Recognition: 2 theorem links
· Lean TheoremChain-of-Models Pre-Training: Rethinking Training Acceleration of Vision Foundation Models
Pith reviewed 2026-05-10 16:12 UTC · model grok-4.3
The pith
Pre-training vision foundation model families from smallest to largest reuses knowledge to match or exceed individual training performance at far lower total cost.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
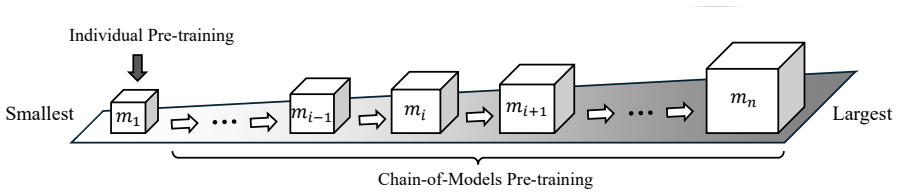
CoM-PT sets up an ascending-size model chain in which only the smallest model undergoes standard pre-training while the others are trained via sequential inverse knowledge transfer that reuses knowledge from smaller predecessors in both parameter and feature spaces, yielding mostly superior performance at substantially lower training cost and higher efficiency as the number of models in the family increases.
What carries the argument
The ascending model chain that performs sequential inverse knowledge transfer by jointly reusing knowledge from smaller predecessors in parameter space and feature space.
If this is right
- All models in the chain mostly outperform models trained individually on zero-shot and fine-tuning tasks across 45 datasets.
- Computational cost drops sharply; for example, prepending smaller models up to ViT-L reduces complexity by as much as 72 percent.
- Acceleration ratios rise with family size, moving from 4.13X for three models to 7.09X for seven models.
- The method applies regardless of the specific pre-training paradigm.
Where Pith is reading between the lines
- The same ascending-chain pattern could be tested on language-model families to measure whether efficiency gains scale similarly.
- Model development practices might shift toward designing compatible size families rather than isolated large models to capture cumulative savings.
- The transfer mechanism might combine with other acceleration methods for still larger gains in compute-intensive regimes.
Load-bearing premise
That knowledge transferred from smaller to larger models can be reused in a way that keeps or improves performance without adding overhead that cancels the overall savings.
What would settle it
A controlled run on a new model family in which the total compute for the CoM-PT chain exceeds the sum of individual trainings or in which downstream accuracy falls below the individually trained baselines.
Figures






read the original abstract
In this paper, we present Chain-of-Models Pre-Training (CoM-PT), a novel performance-lossless training acceleration method for vision foundation models (VFMs). This approach fundamentally differs from existing acceleration methods in its core motivation: rather than optimizing each model individually, CoM-PT is designed to accelerate the training pipeline at the model family level, scaling efficiently as the model family expands. Specifically, CoM-PT establishes a pre-training sequence for the model family, arranged in ascending order of model size, called model chain. In this chain, only the smallest model undergoes standard individual pre-training, while the other models are efficiently trained through sequential inverse knowledge transfer from their smaller predecessors by jointly reusing the knowledge in the parameter space and the feature space. As a result, CoM-PT enables all models to achieve performance that is mostly superior to standard individual training while significantly reducing training cost, and this is extensively validated across 45 datasets spanning zero-shot and fine-tuning tasks. Notably, its efficient scaling property yields a remarkable phenomenon: training more models even results in higher efficiency. For instance, when pre-training on CC3M: i) given ViT-L as the largest model, progressively prepending smaller models to the model chain reduces computational complexity by up to 72%; ii) within a fixed model size range, as the VFM family scales across 3, 4, and 7 models, the acceleration ratio of CoM-PT exhibits a striking leap: from 4.13X to 5.68X and 7.09X. Since CoM-PT is naturally agnostic to specific pre-training paradigms, we open-source the code to spur further extensions in more computationally intensive scenarios, such as large language model pre-training.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Chain-of-Models Pre-Training (CoM-PT), a training acceleration method for vision foundation models that arranges models into an ascending-size chain. Only the smallest model receives standard individual pre-training; all larger models are trained via sequential inverse knowledge transfer that jointly reuses knowledge from predecessors in both parameter space and feature space. The central claims are that this yields performance that is mostly superior (or at least non-inferior) to independent training, delivers substantial compute savings (e.g., up to 72% reduction for ViT-L on CC3M), and exhibits an efficient scaling property in which adding more models to the family increases the acceleration ratio (4.13X to 7.09X). These results are reported across 45 datasets covering zero-shot and fine-tuning tasks, and the method is presented as agnostic to specific pre-training paradigms.
