Recognition: unknown
SubFlow: Sub-mode Conditioned Flow Matching for Diverse One-Step Generation
Pith reviewed 2026-05-10 15:04 UTC · model grok-4.3
The pith
SubFlow restores full mode coverage in one-step flow matching by conditioning on semantic sub-mode clusters to eliminate averaging distortion.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
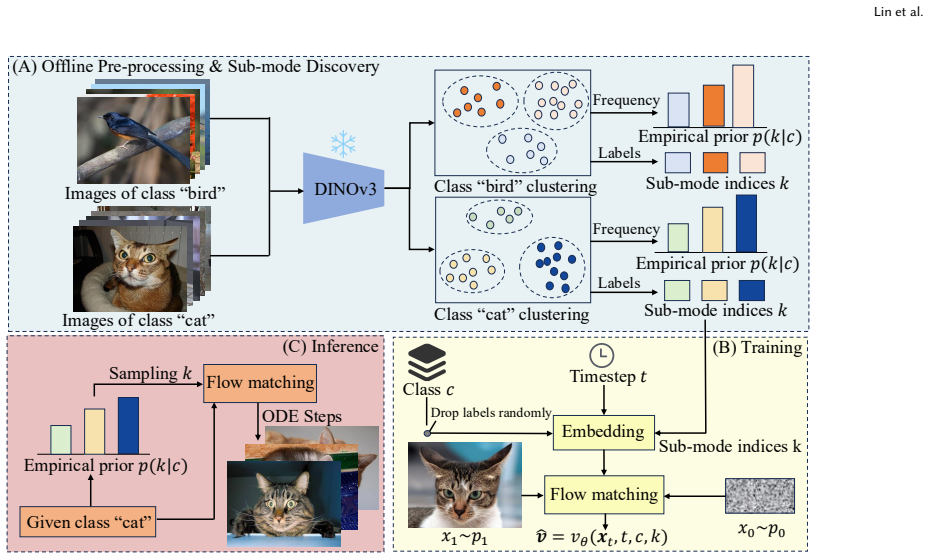
By decomposing each class into fine-grained sub-modes via semantic clustering and conditioning the flow on sub-mode indices, each conditioned sub-distribution becomes approximately unimodal; the learned flow can therefore target individual modes accurately with no averaging distortion, restoring full mode coverage in a single inference step.
What carries the argument
Sub-mode conditioned flow matching, in which semantic clustering supplies discrete sub-mode indices that are fed to the flow at training and generation time so each flow learns a narrow, unimodal target instead of a class-wide average.
If this is right
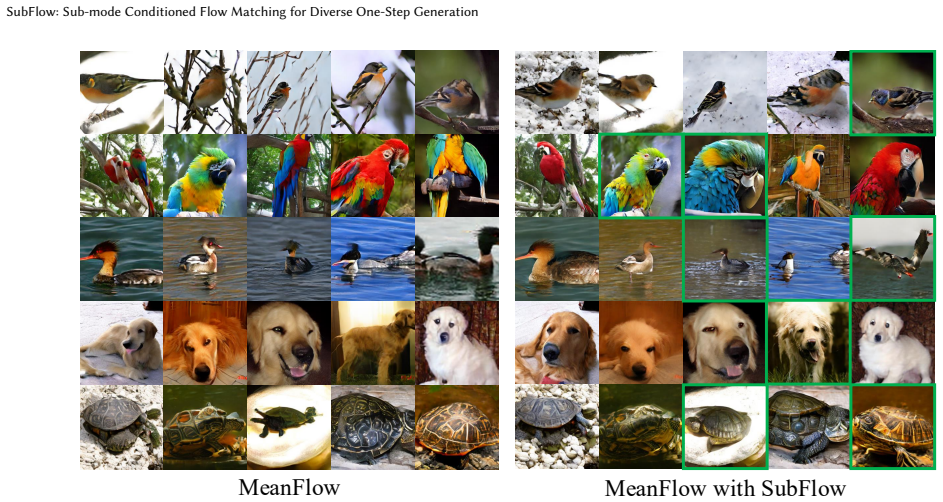
- Existing one-step models such as MeanFlow and Shortcut Models can be upgraded to full mode coverage without changing their networks or adding inference steps.
