Recognition: unknown
Unlocking the Potential of Grounding DINO in Videos: Parameter-Efficient Adaptation for Limited-Data Spatial-Temporal Localization
Pith reviewed 2026-05-10 15:07 UTC · model grok-4.3
The pith
ST-GD adapts frozen Grounding DINO with lightweight adapters and a temporal decoder to perform spatio-temporal video grounding on limited data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ST-GD is a framework that adapts pre-trained 2D visual-language models such as Grounding DINO to spatio-temporal video grounding tasks. By keeping the base model frozen and strategically injecting lightweight adapters to instill spatio-temporal awareness, together with a novel temporal decoder for boundary prediction, the approach avoids destroying pre-trained priors on small datasets. As a result, ST-GD achieves highly competitive performance on the limited-scale HC-STVG v1/v2 benchmarks and maintains robust generalization on the VidSTG dataset.
What carries the argument
Lightweight adapters (~10M trainable parameters) and a novel temporal decoder injected into a frozen Grounding DINO model to add spatio-temporal awareness.
If this is right
- ST-GD achieves highly competitive performance on the limited-scale HC-STVG v1/v2 benchmarks.
- It maintains robust generalization on the VidSTG dataset.
- The design counters data scarcity by preserving pre-trained priors without full retraining.
- Only around 10 million parameters require training compared to fully-trained approaches.
Where Pith is reading between the lines
- This modular adaptation may extend to other pre-trained 2D models needing temporal capabilities in data-limited settings.
- It suggests that task-specific temporal components can be added without retraining entire vision-language backbones.
Load-bearing premise
That strategically injecting lightweight adapters and a novel temporal decoder into a frozen Grounding DINO will instill spatio-temporal awareness without destroying pre-trained priors on small datasets.
What would settle it
A direct comparison showing that ST-GD does not achieve competitive results on HC-STVG v1/v2 or loses performance on VidSTG compared to baselines would disprove the claim.
Figures


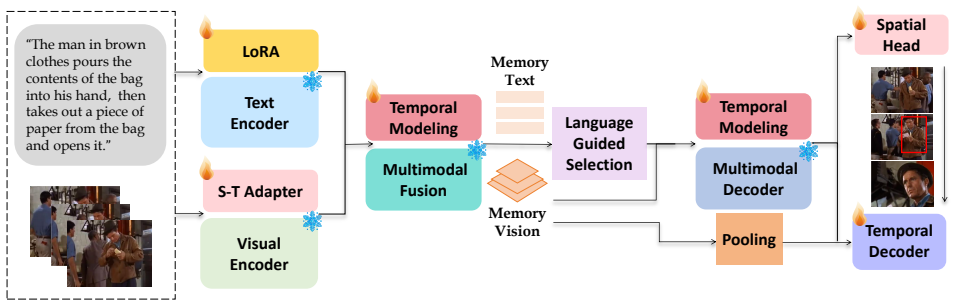



read the original abstract
Spatio-temporal video grounding (STVG) aims to localize queried objects within dynamic video segments. Prevailing fully-trained approaches are notoriously data-hungry. However, gathering large-scale STVG data is exceptionally challenging: dense frame-level bounding boxes and complex temporal language alignments are prohibitively expensive to annotate, especially for specialized video domains. Consequently, conventional models suffer from severe overfitting on these inherently limited datasets, while zero-shot foundational models lack the task-specific temporal awareness needed for precise localization. To resolve this small-data challenge, we introduce ST-GD, a data-efficient framework that adapts pre-trained 2D visual-language models (e.g., Grounding DINO) to video tasks. To avoid destroying pre-trained priors on small datasets, ST-GD keeps the base model frozen and strategically injects lightweight adapters (~10M trainable parameters) to instill spatio-temporal awareness, alongside a novel temporal decoder for boundary prediction. This design naturally counters data scarcity. Consequently, ST-GD excels in data-scarce scenarios, achieving highly competitive performance on the limited-scale HC-STVG v1/v2 benchmarks, while maintaining robust generalization on the VidSTG dataset. This validates ST-GD as a powerful paradigm for complex video understanding under strict small-data constraints.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces ST-GD, a data-efficient framework for spatio-temporal video grounding that adapts the pre-trained Grounding DINO model by keeping it frozen and adding lightweight adapters (approximately 10 million trainable parameters) and a novel temporal decoder. This design is intended to instill spatio-temporal awareness without overwriting pre-trained priors, addressing the challenge of limited annotated data in STVG tasks. The paper claims that ST-GD achieves highly competitive performance on the small-scale HC-STVG v1 and v2 benchmarks while showing robust generalization on the VidSTG dataset.