Significance. If the empirical results hold, the work is significant because it shifts the optimization target from individual models to entire model families and demonstrates that sequential inverse transfer can preserve or improve performance while reducing total compute. The counter-intuitive scaling observation—that larger families become more efficient—is noteworthy and, if reproducible, could influence how vision foundation model suites are trained. Credit is due for the extensive validation on 45 datasets and for open-sourcing the code, both of which support reproducibility and extension to other domains such as language-model pre-training.
major comments (2)
- [§4.3] §4.3 and Table 4: the claim that performance is 'mostly superior' across all 45 datasets requires a clearer breakdown (number of datasets showing statistically significant gains, parity, or degradation) and per-model-size results; without this granularity the 'mostly' qualifier remains difficult to evaluate against the central performance claim.
- [§3.2] §3.2, Eq. (3)–(5): the joint parameter- and feature-space transfer mechanism is load-bearing for both the performance and efficiency claims; the manuscript should explicitly report the additional FLOPs or memory cost of the feature-space reuse step itself so that readers can verify that the reported net savings (e.g., 72%) are not offset by transfer overhead.
minor comments (3)
- The abstract states 'performance-lossless' while the body uses 'mostly superior'; harmonize the terminology and define the precise acceptance criterion for 'superior'.
- [Figure 3] Figure 3 (scaling curves) and the associated text would benefit from error bars or multiple random seeds to substantiate the efficiency-leap claim when the family grows from 3 to 7 models.
- The open-sourced code link is appreciated; please ensure the released repository includes the exact hyper-parameters and data splits used for the 45-dataset evaluation.
Simulated Author's Rebuttal
We thank the referee for the constructive review and the recommendation for minor revision. The comments identify opportunities to strengthen the clarity of our performance claims and the transparency of our efficiency analysis. We address each point below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [§4.3] §4.3 and Table 4: the claim that performance is 'mostly superior' across all 45 datasets requires a clearer breakdown (number of datasets showing statistically significant gains, parity, or degradation) and per-model-size results; without this granularity the 'mostly' qualifier remains difficult to evaluate against the central performance claim.
Authors: We agree that a granular breakdown is necessary to substantiate the 'mostly superior' claim. In the revised manuscript we will augment §4.3 with a new table (or expanded Table 4) that reports, for each model size in the chain: (i) the number of datasets showing statistically significant gains (using paired t-tests at p<0.05), (ii) the number showing parity within a small tolerance, and (iii) any cases of degradation. We will also include per-model-size average metrics across the 45 datasets to allow direct comparison of improvement magnitude at each scale. revision: yes
-
Referee: [§3.2] §3.2, Eq. (3)–(5): the joint parameter- and feature-space transfer mechanism is load-bearing for both the performance and efficiency claims; the manuscript should explicitly report the additional FLOPs or memory cost of the feature-space reuse step itself so that readers can verify that the reported net savings (e.g., 72%) are not offset by transfer overhead.
