Recognition: unknown
BEAM: Bi-level Memory-adaptive Algorithmic Evolution for LLM-Powered Heuristic Design
Pith reviewed 2026-05-10 15:35 UTC · model grok-4.3
The pith
BEAM reframes heuristic design as bi-level optimization so LLMs can evolve complete solvers rather than single functions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
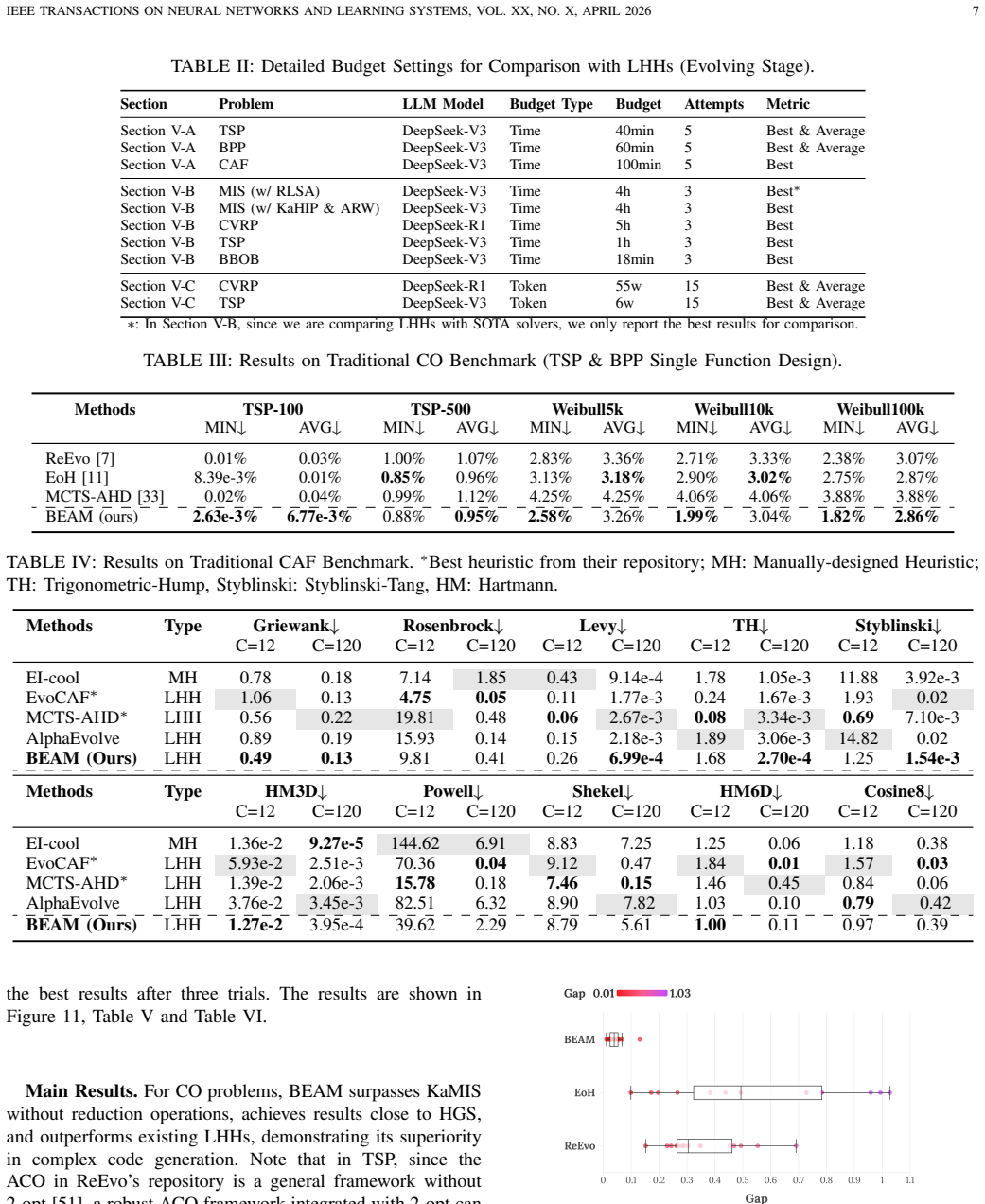
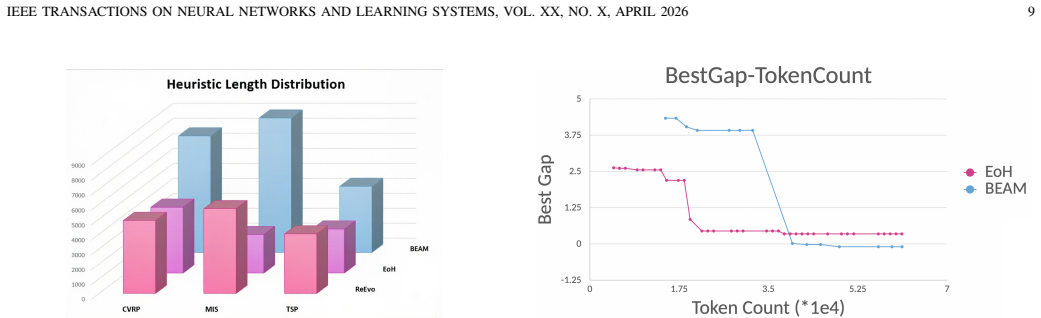
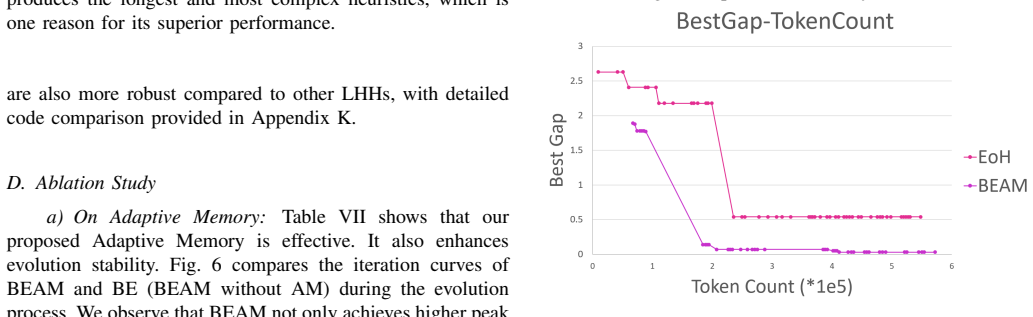
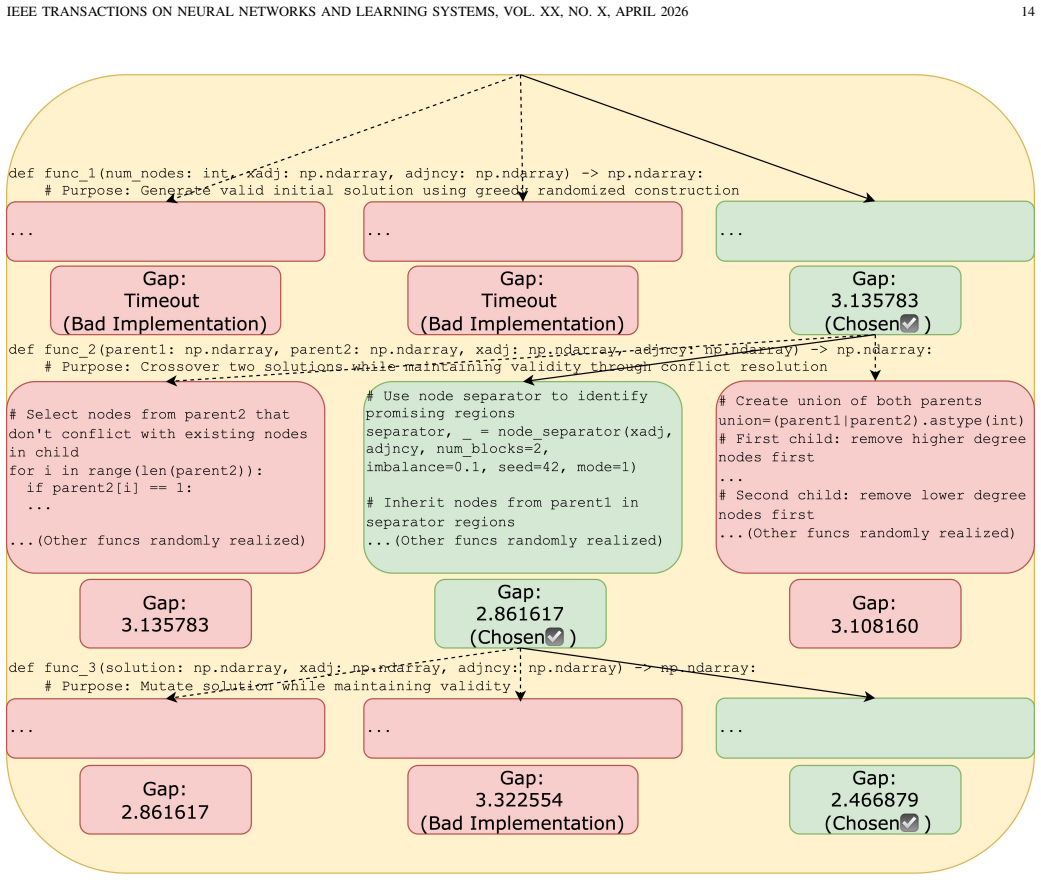
BEAM treats heuristic design as a bi-level optimization problem in which the exterior layer uses a genetic algorithm to evolve algorithmic skeletons with function placeholders and the interior layer uses Monte Carlo tree search to instantiate those placeholders. An adaptive memory mechanism assists complex code generation, and a dedicated knowledge augmentation pipeline supplies evaluation data that avoids starting from scratch or rigid templates. On the capacitated vehicle routing problem the resulting hybrid algorithms reduce the aggregate optimality gap by 37.84 percent relative to prior LLM-based hyper-heuristics; on the maximum independent set problem BEAM produces a heuristic that outr
What carries the argument
Bi-level optimization in which a genetic algorithm evolves high-level algorithmic structures containing placeholders while Monte Carlo tree search fills the placeholders, augmented by adaptive memory and a knowledge augmentation pipeline for code evaluation.