Significance. If the empirical claims are substantiated, this work would be significant as it offers a practical, parameter-efficient method for transferring 2D vision-language foundation models to video-based localization tasks under data constraints. It follows the established paradigm of PEFT to mitigate overfitting on small datasets, which is relevant for specialized video domains where large-scale annotations are costly. The approach could facilitate broader adoption of foundation models in video understanding.
major comments (1)
- [Abstract] The central claim that ST-GD 'excels in data-scarce scenarios, achieving highly competitive performance on the limited-scale HC-STVG v1/v2 benchmarks' is not accompanied by any quantitative results, baseline comparisons, ablation studies, or details on the evaluation protocol. Without these, it is not possible to verify the effectiveness of the proposed adapters and temporal decoder or to assess the soundness of the generalization claims.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of the work's significance and for the detailed feedback. We respond to the major comment point by point below.
read point-by-point responses
-
Referee: [Abstract] The central claim that ST-GD 'excels in data-scarce scenarios, achieving highly competitive performance on the limited-scale HC-STVG v1/v2 benchmarks' is not accompanied by any quantitative results, baseline comparisons, ablation studies, or details on the evaluation protocol. Without these, it is not possible to verify the effectiveness of the proposed adapters and temporal decoder or to assess the soundness of the generalization claims.
Authors: The abstract serves as a concise summary of the paper's main contributions and results. The quantitative results on the HC-STVG v1 and v2 benchmarks, along with baseline comparisons, ablation studies on the proposed adapters and temporal decoder, and the evaluation protocol, are all detailed in the full manuscript's experimental sections. This allows readers to verify the effectiveness and the generalization claims to VidSTG. We agree that including some key numbers in the abstract could strengthen it and will revise the abstract accordingly to include representative performance figures. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper introduces ST-GD as an empirical architectural adaptation of a frozen Grounding DINO model via lightweight adapters and a temporal decoder for spatio-temporal video grounding. No mathematical derivation chain, parameter fitting presented as prediction, or self-referential definitions appear in the abstract or described design. The central claims rest on standard PEFT patterns evaluated directly on HC-STVG v1/v2 and VidSTG benchmarks, with no load-bearing steps that reduce by construction to inputs or prior self-citations. This is a self-contained empirical proposal without circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
E3m: zero-shot spatio-temporal video ground- ing with expectation-maximization multimodal modulation
Peijun Bao, Zihao Shao, Wenhan Yang, Boon Poh Ng, and Alex C Kot. E3m: zero-shot spatio-temporal video ground- ing with expectation-maximization multimodal modulation. InEuropean Conference on Computer Vision, pages 227–
-
[2]
2, 3, 6, 7
Springer, 2024. 2, 3, 6, 7
2024
-
[3]
Locvtp: Video-text pre-training for temporal localization
Meng Cao, Tianyu Yang, Junwu Weng, Can Zhang, Jue Wang, and Yuexian Zou. Locvtp: Video-text pre-training for temporal localization. InEuropean Conference on Computer Vision, pages 38–56. Springer, 2022. 2
2022
-
[4]
Seeclick: Har- nessing gui grounding for advanced visual gui agents
Kanzhi Cheng, Qiushi Sun, Yougang Chu, Fangzhi Xu, Li YanTao, Jianbing Zhang, and Zhiyong Wu. Seeclick: Har- nessing gui grounding for advanced visual gui agents. In Proceedings of the 62nd Annual Meeting of the Associa- tion for Computational Linguistics (Volume 1: Long Papers), pages 9313–9332, 2024. 3
2024
-
[5]
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. BERT: pre-training of deep bidirectional trans- formers for language understanding.CoRR, abs/1810.04805,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Stpro: Spatial and temporal progressive learning for weakly su- pervised spatio-temporal grounding
Aaryan Garg, Akash Kumar, and Yogesh S Rawat. Stpro: Spatial and temporal progressive learning for weakly su- pervised spatio-temporal grounding. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 3384–3394, 2025. 7
2025
-
[7]
GroundingDINO, 2024. 6
2024
-