Authors: We appreciate this request for explicit accounting. The feature-space reuse component in Eq. (3)–(5) adds a modest overhead from the additional feature extraction and alignment computations during each transfer step. In the revision we will insert a dedicated paragraph in §3.2 that quantifies the extra FLOPs and peak memory for this step across the model sizes used in our experiments. We will then recompute and report the net training-cost reduction (including this overhead) for the CC3M ViT-L case and the scaling experiments, confirming that the headline savings figures remain valid after subtraction. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper introduces CoM-PT as a new pre-training method that chains models by size and reuses knowledge from smaller to larger ones via parameter and feature space transfer. The central claims rest on empirical results across 45 datasets and scaling experiments rather than any self-referential definition, fitted input renamed as prediction, or load-bearing self-citation. No equations are presented that reduce the claimed acceleration or performance gains to the method's own inputs by construction, and the approach is described as agnostic to specific paradigms with open-sourced code for independent verification.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearCoM-PT establishes a pre-training sequence for the model family, arranged in ascending order of model size, called model chain... sequential inverse knowledge transfer from their smaller predecessors by jointly reusing the knowledge in the parameter space and the feature space
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearInverse Weight Initialization... Depth Duplication And Width Insertion... Inverse Feature Distillation L_IFD(F^t, F^s)=α||F^t−T(F^s)||²₂
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023. 13
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xi- aodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, et al. Qwen technical report.arXiv preprint arXiv:2309.16609,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Coco- stuff: Thing and stuff classes in context
Holger Caesar, Jasper Uijlings, and Vittorio Ferrari. Coco- stuff: Thing and stuff classes in context. InCVPR, 2018. 7, 12
2018
-
[4]
Conceptual 12M: Pushing web-scale image-text pre- training to recognize long-tail visual concepts
Soravit Changpinyo, Piyush Sharma, Nan Ding, and Radu Soricut. Conceptual 12M: Pushing web-scale image-text pre- training to recognize long-tail visual concepts. InCVPR,
-
[5]
bert2bert: Towards reusable pretrained language models
Cheng Chen, Yichun Yin, Lifeng Shang, Xin Jiang, Yujia Qin, Fengyu Wang, Zhi Wang, Xiao Chen, Zhiyuan Liu, and Qun Liu. bert2bert: Towards reusable pretrained language models. InACL, 2022. 3
2022
-
[6]
Cross-layer distillation with semantic calibration
Defang Chen, Jian-Ping Mei, Yuan Zhang, Can Wang, Zhe Wang, Yan Feng, and Chun Chen. Cross-layer distillation with semantic calibration. InAAAI, 2021. 3
2021
-
[7]
ShareGPT4V: Improving Large Multi-Modal Models with Better Captions
Lin Chen, Jisong Li, Xiaoyi Dong, Pan Zhang, Conghui He, Jiaqi Wang, Feng Zhao, and Dahua Lin. Sharegpt4v: Im- proving large multi-modal models with better captions.arXiv preprint arXiv:2311.12793, 2023. 5
work page internal anchor Pith review arXiv 2023
-
[8]
Distilling knowledge via knowledge review
