Recognition: unknown
Information-Theoretic Optimization for Task-Adapted Compressed Sensing Magnetic Resonance Imaging
Pith reviewed 2026-05-10 14:56 UTC · model grok-4.3
The pith
Maximizing mutual information between undersampled k-space data and clinical tasks enables probabilistic inference and flexible sampling in CS-MRI.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We formalize the task-adapted CS-MRI problem as maximizing mutual information between undersampled k-space measurements and clinical tasks to enable probabilistic inference for uncertainty prediction. Using amortized optimization and variational bounds on this mutual information, sampling, reconstruction, and task-inference models are jointly optimized in a single end-to-end framework. This supports flexible control over sampling ratios and unifies two clinical scenarios: joint task and reconstruction, where reconstruction aids task performance, and task implementation with suppressed reconstruction for privacy protection.
What carries the argument
Variational lower bounds on mutual information between undersampled k-space measurements and clinical task outputs, jointly optimized with sampling masks, reconstruction, and task networks via amortization to enable single-model adaptation across sampling ratios and scenarios.
If this is right
- A single trained model controls sampling ratios on demand without retraining for each ratio or application.
- Probabilistic outputs provide uncertainty estimates for clinical tasks such as segmentation.
- The same framework handles both reconstruction-assisted diagnosis and privacy-preserving task execution without full image recovery.
- Accuracy on standard metrics like Dice remains competitive while better matching the ground-truth posterior distribution according to generalized energy distance.
Where Pith is reading between the lines
- Dynamic adjustment of MRI acquisition length could be performed in real time based on the specific diagnostic question posed to the scanner.
- Privacy-preserving mode might integrate with federated or edge-computing setups where only task outputs are transmitted.
- The information-theoretic approach could transfer to other undersampled imaging modalities such as CT or ultrasound for task-specific acquisition.
- Clinical trials could check whether the uncertainty maps reduce missed diagnoses by flagging ambiguous cases for additional scans.
Load-bearing premise
Tractable variational bounds on mutual information between undersampled k-space measurements and clinical tasks will yield sampling patterns and models that generalize to real clinical uncertainty and outperform deterministic baselines without introducing optimization artifacts.
What would settle it
A test on held-out clinical data where the model's uncertainty estimates show no correlation with actual diagnostic variability among experts, or where reconstruction and task performance drop sharply for sampling ratios not seen during training.
Figures







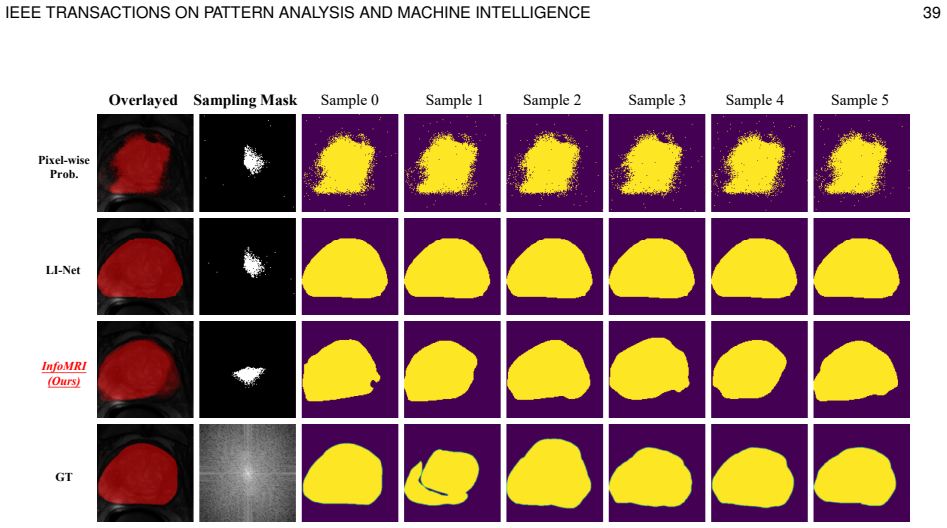
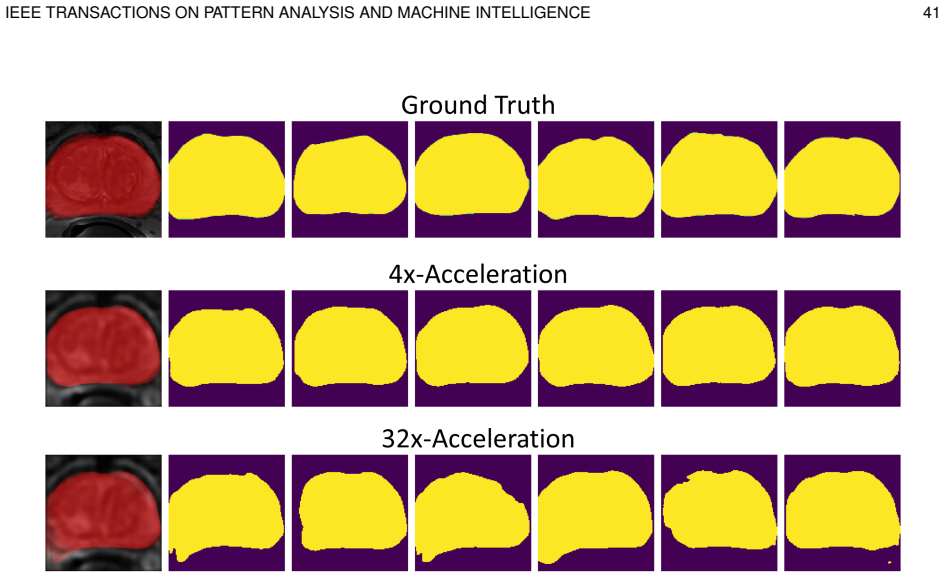






read the original abstract