- Diversity degradation previously observed in few-step flow matching is explained by intra-class averaging and can be removed by explicit sub-mode conditioning.
- The same sub-mode indices used at training can be supplied at generation to steer output toward specific variations inside a class.
- Image quality measured by FID remains competitive while diversity measured by Recall improves substantially on large-scale datasets like ImageNet-256.
Where Pith is reading between the lines
- The sub-mode indices could be predicted from partial images or text prompts, turning the method into controllable generation without retraining.
- If the clustering step is replaced by an unsupervised latent-space partition learned jointly with the flow, the need for a separate clustering stage might disappear.
- The same conditioning trick may apply to diffusion models or other score-based frameworks that currently suffer from mode collapse in few-step regimes.
- Applications that need rare examples, such as medical-image augmentation or long-tail class balancing, could directly select low-density sub-modes at generation time.
Load-bearing premise
Semantic clustering must reliably split each class into approximately unimodal sub-distributions without creating artifacts, and the resulting sub-mode indices must be available at generation time without extra cost or error.
What would settle it
Generate the same number of ImageNet-256 samples with and without sub-mode conditioning and measure whether Recall increases while FID stays comparable; if Recall does not rise or rare modes remain absent, the claim fails.
Figures




read the original abstract
Flow matching has emerged as a powerful generative framework, with recent few-step methods achieving remarkable inference acceleration. However, we identify a critical yet overlooked limitation: these models suffer from severe diversity degradation, concentrating samples on dominant modes while neglecting rare but valid variations of the target distribution. We trace this degradation to averaging distortion: when trained with MSE objectives, class-conditional flows learn a frequency-weighted mean over intra-class sub-modes, causing the model to over-represent high-density modes while systematically neglecting low-density ones. To address this, we propose SubFlow, Sub-mode Conditioned Flow Matching, which eliminates averaging distortion by decomposing each class into fine-grained sub-modes via semantic clustering and conditioning the flow on sub-mode indices. Each conditioned sub-distribution is approximately unimodal, so the learned flow accurately targets individual modes with no averaging distortion, restoring full mode coverage in a single inference step. Crucially, SubFlow is entirely plug-and-play: it integrates seamlessly into existing one-step models such as MeanFlow and Shortcut Models without any architectural modifications. Extensive experiments on ImageNet-256 demonstrate that SubFlow yields substantial gains in generation diversity (Recall) while maintaining competitive image quality (FID), confirming its broad applicability across different one-step generation frameworks. Project page: https://yexionglin.github.io/subflow.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that one-step flow-matching models (e.g., MeanFlow, Shortcut Models) suffer from averaging distortion under MSE training on class-conditional distributions, causing them to collapse onto dominant intra-class modes and lose diversity. SubFlow decomposes each class into fine-grained sub-modes via semantic clustering on embeddings, then trains a flow conditioned on sub-mode indices so that each conditional is approximately unimodal; this is asserted to restore full mode coverage in a single step. The method is presented as plug-and-play with no architectural changes, and experiments on ImageNet-256 report improved Recall with competitive FID.
Significance. If the central mechanism holds, SubFlow would provide a lightweight, training-only intervention that measurably improves diversity in already-accelerated one-step generators without sacrificing speed or requiring new architectures. This would be relevant to the growing literature on few-step and one-step diffusion/flow models, where mode coverage remains a persistent weakness.
major comments (4)
- [§3] §3 (Method): The claim that semantic clustering produces 'approximately unimodal' sub-distributions is load-bearing for the entire argument yet lacks any quantitative validation (e.g., no intra-cluster variance, modality metrics, or t-SNE visualizations comparing original vs. sub-mode supports). Without this, the reduction from averaging distortion to per-sub-mode flows does not follow.