Pengguang Chen, Shu Liu, Hengshuang Zhao, and Jiaya Jia. Distilling knowledge via knowledge review. InCVPR, 2021. 3
2021
-
[9]
Net2net: Accelerating learning via knowl- edge transfer
Tianqi Chen, Ian Goodfellow, and Jonathon Shlens. Net2net: Accelerating learning via knowledge transfer.arXiv preprint arXiv:1511.05641, 2015. 3, 15
-
[10]
Improved feature distillation via projec- tor ensemble
Yudong Chen, Sen Wang, Jiajun Liu, Xuwei Xu, Frank de Hoog, and Zi Huang. Improved feature distillation via projec- tor ensemble. InNeurIPS, 2022. 3
2022
-
[11]
Lemon: Reviving stronger and smaller lms from larger lms with linear parameter fusion
Yilong Chen, Junyuan Shang, Zhenyu Zhang, Shiyao Cui, Tingwen Liu, Shuohuan Wang, Yu Sun, and Hua Wu. Lemon: Reviving stronger and smaller lms from larger lms with linear parameter fusion. InACL, 2024. 3
2024
-
[12]
Clip benchmark, 2025
Mehdi Cherti and Romain Beaumont. Clip benchmark, 2025. 12
2025
-
[13]
Reproducible scal- ing laws for contrastive language-image learning
Mehdi Cherti, Romain Beaumont, Ross Wightman, Mitchell Wortsman, Gabriel Ilharco, Cade Gordon, Christoph Schuh- mann, Ludwig Schmidt, and Jenia Jitsev. Reproducible scal- ing laws for contrastive language-image learning. InCVPR,
-
[14]
Imagenet: A large-scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. InCVPR, 2009. 1, 5, 12
2009
-
[15]
Distpro: Searching a fast knowledge distillation process via meta optimization
Xueqing Deng, Dawei Sun, Shawn Newsam, and Peng Wang. Distpro: Searching a fast knowledge distillation process via meta optimization. InECCV, 2022. 3
2022
-
[16]
Network expansion for practical training acceleration
Ning Ding, Yehui Tang, Kai Han, Chao Xu, and Yunhe Wang. Network expansion for practical training acceleration. In CVPR, 2023. 3, 15
2023
-
[17]
An image is worth 16x16 words: Transformers for image recognition at scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, G Heigold, S Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale. InICLR, 2020. 1, 5
2020
-
[18]
The pascal visual object classes challenge 2012 (voc2012) development kit.PASMCL,
Mark Everingham and John Winn. The pascal visual object classes challenge 2012 (voc2012) development kit.PASMCL,
2012
-
[19]
Improving clip training with language rewrites
Lijie Fan, Dilip Krishnan, Phillip Isola, Dina Katabi, and Yon- glong Tian. Improving clip training with language rewrites
-
[20]
Pyramidclip: Hierarchical feature alignment for vision-language model pretraining
Yuting Gao, Jinfeng Liu, Zihan Xu, Jun Zhang, Ke Li, Ron- grong Ji, and Chunhua Shen. Pyramidclip: Hierarchical feature alignment for vision-language model pretraining. In NeurIPS, 2022. 3
2022
-
[21]
Efficient training of bert by progressively stacking
Linyuan Gong, Di He, Zhuohan Li, Tao Qin, Liwei Wang, and Tieyan Liu. Efficient training of bert by progressively stacking. InICML, 2019. 3
2019
-
[22]
Making the v in vqa matter: Elevating the role of image understanding in visual question answering
Yash Goyal, Tejas Khot, Douglas Summers-Stay, Dhruv Ba- tra, and Devi Parikh. Making the v in vqa matter: Elevating the role of image understanding in visual question answering. InCVPR, 2017. 5, 13
2017
-
[23]
Online knowledge distilla- tion via collaborative learning
Qiushan Guo, Xinjiang Wang, Yichao Wu, Zhipeng Yu, Ding Liang, Xiaolin Hu, and Ping Luo. Online knowledge distilla- tion via collaborative learning. InCVPR, 2020. 3
2020
-
[24]
A comprehensive overhaul of feature distillation