Task-adapted compressed sensing magnetic resonance imaging (CS-MRI) is emerging to address the specific demands of downstream clinical tasks with significantly fewer k-space measurements than required by Nyquist sampling. However, existing task-adapted CS-MRI methods suffer from the uncertainty problem for medical diagnosis and cannot achieve adaptive sampling in end-to-end optimization with reconstruction or clinical tasks. To address these limitations, we propose the first task-adapted CS-MRI from the information-theoretic perspective to simultaneously achieve probabilistic inference for uncertainty prediction and adapt to arbitrary sampling ratios and versatile clinical applications. Specifically, we formalize the task-adapted CS-MRI optimization problem by maximizing the mutual information between undersampled k-space measurements and clinical tasks to enable probabilistic inference for addressing the uncertainty problem. We leverage amortized optimization and construct tractable variational bounds for mutual information to jointly optimize sampling, reconstruction, and task-inference models, which enables flexible sampling ratio control using a single end-to-end trained model. Furthermore, the proposed framework addresses two kinds of distinct clinical scenarios within a unified approach, i.e., i) joint task and reconstruction, where reconstruction serves as an auxiliary process to enhance task performance; and ii) task implementation with suppressed reconstruction, applicable for privacy protection. Extensive experiments on large-scale MRI datasets demonstrate that the proposed framework achieves highly competitive performance on standard metrics like Dice compared to deterministic counterpart but provides better distribution matching to the ground-truth posterior distribution as measured by the generalized energy distance (GED).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes the first information-theoretic framework for task-adapted compressed sensing MRI (CS-MRI). It formalizes the problem as maximizing mutual information between undersampled k-space measurements and downstream clinical tasks, using amortized optimization with tractable variational bounds to jointly train sampling masks, reconstruction networks, and task-inference models. This enables a single model to adapt to arbitrary sampling ratios, provide probabilistic uncertainty estimates, and handle two scenarios (joint reconstruction+task or task-only with suppressed reconstruction for privacy). Experiments on large-scale MRI datasets show competitive Dice scores versus deterministic baselines plus improved posterior matching via generalized energy distance (GED).
Significance. If the variational bounds are sufficiently tight and the amortized optimization produces sampling patterns that truly maximize task-relevant information rather than bound artifacts, the approach would be significant: it offers a unified, ratio-adaptive, uncertainty-aware alternative to existing task-adapted CS-MRI methods, with direct relevance to clinical workflows requiring both diagnostic accuracy and calibrated uncertainty. The explicit handling of privacy-preserving (reconstruction-suppressed) and auxiliary-reconstruction modes is a practical strength.
major comments (2)
- [§3] §3 (Method), variational MI bound derivation: the central claim that maximizing the tractable variational lower bound yields sampling patterns and models that generalize to real clinical uncertainty and outperform deterministic baselines rests on the bound being tight enough to avoid optimizing artifacts rather than true MI. No diagnostic of the bound gap (e.g., via tighter estimators, Monte-Carlo estimates on held-out data, or sensitivity to variational family choice) is reported; this is load-bearing because loose bounds in high-dimensional k-space are known to bias the learned masks.