- [§3.3, §4.1] §3.3 and §4.1: The assertion of 'plug-and-play' integration 'without any architectural modifications' is inconsistent with the addition of a sub-mode conditioning channel; the conditioning interface of the base model (MeanFlow/Shortcut) must be altered to accept the extra index, and the paper does not specify how this is implemented without changing the network or training procedure.
- [§4] §4 (Experiments): Sub-mode indices must be supplied at inference time. The manuscript does not describe or ablate the mechanism (oracle labels, auxiliary classifier, or learned predictor) nor quantify any extra forward-pass cost, which directly contradicts the 'zero extra inference cost' implication and undermines the one-step diversity claim.
- [§4.2] §4.2 (Ablations): No ablation isolates the contribution of sub-mode conditioning versus the clustering itself or the choice of number of sub-modes; the reported Recall gains could arise from other factors (e.g., longer training or different conditioning strength), so the causal link to elimination of averaging distortion remains unproven.
minor comments (3)
- Notation for sub-mode indices and conditioning is introduced without a clear equation or diagram; a small schematic would clarify how the index is concatenated or embedded.
- [§3.1] The abstract and introduction repeatedly use 'semantic clustering' without specifying the embedding model or clustering algorithm (k-means, GMM, etc.); this detail belongs in §3.1.
- Figure captions for qualitative samples could explicitly state the number of sub-modes used per class and whether the shown images correspond to different sub-modes.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We address each major comment point by point below, providing clarifications and committing to revisions that strengthen the manuscript without altering its core claims.
read point-by-point responses
-
Referee: [§3] The claim that semantic clustering produces 'approximately unimodal' sub-distributions is load-bearing for the entire argument yet lacks any quantitative validation (e.g., no intra-cluster variance, modality metrics, or t-SNE visualizations comparing original vs. sub-mode supports). Without this, the reduction from averaging distortion to per-sub-mode flows does not follow.
Authors: We agree that explicit quantitative support for the approximate unimodality of sub-distributions would strengthen the argument. Semantic clustering is performed on embeddings from a pre-trained vision model that are known to organize data by semantic similarity, and the consistent Recall improvements across experiments provide indirect evidence. To directly address the concern, we have added t-SNE visualizations of class-level versus sub-mode supports and intra-cluster variance statistics to the revised Section 3, confirming lower variance within sub-modes. revision: yes
-
Referee: [§3.3, §4.1] The assertion of 'plug-and-play' integration 'without any architectural modifications' is inconsistent with the addition of a sub-mode conditioning channel; the conditioning interface of the base model (MeanFlow/Shortcut) must be altered to accept the extra index, and the paper does not specify how this is implemented without changing the network or training procedure.
Authors: The term 'plug-and-play' and 'no architectural modifications' refers specifically to the generative network backbone and loss function remaining unchanged. The sub-mode index is treated as an additional discrete conditioning variable and embedded in the same manner as the class label before being fed into the existing conditioning pathway (concatenation or cross-attention) already present in MeanFlow and Shortcut Models. No new layers, weights, or training procedure alterations are introduced. We have expanded the implementation details in the revised Section 3.3 to make this explicit. revision: yes
-
Referee: [§4] Sub-mode indices must be supplied at inference time. The manuscript does not describe or ablate the mechanism (oracle labels, auxiliary classifier, or learned predictor) nor quantify any extra forward-pass cost, which directly contradicts the 'zero extra inference cost' implication and undermines the one-step diversity claim.
Authors: Sub-mode indices are obtained at inference by sampling from the empirical per-class sub-mode distribution precomputed from the training set; this is a constant-time lookup with no network forward pass required. We have added a clear description of this procedure together with a complexity analysis in the revised Section 4, confirming that the one-step sampling cost remains identical to the baseline models. revision: yes
-
Referee: [§4.2] No ablation isolates the contribution of sub-mode conditioning versus the clustering itself or the choice of number of sub-modes; the reported Recall gains could arise from other factors (e.g., longer training or different conditioning strength), so the causal link to elimination of averaging distortion remains unproven.
