Recognition: unknown
CoLA: A Choice Leakage Attack Framework to Expose Privacy Risks in Subset Training
Pith reviewed 2026-05-10 15:52 UTC · model grok-4.3
The pith
Subset training leaks private data choices through selection participation even when fewer samples are used.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
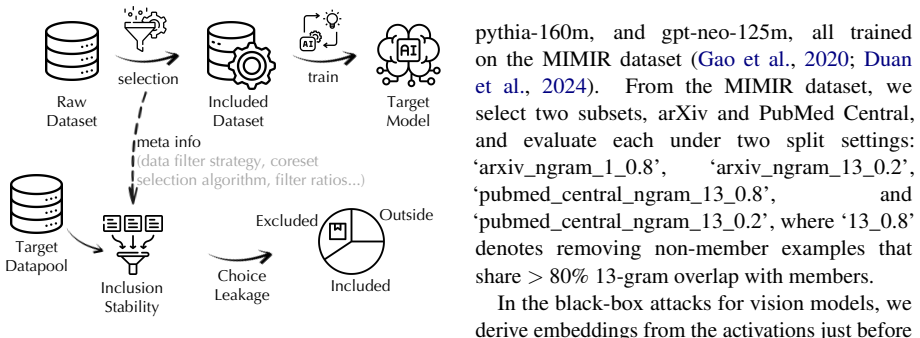
We introduce CoLA, a unified attack framework that defines two realistic adversary settings—subset-aware side-channel attacks and black-box attacks—and two distinct privacy surfaces: training-membership membership inference attacks (TM-MIA) that target only the final training set, and selection-participation membership inference attacks (SP-MIA) that target every sample that participated in the subset selection process. Experiments on vision and language models demonstrate that both surfaces are vulnerable, with selection participation leaking more broadly than training membership alone.
What carries the argument
CoLA framework that separates side-channel metadata attacks from black-box model-output attacks and distinguishes training-membership MIA from the broader selection-participation MIA that covers the full data-model supply chain.
If this is right
- Subset training expands privacy risks from the trained model to every candidate sample considered during data selection.
- Existing membership inference threat models underestimate risks because they ignore selection participation.
- Both side-channel metadata and black-box model outputs can be used to recover selection information.
- Privacy leakage appears in both vision and language model pipelines that rely on subset selection.
- Risks extend across the broader ML ecosystem rather than remaining isolated to individual training runs.
Where Pith is reading between the lines
- Data filtering pipelines used in large language models may require new selection algorithms that hide participation patterns.
- Provenance tracking in ML data pipelines could become a new attack vector if selection choices are logged or observable.
- Defenses focused only on model outputs may leave side-channel metadata leaks unaddressed.
- Subset selection methods could be redesigned to minimize distinguishability of included versus excluded samples.
Load-bearing premise
Practical adversaries can obtain enough side-channel information about the subset selection process or that model outputs alone suffice to distinguish selection participation at scale.
What would settle it
An experiment across multiple vision and language models in which no adversary achieves better than random accuracy at distinguishing selection participation using either side-channel metadata or model outputs on held-out data.
Figures





read the original abstract
Training models on a carefully chosen portion of data rather than the full dataset is now a standard preprocess for modern ML. From vision coreset selection to large-scale filtering in language models, it enables scalability with minimal utility loss. A common intuition is that training on fewer samples should also reduce privacy risks. In this paper, we challenge this assumption. We show that subset training is not privacy free: the very choices of which data are included or excluded can introduce new privacy surface and leak more sensitive information. Such information can be captured by adversaries either through side-channel metadata from the subset selection process or via the outputs of the target model. To systematically study this phenomenon, we propose CoLA (Choice Leakage Attack), a unified framework for analyzing privacy leakage in subset selection. In CoLA, depending on the adversary's knowledge of the side-channel information, we define two practical attack scenarios: Subset-aware Side-channel Attacks and Black-box Attacks. Under both scenarios, we investigate two privacy surfaces unique to subset training: (1) Training-membership MIA (TM-MIA), which concerns only the privacy of training data membership, and (2) Selection-participation MIA (SP-MIA), which concerns the privacy of all samples that participated in the subset selection process. Notably, SP-MIA enlarges the notion of membership from model training to the entire data-model supply chain. Experiments on vision and language models show that existing threat models underestimate subset-training privacy risks: the expanded privacy surface leaks both training and selection membership, extending risks from individual models to the broader ML ecosystem.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CoLA, a unified framework for analyzing privacy leakage from subset selection in ML training. It challenges the intuition that subset training reduces privacy risks and defines two attack scenarios (Subset-aware Side-channel Attacks and Black-box Attacks) along with two privacy surfaces: Training-membership MIA (TM-MIA) and the novel Selection-participation MIA (SP-MIA), which extends membership inference to the data selection process. The central claim is that adversaries can exploit side-channel metadata or target model outputs to infer both training membership and selection participation, with experiments on vision and language models asserted to show that existing threat models underestimate these risks.