- [§4] §4 (Experiments), GED and sampling-ratio adaptation results: the reported GED improvements and single-model ratio flexibility are presented as evidence for calibrated probabilistic inference, yet no ablation isolates the contribution of the MI objective versus the amortized architecture, nor tests whether the learned masks remain optimal when the variational family is altered. Without these controls the cross-ratio and uncertainty claims cannot be fully attributed to the information-theoretic formulation.
minor comments (2)
- Notation for the variational distributions and the amortized sampling network is introduced without an explicit table of symbols; this makes the joint optimization objective harder to follow across equations.
- The abstract and introduction state that the method addresses 'two kinds of distinct clinical scenarios' but the precise loss weighting between reconstruction and task terms in each scenario is only described at high level; a short pseudocode or explicit hyper-parameter table would improve reproducibility.
Simulated Author's Rebuttal
Thank you for the constructive feedback on our manuscript. We appreciate the referee's careful reading and address each major comment below, proposing specific revisions to strengthen the work where appropriate.
read point-by-point responses
-
Referee: [§3] §3 (Method), variational MI bound derivation: the central claim that maximizing the tractable variational lower bound yields sampling patterns and models that generalize to real clinical uncertainty and outperform deterministic baselines rests on the bound being tight enough to avoid optimizing artifacts rather than true MI. No diagnostic of the bound gap (e.g., via tighter estimators, Monte-Carlo estimates on held-out data, or sensitivity to variational family choice) is reported; this is load-bearing because loose bounds in high-dimensional k-space are known to bias the learned masks.
Authors: We agree that the tightness of the variational bound is a critical point for the validity of the claims. The manuscript employs the standard variational lower bound on mutual information (derived via amortized variational inference as in standard information-theoretic frameworks), which is tractable and enables end-to-end optimization. While the large-scale experimental results (competitive Dice scores and superior GED) provide indirect support that the bound is effective in practice, we acknowledge that explicit diagnostics were not included. In the revised manuscript, we will add a new subsection with Monte-Carlo estimates of the bound gap on held-out data, comparisons to tighter estimators where feasible, and sensitivity analysis across variational family choices to confirm that the learned masks optimize true task-relevant information rather than bound artifacts. revision: yes
-
Referee: [§4] §4 (Experiments), GED and sampling-ratio adaptation results: the reported GED improvements and single-model ratio flexibility are presented as evidence for calibrated probabilistic inference, yet no ablation isolates the contribution of the MI objective versus the amortized architecture, nor tests whether the learned masks remain optimal when the variational family is altered. Without these controls the cross-ratio and uncertainty claims cannot be fully attributed to the information-theoretic formulation.
Authors: We concur that additional controls would better isolate the role of the information-theoretic objective. The reported results compare the full framework against deterministic baselines and demonstrate ratio-adaptive behavior and improved posterior matching via GED, but they do not explicitly ablate the MI term or vary the variational family. To address this, the revised version will include new ablation experiments: (i) a variant trained without the MI maximization (replacing it with a standard reconstruction loss) to quantify its contribution to GED and mask quality, and (ii) retraining with an alternative variational family to verify that the learned sampling patterns remain stable and optimal. These will be added to §4 alongside the existing results. revision: yes
Circularity Check
No circularity: derivation uses standard variational MI maximization without self-referential reduction
full rationale
The paper formalizes task-adapted CS-MRI as maximizing mutual information between undersampled k-space and clinical tasks, then applies amortized optimization with tractable variational bounds to jointly train sampling, reconstruction, and task models. This is a conventional information-theoretic construction that does not define any quantity in terms of itself, rename a fitted parameter as a prediction, or rely on load-bearing self-citations for uniqueness. The reported gains on Dice and GED are empirical comparisons to baselines rather than tautological outputs of the same fit. No equations or steps in the provided abstract reduce the claimed results to their inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Mutual information between undersampled k-space and clinical tasks can be bounded variationally in a tractable manner suitable for end-to-end gradient-based optimization.
