Recognition: unknown
Beyond Transcription: Unified Audio Schema for Perception-Aware AudioLLMs
Pith reviewed 2026-05-10 14:45 UTC · model grok-4.3
The pith
A three-component JSON schema for audio lets AudioLLMs perceive tone and events while keeping strong reasoning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Organizing audio information into the three components of Transcription, Paralinguistics, and Non-linguistic Events within a unified JSON format provides comprehensive acoustic coverage and improves fine-grained perception by 10.9 percent on MMSU over same-size state-of-the-art models without sacrificing reasoning capabilities.
What carries the argument
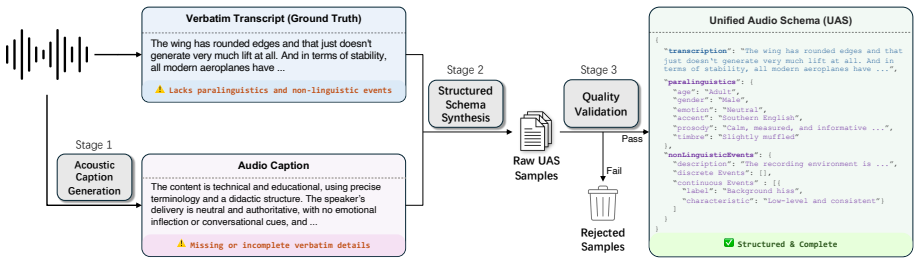
The Unified Audio Schema (UAS), a structured supervision framework that places transcription, paralinguistic features, and non-linguistic events into one JSON object and thereby supplies explicit targets for every acoustic aspect during training.
If this is right
- Models trained with UAS show higher accuracy on tasks that require detecting tone, emotion, and background sounds on MMSU, MMAR, and MMAU.
- The same schema improves both discrete-token and continuous-feature AudioLLM architectures.
- Reasoning performance on complex logic and question-answering tasks remains at the same level as before the change.
- The gains appear consistently across multiple benchmarks without requiring larger model size.
Where Pith is reading between the lines
- The same three-part breakdown could be applied to video models so they learn to link visual events with matching sounds and speech.
- Longer audio recordings might be handled by first segmenting them and then applying the schema to each segment before combining the JSON outputs.
- Other multimodal models facing conflicting objectives could adopt similar explicit multi-aspect targets to reduce interference between perception and reasoning.
Load-bearing premise
That ASR-centric training is the main reason models suppress paralinguistic and event information, and that switching to the three-part JSON schema will not create new alignment or noise problems that cancel the gains.
What would settle it
Train an AudioLLM with the UAS schema on the same data and measure no gain or a loss in fine-grained perception scores on MMSU compared with the original ASR-trained version, or observe a clear drop in reasoning accuracy.
Figures






read the original abstract
Recent Audio Large Language Models (AudioLLMs) exhibit a striking performance inversion: while excelling at complex reasoning tasks, they consistently underperform on fine-grained acoustic perception. We attribute this gap to a fundamental limitation of ASR-centric training, which provides precise linguistic targets but implicitly teaches models to suppress paralinguistic cues and acoustic events as noise. To address this, we propose Unified Audio Schema (UAS), a holistic and structured supervision framework that organizes audio information into three explicit components -- Transcription, Paralinguistics, and Non-linguistic Events -- within a unified JSON format. This design achieves comprehensive acoustic coverage without sacrificing the tight audio-text alignment that enables reasoning. We validate the effectiveness of this supervision strategy by applying it to both discrete and continuous AudioLLM architectures. Extensive experiments on MMSU, MMAR, and MMAU demonstrate that UAS-Audio yields consistent improvements, boosting fine-grained perception by 10.9% on MMSU over the same-size state-of-the-art models while preserving robust reasoning capabilities. Our code and model are publicly available at https://github.com/Tencent/Unified_Audio_Schema.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper attributes the underperformance of AudioLLMs on fine-grained acoustic perception (despite strong reasoning) to ASR-centric training that suppresses paralinguistic and event cues. It introduces Unified Audio Schema (UAS), a JSON-structured supervision with three explicit components—Transcription, Paralinguistics, and Non-linguistic Events—and applies it to both discrete and continuous AudioLLM architectures. Experiments on MMSU, MMAR, and MMAU report consistent gains, including a 10.9% lift in fine-grained perception on MMSU over same-size SOTA models, while preserving reasoning; code and models are released publicly.
Significance. If the gains are attributable to the structured schema rather than ancillary factors, UAS could provide a practical route to perception-aware AudioLLMs without sacrificing the tight audio-text alignment needed for reasoning. Public code release is a clear strength that supports reproducibility and follow-on work.
major comments (2)
- [Abstract / Experiments] Abstract and experimental results: the central claim that UAS overcomes ASR-induced suppression of paralinguistic cues rests on the reported 10.9% MMSU improvement, yet no ablation is described that holds training data volume, epochs, and optimizer fixed while varying only the target structure (full three-component JSON versus transcription-only). Without this isolation, the delta could be explained by increased supervision volume or diversity rather than the specific schema organization.
