Recognition: unknown
Scalable Trajectory Generation for Whole-Body Mobile Manipulation
Pith reviewed 2026-05-10 15:46 UTC · model grok-4.3
The pith
AutoMoMa unifies base arm and object kinematics into one chain to generate 500000 valid whole-body trajectories at 5000 episodes per GPU hour.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
AutoMoMa consolidates the mobile base, manipulator arm, and target object into a single kinematic chain through AKR modeling, then applies parallelized trajectory optimization on GPUs to produce over 500000 physically valid trajectories at a rate of 5000 episodes per GPU-hour, which is more than eighty times faster than CPU baselines. The resulting dataset spans 330 scenes, multiple articulated objects, and several robot embodiments while preserving kinematic fidelity. When used to train imitation learning policies, the volume of data enables approximately eighty percent success on single articulated-object tasks, whereas prior smaller datasets left performance well below that level, showing
What carries the argument
AKR modeling that consolidates base, arm, and object kinematics into one unified chain for joint trajectory optimization, paired with GPU-parallelized planning.
If this is right
- Imitation learning policies trained on the large dataset reach approximately eighty percent success on articulated-object tasks that smaller prior datasets could not support.
- The generation method scales across 330 scenes, diverse objects, and multiple robot embodiments without sacrificing physical validity.
- Data scarcity rather than algorithmic limits has been the binding constraint for reliable whole-body mobile manipulation.
- High-speed GPU pipelines make it feasible to produce the tens of thousands of demonstrations required for state-of-the-art performance on complex tasks.
Where Pith is reading between the lines
- The same single-chain modeling idea could be adapted to speed up planning for other multi-body robotic systems such as dual-arm or legged platforms.
- Future work on robot learning may shift emphasis toward building efficient data-generation pipelines as a prerequisite for testing new algorithms.
- If the trajectories transfer well to hardware, the approach would support policies that operate in unstructured real-world settings where fixed-base methods fall short.
Load-bearing premise
That trajectories produced by the unified kinematic chain remain physically valid and free of hidden inconsistencies that would prevent successful transfer to imitation learning policies or real robots.
What would settle it
Training imitation learning policies on the generated trajectories and measuring success rates that remain far below the claimed eighty percent due to kinematic errors or simulation-reality mismatch would disprove the framework's utility for downstream control.
Figures







read the original abstract
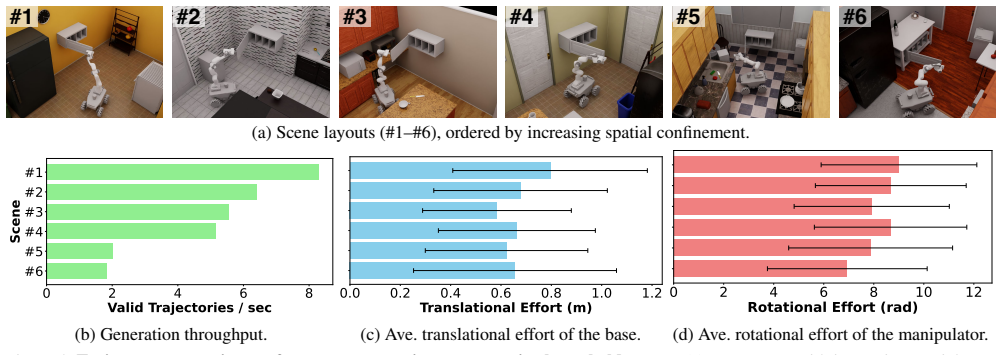
Robots deployed in unstructured environments must coordinate whole-body motion -- simultaneously moving a mobile base and arm -- to interact with the physical world. This coupled mobility and dexterity yields a state space that grows combinatorially with scene and object diversity, demanding datasets far larger than those sufficient for fixed-base manipulation. Yet existing acquisition methods, including teleoperation and planning, are either labor-intensive or computationally prohibitive at scale. The core bottleneck is the lack of a scalable pipeline for generating large-scale, physically valid, coordinated trajectory data across diverse embodiments and environments. Here we introduce AutoMoMa, a GPU-accelerated framework that unifies AKR modeling, which consolidates base, arm, and object kinematics into a single chain, with parallelized trajectory optimization. AutoMoMa achieves 5,000 episodes per GPU-hour (over $80\times$ faster than CPU-based baselines), producing a dataset of over 500k physically valid trajectories spanning 330 scenes, diverse articulated objects, and multiple robot embodiments. Prior datasets were forced to compromise on scale, diversity, or kinematic fidelity; AutoMoMa addresses all three simultaneously. Training downstream IL policies further reveals that even a single articulated-object task requires tens of thousands of demonstrations for SOTA methods to reach $\approx 80\%$ success, confirming that data scarcity -- not algorithmic limitations -- has been the binding constraint. AutoMoMa thus bridges high-performance planning and reliable IL-based control, providing the infrastructure previously missing for coordinated mobile manipulation research. By making large-scale, kinematically valid training data practical, AutoMoMa showcases generalizable whole-body robot policies capable of operating in the diverse, unstructured settings of the real world.