Authors: We acknowledge the value of isolating the effect of sub-mode conditioning. We have performed and included new ablations in the revised Section 4.2 that (i) vary the number of sub-modes per class and (ii) compare full SubFlow against a clustering-only baseline that uses a single averaged label per sub-mode group. These results show that the explicit sub-mode conditioning is responsible for the observed diversity gains, while the number of sub-modes exhibits a clear optimum. revision: yes
Circularity Check
No circularity: method is an additive conditioning proposal validated empirically
full rationale
The paper's central claim—that conditioning flows on sub-mode indices from semantic clustering eliminates averaging distortion and restores mode coverage—does not reduce to any input by construction. No equations appear in the provided text that equate the output diversity metric to a fitted parameter or self-defined quantity. The decomposition into sub-modes is presented as an external preprocessing step whose unimodality is an assumption, not a definitional identity. Experiments on ImageNet-256 are cited as confirmation rather than a tautological restatement of the clustering procedure. No self-citation chains, uniqueness theorems, or ansatzes imported from prior author work are invoked to force the result. The derivation remains self-contained as a proposed architectural addition whose validity rests on external empirical benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Michael S Albergo and Eric Vanden-Eijnden. 2022. Building normalizing flows with stochastic interpolants.arXiv preprint arXiv:2209.15571(2022)
work page internal anchor Pith review arXiv 2022
-
[2]
Andrew Brock, Jeff Donahue, and Karen Simonyan. 2019. Large Scale GAN Training for High Fidelity Natural Image Synthesis. InInternational Conference on Learning Representations. https://openreview.net/forum?id=B1xsqj09Fm
2019
-
[3]
Ricardo JGB Campello, Davoud Moulavi, and Jörg Sander. 2013. Density-based clustering based on hierarchical density estimates. InPacific-Asia conference on knowledge discovery and data mining. Springer, 160–172
2013
-
[4]
Yang Cao, Bo Chen, Xiaoyu Li, Yingyu Liang, Zhizhou Sha, Zhenmei Shi, Zhao Song, and Mingda Wan. 2025. Force matching with relativistic constraints: A physics-inspired approach to stable and efficient generative modeling. InPro- ceedings of the 34th ACM International Conference on Information and Knowledge Management. 179–188
2025
- [5]
-
[6]
Ricky TQ Chen, Yulia Rubanova, Jesse Bettencourt, and David K Duvenaud. 2018. Neural ordinary differential equations.Advances in neural information processing systems31 (2018)
2018
-
[7]
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. 2009. Im- agenet: A large-scale hierarchical image database. In2009 IEEE conference on computer vision and pattern recognition. Ieee, 248–255
2009
-
[8]
Prafulla Dhariwal and Alexander Nichol. 2021. Diffusion models beat gans on image synthesis.Advances in neural information processing systems34 (2021), 8780–8794
2021
-
[9]
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas Müller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, et al. 2024. Scaling rectified flow transformers for high-resolution image synthesis. InForty- first international conference on machine learning
2024
-
[10]
Martin Ester, Hans-Peter Kriegel, Jörg Sander, Xiaowei Xu, et al. 1996. A density- based algorithm for discovering clusters in large spatial databases with noise. In kdd, Vol. 96. 226–231
1996
-
[11]
Kevin Frans, Danijar Hafner, Sergey Levine, and Pieter Abbeel. 2025. One Step Diffusion via Shortcut Models. InThe Thirteenth International Conference on Learning Representations. https://openreview.net/forum?id=OlzB6LnXcS
2025
- [12]
-
[13]
