcement learning to text-conditioned diffusion for temporal consistency.
If this is right
- Recognition accuracy rises for long-tail emotion classes because models see more varied temporal sequences during training.
- Generation quality improves on naturalness and facial consistency metrics when the multi-objective reward is applied.
- The method supplies an interpretable route for adding affective knowledge to any image-to-video diffusion pipeline.
- Data-adaptive augmentation becomes feasible without manual labeling of new emotion videos.
Where Pith is reading between the lines
- The same injection-plus-reinforcement pattern could be tested on other scarce visual categories such as rare actions or medical anomalies.
- If generation speed improves further, the approach might support on-the-fly data creation during model training rather than offline augmentation.
- Cross-dataset transfer could be measured by generating videos styled after one emotion corpus and testing recognition on another.
Load-bearing premise
The synthetic videos accurately reproduce the real temporal dynamics of scarce emotions without adding artifacts or distribution shifts that would harm downstream recognition models.
What would settle it
A controlled experiment in which a standard recognition model is trained once with only real data and once with ARGen-augmented data, then tested on held-out real videos of scarce emotions; no accuracy gain on the scarce classes would falsify the claim.
Figures







read the original abstract
Dynamic facial expression recognition in the wild remains challenging due to data scarcity and long-tail distributions, which hinder models from effectively learning the temporal dynamics of scarce emotions. To address these limitations, we propose ARGen, an Affect-Reinforced Generative Augmentation Framework that enables data-adaptive dynamic expression generation for robust emotion perception. ARGen operates in two stages: Affective Semantic Injection (ASI) and Adaptive Reinforcement Diffusion (ARD). The ASI stage establishes affective knowledge alignment through facial Action Units and employs a retrieval-augmented prompt generation strategy to synthesize consistent and fine-grained affective descriptions via large-scale visual-language models, thereby injecting interpretable emotional priors into the generation process. The ARD stage integrates text-conditioned image-to-video diffusion with reinforcement learning, introducing inter-frame conditional guidance and a multi-objective reward function to jointly optimize expression naturalness, facial integrity, and generative efficiency. Extensive experiments on both generation and recognition tasks verify that ARGen substantially enhances synthesis fidelity and improves recognition performance, establishing an interpretable and generalizable generative augmentation paradigm for vision-based affective computing.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes ARGen, a two-stage framework for generative data augmentation in dynamic facial expression recognition to address data scarcity and long-tail distributions. The ASI stage uses facial Action Units and retrieval-augmented prompt generation with VLMs to inject affective priors; the ARD stage combines text-conditioned image-to-video diffusion with reinforcement learning, inter-frame guidance, and a multi-objective reward function optimizing naturalness, integrity, and efficiency. The central claim is that extensive experiments on generation and recognition tasks show ARGen substantially enhances synthesis fidelity and improves recognition performance, establishing an interpretable paradigm for vision-based affective computing.
Significance. If the experimental verification holds, the work could meaningfully advance affective computing by offering a data-adaptive way to synthesize scarce-emotion dynamics with explicit affective alignment, potentially improving model robustness without additional real-data collection.
major comments (2)
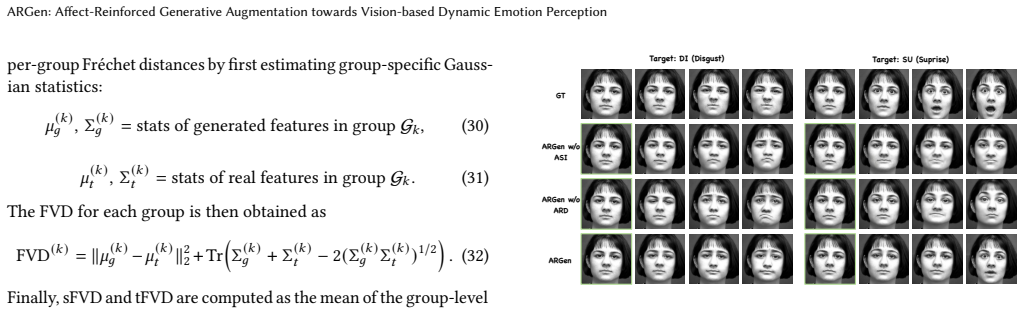
- Abstract: the claim that 'extensive experiments ... verify that ARGen substantially enhances synthesis fidelity and improves recognition performance' is load-bearing for the central contribution, yet the abstract (and provided summary) contains no quantitative results, specific metrics (e.g., FVD, AU consistency, accuracy deltas), ablation tables, or baseline comparisons, preventing assessment of whether gains exceed data-volume effects or artifact fitting.