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces AutoMoMa, a GPU-accelerated framework for generating large-scale datasets of whole-body mobile manipulation trajectories. By unifying AKR modeling—which consolidates the mobile base, arm, and object into a single kinematic chain—with parallelized trajectory optimization, it claims to produce over 500,000 physically valid trajectories at a rate of 5,000 episodes per GPU-hour, representing an 80× speedup over CPU-based methods. The work spans 330 scenes with diverse articulated objects and multiple robot embodiments, and downstream imitation learning experiments indicate that tens of thousands of demonstrations are required for state-of-the-art methods to achieve approximately 80% success on articulated tasks.
Significance. If the claims regarding physical validity, kinematic fidelity, and computational efficiency hold, this paper makes a substantial contribution to robotics by addressing the critical bottleneck of data acquisition for whole-body mobile manipulation in unstructured environments. The ability to generate diverse, large-scale, valid trajectory data at scale could enable more robust imitation learning policies, shifting the focus from algorithmic limitations to data availability. The reported scale and diversity, combined with the IL results, highlight the importance of such infrastructure for advancing generalizable robot control.
major comments (2)
- [Abstract] The abstract reports performance numbers (5,000 episodes/GPU-hour, 80× speedup, 500k trajectories) and IL success rates (~80%) but provides no details on validation metrics, error analysis, or post-optimization checks for physical validity, joint limits, collisions, or dynamic feasibility in the AKR single-chain model.
- [AKR Modeling and Trajectory Optimization] The central claim of producing 'physically valid' trajectories relies on the AKR consolidation into one kinematic chain and GPU-parallel optimization; however, without explicit quantitative evidence that this unification does not introduce undetected kinematic errors, collision violations, or approximation artifacts, the downstream 80% IL success claim and the dataset's utility remain at risk.
minor comments (1)
- [Abstract] The notation for 'AKR modeling' is introduced without prior definition or expansion in the abstract, which may confuse readers unfamiliar with the term.
Simulated Author's Rebuttal
Thank you for your thoughtful review and for recognizing the potential significance of AutoMoMa in addressing data scarcity for whole-body mobile manipulation. We address each major comment below and will revise the manuscript to incorporate additional details on validation and quantitative evidence.
read point-by-point responses
-
Referee: [Abstract] The abstract reports performance numbers (5,000 episodes/GPU-hour, 80× speedup, 500k trajectories) and IL success rates (~80%) but provides no details on validation metrics, error analysis, or post-optimization checks for physical validity, joint limits, collisions, or dynamic feasibility in the AKR single-chain model.
Authors: We agree that the abstract's brevity omits these specifics. The full manuscript describes the validation pipeline in the experimental evaluation, including post-optimization checks for joint limits, collisions, and dynamic feasibility enforced by the optimizer. To address this, we will revise the abstract to include a concise reference to these validation steps and expand the methods section with explicit quantitative metrics such as collision violation rates and joint limit adherence statistics. revision: yes
-
Referee: [AKR Modeling and Trajectory Optimization] The central claim of producing 'physically valid' trajectories relies on the AKR consolidation into one kinematic chain and GPU-parallel optimization; however, without explicit quantitative evidence that this unification does not introduce undetected kinematic errors, collision violations, or approximation artifacts, the downstream 80% IL success claim and the dataset's utility remain at risk.