Zhengyang Geng, Mingyang Deng, Xingjian Bai, J Zico Kolter, and Kaiming He
-
[14]
InThe Thirty-ninth Annual Conference on Neural Information Processing Systems
Mean Flows for One-step Generative Modeling. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems. https://openreview.net/ forum?id=uWj4s7rMnR
- [15]
-
[16]
Ian J Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde- Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. 2014. Generative adversarial nets.Advances in neural information processing systems27 (2014)
2014
-
[17]
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. 2017. Gans trained by a two time-scale update rule converge to a local nash equilibrium.Advances in neural information processing systems30 (2017)
2017
-
[18]
Jonathan Ho, Ajay Jain, and Pieter Abbeel. 2020. Denoising diffusion probabilistic models.Advances in neural information processing systems33 (2020), 6840–6851
2020
-
[19]
Jonathan Ho and Tim Salimans. 2022. Classifier-free diffusion guidance.arXiv preprint arXiv:2207.12598(2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
- [20]
-
[21]
Minguk Kang, Jun-Yan Zhu, Richard Zhang, Jaesik Park, Eli Shechtman, Sylvain Paris, and Taesung Park. 2023. Scaling up gans for text-to-image synthesis. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 10124–10134
2023
-
[22]
Tero Karras, Miika Aittala, Timo Aila, and Samuli Laine. 2022. Elucidating the design space of diffusion-based generative models.Advances in neural information processing systems35 (2022), 26565–26577
2022
-
[23]
Dongjun Kim, Chieh-Hsin Lai, Wei-Hsiang Liao, Naoki Murata, Yuhta Takida, Toshimitsu Uesaka, Yutong He, Yuki Mitsufuji, and Stefano Ermon. 2024. Consis- tency Trajectory Models: Learning Probability Flow ODE Trajectory of Dif- fusion. InThe Twelfth International Conference on Learning Representations. https://openreview.net/forum?id=ymjI8feDTD
2024
-
[24]
Tuomas Kynkäänniemi, Miika Aittala, Tero Karras, Samuli Laine, Timo Aila, and Jaakko Lehtinen. 2024. Applying guidance in a limited interval improves sample and distribution quality in diffusion models.Advances in Neural Information Processing Systems37 (2024), 122458–122483
2024
-
[25]
Tuomas Kynkäänniemi, Tero Karras, Samuli Laine, Jaakko Lehtinen, and Timo Aila. 2019. Improved precision and recall metric for assessing generative models. Advances in neural information processing systems32 (2019)
2019
-
[26]
Shanchuan Lin, Ceyuan Yang, Zhijie Lin, Hao Chen, and Haoqi Fan. 2025. Ad- versarial Flow Models.arXiv preprint arXiv:2511.22475(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [27]
-
[28]
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le
-
[29]
Flow matching for generative modeling.arXiv preprint arXiv:2210.02747 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[30]
Xingchao Liu, Chengyue Gong, and Qiang Liu. 2022. Flow straight and fast: Learning to generate and transfer data with rectified flow.arXiv preprint arXiv:2209.03003(2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[31]
Xingchao Liu, Xiwen Zhang, Jianzhu Ma, Jian Peng, and qiang liu. 2024. In- staFlow: One Step is Enough for High-Quality Diffusion-Based Text-to-Image Generation. InThe Twelfth International Conference on Learning Representations. https://openreview.net/forum?id=1k4yZbbDqX
2024
-
[32]
Cheng Lu and Yang Song. 2025. Simplifying, Stabilizing and Scaling Continuous- time Consistency Models. InThe Thirteenth International Conference on Learning Representations. https://openreview.net/forum?id=LyJi5ugyJx
2025
-
[33]
Yiyang Lu, Susie Lu, Qiao Sun, Hanhong Zhao, Zhicheng Jiang, Xianbang Wang, Tianhong Li, Zhengyang Geng, and Kaiming He. 2026. One-step Latent-free Image Generation with Pixel Mean Flows.arXiv preprint arXiv:2601.22158(2026)
work page internal anchor Pith review arXiv 2026
-
[34]
