Recognition: unknown
Efficient Adversarial Training via Criticality-Aware Fine-Tuning
Pith reviewed 2026-05-10 14:46 UTC · model grok-4.3
The pith
Criticality-aware fine-tuning achieves near-full adversarial robustness in vision transformers by updating only 6% of parameters.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
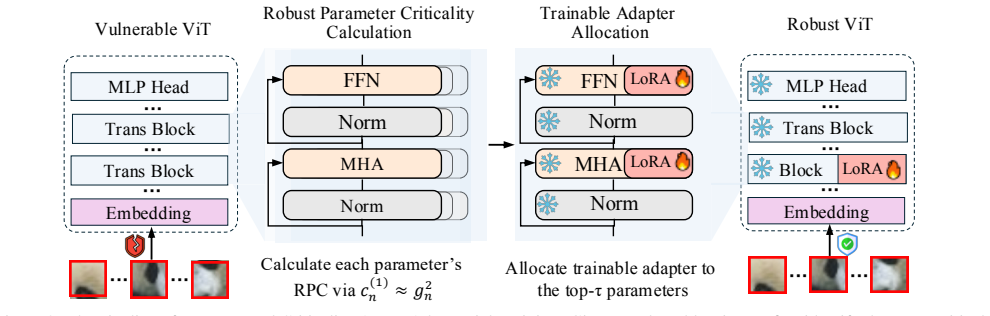
CAAT identifies robustness-critical parameters and then uses PEFT to fine-tune only those modules whose critical-parameter count exceeds a chosen threshold, thereby matching the adversarial robustness of full-model training while tuning far fewer weights.
What carries the argument
The criticality identification step followed by threshold-based module selection for PEFT, which concentrates updates on the parameters that contribute most to adversarial robustness.
If this is right
- CAAT outperforms existing lightweight adversarial training methods while requiring fewer trainable parameters.
- The performance gap to full adversarial training remains small (4.3 percent) even as vision transformer size increases.
- Adversarial training becomes feasible for large-scale vision transformers without retraining every weight.
- The same criticality-driven selection can be applied across multiple standard adversarial learning benchmarks with consistent efficiency gains.
Where Pith is reading between the lines
- If critical parameters remain sparse across different model scales, robustness may be maintained by updating only a stable core set of modules rather than the whole network.
- The approach suggests that adversarial robustness in transformers is modular enough to support incremental or selective protection instead of monolithic retraining.
- Combining the criticality map with other efficiency techniques could further reduce the cost of maintaining robustness when models continue to grow.
Load-bearing premise
The procedure that ranks parameters by their contribution to robustness correctly isolates the modules that, when updated via PEFT, are sufficient to restore nearly all of the protection that full-model adversarial training would provide.
What would settle it
Run full adversarial training and CAAT side-by-side on a held-out large ViT using one of the three standard adversarial datasets; if the adversarial accuracy of CAAT falls more than five percentage points below full training while still using only the selected six percent of parameters, the core claim does not hold.
Figures


read the original abstract
Vision Transformer (ViT) models have achieved remarkable performance across various vision tasks, with scalability being a key advantage when applied to large datasets. This scalability enables ViT models to exhibit strong generalization capabilities. However, as the number of parameters increases, the robustness of ViT models to adversarial examples does not scale proportionally. Adversarial training (AT), one of the most effective methods for enhancing robustness, typically requires fine-tuning the entire model, leading to prohibitively high computational costs, especially for large ViT architectures. In this paper, we aim to robustly fine-tune only a small subset of parameters to achieve robustness comparable to standard AT. To accomplish this, we introduce Criticality-Aware Adversarial Training (CAAT), a novel method that adaptively allocates resources to the most robustness-critical parameters, fine-tuning only selected modules. Specifically, CAAT efficiently identifies parameters that contribute most to adversarial robustness. It then leverages parameter-efficient fine-tuning (PEFT) to robustly adjust weight matrices where the number of critical parameters exceeds a predefined threshold. CAAT exhibits favorable generalization when scaled to larger vision transformer architectures, potentially paving the way for adversarial training at scale, e.g, compared with plain adversarial training, CAAT incurs only a 4.3% decrease in adversarial robustness while tuning approximately 6% of its parameters. Extensive experiments on three widely used adversarial learning datasets demonstrate that CAAT outperforms state-of-the-art lightweight AT methods with fewer trainable parameters.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Criticality-Aware Adversarial Training (CAAT) for Vision Transformers. It identifies a small subset of robustness-critical parameters/modules, applies parameter-efficient fine-tuning (PEFT) only to those exceeding a threshold, and claims this yields adversarial robustness within 4.3% of full-model adversarial training while tuning ~6% of parameters. The method is reported to scale favorably to larger ViTs and to outperform prior lightweight AT baselines on three standard adversarial datasets.