Authors: The AKR formulation performs an exact kinematic consolidation without approximation artifacts, as the single-chain representation is mathematically equivalent to the original multi-body system. Trajectory optimization directly encodes collision, joint-limit, and feasibility constraints, with the reported IL success rates serving as downstream validation. We acknowledge the request for more direct quantitative evidence; in revision we will add explicit metrics (e.g., fraction of trajectories with zero inter-body penetration, average joint-limit slack, and any residual kinematic discrepancies) to the results section to strengthen support for the physical-validity claims. revision: yes
Circularity Check
No circularity: empirical framework performance stands independent of inputs
full rationale
The paper presents an implemented GPU framework (AKR chain unification + parallel trajectory optimization) whose speed and scale metrics (5000 episodes/GPU-hour, 500k trajectories) are direct runtime outputs rather than fitted predictions or self-defined quantities. Downstream IL success rates (~80%) are measured on the generated dataset and serve as external validation, not a loop back to the modeling assumptions. No equations, uniqueness theorems, or ansatzes are shown to reduce to prior self-citations or input data by construction. The derivation from modeling choice to dataset production is self-contained and falsifiable via the reported benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption AKR modeling consolidates base, arm, and object kinematics into a single chain without loss of fidelity.
invented entities (1)
-
AutoMoMa framework
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Affordances from human videos as a versa- tile representation for robotics
Shikhar Bahl, Russell Mendonca, Lili Chen, Unnat Jain, and Deepak Pathak. Affordances from human videos as a versa- tile representation for robotics. InConference on Computer Vision and Pattern Recognition (CVPR), 2023. 3
2023
-
[2]
An optimization approach to planning for mobile manipulation
Dmitry Berenson, James Kuffner, and Howie Choset. An optimization approach to planning for mobile manipulation. InInternational Conference on Robotics and Automation (ICRA), 2008. 2
2008
-
[3]
Motion planning for mobile robots using inverse kinematics branching
Daniel M Bodily, Thomas F Allen, and Marc D Killpack. Motion planning for mobile robots using inverse kinematics branching. InInternational Conference on Robotics and Au- tomation (ICRA), 2017. 2
2017
-
[4]
Rt-1: Robotics transformer for real-world control at scale
Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Joseph Dabis, Chelsea Finn, Keerthana Gopalakr- ishnan, Karol Hausman, Alexander Herzog, Jasmine Hsu, et al. Rt-1: Robotics transformer for real-world control at scale. InRobotics: Science and Systems (RSS), 2023. 3
2023
-
[5]
Federico Ceola, Lorenzo Natale, Niko S ¨underhauf, and Kr- ishan Rana. Lhmanip: A dataset for long-horizon language- grounded manipulation tasks in cluttered tabletop environ- ments.arXiv preprint arXiv:2312.12036, 2023. 2, 3
-
[6]
Diffusion policy: Visuomotor policy learning via action dif- fusion.International Journal of Robotics Research (IJRR), 44(10-11):1684–1704, 2025
Cheng Chi, Zhenjia Xu, Siyuan Feng, Eric Cousineau, Yilun Du, Benjamin Burchfiel, Russ Tedrake, and Shuran Song. Diffusion policy: Visuomotor policy learning via action dif- fusion.International Journal of Robotics Research (IJRR), 44(10-11):1684–1704, 2025. 7, 8, A2, A7
2025
-
[7]