Reference graph
Works this paper leans on
-
[1]
Deep ADMM-Net for compressive sensing MRI,
J. Sun, H. Li, Z. Xuet al., “Deep ADMM-Net for compressive sensing MRI,” inAdv. Neural Inf. Process. Syst. 29, 2016, pp. 10–18
2016
-
[2]
ISTA-Net: Interpretable optimization-inspired deep network for image compressive sensing,
J. Zhang and B. Ghanem, “ISTA-Net: Interpretable optimization-inspired deep network for image compressive sensing,” in2018 IEEE Conf. Comput. Vis. Pattern Recognit., 2018, pp. 1828–1837
2018
-
[3]
End-to-end variational networks for accelerated MRI reconstruction,
A. Sriramet al., “End-to-end variational networks for accelerated MRI reconstruction,” inInt. Conf. Med. Image Comput. Comput.-Assist. Interv.–MICCAI 2020, 2020, pp. 64–73
2020
-
[4]
Deep probabilistic subsampling for task-adaptive com- pressed sensing,
I. A. Huijben, B. S. Veeling, and R. J. van Sloun, “Deep probabilistic subsampling for task-adaptive com- pressed sensing,” in8th Int. Conf. Learn. Rep., 2020. [Online]. Available: https://research.tue.nl/nl/publications/ 69ddddef-ed02-4293-830a-2cb4e1ec35b3
2020
-
[5]
J-MoDL: Joint model-based deep learning for optimized sampling and reconstruction,
H. K. Aggarwal and M. Jacob, “J-MoDL: Joint model-based deep learning for optimized sampling and reconstruction,”IEEE J. Sel. Topics Signal Process., vol. 14, no. 6, pp. 1151–1162, 2020
2020
-
[6]
Deep-learning-based optimization of the under-sampling pattern in MRI,
C. D. Bahadiret al., “Deep-learning-based optimization of the under-sampling pattern in MRI,”IEEE Trans. Comput. Imag., vol. 6, pp. 1139–1152, 2020
2020
-
[7]
One network to solve them all: A sequential multi-task joint learning network framework for MR imaging pipeline,
Z. Wanget al., “One network to solve them all: A sequential multi-task joint learning network framework for MR imaging pipeline,” inInt. Workshop Mach. Learn. Med. Image Recon., 2021, pp. 76–85
2021
-
[8]
End-to-end sequential sampling and reconstruction for MRI,
T. Yinet al., “End-to-end sequential sampling and reconstruction for MRI,” inML4H@ NeurIPS, 2021, pp. 261–281
2021
-
[9]
PUERT: Probabilistic under-sampling and explicable reconstruction network for CS-MRI,
J. Xie, J. Zhang, Y. Zhang, and X. Ji, “PUERT: Probabilistic under-sampling and explicable reconstruction network for CS-MRI,”IEEE J. Sel. Topics Signal Process., vol. 16, no. 4, pp. 737–749, 2022
2022
-
[10]
Reducing uncertainty in undersampled MRI reconstruction with active acquisition,
Z. Zhanget al., “Reducing uncertainty in undersampled MRI reconstruction with active acquisition,” in2019 IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2019, pp. 2049–2058
2019
-
[11]
Experimental design for MRI by greedy policy search,
T. Bakker, H. van Hoof, and M. Welling, “Experimental design for MRI by greedy policy search,” inAdv. Neural Inf. Process. Syst. 33, 2020, pp. 18 954–18 966
2020
-
[12]
Active MR k-space sampling with reinforcement learning,
L. Pineda, S. Basu, A. Romero, R. Calandra, and M. Drozdzal, “Active MR k-space sampling with reinforcement learning,” inInt. Conf. Med. Image Comput. Comput.-Assist. Interv.–MICCAI 2020, 2020, pp. 23–33
2020
-
[13]
Active deep probabilistic subsampling,
H. Van Gorp, I. Huijben, B. S. Veeling, N. Pezzotti, and R. J. Van Sloun, “Active deep probabilistic subsampling,” inProc. 38th Int. Conf. Mach. Learn., 2021, pp. 10 509–10 518. IEEE TRANSACTIONS ON PATTERN ANAL YSIS AND MACHINE INTELLIGENCE 64
2021
-
[14]
Stochastic segmentation networks: Modelling spatially correlated aleatoric uncertainty,
M. Monteiroet al., “Stochastic segmentation networks: Modelling spatially correlated aleatoric uncertainty,” in Adv. Neural Inf. Process. Syst. 33, 2020, pp. 12 756–12 767
2020
-
[15]
Cardiac MR segmentation from undersampled k-space using deep latent representation learning,
J. Schlemperet al., “Cardiac MR segmentation from undersampled k-space using deep latent representation learning,” inInt. Conf. Med. Image Comput. Comput.-Assist. Interv.–MICCAI 2018, 2018, pp. 259–267