If this is right
- Hybrid solvers for vehicle routing achieve lower optimality gaps than previous LLM hyper-heuristics.
- The same pipeline can produce a heuristic that surpasses the KaMIS solver on maximum independent set instances.
- Knowledge augmentation enables reliable evaluation of complex generated code instead of relying on templates or zero-shot starts.
- The separation of high-level structure search from low-level code realization improves exploration efficiency over flat evolution.
Where Pith is reading between the lines
- If the bi-level split generalizes, similar outer-inner decompositions could be applied to other automated design tasks such as neural architecture search or program synthesis.
- The reported gains suggest that explicit memory of past partial solutions may become a standard component in LLM-driven algorithm generators.
- Success on routing and independent set raises the possibility of testing the same framework on scheduling or packing problems where complete solver construction is also difficult.
Load-bearing premise
The combination of outer genetic search over structures, inner tree search for code, adaptive memory, and knowledge augmentation will produce meaningfully better exploration and final solvers than single-layer baselines without introducing new biases or needing heavy problem-specific tuning.
What would settle it
An ablation that removes either the outer genetic layer or the inner tree-search layer and shows no drop, or a broader test set where the designed solvers fail to improve on held-out instances of similar size.
Figures





read the original abstract
Large Language Model-based Hyper Heuristic (LHH) has recently emerged as an efficient way for automatic heuristic design. However, most existing LHHs just perform well in optimizing a single function within a pre-defined solver. Their single-layer evolution makes them not effective enough to write a competent complete solver. While some variants incorporate hyperparameter tuning or attempt to generate complex code through iterative local modifications, they still lack a high-level algorithmic modeling, leading to limited exploration efficiency. To address this, we reformulate heuristic design as a Bi-level Optimization problem and propose \textbf{BEAM} (Bi-level Memory-adaptive Algorithmic Evolution). BEAM's exterior layer evolves high-level algorithmic structures with function placeholders through genetic algorithm (GA), while the interior layer realizes these placeholders via Monte Carlo Tree Search (MCTS). We further introduce an Adaptive Memory module to facilitate complex code generation. To support the evaluation for complex code generation, we point out the limitations of starting LHHs from scratch or from code templates and introduce a Knowledge Augmentation (KA) Pipeline. Experimental results on several optimization problems demonstrate that BEAM significantly outperforms existing LHHs, notably reducing the optimality gap by 37.84\% on aggregate in CVRP hybrid algorithm design. BEAM also designs a heuristic that outperforms SOTA Maximum Independent Set (MIS) solver KaMIS.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes BEAM, a bi-level optimization framework for LLM-powered heuristic design. The outer layer evolves high-level algorithmic structures containing function placeholders via genetic algorithm, while the inner layer realizes the placeholders using Monte Carlo Tree Search. An Adaptive Memory module and Knowledge Augmentation Pipeline are introduced to support complex code generation. On CVRP hybrid algorithm design the method reports a 37.84% aggregate optimality-gap reduction versus prior LHHs and produces a heuristic that outperforms the SOTA MIS solver KaMIS.
Significance. If the performance claims survive controlled re-evaluation, the bi-level separation of structure search from placeholder realization, together with the adaptive memory and KA pipeline, would represent a meaningful advance over single-layer LHHs by enabling more systematic exploration of complete solver architectures rather than isolated functions.
major comments (2)
- [Experimental results] Experimental results section: the central claim of a 37.84% aggregate gap reduction is presented without any statement of the total LLM query budget, number of generations, or wall-clock evaluations allocated to BEAM versus the single-layer baselines. Because the bi-level GA+MCTS structure inherently multiplies the number of LLM calls per candidate, the reported improvement cannot yet be attributed to the proposed architecture rather than to greater search effort.
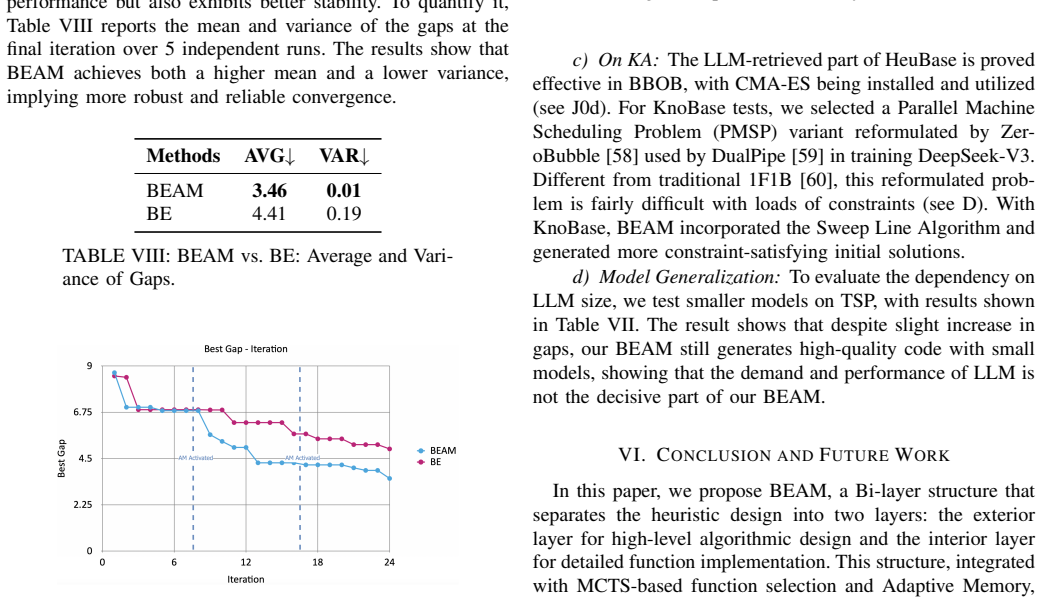
- [Experimental results] Experimental results section: no ablation study isolates the contribution of the Adaptive Memory module or the KA Pipeline, nor are statistical significance tests or variance estimates across runs reported for the CVRP and MIS results. Without these controls the load-bearing performance claims remain under-supported.