Toward affordance detection and ranking on novel ob- jects for real-world robotic manipulation.IEEE Robotics and Automation Letters (RA-L), 4(4):4070–4077, 2019
Fu-Jen Chu, Ruinian Xu, Landan Seguin, and Patricio A Vela. Toward affordance detection and ranking on novel ob- jects for real-world robotic manipulation.IEEE Robotics and Automation Letters (RA-L), 4(4):4070–4077, 2019. 6
2019
-
[8]
Gapartmanip: a large-scale dataset for generalizable and actionable part ma- nipulation with material-agnostic articulated objects
Wenbo Cui, Chengyang Zhao, Songlin Wei, Jiazhao Zhang, Haoran Geng, Yaran Chen, and He Wang. Gapartmanip: a large-scale dataset for generalizable and actionable part ma- nipulation with material-agnostic articulated objects. InIn- ternational Conference on Robotics and Automation (ICRA),
-
[9]
Shivin Dass, Wensi Ai, Yuqian Jiang, Samik Singh, Jiaheng Hu, Ruohan Zhang, Peter Stone, Ben Abbatematteo, and Roberto Mart´ın-Mart´ın. Telemoma: A modular and versatile teleoperation system for mobile manipulation.arXiv preprint arXiv:2403.07869, 2024. 3
-
[10]
Affordancenet: An end-to-end deep learning approach for object affordance detection
Thanh-Toan Do, Anh Nguyen, and Ian Reid. Affordancenet: An end-to-end deep learning approach for object affordance detection. InInternational Conference on Robotics and Au- tomation (ICRA), 2018. 6
2018
-
[11]
Survey of imitation learning for robotic manipulation.International Journal of Intelligent Robotics and Applications, 3(4):362–369, 2019
Bin Fang, Shidong Jia, Di Guo, Muhua Xu, Shuhuan Wen, and Fuchun Sun. Survey of imitation learning for robotic manipulation.International Journal of Intelligent Robotics and Applications, 3(4):362–369, 2019. 6
2019
-
[12]
Deep whole- body control: learning a unified policy for manipulation and locomotion
Zipeng Fu, Xuxin Cheng, and Deepak Pathak. Deep whole- body control: learning a unified policy for manipulation and locomotion. InConference on Robot Learning (CoRL),
-
[13]
Mobile aloha: Learning bimanual mobile manipulation using low- cost whole-body teleoperation
Zipeng Fu, Tony Z Zhao, and Chelsea Finn. Mobile aloha: Learning bimanual mobile manipulation using low- cost whole-body teleoperation. InConference on Robot Learning (CoRL), 2024. 1, 2, 3, 7, 8, A4, A7
2024
-
[14]
Plan- ning with adaptive dimensionality for mobile manipulation
Kalin Gochev, Alla Safonova, and Maxim Likhachev. Plan- ning with adaptive dimensionality for mobile manipulation. InInternational Conference on Robotics and Automation (ICRA), 2012. 2
2012
-
[15]
Learn- ing for a robot: Deep reinforcement learning, imitation learn- ing, transfer learning.Sensors, 21(4):1278, 2021
Jiang Hua, Liangcai Zeng, Gongfa Li, and Zhaojie Ju. Learn- ing for a robot: Deep reinforcement learning, imitation learn- ing, transfer learning.Sensors, 21(4):1278, 2021. 6
2021
-
[16]
Pulling open doors and drawers: Coordinating an omni-directional base and a com- pliant arm with equilibrium point control
Advait Jain and Charles C Kemp. Pulling open doors and drawers: Coordinating an omni-directional base and a com- pliant arm with equilibrium point control. InInternational Conference on Robotics and Automation (ICRA), 2010. 2
2010
-
[17]
Comparison of basic visual servoing methods.Trans- actions on Mechatronics (TMECH), 16(5):967–983, 2010
Farrokh Janabi-Sharifi, Lingfeng Deng, and William J Wil- son. Comparison of basic visual servoing methods.Trans- actions on Mechatronics (TMECH), 16(5):967–983, 2010. 6
2010
-
[18]
Bc-z: Zero-shot task generalization with robotic imitation learning