Byeongho Heo, Jeesoo Kim, Sangdoo Yun, Hyojin Park, Nojun Kwak, and Jin Young Choi. A comprehensive overhaul of feature distillation. InICCV, 2019. 3
2019
-
[25]
Distilling the Knowledge in a Neural Network
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distill- ing the knowledge in a neural network.arXiv preprint arXiv:1503.02531, 2015. 3
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[26]
Lora: Low-rank adaptation of large language models
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models. InICLR,
-
[27]
Masked distillation with receptive tokens
Tao Huang, Yuan Zhang, Shan You, Fei Wang, Chen Qian, Jian Cao, and Chang Xu. Masked distillation with receptive tokens. InICLR, 2023. 3
2023
-
[28]
Accelerating pre-training of multimodal llms via chain-of-sight
Ziyuan Huang, Kaixiang Ji, Biao Gong, Zhiwu Qing, Qing- long Zhang, Kecheng Zheng, Jian Wang, Jingdong Chen, and Ming Yang. Accelerating pre-training of multimodal llms via chain-of-sight. 2024. 1, 3
2024
-
[29]
Juwels booster–a supercomputer for large-scale ai research
Stefan Kesselheim, Andreas Herten, Kai Krajsek, Jan Ebert, Jenia Jitsev, Mehdi Cherti, Michael Langguth, Bing Gong, Scarlet Stadtler, Amirpasha Mozaffari, et al. Juwels booster–a supercomputer for large-scale ai research. InICHPC, 2021. 1, 3
2021
-
[30]
Dahyun Kim, Chanjun Park, Sanghoon Kim, Wonsung Lee, Wonho Song, Yunsu Kim, Hyeonwoo Kim, Yungi Kim, Hyeonju Lee, Jihoo Kim, et al. Solar 10.7 b: Scaling large language models with simple yet effective depth up-scaling. arXiv preprint arXiv:2312.15166, 2023. 3
-
[31]
Cosmos: Cross-modality self-distillation for vision language pre-training
Sanghwan Kim, Rui Xiao, Mariana-Iuliana Georgescu, Stephan Alaniz, and Zeynep Akata. Cosmos: Cross-modality self-distillation for vision language pre-training. InCVPR,
-
[32]
Otter: A multi-modal model with in-context instruction tuning.PAMI, 2025
Bo Li, Yuanhan Zhang, Liangyu Chen, Jinghao Wang, Fanyi Pu, Joshua Adrian Cahyono, Jingkang Yang, Chunyuan Li, and Ziwei Liu. Otter: A multi-modal model with in-context instruction tuning.PAMI, 2025. 5
2025
-
[33]
Blip- 2: Bootstrapping language-image pre-training with frozen image encoders and large language models
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip- 2: Bootstrapping language-image pre-training with frozen image encoders and large language models. InICML, 2023. 12
2023
-
[34]
Pytorch distributed: experiences on accelerating data parallel training
Shen Li, Yanli Zhao, Rohan Varma, Omkar Salpekar, Pieter Noordhuis, Teng Li, Adam Paszke, Jeff Smith, Brian Vaughan, Pritam Damania, et al. Pytorch distributed: experiences on accelerating data parallel training. InVLDB Endowment,
-
[35]
Supervi- sion exists everywhere: A data efficient contrastive language- image pre-training paradigm
Yangguang Li, Feng Liang, Lichen Zhao, Yufeng Cui, Wanli Ouyang, Jing Shao, Fengwei Yu, and Junjie Yan. Supervi- sion exists everywhere: A data efficient contrastive language- image pre-training paradigm. InICLR, 2022. 1, 3, 5
2022
-
[36]
Evaluating Object Hallucination in Large Vision-Language Models
Yifan Li, Yifan Du, Kun Zhou, Jinpeng Wang, Wayne Xin Zhao, and Ji-Rong Wen. Evaluating object hallucina- tion in large vision-language models.arXiv preprint arXiv:2305.10355, 2023. 5, 13
work page internal anchor Pith review arXiv 2023
-
[37]
Scaling language-image pre-training via masking