2018
-
[16]
Learning task-specific strategies for accelerated MRI,
Z. Wu, T. Yin, Y. Sun, R. Frost, A. van der Kouwe, A. V . Dalca, and K. L. Bouman, “Learning task-specific strategies for accelerated MRI,”IEEE Trans. Comput. Imaging, vol. 10, pp. 1040–1054, 2024
2024
-
[17]
Application-driven MRI: joint reconstruction and segmentation from undersampled MRI data,
J. Caballero, W. Bai, A. N. Price, D. Rueckert, and J. V . Hajnal, “Application-driven MRI: joint reconstruction and segmentation from undersampled MRI data,” inInt. Conf. Med. Image Comput. Comput.-Assist. Interv.–MICCAI 2014, 2014, pp. 106–113
2014
-
[18]
PHiSeg: Capturing uncertainty in medical image segmentation,
C. F. Baumgartneret al., “PHiSeg: Capturing uncertainty in medical image segmentation,” inInt. Conf. Med. Image Comput. Comput.-Assist. Interv.–MICCAI 2019, 2019, pp. 119–127
2019
-
[19]
T. M. Cover and J. A. Thomas,Elements of Information Theory. John Wiley & Sons, 2005
2005
-
[20]
Information-theoretic compressive measurement design,
L. Wanget al., “Information-theoretic compressive measurement design,”IEEE Trans. Pattern Anal. Mach. Intell., vol. 39, no. 6, pp. 1150–1164, 2016
2016
-
[21]
Tutorial on amortized optimization,
B. Amoset al., “Tutorial on amortized optimization,”Found Trends® Mach Learn, vol. 16, no. 5, pp. 592–732, 2023
2023
-
[22]
TransCL: Transformer makes strong and flexible compressive learning,
C. Mou and J. Zhang, “TransCL: Transformer makes strong and flexible compressive learning,”IEEE Trans. Pattern Anal. Mach. Intell., vol. 45, no. 4, pp. 5236–5251, 2023
2023
-
[23]
On learning adaptive acquisition policies for undersampled multi-coil MRI reconstruction,
T. Bakkeret al., “On learning adaptive acquisition policies for undersampled multi-coil MRI reconstruction,” in Int. Conf. Med. Imag. Deep Learn., 2022, pp. 63–85
2022
-
[24]
Compressed sensing and Bayesian experimental design,
M. W. Seeger and H. Nickisch, “Compressed sensing and Bayesian experimental design,” inProc. 25th Int. Conf. Mach. Learn., 2008, pp. 912–919
2008
-
[25]
Bayesian compressive sensing,
S. Ji, Y. Xue, and L. Carin, “Bayesian compressive sensing,”IEEE Trans. Signal Process., vol. 56, no. 6, pp. 2346– 2356, 2008
2008
-
[26]
Bayesian experimental design of magnetic resonance imaging sequences,
H. Nickisch, R. Pohmann, B. Sch ¨olkopf, and M. Seeger, “Bayesian experimental design of magnetic resonance imaging sequences,” inAdv. Neural Inf. Process. Syst. 21, 2008, pp. 1441–1448
2008
-
[27]
Uncertainty autoencoders: Learning compressed representations via variational information maximization,
A. Grover and S. Ermon, “Uncertainty autoencoders: Learning compressed representations via variational information maximization,” inProc. 22nd Int. Conf. Artif. Intell. Stat., 2019, pp. 2514–2524
2019
-
[28]
Variational Bayesian optimal experimental design,
A. Fosteret al., “Variational Bayesian optimal experimental design,” inAdv. Neural Inf. Process. Syst. 32, 2019, pp. 14 036–14 047
2019
-
[29]
Deep adaptive design: Amortizing sequential Bayesian experimental design,
A. Foster, D. R. Ivanova, I. Malik, and T. Rainforth, “Deep adaptive design: Amortizing sequential Bayesian experimental design,” inProc. 38th Int. Conf. Mach. Learn., 2021, pp. 3384–3395
2021
-
[30]
Efficient Bayesian experimental design for implicit models,
S. Kleinegesse and M. U. Gutmann, “Efficient Bayesian experimental design for implicit models,” inProc. 22nd Int. Conf. Artif. Intell. Stat., 2019, pp. 476–485
2019
-
[31]
Bayesian experimental design for implicit models by mutual information neural estimation,
——, “Bayesian experimental design for implicit models by mutual information neural estimation,” inProc. 37th Int. Conf. Mach. Learn., 2020, pp. 5316–5326
2020
-
[32]
Fast Bayesian experimental design: Laplace-based importance sampling for the expected information gain,