Tianze Luo, Haotian Yuan, and Zhuang Liu. 2026. SoFlow: Solution Flow Models for One-Step Generative Modeling. InThe Fourteenth International Conference on Learning Representations. https://openreview.net/forum?id=cjb03GNqYw
2026
-
[35]
Weijian Luo, Tianyang Hu, Shifeng Zhang, Jiacheng Sun, Zhenguo Li, and Zhihua Zhang. 2023. Diff-instruct: A universal approach for transferring knowledge from pre-trained diffusion models.Advances in Neural Information Processing Systems36 (2023), 76525–76546
2023
-
[36]
Weijian Luo, Zemin Huang, Zhengyang Geng, J Zico Kolter, and Guo-jun Qi
-
[37]
One-step diffusion distillation through score implicit matching.Advances in Neural Information Processing Systems37 (2024), 115377–115408
2024
-
[38]
Nanye Ma, Mark Goldstein, Michael S Albergo, Nicholas M Boffi, Eric Vanden- Eijnden, and Saining Xie. 2024. Sit: Exploring flow and diffusion-based generative models with scalable interpolant transformers. InEuropean Conference on Com- puter Vision. Springer, 23–40
2024
-
[39]
Chenlin Meng, Robin Rombach, Ruiqi Gao, Diederik Kingma, Stefano Ermon, Jonathan Ho, and Tim Salimans. 2023. On distillation of guided diffusion mod- els. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 14297–14306
2023
- [40]
-
[41]
William Peebles and Saining Xie. 2023. Scalable diffusion models with transform- ers. InProceedings of the IEEE/CVF international conference on computer vision. 4195–4205
2023
- [42]
-
[43]
Delin Qu, Haoming Song, Qizhi Chen, Yuanqi Yao, Xinyi Ye, Yan Ding, Zhigang Wang, JiaYuan Gu, Bin Zhao, Dong Wang, et al . 2025. Spatialvla: Exploring spatial representations for visual-language-action model.Robotics: Science and Systems. Lin et al
2025
-
[44]
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. 2022. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 10684–10695
2022
-
[45]
Seyedmorteza Sadat, Jakob Buhmann, Derek Bradley, Otmar Hilliges, and Ro- mann M. Weber. 2024. CADS: Unleashing the Diversity of Diffusion Models through Condition-Annealed Sampling. InThe Twelfth International Conference on Learning Representations. https://openreview.net/forum?id=zMoNrajk2X
2024
-
[46]
Tim Salimans and Jonathan Ho. 2022. Progressive distillation for fast sampling of diffusion models.arXiv preprint arXiv:2202.00512(2022)
work page internal anchor Pith review arXiv 2022
-
[47]
Axel Sauer, Katja Schwarz, and Andreas Geiger. 2022. Stylegan-xl: Scaling stylegan to large diverse datasets. InACM SIGGRAPH 2022 conference proceedings. 1–10
2022
-
[48]
Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc Le, Geoffrey Hinton, and Jeff Dean. 2017. Outrageously large neural networks: The sparsely-gated mixture-of-experts layer.arXiv preprint arXiv:1701.06538(2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[49]
Oriane Siméoni, Huy V Vo, Maximilian Seitzer, Federico Baldassarre, Maxime Oquab, Cijo Jose, Vasil Khalidov, Marc Szafraniec, Seungeun Yi, Michaël Rama- monjisoa, et al. 2025. Dinov3.arXiv preprint arXiv:2508.10104(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [50]
-
[51]
Yang Song, Prafulla Dhariwal, Mark Chen, and Ilya Sutskever. 2023. Consistency models. (2023)
2023
-
[52]
Yang Song and Stefano Ermon. 2019. Generative modeling by estimating gradi- ents of the data distribution.Advances in neural information processing systems 32 (2019)
2019
-
[53]
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. 2020. Score-based generative modeling through stochastic differential equations.arXiv preprint arXiv:2011.13456(2020)
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[54]
Akash Srivastava, Lazar Valkov, Chris Russell, Michael U Gutmann, and Charles Sutton. 2017. Veegan: Reducing mode collapse in gans using implicit variational learning.Advances in neural information processing systems30 (2017)
2017
-
[55]
