Recognition: unknown
Lit2Vec: A Reproducible Workflow for Building a Legally Screened Chemistry Corpus from S2ORC for Downstream Retrieval and Text Mining
Pith reviewed 2026-05-10 14:10 UTC · model grok-4.3
The pith
The Lit2Vec workflow builds a reproducible, legally screened corpus of 582k chemistry articles from S2ORC.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By applying conservative license screening based on metadata from Unpaywall, OpenAlex, and Crossref, the workflow constructs an internal study corpus of 582,683 chemistry-specific full-text articles equipped with structured text, token-aware chunks, paragraph embeddings, abstracts, licensing data, machine-generated summaries, and multi-label annotations for 18 chemistry subfields, all validated for reproducibility and technical compliance.
What carries the argument
The Lit2Vec workflow, which chains metadata-driven license screening, text structuring into paragraph chunks, embedding generation, and multi-label annotation while emitting a schema and validation outputs.
If this is right
- The released code and provenance artifacts allow any researcher to reconstruct the identical corpus from current public sources.
- Enriched records with embeddings and 18-domain annotations directly support retrieval systems and multi-label text classification.
- Validation steps confirm embedding reproducibility and metadata completeness for downstream applications.
- Only the workflow and metadata are shared, keeping source text and broad representations out of public redistribution.
Where Pith is reading between the lines
- The same screening logic could be reused to build compliant corpora in other scientific domains by swapping the field filter.
- Releasing validation outputs instead of raw text offers a template for sharing large derived scientific resources while respecting licenses.
- Widespread adoption might reduce the legal friction of using full-text scientific literature for training retrieval and language models.
Load-bearing premise
Metadata from Unpaywall, OpenAlex, and Crossref supplies an accurate enough signal to conservatively identify articles whose licenses permit inclusion in a full-text corpus.
What would settle it
Re-executing the released pipeline on the same pinned upstream datasets and obtaining a corpus whose size, composition, or included articles differ from the reported 582,683 records, or identifying any included article whose license metadata prohibits the intended use.
Figures





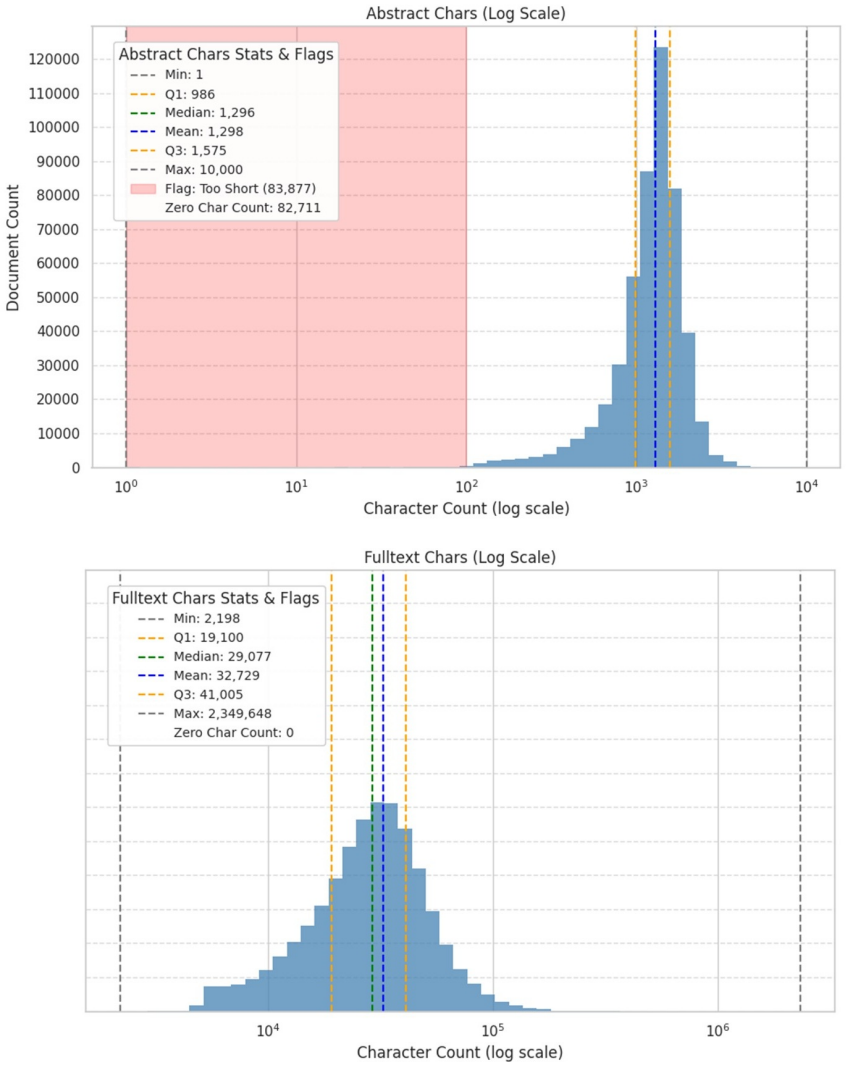







read the original abstract
We present Lit2Vec, a reproducible workflow for constructing and validating a chemistry corpus from the Semantic Scholar Open Research Corpus using conservative, metadata-based license screening. Using this workflow, we assembled an internal study corpus of 582,683 chemistry-specific full-text research articles with structured full text, token-aware paragraph chunks, paragraph-level embeddings generated with the intfloat/e5-large-v2 model, and record-level