Recognition: unknown
Calibration-Aware Policy Optimization for Reasoning LLMs
Pith reviewed 2026-05-10 15:35 UTC · model grok-4.3
The pith
CAPO uses a logistic AUC surrogate to make policy optimization aware of uncertainty, jointly boosting calibration and accuracy in LLM reasoning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
GRPO-style algorithms degrade relative calibration because their uncertainty-agnostic advantage estimation inevitably misaligns optimization gradients with calibration. CAPO addresses this by adopting a logistic AUC surrogate loss that is theoretically consistent and admits regret bound, enabling uncertainty-aware advantage estimation, and by incorporating a noise masking mechanism that achieves stable learning dynamics jointly optimizing calibration and accuracy.
What carries the argument
logistic AUC surrogate loss that enables uncertainty-aware advantage estimation in policy optimization
If this is right
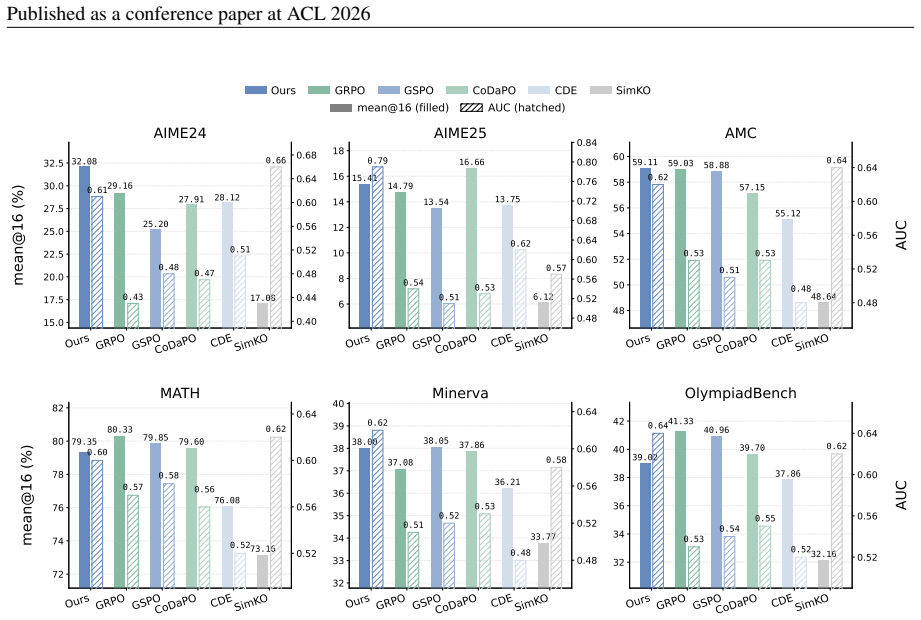
- CAPO improves calibration by up to 15% on multiple mathematical reasoning benchmarks while keeping accuracy comparable to or better than GRPO.
- Models trained with CAPO gain up to 5% accuracy on downstream inference-time scaling tasks.
- When allowed to abstain on low-confidence outputs, CAPO achieves a Pareto-optimal precision-coverage trade-off.
- The joint optimization prevents the accuracy-calibration trade-off that appears in prior approaches.
Where Pith is reading between the lines
- The same uncertainty-aware loss could be plugged into other reinforcement-learning loops for LLMs to reduce overconfidence without task-specific redesign.
- Better calibration opens a practical path to safer deployment by letting models abstain more reliably rather than hallucinating.
- Testing whether the noise-masking component remains necessary on larger models would clarify the minimal set of changes needed for stable training.
Load-bearing premise
The degradation in calibration under GRPO-style algorithms stems specifically from uncertainty-agnostic advantage estimation.
What would settle it
An experiment that measures gradient alignment in GRPO and finds no misalignment with calibration, or a faithful reimplementation of CAPO that shows no AUC improvement.