Significance. If the criticality selection mechanism is shown to be necessary (i.e., superior to random selection at fixed budget), the result would be practically significant: it offers a concrete route to make adversarial training computationally feasible for large-scale ViTs without sacrificing most of the robustness gain. The reported parameter efficiency and scaling behavior would be a useful empirical contribution to the literature on robust fine-tuning.
major comments (2)
- [Experiments / Ablation studies] The manuscript contains no ablation that compares criticality-based module selection against random module selection at the same ~6% parameter budget and identical PEFT protocol. Without this control, it is impossible to attribute the reported 4.3% robustness gap to the proposed criticality mechanism rather than to the generic benefits of PEFT on ViTs. This directly undermines the central claim that CAAT “adaptively allocates resources to the most robustness-critical parameters.”
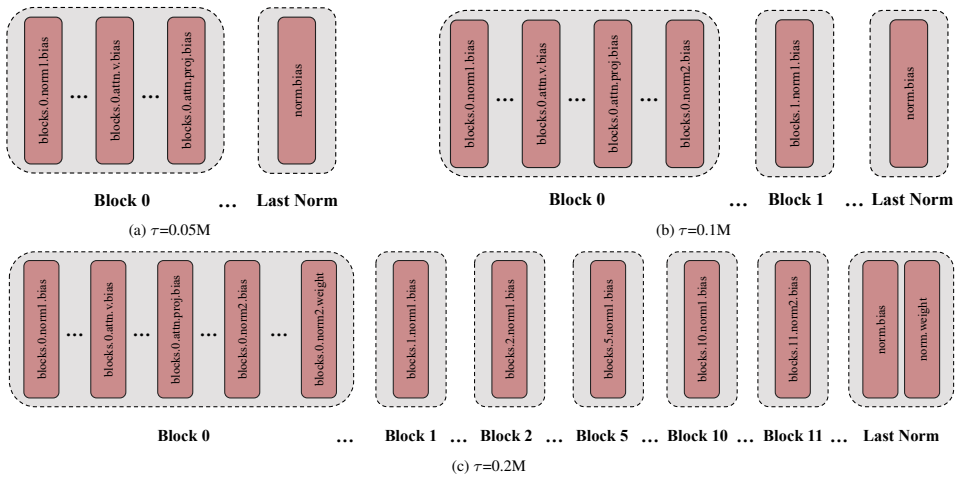
- [Method / Criticality identification] The description of the criticality metric itself (how parameters are scored for robustness contribution, the exact threshold used for module selection, and any hyper-parameters of the identification step) is insufficiently detailed to allow reproduction or to assess whether the selection is stable across runs or architectures.
minor comments (2)
- [Abstract] The abstract reports numerical outcomes (4.3% drop, 6% parameters) but supplies no description of the criticality metric, selection threshold, number of runs, or statistical significance, making the headline claims hard to evaluate at a glance.
- [Method] Notation for the PEFT modules (e.g., which weight matrices are adapted and how the threshold interacts with module size) should be formalized with a short equation or pseudocode for clarity.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. The comments highlight important aspects that will improve the clarity and rigor of the manuscript. We address each major comment below and will revise the paper accordingly.
read point-by-point responses
-
Referee: [Experiments / Ablation studies] The manuscript contains no ablation that compares criticality-based module selection against random module selection at the same ~6% parameter budget and identical PEFT protocol. Without this control, it is impossible to attribute the reported 4.3% robustness gap to the proposed criticality mechanism rather than to the generic benefits of PEFT on ViTs. This directly undermines the central claim that CAAT “adaptively allocates resources to the most robustness-critical parameters.”