metadata including abstracts and licensing information. To support downstream retrieval and text-mining use cases, an eligible subset of the corpus was additionally enriched with machine-generated brief summaries and multi-label subfield annotations spanning 18 chemistry domains. Licensing was screened using metadata from Unpaywall, OpenAlex, and Crossref, and the resulting corpus was technically validated for schema compliance, embedding reproducibility, text quality, and metadata completeness. The primary contribution of this work is a reproducible workflow for corpus construction and validation, together with its associated schema and reproducibility resources. The released materials include the code, reconstruction workflow, schema, metadata/provenance artifacts, and validation outputs needed to reproduce the corpus from pinned public upstream resources. Public redistribution of source-derived text and broad text-derived representations is outside the scope of the general release. Researchers can reproduce the workflow by using the released pipeline with publicly available upstream datasets and metadata services.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents Lit2Vec, a reproducible workflow for constructing a chemistry corpus of 582,683 full-text articles from S2ORC. It applies conservative metadata-based license screening via Unpaywall, OpenAlex, and Crossref; generates structured full text, token-aware paragraph chunks, and paragraph-level embeddings with intfloat/e5-large-v2; and enriches an eligible subset with machine-generated summaries and 18-domain subfield annotations. Technical validation covers schema compliance, embedding reproducibility, text quality, and metadata completeness. The primary contribution is the workflow itself together with released code, schema, provenance artifacts, and validation outputs that enable reconstruction from pinned public upstream resources.
Significance. If the workflow holds, the contribution is a practical, reproducible resource for chemistry retrieval and text mining that prioritizes legal compliance. The explicit release of code, schema, and reconstruction artifacts is a clear strength that supports independent verification and extension, consistent with best practices in data-intensive database research.
major comments (1)
- [Validation section] Validation section: the technical validation is stated to cover schema compliance, embedding reproducibility, text quality, and metadata completeness, yet contains no reported error rate, manual audit, or comparison against actual article licenses or publisher terms for the Unpaywall/OpenAlex/Crossref metadata screening step. Because the central claim is a 'legally screened' corpus, the absence of any accuracy assessment for this load-bearing step leaves the 'conservative' characterization unverified.
minor comments (1)
- [Abstract] The abstract and methods could clarify the exact size of the 'eligible subset' that receives summaries and annotations relative to the full 582,683-article corpus.