Figures








read the original abstract
Group Relative Policy Optimization (GRPO) enhances LLM reasoning but often induces overconfidence, where incorrect responses yield lower perplexity than correct ones, degrading relative calibration as described by the Area Under the Curve (AUC). Existing approaches either yield limited improvements in calibration or sacrifice gains in reasoning accuracy. We first prove that this degradation in GRPO-style algorithms stems from their uncertainty-agnostic advantage estimation, which inevitably misaligns optimization gradients with calibration. This leads to improved accuracy at the expense of degraded calibration. We then propose Calibration-Aware Policy Optimization (CAPO). It adopts a logistic AUC surrogate loss that is theoretically consistent and admits regret bound, enabling uncertainty-aware advantage estimation. By further incorporating a noise masking mechanism, CAPO achieves stable learning dynamics that jointly optimize calibration and accuracy. Experiments on multiple mathematical reasoning benchmarks show that CAPO-1.5B significantly improves calibration by up to 15% while achieving accuracy comparable to or better than GRPO, and further boosts accuracy on downstream inference-time scaling tasks by up to 5%. Moreover, when allowed to abstain under low-confidence conditions, CAPO achieves a Pareto-optimal precision-coverage trade-off, highlighting its practical value for hallucination mitigation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that GRPO-style algorithms degrade calibration in reasoning LLMs because their uncertainty-agnostic advantage estimation inevitably misaligns optimization gradients with calibration, leading to improved accuracy at the cost of overconfidence (measured via AUC). It proves this degradation, then introduces CAPO, which replaces the advantage estimator with a logistic AUC surrogate loss that is theoretically consistent and admits a regret bound, augmented by a noise masking mechanism for stable joint optimization of calibration and accuracy. Experiments on mathematical reasoning benchmarks report up to 15% calibration gains with accuracy comparable or superior to GRPO, plus up to 5% gains on downstream scaling tasks and improved Pareto precision-coverage when abstaining under low confidence.
Significance. If the central proof holds under standard GRPO formulations and the empirical results are reproducible, the work would be significant for LLM reasoning reliability: it provides a theoretically grounded mechanism to mitigate overconfidence without accuracy trade-offs, with direct applicability to hallucination mitigation via confidence-aware abstention. The regret-bound surrogate and joint optimization are strengths that distinguish it from prior calibration fixes.
major comments (2)
- [Theoretical analysis / proof of GRPO degradation] The proof that GRPO's uncertainty-agnostic advantage estimation 'inevitably misaligns optimization gradients with calibration' (stated in the abstract and presumably detailed in the theoretical section): the manuscript asserts this as the root cause but supplies no derivation details, explicit assumptions on the reward model or uncertainty distribution, or verification that misalignment is unavoidable rather than dependent on stylized conditions. This is load-bearing for the motivation of CAPO and the interpretation of the reported 15% calibration gains.
- [Experiments] Experimental claims (abstract and results section): up to 15% calibration improvement, accuracy parity or gains, and 5% downstream scaling benefits are reported, yet the manuscript provides no named benchmarks, baseline implementations, full protocol, or error bars. This undermines assessment of whether the AUC surrogate and noise masking deliver the claimed joint optimization under realistic reasoning reward models.
minor comments (2)
- [Abstract] The abstract refers to 'multiple mathematical reasoning benchmarks' without naming them (e.g., GSM8K, MATH); explicit listing would aid clarity and reproducibility.
- [Method] Notation for the logistic AUC surrogate and regret bound could be clarified with an explicit equation reference when first introduced, to make the 'theoretically consistent' claim easier to trace.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and constructive comments, which help clarify the presentation of our theoretical and empirical contributions. We address each major comment point by point below, indicating the revisions we will make.
read point-by-point responses
-
Referee: The proof that GRPO's uncertainty-agnostic advantage estimation 'inevitably misaligns optimization gradients with calibration' (stated in the abstract and presumably detailed in the theoretical section): the manuscript asserts this as the root cause but supplies no derivation details, explicit assumptions on the reward model or uncertainty distribution, or verification that misalignment is unavoidable rather than dependent on stylized conditions. This is load-bearing for the motivation of CAPO and the interpretation of the reported 15% calibration gains.
Authors: We thank the referee for this observation. The derivation of the misalignment is given in Section 3 under the assumptions of a binary correctness-based reward model and an uncertainty-agnostic advantage estimator matching the standard GRPO formulation. The proof shows that the expected gradient for the calibration (AUC) objective opposes the accuracy objective. To improve accessibility and address the concern, we will expand Section 3 with a complete step-by-step derivation, explicitly enumerate all assumptions, and add a remark clarifying the conditions under which the misalignment holds in standard GRPO settings. revision: yes
-
Referee: Experimental claims (abstract and results section): up to 15% calibration improvement, accuracy parity or gains, and 5% downstream scaling benefits are reported, yet the manuscript provides no named benchmarks, baseline implementations, full protocol, or error bars. This undermines assessment of whether the AUC surrogate and noise masking deliver the claimed joint optimization under realistic reasoning reward models.