[8]
Context-guided spatio-temporal video grounding
Xin Gu, Heng Fan, Yan Huang, Tiejian Luo, and Libo Zhang. Context-guided spatio-temporal video grounding. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18330–18339, 2024. 1, 3, 6, 7
2024
-
[9]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InProceed- ings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016. 4
2016
-
[10]
Parameter-efficient transfer learning for nlp, 2019
Neil Houlsby, Andrei Giurgiu, Stanislaw Jastrzebski, Bruna Morrone, Quentin de Laroussilhe, Andrea Gesmundo, Mona Attariyan, and Sylvain Gelly. Parameter-efficient transfer learning for nlp, 2019. 3
2019
-
[11]
Lora: Low-rank adaptation of large language models.ICLR, 1(2):3, 2022
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen- Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models.ICLR, 1(2):3, 2022. 3, 4
2022
-
[12]
Planning-oriented autonomous driving
Yihan Hu, Jiazhi Yang, Li Chen, Keyu Li, Chonghao Sima, Xizhou Zhu, Siqi Chai, Senyao Du, Tianwei Lin, Wenhai Wang, et al. Planning-oriented autonomous driving. InPro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 17853–17862, 2023. 1
2023
-
[13]
Embracing con- sistency: A one-stage approach for spatio-temporal video grounding.Advances in Neural Information Processing Sys- tems, 35:29192–29204, 2022
Yang Jin, Zehuan Yuan, Yadong Mu, et al. Embracing con- sistency: A one-stage approach for spatio-temporal video grounding.Advances in Neural Information Processing Sys- tems, 35:29192–29204, 2022. 1, 3, 6, 7
2022
-
[14]
Video-llava: Learning united visual repre- sentation by alignment before projection
Bin Lin, Yang Ye, Bin Zhu, Jiaxi Cui, Munan Ning, Peng Jin, and Li Yuan. Video-llava: Learning united visual repre- sentation by alignment before projection. InProceedings of the 2024 Conference on Empirical Methods in Natural Lan- guage Processing, pages 5971–5984, 2024. 2
2024
-
[15]
Collaborative static and dynamic vision- language streams for spatio-temporal video grounding
Zihang Lin, Chaolei Tan, Jian-Fang Hu, Zhi Jin, Tiancai Ye, and Wei-Shi Zheng. Collaborative static and dynamic vision- language streams for spatio-temporal video grounding. In Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition, pages 23100–23109, 2023. 7
2023
-
[16]
Grounding dino: Marrying dino with grounded pre-training for open-set object detection
Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Qing Jiang, Chunyuan Li, Jianwei Yang, Hang Su, et al. Grounding dino: Marrying dino with grounded pre-training for open-set object detection. In European Conference on Computer Vision, pages 38–55. Springer, 2024. 2, 3
2024
-
[17]
Continual learning for vlms: A survey and taxonomy beyond forgetting, 2025
Yuyang Liu, Qiuhe Hong, Linlan Huang, Alexandra Gomez- Villa, Dipam Goswami, Xialei Liu, Joost van de Weijer, and Yonghong Tian. Continual learning for vlms: A survey and taxonomy beyond forgetting, 2025. 2, 3
2025
-
[18]
Swin transformer: Hierarchical vision transformer using shifted windows
Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF international conference on computer vision, pages 10012–10022, 2021. 3, 6
2021
-
[19]
An empirical study of catastrophic forgetting in large language models during continual fine-tuning.IEEE Transactions on Audio, Speech and Language Processing,
Yun Luo, Zhen Yang, Fandong Meng, Yafu Li, Jie Zhou, and Yue Zhang. An empirical study of catastrophic forgetting in large language models during continual fine-tuning.IEEE Transactions on Audio, Speech and Language Processing,
-
[20]
St-adapter: Parameter-efficient image-to-video transfer learning.Advances in Neural Information Process- ing Systems, 35:26462–26477, 2022
Junting Pan, Ziyi Lin, Xiatian Zhu, Jing Shao, and Hong- sheng Li. St-adapter: Parameter-efficient image-to-video transfer learning.Advances in Neural Information Process- ing Systems, 35:26462–26477, 2022. 3, 4
2022
-
[21]
Dragdiffusion: Harnessing diffusion models for interactive point-based image editing
Yujun Shi, Chuhui Xue, Jun Hao Liew, Jiachun Pan, Han- shu Yan, Wenqing Zhang, Vincent YF Tan, and Song Bai. Dragdiffusion: Harnessing diffusion models for interactive point-based image editing. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8839–8849, 2024. 1
2024
-
[22]
Stvgbert: A visual- linguistic transformer based framework for spatio-temporal video grounding
Rui Su, Qian Yu, and Dong Xu. Stvgbert: A visual- linguistic transformer based framework for spatio-temporal video grounding. InProceedings of the IEEE/CVF Inter- national Conference on Computer Vision, pages 1533–1542,