Simulated Author's Rebuttal
We thank the referee for the careful review and for highlighting the importance of verifying the license screening process. We address the major comment below and will revise the manuscript to improve clarity on this point.
read point-by-point responses
-
Referee: [Validation section] Validation section: the technical validation is stated to cover schema compliance, embedding reproducibility, text quality, and metadata completeness, yet contains no reported error rate, manual audit, or comparison against actual article licenses or publisher terms for the Unpaywall/OpenAlex/Crossref metadata screening step. Because the central claim is a 'legally screened' corpus, the absence of any accuracy assessment for this load-bearing step leaves the 'conservative' characterization unverified.
Authors: We agree that the validation section does not include a quantitative error rate, manual audit, or direct comparison to publisher terms for the metadata-based license screening. Such an assessment is not feasible at the scale of 582,683 articles because ground-truth license information from publishers is not publicly available in bulk and would require individual negotiations or access that exceeds the scope of this work. The screening is conservative by construction: an article is retained only when Unpaywall, OpenAlex, and Crossref metadata are all consistent in indicating a permissive license (e.g., CC-BY or equivalent) and any conflicting or missing signals result in exclusion. We will revise the manuscript to add an explicit limitations subsection in the validation or methods section that (1) states this design choice and its rationale, (2) references known properties of these metadata services, and (3) clarifies that the reproducibility artifacts allow independent users to apply stricter or alternative filters if desired. This revision will make the conservative characterization more transparent without overstating what can be empirically verified. revision: yes
Circularity Check
No significant circularity; procedural workflow with external dependencies
full rationale
The paper describes a reproducible workflow for corpus construction from S2ORC using conservative metadata-based license screening via independent external services (Unpaywall, OpenAlex, Crossref). The primary contribution is the pipeline, schema, code, and validation outputs for technical compliance, embedding reproducibility, and metadata completeness. No derivations, equations, fitted parameters presented as predictions, or self-citation chains exist. All load-bearing steps rely on pinned public upstream resources and released code rather than reducing to internal definitions or prior author results by construction. The work is self-contained as a procedural artifact.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Metadata from Unpaywall, OpenAlex, and Crossref accurately reflects licensing status for screening purposes
Reference graph
Works this paper leans on
-
[1]
Openalex, 2025
OurResearch. Openalex, 2025. URL https://openalex.org/. Accessed: 2025-06-04
2025
-
[2]
Unpaywall, 2025
OurResearch. Unpaywall, 2025. URL https://unpaywall.org/. Accessed: 2025-06-04
2025
-
[3]
Crossref, 2025
Crossref. Crossref, 2025. URL https://www.crossref.org/. Accessed: 2025-06-04
2025
-
[4]
Text Embeddings by Weakly-Supervised Contrastive Pre-training