Significance. If the empirical results hold, the work is significant for identifying an expanded privacy surface in common ML pipelines that rely on data subsetting (e.g., coresets, filtering). By formalizing SP-MIA and providing a framework that distinguishes side-channel vs. black-box access, it could influence privacy analysis beyond individual models to the broader data curation ecosystem. The empirical focus on both vision and language models is a strength, though the absence of reported metrics in the abstract limits immediate assessment of practical impact.
major comments (2)
- [Abstract] Abstract: the claim that 'experiments on vision and language models show that existing threat models underestimate subset-training privacy risks' is load-bearing for the central thesis, yet the abstract supplies no attack success rates, baselines, ablation results, or quantitative comparison between TM-MIA and SP-MIA. Without these, it is impossible to verify whether model outputs alone suffice to distinguish selection participation at scale rather than reducing to standard membership inference.
- [Abstract] The weakest assumption (that black-box adversaries can reliably infer SP-MIA from target model outputs without side-channel metadata) is not supported by any reported evidence in the provided abstract. The paper must include concrete success rates, ROC curves, or comparison tables showing that selection signals are distinguishable from ordinary membership signals; otherwise the enlargement of the privacy surface remains unproven.
minor comments (1)
- [Abstract] The abstract would be clearer if it briefly named the specific vision and language models/datasets used and the scale of the experiments (e.g., number of samples, subset sizes).
Simulated Author's Rebuttal
We thank the referee for their thoughtful and detailed comments. We agree that the abstract should be strengthened with concrete quantitative results to better support the central claims. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that 'experiments on vision and language models show that existing threat models underestimate subset-training privacy risks' is load-bearing for the central thesis, yet the abstract supplies no attack success rates, baselines, ablation results, or quantitative comparison between TM-MIA and SP-MIA. Without these, it is impossible to verify whether model outputs alone suffice to distinguish selection participation at scale rather than reducing to standard membership inference.
Authors: We appreciate this observation. The full manuscript (Sections 4 and 5) reports attack success rates, AUC values, ROC curves, and direct comparisons between TM-MIA and SP-MIA under both side-channel and black-box settings, including ablations across vision and language models. These results demonstrate that SP-MIA achieves non-trivial success beyond standard membership inference. To address the concern, we will revise the abstract to include representative quantitative metrics (e.g., AUC improvements and success rates) that summarize the key empirical findings. revision: yes
-
Referee: [Abstract] The weakest assumption (that black-box adversaries can reliably infer SP-MIA from target model outputs without side-channel metadata) is not supported by any reported evidence in the provided abstract. The paper must include concrete success rates, ROC curves, or comparison tables showing that selection signals are distinguishable from ordinary membership signals; otherwise the enlargement of the privacy surface remains unproven.
Authors: We agree that the abstract should explicitly substantiate this point. The manuscript provides evidence through black-box experiments showing that model outputs alone yield SP-MIA performance distinguishable from TM-MIA (e.g., via higher AUC and accuracy over random baselines, with tables comparing the two). We will update the abstract to report these concrete metrics and comparisons, clarifying that the enlargement of the privacy surface is supported by the empirical distinction between selection participation and training membership signals. revision: yes
Circularity Check
No circularity: empirical attack framework with no derivations or self-referential reductions
full rationale
The paper presents CoLA as an empirical attack study and framework for subset-training privacy risks, defining TM-MIA and SP-MIA surfaces plus two adversary scenarios (side-channel and black-box) without any equations, fitted parameters, predictions, or derivation chains. Claims rest on experimental results on vision/language models rather than reducing to inputs by construction, self-citations, or ansatzes. No load-bearing steps match the enumerated circularity patterns; the work is self-contained as an attack proposal evaluated externally.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Adversaries can obtain side-channel metadata from subset selection or query model outputs
Forward citations
Cited by 1 Pith paper
-
On-Policy Self-Evolution via Failure Trajectories for Agentic Safety Alignment
FATE lets LLM agents self-evolve safer behaviors by generating and filtering repairs from their own failure trajectories using verifiers and Pareto optimization.
Reference graph
Works this paper leans on
-
[1]
Do membership inference attacks work on large language models?arXiv preprint arXiv:2402.07841, 2024
Coresets for nonparametric estimation-the case of dp-means. InInternational Conference on Machine Learning, pages 209–217. PMLR. Stella Biderman, Hailey Schoelkopf, Quentin Gregory Anthony, Herbie Bradley, Kyle O’Brien, Eric Hal- lahan, Mohammad Aflah Khan, Shivanshu Purohit, USVSN Sai Prashanth, Edward Raff, Aviya Skowron, Lintang Sutawika, and Oskar van...
-
[2]
Scaling Language Models: Methods, Analysis & Insights from Training Gopher
Coresets for data-efficient training of machine learning models. InInternational Conference on Machine Learning, pages 6950–6960. PMLR. Alexander Munteanu, Chris Schwiegelshohn, Christian Sohler, and David Woodruff. 2018. On coresets for logistic regression.Advances in Neural Information Processing Systems, 31. Milad Nasr, Reza Shokri, and Amir Houmansadr...
work page internal anchor Pith review arXiv 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.