Authors: We agree that a direct comparison to random module selection at the identical parameter budget and PEFT protocol is required to isolate the contribution of the criticality mechanism. We will add this ablation study to the revised manuscript, reporting adversarial robustness results for both selection strategies under the same experimental conditions on the three datasets. This addition will allow readers to evaluate whether the reported performance is attributable to criticality-aware allocation rather than PEFT alone. revision: yes
-
Referee: [Method / Criticality identification] The description of the criticality metric itself (how parameters are scored for robustness contribution, the exact threshold used for module selection, and any hyper-parameters of the identification step) is insufficiently detailed to allow reproduction or to assess whether the selection is stable across runs or architectures.
Authors: We acknowledge that the current description of the criticality scoring process in Section 3 is too concise for full reproducibility. In the revised manuscript we will expand the method section to include the exact scoring formula (gradient-based contribution to adversarial loss on a small calibration set), the precise threshold applied per module, all hyper-parameters of the identification step, and additional experiments demonstrating selection stability across random seeds and ViT scales. revision: yes
Circularity Check
No significant circularity in empirical algorithmic method
full rationale
The paper describes CAAT as a procedural algorithmic method for identifying robustness-critical parameters in ViTs and applying PEFT to selected modules, with efficiency claims evaluated via experiments on standard adversarial datasets. No equations, derivations, or first-principles results are present that could reduce to their inputs by construction. The abstract and description contain no self-definitional loops, fitted parameters presented as independent predictions, or load-bearing self-citations invoking uniqueness theorems. Central claims rest on empirical comparisons rather than tautological reductions, rendering the approach self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
An image is worth 16x16 words: Transformers for image recognition at scale,
A. Dosovitskiy, L. Beyeret al., “An image is worth 16x16 words: Transformers for image recognition at scale,” inInternational Conference on Learning Representations,
-
[2]
Available: https://openreview.net/forum?id= YicbFdNTTy 1, 3, 4, 5, 6
[Online]. Available: https://openreview.net/forum?id= YicbFdNTTy 1, 3, 4, 5, 6
-
[3]
Contrastive multi-bit collaborative learning for deep cross-modal hash- ing,
Q. Wu, Z. Zhang, Y . Liu, J. Zhang, and L. Nie, “Contrastive multi-bit collaborative learning for deep cross-modal hash- ing,”IEEE Transactions on Knowledge and Data Engineer- ing, vol. 36, no. 11, pp. 5835–5848, 2024. 1
2024
-
[4]
DeepFit: 3D Surface Fitting via Neural Network Weighted Least Squares
N. Carion, F. Massa, G. Synnaeve, N. Usunier, A. Kirillov, and S. Zagoruyko, “End-to-end object detection with transformers,” inECCV, ser. Lecture Notes in Computer Science, A. Vedaldi, H. Bischof, T. Brox, and J. Frahm, Eds., vol. 12346. Springer, 2020, pp. 213–229. [Online]. Available: https://doi.org/10.1007/978-3-030-58452-8 13 1
-
[5]
Sequential modeling enables scalable learning for large vision models,
Y . Bai, X. Geng, K. Mangalam, A. Bar, A. L. Yuille, T. Dar- rell, J. Malik, and A. A. Efros, “Sequential modeling enables scalable learning for large vision models,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 22 861–22 872. 1, 3
2024
-
[6]
Editing conditional radiance fields
H. Touvron, M. Cord, A. Sablayrolles, G. Synnaeve, and H. J ´egou, “Going deeper with image transformers,” inICCV, 2021, pp. 32–42. [Online]. Available: https: //doi.org/10.1109/ICCV48922.2021.00010 1
-
[7]
Editing conditional radiance fields
C. R. Chen, Q. Fan, and R. Panda, “Crossvit: Cross-attention multi-scale vision transformer for image classification,” in ICCV, 2021, pp. 347–356. [Online]. Available: https: //doi.org/10.1109/ICCV48922.2021.00041 1
-
[8]
Diffusion models for adversarial purification,
W. Nie, B. Guo, Y . Huang, C. Xiao, A. Vahdat, and A. Anandkumar, “Diffusion models for adversarial purification,” inInternational Conference on Machine Learning, ser. Proceedings of Machine Learning Research, K. Chaudhuri, S. Jegelka, L. Song, C. Szepesv ´ari, G. Niu, and S. Sabato, Eds., vol. 162. PMLR, 2022, pp. 16 805– 16 827. [Online]. Available: htt...