- ARD stage description: the multi-objective reward and inter-frame guidance are presented as ensuring faithful temporal dynamics, but no video-level distribution metrics (temporal AU trajectories, motion statistics, cross-domain MMD) or artifact analysis are referenced, leaving the weakest assumption—that synthetic sequences match real scarce-emotion dynamics without diffusion-induced smoothing or reward-induced exaggeration—unverified and directly relevant to downstream recognition claims.
minor comments (1)
- Notation for the reward function components and ASI prompt retrieval could be clarified with explicit equations or pseudocode to improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments highlight important opportunities to strengthen the presentation of quantitative evidence and the verification of temporal dynamics. We address each point below and have revised the manuscript accordingly.
read point-by-point responses
-
Referee: Abstract: the claim that 'extensive experiments ... verify that ARGen substantially enhances synthesis fidelity and improves recognition performance' is load-bearing for the central contribution, yet the abstract (and provided summary) contains no quantitative results, specific metrics (e.g., FVD, AU consistency, accuracy deltas), ablation tables, or baseline comparisons, preventing assessment of whether gains exceed data-volume effects or artifact fitting.
Authors: We agree that the abstract would be strengthened by including concrete quantitative results to support the central claim. The full manuscript reports detailed metrics (including FVD for synthesis fidelity, accuracy improvements on long-tail emotions, and baseline comparisons) in the experimental sections. In the revised version, we have updated the abstract to incorporate key quantitative highlights—such as specific FVD reductions, recognition accuracy deltas, and brief baseline references—while remaining within standard abstract length constraints. This makes the load-bearing claim directly assessable. revision: yes
-
Referee: ARD stage description: the multi-objective reward and inter-frame guidance are presented as ensuring faithful temporal dynamics, but no video-level distribution metrics (temporal AU trajectories, motion statistics, cross-domain MMD) or artifact analysis are referenced, leaving the weakest assumption—that synthetic sequences match real scarce-emotion dynamics without diffusion-induced smoothing or reward-induced exaggeration—unverified and directly relevant to downstream recognition claims.
Authors: This observation is valid; our original evaluation emphasized overall generation quality and downstream recognition gains rather than explicit video-level distributional comparisons. While the recognition improvements provide indirect validation of the generated dynamics, we acknowledge that direct metrics would more rigorously address potential artifacts. In the revised manuscript, we have added video-level analyses including temporal AU trajectory comparisons, motion statistics, cross-domain MMD to real data, and a dedicated artifact analysis section to confirm alignment with real scarce-emotion dynamics. revision: yes
Circularity Check
No circularity: framework stages and external benchmarks remain independent
full rationale