J. Becket al., “Fast Bayesian experimental design: Laplace-based importance sampling for the expected information gain,”Comput. Meth. Appl. Mech. Eng., vol. 334, pp. 523–553, 2018
2018
-
[33]
Brain segmentation from k-space with end-to-end recurrent attention network,
Q. Huang, X. Chen, D. Metaxas, and M. S. Nadar, “Brain segmentation from k-space with end-to-end recurrent attention network,” inInt. Conf. Med. Image Comput. Comput.-Assist. Interv.–MICCAI 2019, 2019, pp. 275–283. IEEE TRANSACTIONS ON PATTERN ANAL YSIS AND MACHINE INTELLIGENCE 65
2019
-
[34]
FR-Net: Joint reconstruction and segmentation in compressed sensing cardiac MRI,
Q. Huang, D. Yang, J. Yi, L. Axel, and D. Metaxas, “FR-Net: Joint reconstruction and segmentation in compressed sensing cardiac MRI,” inInt. Conf. Functional Imaging Model. Heart, 2019, pp. 352–360
2019
-
[35]
Joint CS-MRI reconstruction and segmentation with a unified deep network,
L. Sun, Z. Fan, X. Ding, Y. Huang, and J. Paisley, “Joint CS-MRI reconstruction and segmentation with a unified deep network,” inInt. Conf. Inf. Process. Med. Imag., 2019, pp. 492–504
2019
-
[36]
Breaking speed limits with simultaneous ultra-fast MRI reconstruction and tissue segmentation,
F. Caliv ´aet al., “Breaking speed limits with simultaneous ultra-fast MRI reconstruction and tissue segmentation,” inProc. 3rd Med. Imag. Deep Learn., 2020, pp. 94–110
2020
-
[37]
nnU-Net: a self-configuring method for deep learning-based biomedical image segmentation,
F. Isensee, P . F. Jaeger, S. A. Kohl, J. Petersen, and K. H. Maier-Hein, “nnU-Net: a self-configuring method for deep learning-based biomedical image segmentation,”Nat. Methods, vol. 18, no. 2, pp. 203–211, 2021
2021
-
[38]
A probabilistic U-Net for segmentation of ambiguous images,
S. Kohlet al., “A probabilistic U-Net for segmentation of ambiguous images,” inAdv. Neural Inf. Process. Syst. 31, 2018, pp. 6965–6975
2018
-
[39]
S. A. Kohlet al., “A hierarchical probabilistic U-Net for modeling multi-scale ambiguities,”arXiv preprint arXiv:1905.13077, 2019. [Online]. Available: https://arxiv.org/abs/1905.13077
-
[40]
PixelSeg: Pixel-by-pixel stochastic semantic segmentation for ambiguous medical images,
W. Zhanget al., “PixelSeg: Pixel-by-pixel stochastic semantic segmentation for ambiguous medical images,” in Proc. 30th ACM Int. Conf. Multimedia, 2022, pp. 4742–4750
2022
-
[41]
Uncertainty quantification in medical image segmentation with normalizing flows,
R. Selvan, F. Faye, J. Middleton, and A. Pai, “Uncertainty quantification in medical image segmentation with normalizing flows,” in11th Int. Workshop Mach. Learn. Med. Imaging (MLMI), 2020, pp. 80–90
2020
-
[42]
Stochastic segmentation with conditional categorical diffusion models,
L. Zbindenet al., “Stochastic segmentation with conditional categorical diffusion models,” in2023 IEEE/CVF Int. Conf. Comput. Vis. (ICCV), 2023, pp. 1119–1129
2023
-
[43]
Modeling multimodal aleatoric uncertainty in segmentation with mixture of stochastic experts,
Z. Gao, Y. Chen, C. Zhang, and X. He, “Modeling multimodal aleatoric uncertainty in segmentation with mixture of stochastic experts,” in11th Int. Conf. Learn. Rep., 2023. [Online]. Available: https://arxiv.org/abs/2212.07328
-
[44]
The information bottleneck method
N. Tishby, F. C. Pereira, and W. Bialek, “The information bottleneck method,”arXiv preprint physics/0004057, 2000. [Online]. Available: https://arxiv.org/abs/physics/0004057
work page internal anchor Pith review arXiv 2000
-
[45]
Deep variational information bottleneck,
A. A. Alemi, I. Fischer, J. V . Dillon, and K. Murphy, “Deep variational information bottleneck,” in5th Int. Conf. Learn. Rep., 2017. [Online]. Available: https://openreview.net/forum?id=HyxQzBceg
2017
-
[46]
Maximum likelihood estimation of signal amplitude and noise variance from MR data,
J. Sijbers and A. Den Dekker, “Maximum likelihood estimation of signal amplitude and noise variance from MR data,”Magn. Reson. Med., vol. 51, no. 3, pp. 586–594, 2004