Eric Jang, Alex Irpan, Mohi Khansari, Daniel Kappler, Fred- erik Ebert, Corey Lynch, Sergey Levine, and Chelsea Finn. Bc-z: Zero-shot task generalization with robotic imitation learning. InConference on Robot Learning (CoRL), 2022. 2, 3
2022
-
[19]
Behavior robot suite: Streamlining real- world whole-body manipulation for everyday household ac- tivities
Yunfan Jiang, Ruohan Zhang, Josiah Wong, Chen Wang, Yanjie Ze, Hang Yin, Cem Gokmen, Shuran Song, Jiajun Wu, and Li Fei-Fei. Behavior robot suite: Streamlining real- world whole-body manipulation for everyday household ac- tivities. InConference on Robot Learning (CoRL), 2025. 3
2025
-
[20]
Consolidating kinematic models to promote coordinated mobile manipulations
Ziyuan Jiao, Zeyu Zhang, Xin Jiang, David Han, Song-Chun Zhu, Yixin Zhu, and Hangxin Liu. Consolidating kinematic models to promote coordinated mobile manipulations. In International Conference on Intelligent Robots and Systems (IROS), 2021. 2
2021
-
[21]
Efficient task plan- ning for mobile manipulation: a virtual kinematic chain per- spective
Ziyuan Jiao, Zeyu Zhang, Weiqi Wang, David Han, Song- Chun Zhu, Yixin Zhu, and Hangxin Liu. Efficient task plan- ning for mobile manipulation: a virtual kinematic chain per- spective. InInternational Conference on Intelligent Robots and Systems (IROS), 2021. 2
2021
-
[22]
Integration of robot and scene kinematics for sequential mobile manipula- tion planning.Transactions on Robotics (T-RO), 2025
Ziyuan Jiao, Yida Niu, Zeyu Zhang, Yangyang Wu, Yao Su, Yixin Zhu, Hangxin Liu, and Song-Chun Zhu. Integration of robot and scene kinematics for sequential mobile manipula- tion planning.Transactions on Robotics (T-RO), 2025. 1, 2, 3, 4
2025
-
[23]
An adaptive 9 control approach for opening doors and drawers under uncer- tainties.Transactions on Robotics (T-RO), 32(1):161–175,
Yiannis Karayiannidis, Christian Smith, Francisco Eli Vina Barrientos, Petter ¨Ogren, and Danica Kragic. An adaptive 9 control approach for opening doors and drawers under uncer- tainties.Transactions on Robotics (T-RO), 32(1):161–175,
-
[24]
Mobile manipulation: The robotic assis- tant.Robotics and Autonomous Systems, 26(2-3):175–183,
Oussama Khatib. Mobile manipulation: The robotic assis- tant.Robotics and Autonomous Systems, 26(2-3):175–183,
-
[25]
AI2-THOR: An Interactive 3D Environment for Visual AI
Eric Kolve, Roozbeh Mottaghi, Winson Han, Eli VanderBilt, Luca Weihs, Alvaro Herrasti, Matt Deitke, Kiana Ehsani, Daniel Gordon, Yuke Zhu, et al. Ai2-thor: An interactive 3d environment for visual ai.arXiv preprint arXiv:1712.05474,
work page internal anchor Pith review arXiv
-
[26]
Robohive: A unified framework for robot learn- ing
Vikash Kumar, Rutav Shah, Gaoyue Zhou, Vincent Moens, Vittorio Caggiano, Abhishek Gupta, and Aravind Ra- jeswaran. Robohive: A unified framework for robot learn- ing. InAdvances in Neural Information Processing Systems (NeurIPS), 2023. 2
2023
-
[27]
Behavior-1k: A benchmark for embodied ai with 1,000 ev- eryday activities and realistic simulation
Chengshu Li, Ruohan Zhang, Josiah Wong, Cem Gokmen, Sanjana Srivastava, Roberto Mart ´ın-Mart´ın, Chen Wang, Gabrael Levine, Michael Lingelbach, Jiankai Sun, et al. Behavior-1k: A benchmark for embodied ai with 1,000 ev- eryday activities and realistic simulation. InConference on Robot Learning (CoRL), 2023. 2
2023
-
[28]
Chengshu Li, Mengdi Xu, Arpit Bahety, Hang Yin, Yun- fan Jiang, Huang Huang, Josiah Wong, Sujay Garlanka, Cem Gokmen, Ruohan Zhang, et al. Momagen: Gener- ating demonstrations under soft and hard constraints for multi-step bimanual mobile manipulation.arXiv preprint arXiv:2510.18316, 2025. 3, A6
-
[29]
Struc- tured world models from human videos