Liang Wang, Nan Yang, Xiaolong Huang, Binxing Jiao, Linjun Yang, Daxin Jiang, Rangan Majumder, and Furu Wei. Text embeddings by weakly-supervised contrastive pre-training. arXiv preprint arXiv:2212.03533, 2022
work page internal anchor Pith review arXiv 2022
-
[5]
Pubchem, 2025
National Center for Biotechnology Information. Pubchem, 2025. URL https://pubchem. ncbi.nlm.nih.gov/. Accessed: 2025-06-04
2025
-
[6]
Chembl, 2025
European Bioinformatics Institute. Chembl, 2025. URL https://www.ebi.ac.uk/ chembl/. Accessed: 2025-06-04. 30
2025
-
[7]
Kyle Lo, Lucy Lu Wang, Mark Neumann, Rodney Kinney, and Dan S Weld. S2orc: The semantic scholar open research corpus. arXiv preprint arXiv:1911.02782, 2019
-
[8]
Mongodb, 2025
MongoDB, Inc. Mongodb, 2025. URL https://www.mongodb.com/. Accessed: 2025-06-04
2025
-
[9]
Mahmoud Amiri and Thomas Bocklitz. Chunk twice, embed once: A systematic study of segmentation and representation trade-offs in chemistry-aware retrieval-augmented gener- ation. arXiv preprint arXiv:2506.17277, 2025
-
[10]
Langchain: Building applications with llms through composability
Harrison Chase and LangChain contributors. Langchain: Building applications with llms through composability. https://github.com/langchain-ai/langchain, 2022. Accessed: 2025-05-28
2022
-
[11]
Scibert: A pretrained language model for scientific text
Iz Beltagy, Kyle Lo, and Arman Cohan. Scibert: A pretrained language model for scientific text. EMNLP, 2019
2019
-
[12]
Seyone Chithrananda, Gabriel Grand, Bharath Ramsun- dar, et al
Seyone Chithrananda, Gabriel Grand, and Bharath Ramsundar. Chemberta: large- scale self-supervised pretraining for molecular property prediction. arXiv preprint arXiv:2010.09885, 2020
-
[13]
sshleifer/distilbart-cnn-12-6, 2025
Hugging Face. sshleifer/distilbart-cnn-12-6, 2025. URL https://huggingface.co/ sshleifer/distilbart-cnn-12-6 . Model checkpoint accessed: 2025-06-04
2025
-
[14]
Billion-scale similarity search with gpus
Jeff Johnson, Matthijs Douze, and Hervé Jégou. Billion-scale similarity search with gpus. IEEE Transactions on Big Data, 7(3):535–547, 2019
2019
-
[15]
The use of mmr, diversity-based reranking for re- ordering documents and producing summaries
Jaime Carbonell and Jade Goldstein. The use of mmr, diversity-based reranking for re- ordering documents and producing summaries. In Proceedings of the 21st annual inter- national ACM SIGIR conference on Research and development in information retrieval, pages 335–336, 1998
1998
-
[16]
Chempile: A 250 gb diverse and curated dataset for chemical foundation models,
Adrian Mirza, Nawaf Alampara, Martiño Ríos-García, Mohamed Abdelalim, Jack Butler, Bethany Connolly, Tunca Dogan, Marianna Nezhurina, Bünyamin Şen, Santosh Tiruna- gari, Mark Worrall, Adamo Young, Philippe Schwaller, Michael Pieler, and Kevin Maik Jablonka. Chempile: A 250 gb diverse and curated dataset for chemical foundation models,
- [17]
-
[18]
Core: A global aggregation service for open access papers
Petr Knoth, Drahomira Herrmannova, Matteo Cancellieri, Lucas Anastasiou, Nancy Pon- tika, Samuel Pearce, Bikash Gyawali, and David Pride. Core: A global aggregation service for open access papers. Scientific Data, 10(1):366, 2023
2023
-
[19]
Rodney Kinney, Chloe Anastasiades, Russell Authur, Iz Beltagy, Jonathan Bragg, Alexan- dra Buraczynski, Isabel Cachola, Stefan Candra, Yoganand Chandrasekhar, Arman Cohan, et al. The semantic scholar open data platform. arXiv preprint arXiv:2301.10140, 2023
-
[20]