minor comments (1)
- [Abstract] The abstract and introduction use the acronym LHH without an initial expansion; a parenthetical definition on first use would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The points raised regarding experimental rigor are valid and will be addressed through revisions to strengthen the presentation of results. We respond to each major comment below.
read point-by-point responses
-
Referee: [Experimental results] Experimental results section: the central claim of a 37.84% aggregate gap reduction is presented without any statement of the total LLM query budget, number of generations, or wall-clock evaluations allocated to BEAM versus the single-layer baselines. Because the bi-level GA+MCTS structure inherently multiplies the number of LLM calls per candidate, the reported improvement cannot yet be attributed to the proposed architecture rather than to greater search effort.
Authors: We acknowledge that the manuscript does not explicitly report the total LLM query budget, number of generations, or wall-clock time for BEAM relative to the single-layer baselines. This omission limits the ability to isolate the effect of the bi-level architecture. In the revised manuscript, we will add a new table and accompanying text in the Experimental Results section that details these metrics for all methods, including the number of LLM calls per candidate and aggregate search effort. While the bi-level design does incur additional inner-loop evaluations, the structured separation of structure evolution (GA) from placeholder realization (MCTS) is intended to improve exploration efficiency rather than simply increase query volume; the added budget information will allow readers to assess this directly. revision: yes
-
Referee: [Experimental results] Experimental results section: no ablation study isolates the contribution of the Adaptive Memory module or the KA Pipeline, nor are statistical significance tests or variance estimates across runs reported for the CVRP and MIS results. Without these controls the load-bearing performance claims remain under-supported.
Authors: We agree that ablation studies and statistical reporting are necessary to substantiate the contributions of the Adaptive Memory module and KA Pipeline. In the revised manuscript, we will include new ablation experiments that disable each component individually and report the resulting performance degradation on CVRP and MIS tasks. We will also conduct multiple independent runs (at least five) of the full BEAM method and baselines, reporting means with standard deviations. Statistical significance will be assessed via paired t-tests between BEAM and each baseline, with p-values included in the results tables. These additions will be placed in the Experimental Results section to directly support the performance claims. revision: yes
Circularity Check
No circularity in derivation or claims; method is constructive with empirical validation
full rationale
The paper reformulates heuristic design as bi-level optimization and introduces BEAM with GA outer loop, MCTS inner realization, adaptive memory, and KA Pipeline. All performance claims (e.g., 37.84% optimality gap reduction on CVRP) rest on direct experimental comparisons against baselines rather than any self-definitional equations, fitted parameters renamed as predictions, or load-bearing self-citations. No mathematical derivation chain exists that reduces to its own inputs by construction; the architecture is proposed independently and evaluated externally.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Large language models can generate and refine complex, executable heuristic code when guided by bi-level search and adaptive memory.