Yanghao Li, Haoqi Fan, Ronghang Hu, Christoph Feichten- hofer, and Kaiming He. Scaling language-image pre-training via masking. InCVPR, 2023. 1, 3
2023
-
[38]
Microsoft coco: Common objects in context
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick. Microsoft coco: Common objects in context. In ECCV, 2014. 5, 12
2014
-
[39]
Ye Lin, Yanyang Li, Ziyang Wang, Bei Li, Quan Du, Tong Xiao, and Jingbo Zhu. Weight distillation: Transferring the knowledge in neural network parameters.arXiv preprint arXiv:2009.09152, 2020. 3
-
[40]
Visual instruction tuning
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning. InNeurIPS, 2023. 13
2023
-
[41]
Improved baselines with visual instruction tuning
Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. Improved baselines with visual instruction tuning. InCVPR,
-
[42]
Norm: Knowledge distillation via n-to-one representation matching
Xiaolong Liu, LUKING LI, Chao Li, and Anbang Yao. Norm: Knowledge distillation via n-to-one representation matching. InICLR, 2023. 3
2023
-
[43]
Mllms- augmented visual-language representation learning.arXiv preprint arXiv:2311.18765, 2023
Yanqing Liu, Kai Wang, Wenqi Shao, Ping Luo, Yu Qiao, Mike Zheng Shou, Kaipeng Zhang, and Yang You. Mllms- augmented visual-language representation learning.arXiv preprint arXiv:2311.18765, 2023. 3, 5, 12
-
[44]
Swin transformer: Hierarchical vision transformer using shifted windows
Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo. Swin transformer: Hierarchical vision transformer using shifted windows. In ICCV, 2021. 5
2021
-
[45]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017. 15
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[46]
Learn to explain: Multimodal reasoning via thought chains for science question answering
Pan Lu, Swaroop Mishra, Tanglin Xia, Liang Qiu, Kai-Wei Chang, Song-Chun Zhu, Oyvind Tafjord, Peter Clark, and Ashwin Kalyan. Learn to explain: Multimodal reasoning via thought chains for science question answering. InNeurIPS,
-
[47]
Mixed precision training
Paulius Micikevicius, Sharan Narang, Jonah Alben, Gregory Diamos, Erich Elsen, David Garcia, Boris Ginsburg, Michael Houston, Oleksii Kuchaiev, Ganesh Venkatesh, et al. Mixed precision training. InICLR, 2018. 1, 3
2018
-
[48]
The role of context for object detection and semantic segmentation in the wild
Roozbeh Mottaghi, Xianjie Chen, Xiaobai Liu, Nam-Gyu Cho, Seong-Whan Lee, Sanja Fidler, Raquel Urtasun, and Alan Yuille. The role of context for object detection and semantic segmentation in the wild. InCVPR, 2014. 5, 12
2014
-
[49]
Slip: Self-supervision meets language-image pre- training
Norman Mu, Alexander Kirillov, David Wagner, and Sain- ing Xie. Slip: Self-supervision meets language-image pre- training. InECCV, 2022. 3
2022
-
[50]
Im2text: Describing images using 1 million captioned photographs
Vicente Ordonez, Girish Kulkarni, and Tamara Berg. Im2text: Describing images using 1 million captioned photographs. In NIPS, 2011. 12
2011
-
[51]
Budgeted training for vision transformer
Xuran Pan, Xuan Jin, Yuan He, Shiji Song, Gao Huang, et al. Budgeted training for vision transformer. InICLR, 2022. 3
2022
-
[52]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InICML, 2021. 1, 3, 5
2021
-
[53]
Zero: Memory optimizations toward training trillion parameter models
Samyam Rajbhandari, Jeff Rasley, Olatunji Ruwase, and Yux- iong He. Zero: Memory optimizations toward training trillion parameter models. InSC20, 2020. 3