Chemu 2020: Natural language processing methods are effective for information extraction from chemical patents
Jiayuan He, Dat Quoc Nguyen, Saber A Akhondi, Christian Druckenbrodt, Camilo Thorne, Ralph Hoessel, Zubair Afzal, Zenan Zhai, Biaoyan Fang, Hiyori Yoshikawa, et al. Chemu 2020: Natural language processing methods are effective for information extraction from chemical patents. Frontiers in Research Metrics and Analytics, 6:654438, 2021. 31
2020
-
[21]
Pubmed central open access subset, 2022
National Library of Medicine. Pubmed central open access subset, 2022. https://www. ncbi.nlm.nih.gov/pmc/tools/openftlist/
2022
-
[22]
Domain-specific language model pretraining for biomedical natural language processing
Yu Gu, Ruiqi Tinn, Hao Cheng, et al. Domain-specific language model pretraining for biomedical natural language processing. ACM Transactions on Computing for Healthcare (HEALTH), 3(1):1–23, 2021
2021
-
[23]
TensorFlow: Large-Scale Machine Learning on Heterogeneous Distributed Systems
Martín Abadi, Ashish Agarwal, Paul Barham, Eugene Brevdo, Zhifeng Chen, Craig Citro, Greg S Corrado, Andy Davis, Jeffrey Dean, Matthieu Devin, et al. Tensorflow: Large-scale machine learning on heterogeneous distributed systems. arXiv preprint arXiv:1603.04467, 2016
work page Pith review arXiv 2016
-
[24]
Cord-19: The covid-19 open research dataset
Lucy Lu Wang, Kyle Lo, Yoganand Chandrasekhar, et al. Cord-19: The covid-19 open research dataset. arXiv preprint arXiv:2004.10706, 2020
-
[25]
The chemdner corpus of chem- icals and drugs and its annotation principles
Martin Krallinger, Obdulia Rabal, Anália Lourenço, et al. The chemdner corpus of chem- icals and drugs and its annotation principles. Journal of Cheminformatics, 7(1):S2, 2015
2015
-
[26]
Biocreative v cdr task corpus: a resource for chemical disease relation extraction
Jiao Li, Yueping Sun, Richard J Johnson, et al. Biocreative v cdr task corpus: a resource for chemical disease relation extraction. Database, 2016, 2016
2016
-
[27]
Nlm-chem, a new resource for chemical entity recognition in pubmed full text literature
Ranit Islamaj, Sun Kim, Laritza Rodriguez, et al. Nlm-chem, a new resource for chemical entity recognition in pubmed full text literature. Scientific Data, 8(1):1–12, 2021
2021
-
[28]
Overview of chemu 2020: named entity recognition and event extraction of chemical reactions from patents
Jiayuan He, Dat Quoc Nguyen, Saber A Akhondi, Christian Druckenbrodt, Camilo Thorne, Ralph Hoessel, Zubair Afzal, Zenan Zhai, Biaoyan Fang, Hiyori Yoshikawa, et al. Overview of chemu 2020: named entity recognition and event extraction of chemical reactions from patents. In International Conference of the Cross-Language Evaluation Forum for European Langua...
2020
-
[29]
Yujia Feng, Yida Shen, Tianze Xie, et al. Chemrxivquest: A benchmark for open-domain question answering in chemistry. arXiv preprint arXiv:2310.07699, 2023
-
[30]
Chemnlp: An open-source toolkit for natural language processing in chemistry, 2023
Kanishk Choudhary and David P Kelley. Chemnlp: An open-source toolkit for natural language processing in chemistry, 2023. https://github.com/OpenBioLink/ChemNLP
2023
-
[31]
Camel: Communicative agents for ”mind” exploration of large scale language model society, 2023
Guohao Li, Hasan Abed Al Kader Hammoud, Hani Itani, Dmitrii Khizbullin, and Bernard Ghanem. Camel: Communicative agents for ”mind” exploration of large scale language model society, 2023
2023
-
[32]
Pubmed, 2025