invented entities (1)
-
Adaptive Memory module
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Designing new metaheuristics: Manual versus automatic approaches,
C. L. Camacho-Villal ´on, T. St ¨utzle, and M. Dorigo, “Designing new metaheuristics: Manual versus automatic approaches,”Intelligent Com- puting, vol. 2, p. 0048, 2023
2023
-
[2]
Recent advances in selection hyper-heuristics,
J. H. Drake, A. Kheiri, E. ¨Ozcan, and E. K. Burke, “Recent advances in selection hyper-heuristics,”European Journal of Operational Research, vol. 285, no. 2, pp. 405–428, 2020
2020
-
[3]
Large language models for code generation: A comprehensive survey of challenges, techniques, evaluation, and applications,
N. Huynh and B. Lin, “Large language models for code generation: A comprehensive survey of challenges, techniques, evaluation, and applications,” 2025
2025
-
[4]
A Survey on Large Language Models for Code Generation
J. Jiang, F. Wang, J. Shen, S. Kim, and S. Kim, “A survey on large language models for code generation,”ArXiv, vol. abs/2406.00515, 2024
work page internal anchor Pith review arXiv 2024
-
[5]
A systematic survey of prompt engineering in large language models: Techniques and applications,
P. Sahoo, A. K. Singh, S. Saha, V . Jain, S. Mondal, and A. Chadha, “A systematic survey of prompt engineering in large language models: Techniques and applications,” 2025
2025
-
[6]
Chain-of-thought prompting elicits reasoning in large language models,
J. Wei, X. Wang, D. Schuurmans, M. Bosma, B. Ichter, F. Xia, E. H. Chi, Q. V . Le, and D. Zhou, “Chain-of-thought prompting elicits reasoning in large language models,” inProceedings of the 36th International Conference on Neural Information Processing Systems, ser. NIPS ’22. Red Hook, NY , USA: Curran Associates Inc., 2022
2022
-
[7]
Reevo: Large language models as hyper-heuristics with reflective evolution,
H. Ye, J. Wang, Z. Cao, F. Berto, C. Hua, H. Kim, J. Park, and G. Song, “Reevo: Large language models as hyper-heuristics with reflective evolution,” inAdvances in Neural Information Processing Systems, 2024
2024
-
[8]
Llamea: A large language model evolutionary algorithm for automatically generating metaheuristics,
N. v. Stein and T. B ¨ack, “Llamea: A large language model evolutionary algorithm for automatically generating metaheuristics,”IEEE Transac- tions on Evolutionary Computation, vol. 29, no. 2, pp. 331–345, 2025
2025
-
[9]
AlphaEvolve: A coding agent for scientific and algorithmic discovery
A. Novikov, N. V ˜u, M. Eisenberger, E. Dupont, P.-S. Huang, A. Z. Wagner, S. Shirobokov, B. Kozlovskii, F. J. R. Ruiz, A. Mehrabian, M. P. Kumar, A. See, S. Chaudhuri, G. Holland, A. Davies, S. Nowozin, P. Kohli, and M. Balog, “AlphaEvolve: A coding agent for scientific and algorithmic discovery,”arXiv preprint arXiv:2506.13131, 2025
work page internal anchor Pith review arXiv 2025
-
[10]
Llm4ad: A platform for algorithm design with large language model,
F. Liu, R. Zhang, Z. Xie, R. Sun, K. Li, X. Lin, Z. Wang, Z. Lu, and Q. Zhang, “Llm4ad: A platform for algorithm design with large language model,” 2024
2024
-
[11]
Evolution of heuristics: Towards efficient automatic algorithm design using large language model,
F. Liu, X. Tong, M. Yuan, X. Lin, F. Luo, Z. Wang, Z. Lu, and Q. Zhang, “Evolution of heuristics: Towards efficient automatic algorithm design using large language model,” inInternational Conference on Machine Learning (ICML), 2024
2024
-
[12]
Planning of heuristics: Strategic planning on large language models with monte carlo tree search for automating heuristic optimization,
C. Mu, X. Zhang, and H. Wang, “Planning of heuristics: Strategic planning on large language models with monte carlo tree search for automating heuristic optimization,” 2025
2025
-
[13]
Finding near-optimal independent sets at scale,
S. Lamm, P. Sanders, C. Schulz, D. Strash, and R. F. Werneck, “Finding near-optimal independent sets at scale,” 2015
2015
-
[14]
Pillay and R
N. Pillay and R. Qu,Introduction to Hyper-Heuristics. Cham: Springer International Publishing, 2018, pp. 3–5
2018
-
[15]
An overview of bilevel opti- mization,
B. Colson, P. Marcotte, and G. Savard, “An overview of bilevel opti- mization,”Annals OR, vol. 153, pp. 235–256, 06 2007
2007
-
[16]
Tree of Thoughts: Deliberate Problem Solving with Large Language Models
S. Yao, D. Yu, J. Zhao, I. Shafran, T. L. Griffiths, Y . Cao, and K. Narasimhan, “Tree of thoughts: Deliberate problem solving with large language models,”ArXiv, vol. abs/2305.10601, 2023
work page internal anchor Pith review arXiv 2023
-
[17]
Outline, then details: Syntactically guided coarse-to-fine code generation,
W. Zheng, S. P. Sharan, A. Jaiswal, K. Wang, Y . Xi, D. Xu, and Z. Wang, “Outline, then details: Syntactically guided coarse-to-fine code generation,” inInternational Conference on Machine Learning, 2023
2023
-
[18]
Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning,
DeepSeek-AI, D. Guo, D. Yang, H. Zhang, J. Song, R. Zhang, R. Xu, Q. Zhu, S. Ma, P. Wang, X. Bi, X. Zhang, X. Yu, Y . Wu, Z. F. Wu, Z. Gou, Z. Shao, Z. Li, Z. Gao, A. Liu, B. Xue, B. Wang, B. Wu, B. Feng, C. Lu, C. Zhao, C. Deng, C. Zhang, C. Ruan, D. Dai, D. Chen, D. Ji, E. Li, F. Lin, F. Dai, F. Luo, G. Hao, G. Chen, G. Li, H. Zhang, H. Bao, H. Xu, H. W...