2022
-
[9]
Feature squeezing: Detecting adversarial examples in deep neural networks,
W. Xu, D. Evans, and Y . Qi, “Feature squeezing: Detecting adversarial examples in deep neural networks,” in Network and Distributed System Security Symposium, 2018. [Online]. Available: https://www.ndss-symposium.org/wp- content/uploads/2018/02/ndss2018 03A-4 Xu paper.pdf
2018
-
[10]
Pixeldefend: Leveraging generative models to understand and defend against adversarial examples,
Y . Song, T. Kim, S. Nowozin, S. Ermon, and N. Kushman, “Pixeldefend: Leveraging generative models to understand and defend against adversarial examples,” inInternational Conference on Learning Representations, 2018. [Online]. Available: https://openreview.net/forum?id=rJUYGxbCW 1
2018
-
[11]
Towards deep learning models resistant to ad- versarial attacks,
A. Madry, A. Makelov, L. Schmidt, D. Tsipras, and A. Vladu, “Towards deep learning models resistant to ad- versarial attacks,” inInternational Conference on Learning Representations, 2018. 2, 3, 4, 5, 6
2018
-
[12]
Adversarial weight perturbation helps robust generalization,
D. Wu, S. Xia, and Y . Wang, “Adversarial weight perturbation helps robust generalization,” inNeural Infor- mation Processing Systems, H. Larochelle, M. Ranzato, R. Hadsell, M. Balcan, and H. Lin, Eds., 2020. [Online]. Available: https://proceedings.neurips.cc/paper/2020/hash/ 1ef91c212e30e14bf125e9374262401f-Abstract.html 2
2020
-
[13]
Defending against neural network model stealing attacks using deceptive per- turbations,
T. Lee, B. Edwards, I. Molloy, and D. Su, “Defending against neural network model stealing attacks using deceptive per- turbations,” in2019 IEEE Security and Privacy Workshops (SPW), 2019, pp. 43–49. 2
2019
-
[14]
The power of scale for parameter-efficient prompt tuning,
B. Lester, R. Al-Rfou, and N. Constant, “The power of scale for parameter-efficient prompt tuning,” inEmpirical Methods in Natural Language Processing, M. Moens, X. Huang, L. Specia, and S. W. Yih, Eds. Association for Computational Linguistics, 2021, pp. 3045–3059. [Online]. Available: https://doi.org/10.18653/v1/2021.emnlp-main. 243 2, 3
-
[15]
Parameter-efficient transfer learning for NLP,
N. Houlsby, A. Giurgiu, S. Jastrzebski, B. Morrone, Q. de Laroussilhe, A. Gesmundo, M. Attariyan, and S. Gelly, “Parameter-efficient transfer learning for NLP,” inProceedings of International Conference on Machine Learning, ser. Proceedings of Machine Learning Research, K. Chaudhuri and R. Salakhutdinov, Eds., vol. 97, 2019, pp. 2790–2799. [Online]. Avail...