National Library of Medicine. Pubmed, 2025. URL https://pubmed.ncbi.nlm.nih.gov/. Accessed: 2025-06-04
2025
-
[33]
Lit2vec dataset, 2026
Bocklitz Lab. Lit2vec dataset, 2026. URL https://huggingface.co/datasets/ Bocklitz-Lab/Lit2Vec-dataset. Accessed: 2026-03-30
2026
-
[34]
Lit2vec code, 2026
Bocklitz Lab. Lit2vec code, 2026. URL https://github.com/Bocklitz-Lab/ Lit2Vec-code. Accessed: 2026-03-30. 32
2026
-
[35]
lit2vec-tldr-bart dataset, 2026
Bocklitz Lab. lit2vec-tldr-bart dataset, 2026. URL https://huggingface.co/datasets/ Bocklitz-Lab/lit2vec-tldr-bart . Accessed: 2026-03-30
2026
-
[36]
lit2vec-subfield-classifier dataset, 2026
Bocklitz Lab. lit2vec-subfield-classifier dataset, 2026. URL https://huggingface.co/ datasets/Bocklitz-Lab/lit2vec-subfield-classifier . Accessed: 2026-03-30
2026
-
[37]
lit2vec-tldr-bart, 2026
Bocklitz Lab. lit2vec-tldr-bart, 2026. URL https://github.com/Bocklitz-Lab/ lit2vec-tldr-bart. Accessed: 2026-03-30
2026
-
[38]
lit2vec-subfield-classifier, 2026
Bocklitz Lab. lit2vec-subfield-classifier, 2026. URL https://github.com/Bocklitz-Lab/ lit2vec-subfield-classifier. Accessed: 2026-03-30
2026
-
[39]
Lit2vec example task: Rag, 2026
Bocklitz Lab. Lit2vec example task: Rag, 2026. URL https://github.com/ Bocklitz-Lab/Lit2Vec-code/tree/main/example_tasks/RAG. Accessed: 2026-03-30
2026
-
[40]
Lit2vec example task: recommendation system, 2026
Bocklitz Lab. Lit2vec example task: recommendation system, 2026. URL https://github.com/Bocklitz-Lab/Lit2Vec-code/tree/main/example_tasks/ recomendation_system. Accessed: 2026-03-30
2026
-
[41]
Lit2vec example task: trend analysis, 2026
Bocklitz Lab. Lit2vec example task: trend analysis, 2026. URL https://github.com/ Bocklitz-Lab/Lit2Vec-code/tree/main/example_tasks/trend_analysis. Accessed: 2026-03-30
2026
-
[42]
Lit2vec annotation validation scripts, 2026
Bocklitz Lab. Lit2vec annotation validation scripts, 2026. URL https://github.com/ Bocklitz-Lab/Lit2Vec-code/tree/main/annotation_validation. Accessed: 2026-03- 30
2026
-
[43]
lit2vec-tldr-bart model, 2026
Bocklitz Lab. lit2vec-tldr-bart model, 2026. URL https://huggingface.co/ Bocklitz-Lab/lit2vec-tldr-bart . Accessed: 2026-03-30
2026
-
[44]
lit2vec-tldr-bart-space demo, 2026
Bocklitz Lab. lit2vec-tldr-bart-space demo, 2026. URL https://huggingface.co/ spaces/Bocklitz-Lab/lit2vec-tldr-bart-space . Accessed: 2026-03-30
2026
-
[45]
lit2vec-subfield-classifier model, 2026
Bocklitz Lab. lit2vec-subfield-classifier model, 2026. URL https://huggingface.co/ Bocklitz-Lab/lit2vec-subfield-classifier . Accessed: 2026-03-30
2026
-
[46]
field_classification
Bocklitz Lab. lit2vec-subfield-classifier-space demo, 2026. URL https://huggingface.co/ spaces/Bocklitz-Lab/lit2vec-subfield-classifier-space . Accessed: 2026-03-30. 7 Supplementary Materials 7.1 Related Work Early efforts in biomedical text mining focused on manually annotated, task-specific datasets. The CHEMDNER corpus [ 24] established a benchmark for...
2026
-
[47]
|paragraphs| = |embeddings| = N
-
[48]
ei encodes paragraphs[i] (same index)
-
[49]
Model/dtype are fixed across all records (1024-D, float32). 46 Truncated example JSON record: { " schema_version ": "1.0" , " corpus_id ": 37254803 , " metadata ": { " title ": "..." , " year ": 2016 , " externalids ": { "DOI ": "10. xxxx / xxxxx " }, "url ": " https ://..." }, " abstract ": " Epigallocatechin gallate ..." , " fulltext ": "# Protective ef...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.