2025
-
[19]
Optibench: Benchmarking large language models in optimization mod- eling with equivalence-detection evaluation,
Z. Wang, Z. Zhu, Y . Han, Y . Lin, Z. Lin, R. Sun, and T. Ding, “Optibench: Benchmarking large language models in optimization mod- eling with equivalence-detection evaluation,” 2024
2024
-
[20]
Bridging large language models and optimization: A unified framework for text-attributed com- binatorial optimization,
X. Jiang, Y . Wu, Y . Wang, and Y . Zhang, “Bridging large language models and optimization: A unified framework for text-attributed com- binatorial optimization,” 2024
2024
-
[21]
Monte carlo planning with large language model for text-based game agents,
Z. Shi, M. Fang, and L. Chen, “Monte carlo planning with large language model for text-based game agents,” inThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[22]
Optimus: Scalable op- timization modeling with (mi)lp solvers and large language models,
A. AhmadiTeshnizi, W. Gao, and M. Udell, “Optimus: Scalable op- timization modeling with (mi)lp solvers and large language models,” 2024
2024
-
[23]
Llmopt: Learning to define and solve general optimization problems from scratch,
C. Jiang, X. Shu, H. Qian, X. Lu, J. Zhou, A. Zhou, and Y . Yu, “Llmopt: Learning to define and solve general optimization problems from scratch,” 2025
2025
-
[24]
Ma-gts: A multi-agent frame- work for solving complex graph problems in real-world applications,
Z. Yuan, M. Liu, H. Wang, and B. Qin, “Ma-gts: A multi-agent frame- work for solving complex graph problems in real-world applications,” 2025
2025
-
[25]
DRoc: Elevating large language models for complex vehicle routing via decomposed retrieval of constraints,
X. Jiang, Y . Wu, C. Zhang, and Y . Zhang, “DRoc: Elevating large language models for complex vehicle routing via decomposed retrieval of constraints,” inThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[26]
Retrieval-augmented generation for large language models: A survey,
Y . Gao, Y . Xiong, X. Gao, K. Jia, J. Pan, Y . Bi, Y . Dai, J. Sun, M. Wang, and H. Wang, “Retrieval-augmented generation for large language models: A survey,” 2024
2024
-
[27]
Understanding LSTM - a tutorial into long short-term memory recurrent neural networks,
R. C. Staudemeyer and E. R. Morris, “Understanding LSTM - a tutorial into long short-term memory recurrent neural networks,”CoRR, vol. abs/1909.09586, 2019
-
[28]
Large language model-enhanced algorithm selection: Towards comprehensive algorithm representation,
X. Wu, Y . Zhong, J. Wu, B. Jiang, and K. C. Tan, “Large language model-enhanced algorithm selection: Towards comprehensive algorithm representation,” inProceedings of the Thirty-Third International Joint Conference on Artificial Intelligence, IJCAI-24, K. Larson, Ed. Interna- tional Joint Conferences on Artificial Intelligence Organization, 8 2024, pp. 5...
2024
-
[29]
Mathematical discoveries from program search with large language models,
B. Romera-Paredes, M. Barekatain, A. Novikov, M. Balog, M. P. Kumar, E. Dupont, F. J. R. Ruiz, J. Ellenberg, P. Wang, O. Fawziet al., “Mathematical discoveries from program search with large language models,”Nature, vol. 625, no. 7995, pp. 468–475, 2024
2024
-
[30]
Eiben and J
A. Eiben and J. Smith,Introduction To Evolutionary Computing. Springer, 01 2003, vol. 45
2003
-
[31]
Large language models are human-level prompt engineers,
Y . Zhou, A. I. Muresanu, Z. Han, K. Paster, S. Pitis, H. Chan, and J. Ba, “Large language models are human-level prompt engineers,” 2023
2023
-
[32]
Under- standing the importance of evolutionary search in automated heuristic design with large language models,
R. Zhang, F. Liu, X. Lin, Z. Wang, Z. Lu, and Q. Zhang, “Under- standing the importance of evolutionary search in automated heuristic design with large language models,” inParallel Problem Solving from Nature – PPSN XVIII, M. Affenzeller, S. M. Winkler, A. V . Kononova, H. Trautmann, T. Tuˇsar, P. Machado, and T. B¨ack, Eds. Cham: Springer Nature Switzerl...