- [Experiments] Experimental details: the manuscript provides no description of how the Paralinguistics and Non-linguistic Events fields in the UAS JSON labels were created, annotated, or validated for quality, nor any error bars, confidence intervals, or statistical tests on the benchmark deltas. These omissions make it impossible to assess whether the gains are robust or sensitive to annotation noise.
minor comments (2)
- [Abstract] The abstract states that UAS is applied to 'both discrete and continuous AudioLLM architectures' but does not specify the exact model sizes, baseline checkpoints, or training hyperparameters used in each case, which would aid direct replication.
- Figure or table captions (if present) should explicitly note whether results are averaged over multiple seeds; the absence of such detail compounds the lack of error bars already noted.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript to strengthen the presentation of our results.
read point-by-point responses
-
Referee: [Abstract / Experiments] Abstract and experimental results: the central claim that UAS overcomes ASR-induced suppression of paralinguistic cues rests on the reported 10.9% MMSU improvement, yet no ablation is described that holds training data volume, epochs, and optimizer fixed while varying only the target structure (full three-component JSON versus transcription-only). Without this isolation, the delta could be explained by increased supervision volume or diversity rather than the specific schema organization.
Authors: We agree that a controlled ablation isolating the contribution of the UAS structure itself is needed to fully support the central claim. Our reported gains are relative to same-size SOTA models whose training is predominantly transcription-centric, but we did not include an intra-experiment ablation that fixes data volume, epochs, and optimizer while varying only the supervision format. In the revised manuscript we will add this ablation, training matched model configurations on identical data with either full UAS JSON targets or transcription-only targets. This will allow direct attribution of gains to the structured schema rather than supervision volume. revision: yes
-
Referee: [Experiments] Experimental details: the manuscript provides no description of how the Paralinguistics and Non-linguistic Events fields in the UAS JSON labels were created, annotated, or validated for quality, nor any error bars, confidence intervals, or statistical tests on the benchmark deltas. These omissions make it impossible to assess whether the gains are robust or sensitive to annotation noise.
Authors: We acknowledge these omissions limit assessment of robustness. In the revised manuscript we will add a dedicated subsection describing the creation, annotation, and quality-validation procedures for the Paralinguistics and Non-linguistic Events fields. We will also report error bars (standard deviation across runs), confidence intervals, and statistical significance tests (e.g., paired t-tests or Wilcoxon tests) for all benchmark deltas on MMSU, MMAR, and MMAU. revision: yes
Circularity Check
No circularity: empirical validation on public benchmarks with no derivations or self-referential fits
full rationale
The paper introduces the UAS schema as a structured supervision format and reports performance gains from applying it to existing AudioLLM architectures on MMSU, MMAR, and MMAU. No equations, parameter fits, or predictions appear in the provided text. The central claim rests on comparative results against state-of-the-art models using public datasets rather than any internal normalization, self-citation chain, or construction that equates outputs to inputs by definition. This is a standard empirical proposal whose evidence is externally falsifiable.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Audio signals can be exhaustively and non-overlappingly partitioned into transcription, paralinguistics, and non-linguistic events.
Reference graph
Works this paper leans on
-
[1]
Szu-Wei Fu, Yu Tsao, Hsin-Te Hwang, and Hsin- Min Wang
MiDashengLM: Efficient Audio Under- standing with General Audio Captions.Preprint, arXiv:2508.03983. Alexandre Défossez, Laurent Mazaré, Manu Orsini, Amélie Royer, Patrick Pérez, Hervé Jégou, Edouard Grave, and Neil Zeghidour. 2024. Moshi: a speech-text foundation model for real-time dialogue. Preprint, arXiv:2410.00037. Qingkai Fang, Shoutao Guo, Yan Zho...
-
[2]
In2023 IEEE Automatic Speech Recog- nition and Understanding Workshop (ASRU), pages 1–8
Yodas: Youtube-Oriented Dataset for Audio and Speech. In2023 IEEE Automatic Speech Recog- nition and Understanding Workshop (ASRU), pages 1–8. Yaron Lipman, Ricky T. Q. Chen, Heli Ben-Hamu, Max- imilian Nickel, and Matthew Le. 2023. Flow Match- ing for Generative Modeling. InThe Eleventh Inter- national Conference on Learning Representations. Ziyang Ma, Y...
2023
-
[3]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
MMAR: A Challenging Benchmark for Deep Reasoning in Speech, Audio, Music, and Their Mix. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Bench- marks Track. Vassil Panayotov, Guoguo Chen, Daniel Povey, and Sanjeev Khudanpur. 2015. Librispeech: An ASR corpus based on public domain audio books. In2015 IEEE Internat...
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[4]
WENETSPEECH: A 10000+ Hours Multi- Domain Mandarin Corpus for Speech Recognition. InICASSP 2022 - 2022 IEEE International Confer- ence on Acoustics, Speech and Signal Processing (ICASSP), pages 6182–6186. Dong Zhang, Shimin Li, Xin Zhang, Jun Zhan, Pengyu Wang, Yaqian Zhou, and Xipeng Qiu. 2023. SpeechGPT: Empowering Large Language Models with Intrinsic C...
-
[5]
Unstructured Caption
in both settings to strictly isolate the impact of the supervision format while controlling for model architecture and training data. Target Format Perception Reasoning Average Unstructured Caption48.4 75.5 61.5 Structured UAS 54.8 76.0 65.2 Table 7: Impact of supervision format on MMSU. The "Unstructured Caption" setting serves as a proxy for caption-bas...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.