The paper defines ASI (affective semantic injection via AUs and retrieval-augmented prompts) and ARD (text-conditioned I2V diffusion plus RL with inter-frame guidance and multi-objective rewards) as sequential generative stages whose outputs are then fed to separate downstream recognition models. Evaluation relies on external recognition benchmarks and generation fidelity metrics rather than any self-referential loop or fitted parameter renamed as prediction. No equations, uniqueness theorems, or self-citations are shown to reduce the claimed improvements to the inputs by construction. The derivation chain therefore contains independent content.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al . 2025. Qwen2.5-vl technical report.arXiv preprint arXiv:2502.13923(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [2]
-
[3]
Andreas Blattmann, Timo Milbich, Michael Dorkenwald, and Bjorn Ommer. 2021. Understanding object dynamics for interactive image-to-video synthesis. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 5171–5181
2021
-
[4]
Andreas Blattmann, Robin Rombach, Huan Ling, Tim Dockhorn, Seung Wook Kim, Sanja Fidler, and Karsten Kreis. 2023. Align your latents: High-resolution video synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 22563–22575
2023
- [5]
-
[6]
Rafael A Calvo and Sidney D’Mello. 2010. Affect detection: An interdisciplinary review of models, methods, and their applications.IEEE Transactions on affective computing1, 1 (2010), 18–37
2010
-
[7]
Yin Chen, Jia Li, Yu Zhang, Zhenzhen Hu, Shiguang Shan, Meng Wang, and Richang Hong. 2025. Static for dynamic: Towards a deeper understanding of dynamic facial expressions using static expression data.IEEE Transactions on Affective Computing(2025)
2025
-
[8]
Zebang Cheng, Zhi-Qi Cheng, Jun-Yan He, Kai Wang, Yuxiang Lin, Zheng Lian, Xiaojiang Peng, and Alexander Hauptmann. 2024. Emotion-llama: Multimodal emotion recognition and reasoning with instruction tuning.Advances in Neural Information Processing Systems37 (2024), 110805–110853
2024
-
[9]
Prafulla Dhariwal and Alexander Nichol. 2021. Diffusion models beat gans on image synthesis.Advances in neural information processing systems34 (2021), 8780–8794
2021
-
[10]
Paul Ekman and Wallace V Friesen. 1978. Facial action coding system.Environ- mental Psychology & Nonverbal Behavior(1978)
1978
-
[11]
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas Müller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, et al. 2024. Scaling Rectified Flow Transformers for High-Resolution Image Synthesis. In ICML
2024
- [12]
-
[13]
Yuwei Guo, Ceyuan Yang, Anyi Rao, Zhengyang Liang, Yaohui Wang, Yu Qiao, Maneesh Agrawala, Dahua Lin, and Bo Dai. 2023. Animatediff: Animate your personalized text-to-image diffusion models without specific tuning.arXiv preprint arXiv:2307.04725(2023)
work page internal anchor Pith review arXiv 2023
-
[14]
Jonathan Ho, William Chan, Chitwan Saharia, Jay Whang, Ruiqi Gao, Alexey Gritsenko, Diederik P Kingma, Ben Poole, Mohammad Norouzi, David J Fleet, et al. 2022. Imagen video: High definition video generation with diffusion models. arXiv preprint arXiv:2210.02303(2022)
work page internal anchor Pith review arXiv 2022
-
[15]
Jonathan Ho, Ajay Jain, and Pieter Abbeel. 2020. Denoising diffusion probabilistic models.Advances in neural information processing systems33 (2020), 6840–6851
2020
-
[16]
Jonathan Ho and Tim Salimans. 2022. Classifier-free diffusion guidance.arXiv preprint arXiv:2207.12598(2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[17]
Tobias Höppe, Arash Mehrjou, Stefan Bauer, Didrik Nielsen, and Andrea Dittadi
-
[18]
Diffusion Models for Video Prediction and Infilling.Transactions on Machine Learning Research2022 (2022)
2022
-
[19]
Xingxun Jiang, Yuan Zong, Wenming Zheng, Chuangao Tang, Wanchuang Xia, Cheng Lu, and Jiateng Liu. 2020. Dfew: A large-scale database for recognizing dy- namic facial expressions in the wild. InProceedings of the 28th ACM international conference on multimedia. 2881–2889
2020
-
[20]