2019
-
[16]
Language models are few-shot learners,
T. B. Brown, B. Mann, N. Ryder, M. Subbiahet al., “Language models are few-shot learners,” inNeural Information Processing Systems, H. Larochelle, M. Ranzato, R. Hadsell, M. Balcan, and H. Lin, Eds., 2020. [Online]. Available: https://proceedings.neurips.cc/paper/2020/hash/ 1457c0d6bfcb4967418bfb8ac142f64a-Abstract.html 2
2020
-
[17]
LoRA: Low-rank adaptation of large language models,
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, and W. Chen, “LoRA: Low-rank adaptation of large language models,” inInternational Conference on Learning Representations, 2022. 2, 3, 5, 6
2022
-
[18]
Fulllora-at: Efficiently boosting the robustness of pretrained vision transformers,
Z. Yuan, J. Zhang, and S. Shan, “Fulllora-at: Efficiently boosting the robustness of pretrained vision transformers,” arXiv preprint arXiv:2401.01752, 2024. 2, 3, 5
-
[19]
Theoretically principled trade-off between robustness and accuracy,
H. Zhang, Y . Yu, J. Jiao, E. Xing, L. El Ghaoui, and M. Jor- dan, “Theoretically principled trade-off between robustness and accuracy,” inInternational conference on machine learn- ing. PMLR, 2019, pp. 7472–7482. 2, 3, 7
2019
-
[20]
Im- proving adversarial robustness requires revisiting misclassi- fied examples,
Y . Wang, D. Zou, J. Yi, J. Bailey, X. Ma, and Q. Gu, “Im- proving adversarial robustness requires revisiting misclassi- fied examples,” inInternational conference on learning rep- resentations, 2019. 2, 3, 7
2019
-
[21]
When adver- sarial training meets vision transformers: Recipes from train- ing to architecture,
Y . Mo, D. Wu, Y . Wang, Y . Guo, and Y . Wang, “When adver- sarial training meets vision transformers: Recipes from train- ing to architecture,”Advances in Neural Information Pro- cessing Systems, vol. 35, pp. 18 599–18 611, 2022. 2, 3, 7
2022
-
[22]
Heung-Chang Lee and Jeonggeun Song
Y . LeCun, L. Bottou, Y . Bengio, and P. Haffner, “Gradient- based learning applied to document recognition,”Proc. IEEE, vol. 86, no. 11, pp. 2278–2324, 1998. [Online]. Available: https://doi.org/10.1109/5.726791 3
-
[23]
Imagenet classification with deep convolutional neural networks,
A. Krizhevsky, I. Sutskever, and G. E. Hinton, “Imagenet classification with deep convolutional neural networks,” in Advances in Neural Information Processing Systems, P. L. 9 Bartlett, F. C. N. Pereira, C. J. C. Burges, L. Bottou, and K. Q. Weinberger, Eds., 2012, pp. 1106–1114. [Online]. Available: https://proceedings.neurips.cc/paper/2012/hash/ c399862...
2012
-
[24]
Segment anything,
A. Kirillov, E. Mintun, N. Raviet al., “Segment anything,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 4015–4026. 3
2023
-
[25]
Masked-attention mask transformer for universal image segmentation,
B. Cheng, I. Misra, A. G. Schwing, A. Kirillov, and R. Gird- har, “Masked-attention mask transformer for universal image segmentation,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 1290–
2022
-
[26]
Attention is all you need,
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin, “Attention is all you need,” inAdvances in Neural Information Processing Systems, I. Guyon, U. von Luxburg, S. Bengio, H. M. Wallach, R. Fergus, S. V . N. Vishwanathan, and R. Garnett, Eds., 2017, pp. 5998–6008. [Online]. Available: https://proceedings.ne...
2017
-
[27]
A. Dubey, A. Jauhri, A. Pandeyet al., “The llama 3 herd of models,”arXiv preprint arXiv:2407.21783, 2024. 3
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
Elf: An end-to-end local and global multimodal fusion framework for glaucoma grading,
W. Li and C.-M. Pun, “Elf: An end-to-end local and global multimodal fusion framework for glaucoma grading,” in 2023 IEEE International Conference on Bioinformatics and Biomedicine (BIBM). IEEE, 2023, pp. 4081–4085. 3
2023
-
[29]
Facenet: A unified embedding for face recognition and clustering,
F. Schroff, D. Kalenichenko, and J. Philbin, “Facenet: A unified embedding for face recognition and clustering,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2015, pp. 815–823. 3
2015
-
[30]
Adversarial sticker: A stealthy attack method in the physical world,
X. Wei, Y . Guo, and J. Yu, “Adversarial sticker: A stealthy attack method in the physical world,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 45, no. 3, pp. 2711–2725, 2022. 3
2022
-
[31]
Provable robustness against all adversariall p-perturbations forp≥1,
F. Croce and M. Hein, “Provable robustness against all adversariall p-perturbations forp≥1,”arXiv preprint arXiv:1905.11213, 2019. 3
-
[32]
Random entangled tokens for adversarially robust vision transformer,
H. Gong, M. Dong, S. Ma, S. Camtepe, S. Nepal, and C. Xu, “Random entangled tokens for adversarially robust vision transformer,” inProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, 2024, pp. 24 554–24 563. 3
2024
-
[33]
Towards understanding and improving adversarial robustness of vision transformers,
S. Jain and T. Dutta, “Towards understanding and improving adversarial robustness of vision transformers,” inProceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 24 736–24 745. 3
2024
-
[34]
Adaptformer: Adapting vision transformers for scalable visual recognition,
S. Chen, C. Ge, Z. Tong, J. Wang, Y . Song, J. Wang, and P. Luo, “Adaptformer: Adapting vision transformers for scalable visual recognition,” inNeural Information Processing Systems, S. Koyejo, S. Mohamed, A. Agar- wal, D. Belgrave, K. Cho, and A. Oh, Eds., 2022. [Online]. Available: http://papers.nips.cc/paper files/paper/ 2022/hash/69e2f49ab0837b71b0e0c...