-
[23]
Chaolei Tan, Zihang Lin, Jian-Fang Hu, Xiang Li, and Wei-Shi Zheng. Augmented 2d-tan: A two-stage approach for human-centric spatio-temporal video grounding.arXiv preprint arXiv:2106.10634, 2021. 1
-
[24]
Human-centric spatio-temporal video grounding with visual transformers
Zongheng Tang, Yue Liao, Si Liu, Guanbin Li, Xiaojie Jin, Hongxu Jiang, Qian Yu, and Dong Xu. Human-centric spatio-temporal video grounding with visual transformers. IEEE Transactions on Circuits and Systems for Video Tech- nology, 32(12):8238–8249, 2021. 2, 6
2021
-
[25]
Lave: Llm-powered agent assistance and lan- 9 guage augmentation for video editing
Bryan Wang, Yuliang Li, Zhaoyang Lv, Haijun Xia, Yan Xu, and Raj Sodhi. Lave: Llm-powered agent assistance and lan- 9 guage augmentation for video editing. InProceedings of the 29th International Conference on Intelligent User Interfaces, pages 699–714, 2024. 1
2024
-
[26]
Learning spatiotemporal and motion features in a unified 2d network for action recognition.IEEE Transac- tions on Pattern Analysis and Machine Intelligence, 45(3): 3347–3362, 2022
Mengmeng Wang, Jiazheng Xing, Jing Su, Jun Chen, and Yong Liu. Learning spatiotemporal and motion features in a unified 2d network for action recognition.IEEE Transac- tions on Pattern Analysis and Machine Intelligence, 45(3): 3347–3362, 2022. 2
2022
-
[27]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, et al. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191, 2024. 2, 3, 6
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
Videogrounding- dino: Towards open-vocabulary spatio-temporal video grounding
Syed Talal Wasim, Muzammal Naseer, Salman Khan, Ming- Hsuan Yang, and Fahad Shahbaz Khan. Videogrounding- dino: Towards open-vocabulary spatio-temporal video grounding. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18909– 18918, 2024. 2, 3, 4, 6, 7
2024
-
[29]
Realvg: Unleashing mllms for training-free spatio-temporal video grounding in the wild
Hongchen Wei and Zhenzhong Chen. Realvg: Unleashing mllms for training-free spatio-temporal video grounding in the wild. InProceedings of the 33rd ACM International Con- ference on Multimedia, pages 4271–4280, 2025. 6, 7
2025
-
[30]
Longvlm: Efficient long video understand- ing via large language models
Yuetian Weng, Mingfei Han, Haoyu He, Xiaojun Chang, and Bohan Zhuang. Longvlm: Efficient long video understand- ing via large language models. InEuropean Conference on Computer Vision, pages 453–470. Springer, 2024. 2
2024
-
[31]
Tubedetr: Spatio-temporal video ground- ing with transformers
Antoine Yang, Antoine Miech, Josef Sivic, Ivan Laptev, and Cordelia Schmid. Tubedetr: Spatio-temporal video ground- ing with transformers. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 16442–16453, 2022. 1, 2, 6, 7
2022
-
[32]
Ferret-ui: Grounded mobile ui understanding with mul- timodal llms
Keen You, Haotian Zhang, Eldon Schoop, Floris Weers, Amanda Swearngin, Jeffrey Nichols, Yinfei Yang, and Zhe Gan. Ferret-ui: Grounded mobile ui understanding with mul- timodal llms. InEuropean Conference on Computer Vision, pages 240–255. Springer, 2024. 3
2024
-
[33]
A survey of autonomous driving: Common practices and emerging technologies.IEEE access, 8:58443– 58469, 2020
Ekim Yurtsever, Jacob Lambert, Alexander Carballo, and Kazuya Takeda. A survey of autonomous driving: Common practices and emerging technologies.IEEE access, 8:58443– 58469, 2020. 1
2020
-
[34]
Where does it exist: Spatio-temporal video grounding for multi-form sentences
Zhu Zhang, Zhou Zhao, Yang Zhao, Qi Wang, Huasheng Liu, and Lianli Gao. Where does it exist: Spatio-temporal video grounding for multi-form sentences. InProceedings of the IEEE/CVF Conference on Computer Vision and Pat- tern Recognition, pages 10668–10677, 2020. 1, 2, 6
2020
-
[35]
Video-text prompting for weakly super- vised spatio-temporal video grounding
Heng Zhao, Zhao Yinjie, Bihan Wen, Yew-Soon Ong, and Joey Tianyi Zhou. Video-text prompting for weakly super- vised spatio-temporal video grounding. InProceedings of the 2024 Conference on Empirical Methods in Natural Lan- guage Processing, pages 19494–19505, 2024. 7
2024
-
[36]
Deformable DETR: Deformable Transformers for End-to-End Object Detection
Xizhou Zhu, Weijie Su, Lewei Lu, Bin Li, Xiaogang Wang, and Jifeng Dai. Deformable detr: Deformable trans- formers for end-to-end object detection.arXiv preprint arXiv:2010.04159, 2020. 6 10
work page internal anchor Pith review arXiv 2010
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.