Authors: We appreciate the referee noting the need for greater experimental transparency. The reported results use the GSM8K, MATH, and AIME benchmarks with GRPO baselines implemented per the original GRPO reference; full training protocols, hyperparameters, and error bars (from three random seeds) appear in the appendix. In the revision we will name the benchmarks in the main text, add a summary table of results with error bars, and briefly restate the protocol to allow direct assessment of the joint optimization under the described reward models. revision: yes
Circularity Check
Derivation chain self-contained; no reductions to inputs by construction
full rationale
The provided abstract and context present a proof that GRPO degrades calibration via uncertainty-agnostic advantage estimation, followed by CAPO using a logistic AUC surrogate loss claimed to be theoretically consistent with a regret bound. No equations, definitions, or self-citations in the visible text reduce the central proof or surrogate to fitted parameters, renamed inputs, or load-bearing self-references. The AUC degradation is described as an observed empirical pattern, and the surrogate is introduced as an independent theoretical fix rather than a post-hoc fit. This matches the default case of a non-circular paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Degradation in GRPO-style algorithms stems from uncertainty-agnostic advantage estimation that misaligns gradients with calibration
Reference graph
Works this paper leans on
- [1]
- [2]
-
[3]
Nontawat Charoenphakdee, Jongyeong Lee, and Masashi Sugiyama. 2019. http://proceedings.mlr.press/v97/charoenphakdee19a/charoenphakdee19a.pdf On symmetric losses for learning from corrupted labels . In International Conference on Machine Learning, pages 961--970
2019
- [4]
-
[5]
Runpeng Dai, Linfeng Song, Haolin Liu, Zhenwen Liang, Dian Yu, Haitao Mi, Zhaopeng Tu, Rui Liu, Tong Zheng, Hongtu Zhu, and 1 others. 2025. https://arxiv.org/pdf/2509.09675? Cde: Curiosity-driven exploration for efficient reinforcement learning in large language models . arXiv preprint arXiv:2509.09675
- [6]
-
[7]
Qi Feng, Yihong Liu, and Hinrich Sch \"u tze. 2025. https://aclanthology.org/2025.acl-srw.15.pdf Your pretrained model tells the difficulty itself: A self-adaptive curriculum learning paradigm for natural language understanding . In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 4: Student Research Workshop...
2025
-
[8]
Wei Gao, Rong Jin, Shenghuo Zhu, and Zhi-Hua Zhou. 2013. http://proceedings.mlr.press/v28/gao13.pdf One-pass auc optimization . In International Conference on Machine Learning, pages 906--914. PMLR
2013
- [9]
-
[10]
Jiahui Geng, Fengyu Cai, Yuxia Wang, Heinz Koeppl, Preslav Nakov, and Iryna Gurevych. 2024. https://aclanthology.org/2024.naacl-long.366.pdf A survey of confidence estimation and calibration in large language models . In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Techno...
2024
-
[11]
Chaoqun He, Renjie Luo, Yuzhuo Bai, Shengding Hu, Zhen Thai, Junhao Shen, Jinyi Hu, Xu Han, Yujie Huang, Yuxiang Zhang, and 1 others. 2024. https://aclanthology.org/2024.acl-long.211.pdf Olympiadbench: A challenging benchmark for promoting agi with olympiad-level bilingual multimodal scientific problems . In Proceedings of the 62nd Annual Meeting of the A...
2024
-
[12]
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. 2021. https://arxiv.org/pdf/2103.03874 Measuring mathematical problem solving with the math dataset . arXiv preprint arXiv:2103.03874
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[13]
Saurav Kadavath, Tom Conerly, Amanda Askell, Tom Henighan, Dawn Drain, Ethan Perez, Nicholas Schiefer, Zac Hatfield-Dodds, Nova DasSarma, Eli Tran-Johnson, and 1 others. 2022. https://arxiv.org/pdf/2207.05221 Language models (mostly) know what they know . arXiv preprint arXiv:2207.05221
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[14]
Adam Tauman Kalai, Ofir Nachum, Santosh S Vempala, and Edwin Zhang. 2025. https://arxiv.org/pdf/2509.04664 Why language models hallucinate . arXiv preprint arXiv:2509.04664
work page internal anchor Pith review arXiv 2025
-
[15]
Wojciech Kotlowski, Krzysztof J Dembczynski, and Eyke Huellermeier. 2011. http://www.icml-2011.org/papers/567_icmlpaper.pdf Bipartite ranking through minimization of univariate loss . In Proceedings of the 28th International Conference on Machine Learning (ICML-11), pages 1113--1120
2011
-
[16]
Aitor Lewkowycz, Anders Andreassen, David Dohan, Ethan Dyer, Henryk Michalewski, Vinay Ramasesh, Ambrose Slone, Cem Anil, Imanol Schlag, Theo Gutman-Solo, and 1 others. 2022. https://proceedings.neurips.cc/paper_files/paper/2022/file/18abbeef8cfe9203fdf9053c9c4fe191-Paper-Conference.pdf Solving quantitative reasoning problems with language models . Advanc...