2024
-
[33]
Monte carlo tree search for comprehensive exploration in llm-based automatic heuristic design,
Z. Zheng, Z. Xie, Z. Wang, and B. Hooi, “Monte carlo tree search for comprehensive exploration in llm-based automatic heuristic design,” 2025
2025
-
[34]
Algorithm discovery with llms: Evolutionary search meets reinforcement learning,
A. Surina, A. Mansouri, L. Quaedvlieg, A. Seddas, M. Viazovska, E. Abbe, and C. Gulcehre, “Algorithm discovery with llms: Evolutionary search meets reinforcement learning,” 04 2025
2025
-
[35]
Regularized evolution for image classifier architecture search,
E. Real, A. Aggarwal, Y . Huang, and Q. Le, “Regularized evolution for image classifier architecture search,”Proceedings of the AAAI Conference on Artificial Intelligence, vol. 33, 02 2018
2018
-
[36]
Darts: Differentiable architecture search,
H. Liu, K. Simonyan, and Y . Yang, “Darts: Differentiable architecture search,” 2019
2019
-
[37]
Diy your easynas for vision: Convolution operation merging, map channel reducing, and search space to supernet conversion tooling,
X. Wang, Z. Lian, J. Lin, C. Xue, and J. Yan, “Diy your easynas for vision: Convolution operation merging, map channel reducing, and search space to supernet conversion tooling,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 45, no. 11, pp. 13 974– 13 990, 2023
2023
-
[38]
A method for parameter calibration and relevance estimation in evolutionary algorithms,
V . Nannen and A. Eiben, “A method for parameter calibration and relevance estimation in evolutionary algorithms,” inGenetic and Evolu- tionary Computation Conference, vol. 1, 07 2006, pp. 183–190
2006
-
[39]
Versatile genetic algorithm-bayesian optimization(ga-bo) bi-level optimization for decoupling capacitor place- ment,
H. Park, H. Kim, H. Kim, J. Park, S. Choi, J. Kim, K. Son, H. Suh, T. Kim, J. Ahn, and J. Kim, “Versatile genetic algorithm-bayesian optimization(ga-bo) bi-level optimization for decoupling capacitor place- ment,” inIEEE 32nd Conference on Electrical Performance of Electronic Packaging and Systems (EPEPS), 10 2023, pp. 1–3. IEEE TRANSACTIONS ON NEURAL NET...
2023
-
[40]
Evolve cost-aware acquisition functions using large language models,
Y . Yao, F. Liu, J. Cheng, and Q. Zhang, “Evolve cost-aware acquisition functions using large language models,” inParallel Problem Solving from Nature – PPSN XVIII, M. Affenzeller, S. M. Winkler, A. V . Kononova, H. Trautmann, T. Tu ˇsar, P. Machado, and T. B ¨ack, Eds. Cham: Springer Nature Switzerland, 2024, pp. 374–390
2024
-
[41]
Hsevo: Elevating automatic heuristic design with diversity-driven harmony search and genetic algo- rithm using llms,
P. V . T. Dat, L. Doan, and H. T. T. Binh, “Hsevo: Elevating automatic heuristic design with diversity-driven harmony search and genetic algo- rithm using llms,” inThe 39th Annual AAAI Conference on Artificial Intelligence, 2025
2025
-
[42]
In-the-loop hyper-parameter optimization for llm-based automated design of heuristics,
N. van Stein, D. Vermetten, and T. B ¨ack, “In-the-loop hyper-parameter optimization for llm-based automated design of heuristics,”ACM Trans- actions on Evolutionary Learning and Optimization, Apr. 2025
2025
-
[43]
Using code generation to solve open instances of combi- natorial design problems,
C. D. Rosin, “Using code generation to solve open instances of combi- natorial design problems,” 2025
2025
-
[44]
Using modular programming strategy to practice computer programming: A case study,
W. Sun, X. Sun, and X. Wang, “Using modular programming strategy to practice computer programming: A case study,” inASEE Annual Conference and Exposition, 06 2012
2012
-
[45]
Evolutionary computation in the era of large language model: Survey and roadmap,
X. Wu, S. hao Wu, J. Wu, L. Feng, and K. C. Tan, “Evolutionary computation in the era of large language model: Survey and roadmap,” 2024
2024
-
[46]
An elitist polynomial mutation operator for improved performance of moeas in computer networks,
K. Liagkouras and K. Metaxiotis, “An elitist polynomial mutation operator for improved performance of moeas in computer networks,” in2013 22nd International Conference on Computer Communication and Networks (ICCCN), 2013, pp. 1–5
2013
-
[47]
Debugbench: Evaluating debugging capability of large language models,
R. Tian, Y . Ye, Y . Qin, X. Cong, Y . Lin, Y . Pan, Y . Wu, H. Hui, W. Liu, Z. Liu, and M. Sun, “Debugbench: Evaluating debugging capability of large language models,” 2024
2024
-
[48]
Completely derandomized self- adaptation in evolution strategies,
N. Hansen and A. Ostermeier, “Completely derandomized self- adaptation in evolution strategies,”Evolutionary Computation, vol. 9, pp. 159–195, 06 2001
2001
-
[49]
Restart scheduling for genetic algorithms,
A. Fukunaga, “Restart scheduling for genetic algorithms,”Lecture Notes in Computer Science, 05 2002
2002
-
[50]
A novel multi- level population hybrid search evolution algorithm for constrained multi- objective optimization problems,