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rock- täschel, et al. 2020. Retrieval-augmented generation for knowledge-intensive nlp tasks.Advances in neural information processing systems33 (2020), 9459–9474
2020
-
[21]
Shan Li and Weihong Deng. 2020. Deep facial expression recognition: A survey. IEEE transactions on affective computing13, 3 (2020), 1195–1215
2020
-
[22]
Steven R Livingstone and Frank A Russo. 2018. The Ryerson Audio-Visual Database of Emotional Speech and Song (RAVDESS): A dynamic, multimodal set of facial and vocal expressions in North American English.PloS one13, 5 (2018), e0196391
2018
-
[23]
Patrick Lucey, Jeffrey F Cohn, Takeo Kanade, Jason Saragih, Zara Ambadar, and Iain Matthews. 2010. The extended cohn-kanade dataset (ck+): A complete dataset for action unit and emotion-specified expression. In2010 ieee computer society conference on computer vision and pattern recognition-workshops. IEEE, 94–101
2010
-
[24]
Andreas Lugmayr, Martin Danelljan, Andres Romero, Fisher Yu, Radu Timofte, and Luc Van Gool. 2022. Repaint: Inpainting using denoising diffusion proba- bilistic models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 11461–11471
2022
-
[25]
Yue Ma, Hongyu Liu, Hongfa Wang, Heng Pan, Yingqing He, Junkun Yuan, Ailing Zeng, Chengfei Cai, Heung-Yeung Shum, Wei Liu, et al. 2024. Follow-your-emoji: Fine-controllable and expressive freestyle portrait animation. InSIGGRAPH Asia 2024 Conference Papers. 1–12
2024
-
[26]
Haomiao Ni, Bernhard Egger, Suhas Lohit, Anoop Cherian, Ye Wang, Toshiaki Koike-Akino, Sharon X Huang, and Tim K Marks. 2024. Ti2v-zero: Zero-shot image conditioning for text-to-video diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 9015–9025
2024
-
[27]
Rosalind W Picard and Jennifer Healey. 1997. Affective wearables.Personal technologies1, 4 (1997), 231–240
1997
-
[28]
Konpat Preechakul, Nattanat Chatthee, Suttisak Wizadwongsa, and Supasorn Suwajanakorn. 2022. Diffusion autoencoders: Toward a meaningful and decod- able representation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 10619–10629
2022
-
[29]
Albert Pumarola, Antonio Agudo, Aleix M Martinez, Alberto Sanfeliu, and Francesc Moreno-Noguer. 2018. Ganimation: Anatomically-aware facial anima- tion from a single image. InProceedings of the European conference on computer vision (ECCV). 818–833
2018
-
[30]
1998.Reinforcement learning: An introduction
Richard S Sutton, Andrew G Barto, et al . 1998.Reinforcement learning: An introduction. Vol. 1. MIT press Cambridge
1998
-
[31]
Zeng Tao, Yan Wang, Zhaoyu Chen, Boyang Wang, Shaoqi Yan, Kaixun Jiang, Shuyong Gao, and Wenqiang Zhang. 2023. Freq-hd: An interpretable frequency- based high-dynamics affective clip selection method for in-the-wild facial expres- sion recognition in videos. InProceedings of the 31st ACM International Conference on Multimedia. 843–852
2023
-
[32]
Changyao Tian, Wenhai Wang, Xizhou Zhu, Jifeng Dai, and Yu Qiao. 2022. Vl- ltr: Learning class-wise visual-linguistic representation for long-tailed visual recognition. InEuropean conference on computer vision. Springer, 73–91
2022
-
[33]
Ching-Ting Tu and Kuan-Lin Chen. 2023. Style-exprGAN: Diverse Smile Style Image Generation Via Attention-Guided Adversarial Networks.IEEE Transactions on Affective Computing15, 3 (2023), 1190–1201
2023
-
[34]
Zhengzhong Tu, Yilin Wang, Neil Birkbeck, Balu Adsumilli, and Alan C Bovik
-
[35]
UGC-VQA: Benchmarking blind video quality assessment for user gener- ated content.IEEE Transactions on Image Processing30 (2021), 4449–4464
2021
- [36]
-
[37]
Bram Wallace, Akash Gokul, Stefano Ermon, and Nikhil Naik. 2023. End-to-end diffusion latent optimization improves classifier guidance. InProceedings of the IEEE/CVF International Conference on Computer Vision. 7280–7290