2022
-
[17]
Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harrison Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. 2023. https://openreview.net/pdf?id=v8L0pN6EOi Let's verify step by step . In The Twelfth International Conference on Learning Representations
2023
-
[18]
Charles X Ling, Jin Huang, Harry Zhang, and 1 others. 2003. http://www.cs.unb.ca/ hzhang/publications/ijcai03.pdf Auc: a statistically consistent and more discriminating measure than accuracy . In International Joint Conference on Artificial Intelligence, volume 3, pages 519--524
2003
- [19]
-
[20]
Zichen Liu, Changyu Chen, Wenjun Li, Penghui Qi, Tianyu Pang, Chao Du, Wee Sun Lee, and Min Lin. 2025 b . https://arxiv.org/pdf/2503.20783 Understanding r1-zero-like training: A critical perspective . arXiv preprint arXiv:2503.20783
work page internal anchor Pith review arXiv 2025
-
[21]
Michael Luo, Sijun Tan, Justin Wong, Xiaoxiang Shi, William Y Tang, Manan Roongta, Colin Cai, Jeffrey Luo, Tianjun Zhang, Li Erran Li, and 1 others. 2025 a . Deepscaler: Surpassing o1-preview with a 1.5 b model by scaling rl. Notion Blog
2025
- [22]
-
[23]
Potsawee Manakul, Adian Liusie, and Mark Gales. 2023. https://aclanthology.org/2023.emnlp-main.557.pdf Selfcheckgpt: Zero-resource black-box hallucination detection for generative large language models . In Proceedings of the 2023 conference on empirical methods in natural language processing, pages 9004--9017
2023
- [24]
-
[25]
Thomas Savage, John Wang, Robert Gallo, Abdessalem Boukil, Vishwesh Patel, Seyed Amir Ahmad Safavi-Naini, Ali Soroush, and Jonathan H Chen. 2025. https://academic.oup.com/jamia/article-pdf/32/1/139/61202176/ocae254.pdf Large language model uncertainty proxies: discrimination and calibration for medical diagnosis and treatment . Journal of the American Med...
2025
-
[26]
John Schulman, Sergey Levine, Pieter Abbeel, Michael Jordan, and Philipp Moritz. 2015. http://proceedings.mlr.press/v37/schulman15.pdf Trust region policy optimization . In International Conference on Machine Learning, pages 1889--1897. PMLR
2015
-
[27]
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. 2017. https://arxiv.org/abs/1707.06347 Proximal policy optimization algorithms . Preprint, arXiv:1707.06347
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[28]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, and 1 others. 2024. https://arxiv.org/pdf/2402.03300 Deepseekmath: Pushing the limits of mathematical reasoning in open language models . arXiv preprint arXiv:2402.03300
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[29]
Josefa Lia Stoisser, Marc Boubnovski Martell, Lawrence Phillips, Gianluca Mazzoni, Lea M rch Harder, Philip Torr, Jesper Ferkinghoff-Borg, Kaspar Martens, and Julien Fauqueur. 2025. https://arxiv.org/pdf/2509.02401 Towards agents that know when they don't know: Uncertainty as a control signal for structured reasoning . arXiv preprint arXiv:2509.02401
-
[30]
Sree Harsha Tanneru, Chirag Agarwal, and Himabindu Lakkaraju. 2024. https://proceedings.mlr.press/v238/harsha-tanneru24a/harsha-tanneru24a.pdf Quantifying uncertainty in natural language explanations of large language models . In International Conference on Artificial Intelligence and Statistics, pages 1072--1080. PMLR
2024
- [31]
-
[32]
Roman Vashurin, Maiya Goloburda, Albina Ilina, Aleksandr Rubashevskii, Preslav Nakov, Artem Shelmanov, and Maxim Panov. 2025. https://arxiv.org/pdf/2502.04964 Uncertainty quantification for llms through minimum bayes risk: Bridging confidence and consistency . arXiv preprint arXiv:2502.04964