2022
-
[35]
Clip-adapter: Better vision-language models with feature adapters,
P. Gao, S. Geng, R. Zhang, T. Ma, R. Fang, Y . Zhang, H. Li, and Y . Qiao, “Clip-adapter: Better vision-language models with feature adapters,”Int. J. Comput. Vis., vol. 132, no. 2, pp. 581–595, 2024. [Online]. Available: https://doi.org/10.1007/s11263-023-01891-x 3
-
[36]
Towards evaluating the robust- ness of neural networks,
N. Carlini and D. Wagner, “Towards evaluating the robust- ness of neural networks,” inIEEE Symposium on Security and Privacy, 2017, pp. 39–57. 4, 5, 6
2017
-
[37]
Explaining and harnessing adversarial examples,
I. J. Goodfellow, J. Shlens, and C. Szegedy, “Explaining and harnessing adversarial examples,” inInternational Confer- ence on Learning Representations, Y . Bengio and Y . LeCun, Eds., 2015. 4
2015
-
[38]
Improv- ing generalization of adversarial training via robust critical fine-tuning,
K. Zhu, X. Hu, J. Wang, X. Xie, and G. Yang, “Improv- ing generalization of adversarial training via robust critical fine-tuning,” inInternational Conference on Computer Vi- sion, 2023. 4
2023
-
[39]
Importance estimation for neural network pruning,
P. Molchanov, A. Mallya, S. Tyree, I. Frosio, and J. Kautz, “Importance estimation for neural network pruning,” inPro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 11 264–11 272. [Online]. Available: http://openaccess.thecvf.com/content CVPR 2019 / html / MolchanovImportance Estimation for Neural Network Prunin...
2019
-
[40]
Proxylessnas: Direct neural architecture search on target task and hardware,
H. Cai, L. Zhu, and S. Han, “Proxylessnas: Direct neural architecture search on target task and hardware,” inInternational Conference on Learning Representations,
-
[41]
Available: https://openreview.net/forum?id= HylVB3AqYm 4
[Online]. Available: https://openreview.net/forum?id= HylVB3AqYm 4
-
[42]
Peft: State-of-the-art parameter-efficient fine- tuning methods,
S. Mangrulkar, S. Gugger, L. Debut, Y . Belkada, S. Paul, and B. Bossan, “Peft: State-of-the-art parameter-efficient fine- tuning methods,” https://github.com/huggingface/peft, 2022. 5
2022
-
[43]
Multi-lora composition for image generation,
M. Zhong, Y . Shen, S. Wang, Y . Lu, Y . Jiao, S. Ouyang, D. Yu, J. Han, and W. Chen, “Multi-lora composition for image generation,”arXiv preprint arXiv:2402.16843, 2024. 5
-
[44]
Parameter-efficient fine-tuning of large-scale pre-trained language models,
N. Ding, Y . Qin, G. Yang, F. Wei, Z. Yang, Y . Su, S. Hu, Y . Chen, C.-M. Chan, W. Chenet al., “Parameter-efficient fine-tuning of large-scale pre-trained language models,”Na- ture Machine Intelligence, vol. 5, no. 3, pp. 220–235, 2023. 5
2023
-
[45]
Learning multiple layers of features from tiny images,
A. Krizhevsky, G. Hintonet al., “Learning multiple layers of features from tiny images,” 2009. 5
2009
-
[46]
O. Russakovsky, J. Deng, H. Su, J. Krauseet al., “Imagenet large scale visual recognition challenge,”Int. J. Comput. Vis., vol. 115, no. 3, pp. 211–252, 2015. [Online]. Available: https://doi.org/10.1007/s11263-015-0816-y 5
-
[47]
Swin transformer: Hierarchical vision transformer using shifted windows,
Z. Liu, Y . Lin, Y . Cao, H. Hu, Y . Wei, Z. Zhang, S. Lin, and B. Guo, “Swin transformer: Hierarchical vision transformer using shifted windows,” inProceedings of the IEEE/CVF international conference on computer vision, 2021, pp. 10 012–10 022. 5, 2
2021
-
[48]
Reliable evaluation of adversarial robustness with an ensemble of diverse parameter-free attacks,