2004
-
[47]
The IM algorithm: a variational approach to information maximization,
D. Barber and F. Agakov, “The IM algorithm: a variational approach to information maximization,” inAdv. Neural Inf. Process. Syst. 16, 2004, pp. 201–208
2004
-
[48]
Von Neumann’s comparison method for random sampling from the normal and other distributions,
G. E. Forsythe, “Von Neumann’s comparison method for random sampling from the normal and other distributions,”Math. Comput., vol. 26, no. 120, pp. 817–826, 1972
1972
-
[49]
Learning the sampling pattern for MRI,
F. Sherryet al., “Learning the sampling pattern for MRI,”IEEE Trans. Med. Imag.vol. 39, no. 12, pp. 4310–4321, 2020
2020
-
[50]
Auto-Encoding Variational Bayes
D. P . Kingma and M. Welling, “Auto-encoding variational bayes,” in2nd Int. Conf. Learn. Rep., 2014. [Online]. Available: https://arxiv.org/abs/1312.6114
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[51]
VAE with a VampPrior,
J. Tomczak and M. Welling, “VAE with a VampPrior,” inProc. 21st Int. Conf. Artif. Intell. Stat., 2018, pp. 1214–1223
2018
-
[52]
Variational inference: A review for statisticians,
D. M. Blei, A. Kucukelbir, and J. D. McAuliffe, “Variational inference: A review for statisticians,”J. Am. Stat. Assoc., vol. 112, no. 518, pp. 859–877, 2017
2017
-
[53]
Offset sampling improves deep learning based accelerated MRI reconstructions by exploiting symmetry,
A. Defazio, “Offset sampling improves deep learning based accelerated MRI reconstructions by exploiting symmetry,”arXiv preprint arXiv:1912.01101, 2019. [Online]. Available: https://arxiv.org/abs/1912.01101
-
[54]
C. M. Bishop,Pattern Recognition and Machine Learning. Springer New York, NY, 2006. IEEE TRANSACTIONS ON PATTERN ANAL YSIS AND MACHINE INTELLIGENCE 66
2006
-
[55]
Multi-task learning using uncertainty to weigh losses for scene geometry and semantics,
A. Kendall, Y. Gal, and R. Cipolla, “Multi-task learning using uncertainty to weigh losses for scene geometry and semantics,” in2018 IEEE Conf. Comput. Vis. Pattern Recognit., 2018, pp. 7482–7491
2018
-
[56]
Analyzing and improving the training dynamics of diffusion models,
T. Karras, M. Aittala, J. Lehtinen, J. Hellsten, T. Aila, and S. Laine, “Analyzing and improving the training dynamics of diffusion models,” in2024 IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2024, pp. 24 174– 24 184
2024
-
[57]
Promoting fast MR imaging pipeline by full-stack AI,
Z. Wanget al., “Promoting fast MR imaging pipeline by full-stack AI,”iScience, vol. 27, no. 1, article no. 108 608, 2024
2024
-
[58]
Optimizing sequential experimental design with deep reinforcement learning,
T. Blau, E. V . Bonilla, I. Chades, and A. Dezfouli, “Optimizing sequential experimental design with deep reinforcement learning,” inProc. 39th Int. Conf. Mach. Learn., 2022, pp. 2107–2128
2022
- [60]
-
[61]
Robust uncertainty principles: Exact signal reconstruction from highly incomplete frequency information,
E. J. Cand `es, J. Romberg, and T. Tao, “Robust uncertainty principles: Exact signal reconstruction from highly incomplete frequency information,”IEEE Trans. Inf. Theory, vol. 52, no. 2, pp. 489–509, 2006
2006
-
[62]
Sparse MRI: The application of compressed sensing for rapid MR imaging,
M. Lustig, D. Donoho, and J. M. Pauly, “Sparse MRI: The application of compressed sensing for rapid MR imaging,”Magn. Reson. Med., vol. 58, no. 6, pp. 1182–1195, 2007
2007
-
[63]
A robust adaptive sampling method for faster acquisition of MR images,
J. Vellagoundar and R. R. Machireddy, “A robust adaptive sampling method for faster acquisition of MR images,” Magn. Reson. Imaging, vol. 33, no. 5, pp. 635–643, 2015
2015
-
[64]
U-Net: Convolutional networks for biomedical image segmentation,
O. Ronneberger, P . Fischer, and T. Brox, “U-Net: Convolutional networks for biomedical image segmentation,” in18th Int. Conf. Med. Image Comput. Comput.-Assist. Interv., 2015, pp. 234–241