2023
-
[38]
Hanyang Wang, Bo Li, Shuang Wu, Siyuan Shen, Feng Liu, Shouhong Ding, and Aimin Zhou. 2023. Rethinking the learning paradigm for dynamic facial expression recognition. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 17958–17968
2023
-
[39]
Haoran Wang, Xinji Mai, Zeng Tao, Xuan Tong, Junxiong Lin, Yan Wang, Jiawen Yu, Shaoqi Yan, Ziheng Zhou, and Wenqiang Zhang. 2025. D2SP: Dynamic Dual- Stage Purification Framework for Dual Noise Mitigation in Vision-based Affective Recognition.. InProceedings of the Computer Vision and Pattern Recognition Conference. 19218–19229
2025
-
[40]
Jiuniu Wang, Hangjie Yuan, Dayou Chen, Yingya Zhang, Xiang Wang, and Shiwei Zhang. 2023. Modelscope text-to-video technical report.arXiv preprint arXiv:2308.06571(2023)
work page internal anchor Pith review arXiv 2023
-
[41]
Yan Wang, Wei Song, Wei Tao, Antonio Liotta, Dawei Yang, Xinlei Li, Shuyong Gao, Yixuan Sun, Weifeng Ge, Wei Zhang, et al. 2022. A systematic review on af- fective computing: Emotion models, databases, and recent advances.Information Fusion83 (2022), 19–52
2022
-
[42]
Yan Wang, Yixuan Sun, Yiwen Huang, Zhongying Liu, Shuyong Gao, Wei Zhang, Weifeng Ge, and Wenqiang Zhang. 2022. Ferv39k: A large-scale multi-scene dataset for facial expression recognition in videos. InProceedings of the IEEE/CVF Huanzhen Wang, Ziheng Zhou, Jiaqi Song, Li He, Yunshi Lan, Yan Wang, and Wenqiang Zhang conference on computer vision and patte...
2022
- [43]
-
[44]
Xiaoshi Wu, Keqiang Sun, Feng Zhu, Rui Zhao, and Hongsheng Li. 2023. Human preference score: Better aligning text-to-image models with human preference. InProceedings of the IEEE/CVF International Conference on Computer Vision. 2096– 2105
2023
-
[45]
Bin Xia, Yulun Zhang, Shiyin Wang, Yitong Wang, Xinglong Wu, Yapeng Tian, Wenming Yang, and Luc Van Gool. 2023. Diffir: Efficient diffusion model for image restoration. InProceedings of the IEEE/CVF international conference on computer vision. 13095–13105
2023
-
[46]
Jinbo Xing, Menghan Xia, Yong Zhang, Haoxin Chen, Wangbo Yu, Hanyuan Liu, Gongye Liu, Xintao Wang, Ying Shan, and Tien-Tsin Wong. 2024. Dynami- crafter: Animating open-domain images with video diffusion priors. InEuropean Conference on Computer Vision. Springer, 399–417
2024
-
[47]
Ceyuan Yang, Zhe Wang, Xinge Zhu, Chen Huang, Jianping Shi, and Dahua Lin. 2018. Pose guided human video generation. InProceedings of the European conference on computer vision (ECCV). 201–216
2018
-
[48]
Hui Zhang, Zuxuan Wu, Zhen Xing, Jie Shao, and Yu-Gang Jiang. 2025. AdaDiff: Adaptive Step Selection for Fast Diffusion Models. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 39. 9914–9922
2025
- [49]
-
[50]
Qihao Zhao, Yalun Dai, Hao Li, Wei Hu, Fan Zhang, and Jun Liu. 2024. Ltgc: Long- tail recognition via leveraging llms-driven generated content. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 19510–19520
2024
-
[51]
Zengqun Zhao and Qingshan Liu. 2021. Former-dfer: Dynamic facial expression recognition transformer. InProceedings of the 29th ACM international conference on multimedia. 1553–1561
2021
-
[52]
Zengqun Zhao and Ioannis Patras. 2023. Prompting Visual-Language Models for Dynamic Facial Expression Recognition. InBMVC
2023
-
[53]
visual hallucinations
Yang Zhou, Xintong Han, Eli Shechtman, Jose Echevarria, Evangelos Kalogerakis, and Dingzeyu Li. 2020. Makelttalk: speaker-aware talking-head animation.ACM Transactions On Graphics (TOG)39, 6 (2020), 1–15. ARGen: Affect-Reinforced Generative Augmentation towards Vision-based Dynamic Emotion Perception Supplementary Materials for ARGen Overview The suppleme...
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.