Russell Mendonca, Shikhar Bahl, and Deepak Pathak. Struc- tured world models from human videos. InRobotics: Science and Systems (RSS), 2023. 3
2023
-
[30]
Conq hose manipula- tion dataset, v1.15.0, 2024
Peter Mitrano and Dmitry Berenson. Conq hose manipula- tion dataset, v1.15.0, 2024. 3
2024
-
[31]
Articulated object interaction in unknown scenes with whole-body mobile manipulation
Mayank Mittal, David Hoeller, Farbod Farshidian, Marco Hutter, and Animesh Garg. Articulated object interaction in unknown scenes with whole-body mobile manipulation. In International Conference on Intelligent Robots and Systems (IROS), 2022. 2
2022
-
[32]
Ao-grasp: Articulated object grasp generation
Carlota Par ´es Morlans, Claire Chen, Yijia Weng, Michelle Yi, Yuying Huang, Nick Heppert, Linqi Zhou, Leonidas Guibas, and Jeannette Bohg. Ao-grasp: Articulated object grasp generation. InInternational Conference on Intelligent Robots and Systems (IROS), 2024. 6
2024
-
[33]
The surprising effec- tiveness of representation learning for visual imitation
Jyothish Pari, Nur Muhammad Mahi Shafiullah, Sridhar Pan- dian Arunachalam, and Lerrel Pinto. The surprising effec- tiveness of representation learning for visual imitation. In Robotics: Science and Systems (RSS), 2022. 2, 3
2022
-
[34]
In- finigen indoors: Photorealistic indoor scenes using procedu- ral generation
Alexander Raistrick, Lingjie Mei, Karhan Kayan, David Yan, Yiming Zuo, Beining Han, Hongyu Wen, Meenal Parakh, Stamatis Alexandropoulos, Lahav Lipson, et al. In- finigen indoors: Photorealistic indoor scenes using procedu- ral generation. InConference on Computer Vision and Pat- tern Recognition (CVPR), 2024. 6, A2
2024
-
[35]
Learning agent-aware affordances for closed-loop interaction with articulated ob- jects
Giulio Schiavi, Paula Wulkop, Giuseppe Rizzi, Lionel Ott, Roland Siegwart, and Jen Jen Chung. Learning agent-aware affordances for closed-loop interaction with articulated ob- jects. InInternational Conference on Robotics and Automa- tion (ICRA), 2023. 3
2023
-
[36]
Nur Muhammad Mahi Shafiullah, Anant Rai, Haritheja Etukuru, Yiqian Liu, Ishan Misra, Soumith Chintala, and Lerrel Pinto. On bringing robots home.arXiv preprint arXiv:2311.16098, 2023. 3
-
[37]
Maniskill-hab: A benchmark for low-level manipulation in home rearrange- ment tasks
Arth Shukla, Stone Tao, and Hao Su. Maniskill-hab: A benchmark for low-level manipulation in home rearrange- ment tasks. InInternational Conference on Learning Rep- resentations (ICLR), 2025. 3
2025
-
[38]
Versatile multicontact planning and control for legged loco- manipulation.Science Robotics, 8(81):eadg5014, 2023
Jean-Pierre Sleiman, Farbod Farshidian, and Marco Hutter. Versatile multicontact planning and control for legged loco- manipulation.Science Robotics, 8(81):eadg5014, 2023. 1, 2
2023
-
[39]
Door opening and traversal with an industrial cartesian impedance controlled mobile robot
Marvin Stuede, Kathrin Nuelle, Svenja Tappe, and Tobias Ortmaier. Door opening and traversal with an industrial cartesian impedance controlled mobile robot. InInter- national Conference on Robotics and Automation (ICRA),
-
[40]
Fully autonomous real-world reinforcement learning with applications to mobile manipulation
Charles Sun, Jedrzej Orbik, Coline Manon Devin, Brian H Yang, Abhishek Gupta, Glen Berseth, and Sergey Levine. Fully autonomous real-world reinforcement learning with applications to mobile manipulation. InConference on Robot Learning (CoRL), 2022. 2
2022
-
[41]
A review of robot control with visual servoing