Maojiang Su, Jerry Yao-Chieh Hu, Yi-Chen Lee, Ning Zhu, Jui-Hui Chung, Shang Wu, Zhao Song, Minshuo Chen, and Han Liu. 2025. High-order flow match- ing: Unified framework and sharp statistical rates. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems
2025
-
[56]
Alexander Tong, Kilian Fatras, Nikolay Malkin, Guillaume Huguet, Yanlei Zhang, Jarrid Rector-Brooks, Guy Wolf, and Yoshua Bengio. 2023. Improving and gener- alizing flow-based generative models with minibatch optimal transport.arXiv preprint arXiv:2302.00482(2023)
work page internal anchor Pith review arXiv 2023
-
[57]
Aaron Van Den Oord, Oriol Vinyals, et al. 2017. Neural discrete representation learning.Advances in neural information processing systems30 (2017)
2017
- [58]
- [59]
- [60]
-
[61]
Jingfeng Yao, Bin Yang, and Xinggang Wang. 2025. Reconstruction vs. generation: Taming optimization dilemma in latent diffusion models. InProceedings of the Computer Vision and Pattern Recognition Conference. 15703–15712
2025
-
[62]
Tianwei Yin, Michaël Gharbi, Richard Zhang, Eli Shechtman, Fredo Durand, William T Freeman, and Taesung Park. 2024. One-step diffusion with distribution matching distillation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 6613–6623
2024
-
[63]
Sihyun Yu, Sangkyung Kwak, Huiwon Jang, Jongheon Jeong, Jonathan Huang, Jinwoo Shin, and Saining Xie. 2025. Representation Alignment for Generation: Training Diffusion Transformers Is Easier Than You Think. InThe Thirteenth International Conference on Learning Representations. https://openreview.net/ forum?id=DJSZGGZYVi
2025
- [64]
-
[65]
Yichi Zhang, Yici Yan, Alex Schwing, and Zhizhen Zhao. 2025. Towards Hier- archical Rectified Flow. InThe Thirteenth International Conference on Learning Representations. https://openreview.net/forum?id=6F6qwdycgJ
2025
-
[66]
Boyang Zheng, Nanye Ma, Shengbang Tong, and Saining Xie. 2026. Diffusion Transformers with Representation Autoencoders. InThe Fourteenth Interna- tional Conference on Learning Representations. https://openreview.net/forum? id=0u1LigJaab
2026
- [67]
-
[68]
Jiyang Zheng, Siqi Pan, Yu Yao, Zhaoqing Wang, Dadong Wang, and Tongliang Liu. 2025. Aligning What Matters: Masked Latent Adaptation for Text-to-Audio- Video Generation. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems. https://openreview.net/forum?id=I0hRN2HMeH
2025
-
[69]
Linqi Zhou, Stefano Ermon, and Jiaming Song. 2025. Inductive Moment Matching. InForty-second International Conference on Machine Learning. https://openreview. net/forum?id=pwNSUo7yUb
2025
-
[70]
Mingyuan Zhou, Huangjie Zheng, Zhendong Wang, Mingzhang Yin, and Hai Huang. 2024. Score identity distillation: Exponentially fast distillation of pre- trained diffusion models for one-step generation. InForty-first International Conference on Machine Learning
2024
-
[71]
Waslander, Hongsheng Li, and Yu Liu
Yang Zhou, Hao Shao, Letian Wang, Steven L. Waslander, Hongsheng Li, and Yu Liu. 2024. SmartRefine: A Scenario-Adaptive Refinement Framework for Efficient Motion Prediction. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 15281–15290
2024
-
[72]
Waslander
Yang Zhou, Hao Shao, Letian Wang, Zhuofan Zong, Hongsheng Li, and Steven L. Waslander. 2026. DrivingGen: A Comprehensive Benchmark for Generative Video World Models in Autonomous Driving. InThe Fourteenth International Conference on Learning Representations. https://openreview.net/forum?id= OrgL5DsU0f
2026
-
[73]
Yang Zhou, Xiaofeng Wang, Hao Shao, Letian Wang, Guosheng Zhao, Jiang- nan Shao, Jiagang Zhu, Tingdong Yu, Zheng Zhu, Guan Huang, and Steven L. Waslander. 2026. DriveDreamer-Policy: A Geometry-Grounded World-Action Model for Unified Generation and Planning. arXiv:2604.01765 [cs.CV] https: //arxiv.org/abs/2604.01765 SubFlow: Sub-mode Conditioned Flow Match...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.