F. Croce and M. Hein, “Reliable evaluation of adversarial robustness with an ensemble of diverse parameter-free attacks,” inProceedings of Machine Learning Research, ser. Proceedings of Machine Learning Research, vol. 119, 2020, pp. 2206–2216. [Online]. Available: http: //proceedings.mlr.press/v119/croce20b.html 5, 6
2020
-
[49]
Parameter-efficient tuning of 10 large-scale multimodal foundation model,
H. Wang, X. Yang, J. Chang, D. Jin, J. Sun, S. Zhang, X. Luo, and Q. Tian, “Parameter-efficient tuning of 10 large-scale multimodal foundation model,” 2023. [Online]. Available: https://arxiv.org/abs/2305.08381 5
-
[50]
Hyper adversarial tuning for boosting adversarial robustness of pretrained large vision models,
K. Lv, H. Cao, K. Tu, Y . Xu, Z. Zhang, X. Ding, and Y . Wang, “Hyper adversarial tuning for boosting adversarial robustness of pretrained large vision models,” CoRR, vol. abs/2410.05951, 2024. [Online]. Available: https://doi.org/10.48550/arXiv.2410.05951 5
-
[51]
Decoupled Weight Decay Regularization
I. Loshchilov, F. Hutteret al., “Fixing weight decay regular- ization in adam,”arXiv preprint arXiv:1711.05101, vol. 5,
work page internal anchor Pith review Pith/arXiv arXiv
-
[52]
Scaling vision transformers to 22 billion parameters,
M. Dehghani, J. Djolonga, B. Mustafa, P. Padlewski, J. Heek et al., “Scaling vision transformers to 22 billion parameters,” inInternational Conference on Machine Learning. PMLR, 2023, pp. 7480–7512. 7
2023
-
[53]
LLaVA-OneVision: Easy Visual Task Transfer
B. Li, Y . Zhang, D. Guo, R. Zhanget al., “Llava-onevision: Easy visual task transfer,”CoRR, vol. abs/2408.03326, 2024. [Online]. Available: https://doi.org/10.48550/arXiv.2408. 03326 9 11 Efficient Adversarial Training via Criticality-Aware Fine-Tuning Supplementary Material
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2408 2024
-
[54]
Algorithm of CAAT A detailed description of the CAAT algorithm is provided in Algorithm.2. Algorithm 2Criticality-Aware Adversarial Training Input:Pre-trained ViT model with network parameterθ, adversarial datasetD adv, adversarial training iteration stepsT, learning rateγ. Output:The adversarial trained model weightsθ ∗ AT . 1:Initialize criticality set:...
-
[55]
Experiment Code The source code is available athttps://anonymous
Training Details 7.1. Experiment Code The source code is available athttps://anonymous. 4open.science/r/CAAT-CF86
-
[56]
Effect of number of adversarial samples We also investigate the effect of varying the number of ad- versarial samples used to calculate parameter criticality
Experiment Results 8.1. Effect of number of adversarial samples We also investigate the effect of varying the number of ad- versarial samples used to calculate parameter criticality. Re- sults in Table. 7 show that the robustness accuracy increases slightly from 200 to 600 samples and plateaus thereafter. This suggests that the robustness accuracy is not ...
-
[57]
It is important to note that enhancing robustness is not the primary objective of this work
Ethical Impact We propose Criticality-Aware Adversarial Training (CAAT), a method aimed at achieving parameter-efficient adversarial training. It is important to note that enhancing robustness is not the primary objective of this work. While our research currently focuses on ViT with relatively small parameter sizes, we plan to extend our methods to large...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.