Xiaoying Sun, Xiaojun Zhu, Pengyuan Wang, and Hua Chen. A review of robot control with visual servoing. In2018 IEEE 8th Annual International Conference on CYBER Technology in Automation, Control, and Intelligent Systems (CYBER),
-
[42]
Curobo: Parallelized collision-free robot mo- tion generation
Balakumar Sundaralingam, Siva Kumar Sastry Hari, Adam Fishman, Caelan Garrett, Karl Van Wyk, Valts Blukis, Alexander Millane, Helen Oleynikova, Ankur Handa, Fabio Ramos, et al. Curobo: Parallelized collision-free robot mo- tion generation. InInternational Conference on Robotics and Automation (ICRA), 2023. 2, A2
2023
-
[43]
Habitat 2.0: training home assistants to rearrange their habitat
Andrew Szot, Alex Clegg, Eric Undersander, Erik Wijmans, Yili Zhao, John Turner, Noah Maestre, Mustafa Mukadam, Devendra Chaplot, Oleksandr Maksymets, et al. Habitat 2.0: training home assistants to rearrange their habitat. InAd- vances in Neural Information Processing Systems (NeurIPS),
-
[44]
Tidybot: Person- alized robot assistance with large language models.Au- tonomous Robots, 47(8):1087–1102, 2023
Jimmy Wu, Rika Antonova, Adam Kan, Marion Lep- ert, Andy Zeng, Shuran Song, Jeannette Bohg, Szymon Rusinkiewicz, and Thomas Funkhouser. Tidybot: Person- alized robot assistance with large language models.Au- tonomous Robots, 47(8):1087–1102, 2023. 2, 3
2023
-
[45]
A teleoperation interface for loco-manipulation control of mobile collaborative robotic as- sistant.IEEE Robotics and Automation Letters (RA-L), 4(4): 3593–3600, 2019
Yuqiang Wu, Pietro Balatti, Marta Lorenzini, Fei Zhao, Wan- soo Kim, and Arash Ajoudani. A teleoperation interface for loco-manipulation control of mobile collaborative robotic as- sistant.IEEE Robotics and Automation Letters (RA-L), 4(4): 3593–3600, 2019. 3
2019
-
[46]
Relmogen: Integrat- ing motion generation in reinforcement learning for mobile manipulation
Fei Xia, Chengshu Li, Roberto Mart ´ın-Mart´ın, Or Litany, Alexander Toshev, and Silvio Savarese. Relmogen: Integrat- ing motion generation in reinforcement learning for mobile manipulation. InInternational Conference on Robotics and Automation (ICRA), 2021. 2
2021
-
[47]
Sapien: A simulated part-based interactive 10 environment
Fanbo Xiang, Yuzhe Qin, Kaichun Mo, Yikuan Xia, Hao Zhu, Fangchen Liu, Minghua Liu, Hanxiao Jiang, Yifu Yuan, He Wang, et al. Sapien: A simulated part-based interactive 10 environment. InConference on Computer Vision and Pattern Recognition (CVPR), 2020. 6, 8, A2
2020
-
[48]
Moma-force: Visual-force imitation for real-world mobile manipulation
Taozheng Yang, Ya Jing, Hongtao Wu, Jiafeng Xu, Kuankuan Sima, Guangzeng Chen, Qie Sima, and Tao Kong. Moma-force: Visual-force imitation for real-world mobile manipulation. InInternational Conference on Intelligent Robots and Systems (IROS), 2023. 3
2023
-
[49]
3d diffusion policy: Gener- alizable visuomotor policy learning via simple 3d represen- tations
Yanjie Ze, Gu Zhang, Kangning Zhang, Chenyuan Hu, Muhan Wang, and Huazhe Xu. 3d diffusion policy: Gener- alizable visuomotor policy learning via simple 3d represen- tations. InRobotics: Science and Systems (RSS), 2024. 2, 7, 8, A2, A6, A10
2024
-
[50]
M3bench: Bench- marking whole-body motion generation for mobile manipu- lation in 3d scenes.IEEE Robotics and Automation Letters (RA-L), 2025
Zeyu Zhang, Sixu Yan, Muzhi Han, Zaijin Wang, Xinggang Wang, Song-Chun Zhu, and Hangxin Liu. M3bench: Bench- marking whole-body motion generation for mobile manipu- lation in 3d scenes.IEEE Robotics and Automation Letters (RA-L), 2025. 1, 2 11 A. Additional Method and Implementation De- tails This section provides additional implementation details of the ...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.