- [33]
- [34]
-
[35]
Bingbing Wen, Chenjun Xu, Robert Wolfe, Lucy Lu Wang, Bill Howe, and 1 others. 2024. https://openreview.net/pdf?id=y9UdO5cmHs Mitigating overconfidence in large language models: A behavioral lens on confidence estimation and calibration . In NeurIPS 2024 Workshop on Behavioral Machine Learning
2024
- [36]
-
[37]
Miao Xiong, Zhiyuan Hu, Xinyang Lu, Yifei Li, Jie Fu, Junxian He, and Bryan Hooi. 2024. https://arxiv.org/abs/2306.13063 Can llms express their uncertainty? an empirical evaluation of confidence elicitation in llms . Preprint, arXiv:2306.13063
work page internal anchor Pith review arXiv 2024
-
[38]
An Yang, Beichen Zhang, Binyuan Hui, Bofei Gao, Bowen Yu, Chengpeng Li, Dayiheng Liu, Jianhong Tu, Jingren Zhou, Junyang Lin, Keming Lu, Mingfeng Xue, Runji Lin, Tianyu Liu, Xingzhang Ren, and Zhenru Zhang. 2024 a . https://arxiv.org/abs/2409.12122 Qwen2.5-math technical report: Toward mathematical expert model via self-improvement . Preprint, arXiv:2409.12122
work page internal anchor Pith review arXiv 2024
-
[39]
Daniel Yang, Yao-Hung Hubert Tsai, and Makoto Yamada. 2024 b . https://arxiv.org/abs/2412.14737 On verbalized confidence scores for llms . Preprint, arXiv:2412.14737
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[40]
Tianbao Yang and Yiming Ying. 2022. https://dl.acm.org/doi/pdf/10.1145/3554729 Auc maximization in the era of big data and ai: A survey . ACM computing surveys, 55(8):1--37
-
[41]
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, and 1 others. 2025. https://arxiv.org/pdf/2503.14476 Dapo: An open-source llm reinforcement learning system at scale . arXiv preprint arXiv:2503.14476
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[42]
Zhuoning Yuan, Yan Yan, Milan Sonka, and Tianbao Yang. 2021. https://openaccess.thecvf.com/content/ICCV2021/papers/Yuan_Large-Scale_Robust_Deep_AUC_Maximization_A_New_Surrogate_Loss_and_ICCV_2021_paper.pdf Large-scale robust deep auc maximization: A new surrogate loss and empirical studies on medical image classification . In Proceedings of the IEEE/CVF I...
2021
-
[43]
Yang Yue, Zhiqi Chen, Rui Lu, Andrew Zhao, Zhaokai Wang, Shiji Song, and Gao Huang. 2025. https://arxiv.org/pdf/2504.13837 Does reinforcement learning really incentivize reasoning capacity in llms beyond the base model? arXiv preprint arXiv:2504.13837
work page internal anchor Pith review arXiv 2025
- [44]
-
[45]
Peilin Zhao, Steven CH Hoi, Rong Jin, and Tianbo Yang. 2011. https://ink.library.smu.edu.sg/cgi/viewcontent.cgi?article=3351&context=sis_research Online auc maximization
2011
-
[46]
Chujie Zheng, Shixuan Liu, Mingze Li, Xiong-Hui Chen, Bowen Yu, Chang Gao, Kai Dang, Yuqiong Liu, Rui Men, An Yang, Jingren Zhou, and Junyang Lin. 2025. https://arxiv.org/abs/2507.18071 Group sequence policy optimization . Preprint, arXiv:2507.18071
work page internal anchor Pith review arXiv 2025
-
[47]
Zhanke Zhou, Xiangyu Lu, Chentao Cao, Brando Miranda, Tongliang Liu, Bo Han, and Sanmi Koyejo. 2025 a . https://openreview.net/pdf?id=O9CYgZFtm7 Codapo: Confidence and difficulty-adaptive policy optimization for post-training language models . In 2nd AI for Math Workshop@ ICML 2025
2025
- [48]
- [49]
-
[50]
online" 'onlinestring :=
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[51]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.