2020
-
[54]
Deepspeed: System optimizations enable training deep learning models with over 100 billion parameters
Jeff Rasley, Samyam Rajbhandari, Olatunji Ruwase, and Yux- iong He. Deepspeed: System optimizations enable training deep learning models with over 100 billion parameters. In SIGKDD, 2020. 1, 3
2020
-
[55]
Fitnets: Hints for thin deep nets
Adriana Romero, Nicolas Ballas, Samira Ebrahimi Kahou, Antoine Chassang, Carlo Gatta, and Yoshua Bengio. Fitnets: Hints for thin deep nets. InICLR, 2015. 3
2015
-
[56]
DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter
Victor Sanh, Lysandre Debut, Julien Chaumond, and Thomas Wolf. Distilbert, a distilled version of bert: smaller, faster, cheaper and lighter.arXiv preprint arXiv:1910.01108, 2019. 3
work page internal anchor Pith review arXiv 1910
-
[57]
Laion- 400m: Open dataset of clip-filtered 400 million image-text pairs
Christoph Schuhmann, Robert Kaczmarczyk, Aran Komat- suzaki, Aarush Katta, Richard Vencu, Romain Beaumont, Jenia Jitsev, Theo Coombes, and Clayton Mullis. Laion- 400m: Open dataset of clip-filtered 400 million image-text pairs. InNeurIPSW, 2021. 5, 12
2021
-
[58]
Laion-5b: An open large-scale dataset for training next gener- ation image-text models
Christoph Schuhmann, Romain Beaumont, Richard Vencu, Cade Gordon, Ross Wightman, Mehdi Cherti, Theo Coombes, Aarush Katta, Clayton Mullis, Mitchell Wortsman, et al. Laion-5b: An open large-scale dataset for training next gener- ation image-text models. InNeurIPS, 2022. 1, 5, 12
2022
-
[59]
Conceptual captions: A cleaned, hypernymed, image alt-text dataset for automatic image captioning
Piyush Sharma, Nan Ding, Sebastian Goodman, and Radu Soricut. Conceptual captions: A cleaned, hypernymed, image alt-text dataset for automatic image captioning. InACL, 2018. 1, 4, 12
2018
-
[60]
Pre-trained summa- rization distillation.arXiv preprint arXiv:2010.13002, 2020
Sam Shleifer and Alexander M Rush. Pre-trained summa- rization distillation.arXiv preprint arXiv:2010.13002, 2020. 3
-
[61]
Towards vqa models that can read
Amanpreet Singh, Vivek Natarajan, Meet Shah, Yu Jiang, Xinlei Chen, Dhruv Batra, Devi Parikh, and Marcus Rohrbach. Towards vqa models that can read. InCVPR, 2019. 5, 13
2019
-
[62]
EVA-CLIP: Improved Training Techniques for CLIP at Scale
Quan Sun, Yuxin Fang, Ledell Wu, Xinlong Wang, and Yue Cao. Eva-clip: Improved training techniques for clip at scale. arXiv preprint arXiv:2303.15389, 2023. 3 10
work page internal anchor Pith review arXiv 2023
-
[63]
EVA-CLIP- 18B: Scaling clip to 18 billion parameters.arXiv:2402.04252, 2024
Quan Sun, Jinsheng Wang, Qiying Yu, Yufeng Cui, Fan Zhang, Xiaosong Zhang, and Xinlong Wang. Eva-clip- 18b: Scaling clip to 18 billion parameters.arXiv preprint arXiv:2402.04252, 2024. 3
-
[64]
LLaMA: Open and Efficient Foundation Language Models
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Mar- tinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Roz- ière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models.arXiv preprint arXiv:2302.13971, 2023. 5
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[65]
Mimetic initialization of self-attention layers
Asher Trockman and J Zico Kolter. Mimetic initialization of self-attention layers. InICML, 2023. 3
2023
-
[66]
Efficienttrain: Exploring gener- alized curriculum learning for training visual backbones