2015
-
[65]
ADMM-CSNet: A deep learning approach for image compressive sensing,
Y. Yang, J. Sun, H. Li, and Z. Xu, “ADMM-CSNet: A deep learning approach for image compressive sensing,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 42, no. 3, pp. 521–538, 2018
2018
-
[66]
Plug-and-play image restoration with deep denoiser prior,
K. Zhang, Y. Li, W. Zuo, L. Zhang, L. Van Gool, and R. Timofte, “Plug-and-play image restoration with deep denoiser prior,”IEEE Trans. Pattern Anal. Mach. Intell., vol. 44, no. 10, pp. 6360–6376, 2021
2021
-
[67]
Deep plug-and-play prior for parallel MRI reconstruction,
A. Pour Yazdanpanah, O. Afacan, and S. Warfield, “Deep plug-and-play prior for parallel MRI reconstruction,” in2019 IEEE/CVF Int. Conf. Comput. Vis. Workshops (ICCVW), 2019, pp. 3952–3958
2019
-
[68]
MD-Recon-Net: A Parallel Dual-Domain Convolutional Neural Network for Compressed Sensing MRI,
M. Ranet al., “MD-Recon-Net: A Parallel Dual-Domain Convolutional Neural Network for Compressed Sensing MRI,”IEEE Trans. Radiat. Plasma Med. Sci., vol. 5, no. 1, pp. 120–135, 2020
2020
-
[69]
Self-supervised learning for MRI reconstruction with a parallel network training framework,
C. Huet al., “Self-supervised learning for MRI reconstruction with a parallel network training framework,” in Int. Conf. Med. Image Comput. Comput.-Assist. Interv.–MICCAI 2021, 2021, pp. 382–391
2021
-
[70]
High-resolution image synthesis with latent diffusion models,
R. Rombachet al., “High-resolution image synthesis with latent diffusion models,” in2022 IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2022, pp. 10 684–10 695
2022
-
[71]
beta-VAE: Learning basic visual concepts with a constrained variational framework,
I. Higginset al., “beta-VAE: Learning basic visual concepts with a constrained variational framework,” in5th Int. Conf. Learn. Rep., 2017. [Online]. Available: https://openreview.net/forum?id=Sy2fzU9gl
2017
-
[72]
Quantification of uncertainties in biomedical image quantification challenge 2021,
B. Menzeet al., “Quantification of uncertainties in biomedical image quantification challenge 2021,” 2021. [Online]. Available: https://qubiq21.grand-challenge.org/QUBIQ2021/
2021
-
[73]
Using soft labels to model uncertainty in medical image segmentation,
J. L. Silva and A. L. Oliveira, “Using soft labels to model uncertainty in medical image segmentation,” inInt. MICCAI Brainlesion Workshop, 2021, pp. 585–596
2021
-
[74]
Deep residual learning for image recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in2016 IEEE Conf. Comput. Vis. Pattern Recognit., 2016, pp. 770–778. IEEE TRANSACTIONS ON PATTERN ANAL YSIS AND MACHINE INTELLIGENCE 67
2016
-
[75]
fastMRI+, Clinical pathology annotations for knee and brain fully sampled multi-coil MRI data,
R. Zhaoet al., “fastMRI+, Clinical pathology annotations for knee and brain fully sampled multi-coil MRI data,” Sci. Data, vol. 9, no. 152, 2022
2022
-
[76]
Adaptive sampling of k-space in magnetic resonance for rapid pathology prediction,
C.-Y. Yenet al., “Adaptive sampling of k-space in magnetic resonance for rapid pathology prediction,” inProc. 41st Int. Conf. Mach. Learn., 2024, pp. 57 018–57 032
2024
-
[77]
Skm-tea: A dataset for accelerated mri reconstruction with dense image labels for quantitative clinical evaluation,
A. D. Desai, A. M. Schmidt, E. B. Rubin, C. M. Sandino, M. S. Black, V . Mazzoli, K. J. Stevens, R. Boutin, C. Re, G. E. Goldet al., “Skm-tea: A dataset for accelerated mri reconstruction with dense image labels for quantitative clinical evaluation,” inThirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2), 2021
2021
-
[78]
Brisc: Annotated dataset for brain tumor segmentation and classification,
A. Fateh, Y. Rezvani, S. Moayedi, S. Rezvani, F. Fateh, M. Fateh, and V . Abolghasemi, “Brisc: Annotated dataset for brain tumor segmentation and classification,”Scientific Data, 2026
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.