Yulin Wang, Yang Yue, Rui Lu, Tianjiao Liu, Zhao Zhong, Shiji Song, and Gao Huang. Efficienttrain: Exploring gener- alized curriculum learning for training visual backbones. In ICCV, 2023. 3
2023
-
[67]
arXiv preprint arXiv:2407.01445 , year=
Xiyuan Wei, Fanjiang Ye, Ori Yonay, Xingyu Chen, Baixi Sun, Dingwen Tao, and Tianbao Yang. Fastclip: A suite of optimization techniques to accelerate clip training with limited resources.arXiv preprint arXiv:2407.01445, 2024. 1
-
[68]
Lotlip: Improving language-image pre-training for long text understanding
Wei Wu, Kecheng Zheng, Shuailei Ma, Fan Lu, Yuxin Guo, Yifei Zhang, Wei Chen, Qingpei Guo, Yujun Shen, and Zheng- Jun Zha. Lotlip: Improving language-image pre-training for long text understanding. InNeurIPS, 2024. 3, 5
2024
-
[69]
Initializ- ing variable-sized vision transformers from learngene with learnable transformation
Shiyu Xia, Yuankun Zu, Xu Yang, and Xin Geng. Initializ- ing variable-sized vision transformers from learngene with learnable transformation. InNeurIPS, 2024. 3
2024
-
[70]
San: side adapter network for open-vocabulary semantic segmentation.TPAMI, 2023
Mengde Xu, Zheng Zhang, Fangyun Wei, Han Hu, and Xiang Bai. San: side adapter network for open-vocabulary semantic segmentation.TPAMI, 2023. 5, 7, 13
2023
-
[71]
Initializing models with larger ones
Zhiqiu Xu, Yanjie Chen, Kirill Vishniakov, Yida Yin, Zhiqiang Shen, Trevor Darrell, Lingjie Liu, and Zhuang Liu. Initializing models with larger ones. InICLR, 2024. 3
2024
-
[72]
Alip: Adaptive language-image pre-training with synthetic caption
Kaicheng Yang, Jiankang Deng, Xiang An, Jiawei Li, Ziyong Feng, Jia Guo, Jing Yang, and Tongliang Liu. Alip: Adaptive language-image pre-training with synthetic caption. InICCV,
-
[73]
Masked generative distillation
Zhendong Yang, Zhe Li, Mingqi Shao, Dachuan Shi, Zehuan Yuan, and Chun Yuan. Masked generative distillation. In ECCV, 2022. 3
2022
-
[74]
Filip: Fine-grained interactive language-image pre-training
Lewei Yao, Runhui Huang, Lu Hou, Guansong Lu, Minzhe Niu, Hang Xu, Xiaodan Liang, Zhenguo Li, Xin Jiang, and Chunjing Xu. Filip: Fine-grained interactive language-image pre-training. InICLR, 2022. 3
2022
-
[75]
A gift from knowledge distillation: Fast optimization, network minimization and transfer learning
Junho Yim, Donggyu Joo, Jihoon Bae, and Junmo Kim. A gift from knowledge distillation: Fast optimization, network minimization and transfer learning. InCVPR, 2017. 3
2017
-
[76]
Udon: Universal dynamic online distil- lation for generic image representations
Nikolaos-Antonios Ypsilantis, Kaifeng Chen, André Araujo, and Ondrej Chum. Udon: Universal dynamic online distil- lation for generic image representations. InNeurIPS, 2024. 3
2024
-
[77]
Scaling vision transformers
Xiaohua Zhai, Alexander Kolesnikov, Neil Houlsby, and Lu- cas Beyer. Scaling vision transformers. InCVPR, 2022. 8
2022
-
[78]
Sigmoid loss for language image pre-training
Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, and Lucas Beyer. Sigmoid loss for language image pre-training. InCVPR, 2023. 1
2023
-
[79]
Deep mutual learning
Ying Zhang, Tao Xiang, Timothy M Hospedales, and Huchuan Lu. Deep mutual learning. InCVPR, 2018. 3
2018
-
[80]
Dreamlip: Language- image pre-training with long captions
Kecheng Zheng, Yifei Zhang, Wei Wu, Fan Lu, Shuailei Ma, Xin Jin, Wei Chen, and Yujun Shen. Dreamlip: Language- image pre-training with long captions. InECCV, 2024. 1, 3, 4, 5, 12
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.