C. Li, Y . Liu, Y . Zhang, M. Xu, J. Xiao, and J. Zhou, “A novel multi- level population hybrid search evolution algorithm for constrained multi- objective optimization problems,”Journal of King Saud University - Computer and Information Sciences, vol. 34, no. 10, Part B, pp. 9071– 9087, 2022
2022
-
[51]
J. K. Lenstra and E. Aarts,Local Search in Combinatorial Optimization. Princeton University Press, 2003
2003
-
[52]
Cost-aware bayesian optimization,
E. H. Lee, V . Perrone, C. Archambeau, and M. W. Seeger, “Cost-aware bayesian optimization,”CoRR, vol. abs/2003.10870, 2020
-
[53]
On bayesian methods for seeking the extremum,
J. Mockus, “On bayesian methods for seeking the extremum,” in Optimization Techniques, 1974
1974
-
[54]
Practical bayesian optimiza- tion of machine learning algorithms,
J. Snoek, H. Larochelle, and R. P. Adams, “Practical bayesian optimiza- tion of machine learning algorithms,” inAdvances in Neural Information Processing Systems, F. Pereira, C. Burges, L. Bottou, and K. Weinberger, Eds., vol. 25. Curran Associates, Inc., 2012
2012
-
[55]
A hybrid genetic algorithm for multidepot and periodic vehicle routing problems,
T. Vidal, T. G. Crainic, M. Gendreau, N. Lahrichi, and W. Rei, “A hybrid genetic algorithm for multidepot and periodic vehicle routing problems,” Operations Research, vol. 60, pp. 611–624, 06 2012
2012
-
[56]
A simple and effective evolutionary algorithm for the vehicle routing problem,
C. Prins, “A simple and effective evolutionary algorithm for the vehicle routing problem,”Computers & Operations Research, vol. 31, no. 12, pp. 1985–2002, 2004
1985
-
[57]
van Stein and T
N. van Stein and T. B ¨ack, “Llamea,” Sep. 2024, accessed: YYYY-MM- DD
2024
-
[58]
Zero bubble pipeline parallelism,
P. Qi, X. Wan, G. Huang, and M. Lin, “Zero bubble pipeline parallelism,” 2023
2023
-
[59]
Deepseek-v3 technical report,
DeepSeek-AI, A. Liu, B. Feng, B. Xue, B. Wang, B. Wu, C. Lu, C. Zhao, C. Deng, C. Zhang, C. Ruan, D. Dai, D. Guo, D. Yang, D. Chen, D. Ji, E. Li, F. Lin, F. Dai, F. Luo, G. Hao, G. Chen, G. Li, H. Zhang, H. Bao, H. Xu, H. Wang, H. Zhang, H. Ding, H. Xin, H. Gao, H. Li, H. Qu, J. L. Cai, J. Liang, J. Guo, J. Ni, J. Li, J. Wang, J. Chen, J. Chen, J. Yuan, J...
2025
-
[60]
Pipedream: generalized pipeline parallelism for dnn training,
D. Narayanan, A. Harlap, A. Phanishayee, V . Seshadri, N. R. Devanur, G. R. Ganger, P. B. Gibbons, and M. Zaharia, “Pipedream: generalized pipeline parallelism for dnn training,” inProceedings of the 27th ACM Symposium on Operating Systems Principles, ser. SOSP ’19. New York, NY , USA: Association for Computing Machinery, 2019, p. 1–15
2019
-
[61]
DIFUSCO: Graph-based diffusion solvers for combinatorial optimization,
Z. Sun and Y . Yang, “DIFUSCO: Graph-based diffusion solvers for combinatorial optimization,” inThirty-seventh Conference on Neural Information Processing Systems, 2023
2023
-
[62]
Regularized langevin dynamics for combinatorial optimization,
S. Feng and Y . Yang, “Regularized langevin dynamics for combinatorial optimization,” 2025
2025
-
[63]
A diffusion model framework for unsupervised neural combinatorial optimization,
S. Sanokowski, S. Hochreiter, and S. Lehner, “A diffusion model framework for unsupervised neural combinatorial optimization,” 2024
2024
-
[64]
Coexpander: Adaptive solution expansion for combinatorial optimization,
J. Ma, W. Pan, Y . Li, and J. Yan, “Coexpander: Adaptive solution expansion for combinatorial optimization,” inInternational Conference on Machine Learning (ICML), 05 2025
2025
-
[65]
Goal: A generalist com- binatorial optimization agent learner,
D. Drakulic, S. Michel, and J.-M. Andreoli, “Goal: A generalist com- binatorial optimization agent learner,” 2025
2025
-
[66]
Kahip v3.00 – karlsruhe high quality partitioning – user guide,
P. Sanders and C. Schulz, “Kahip v3.00 – karlsruhe high quality partitioning – user guide,” 2020
2020
-
[67]
Perturbation operator analysis on ils-rvnd algorithm to solve cvrp,
M. Ngisomuddin and D. Satyananda, “Perturbation operator analysis on ils-rvnd algorithm to solve cvrp,” inTHE 3RD INTERNATIONAL CONFERENCE ON MATHEMATICS AND SCIENCE EDUCATION (ICOMSE), vol. 2215, 04 2020, p. 070015. APPENDIX A. Additional Comparison Our usage of MCTS is fundamentally different from PoH and MCTS-AHD as detailed in Table X. B. Diversity Di...
2020
-
[68]
Put your main structure in the following function: {baseline}
-
[69]
You should not think too much of how to realize the subproblems
You should look at the *heuristic database* first, and then think: - How can you deconstruct the big problem into small subproblems step by step? - What are the main goal of the subproblems that are needed to complete the heuristic designing? Your thoughts should guide you to complete the heuristic design in step 3. You should not think too much of how to...
-
[70]
You can call external functions to represent or compose every subproblems
In this code you needn’t implement everything and utilize the idea of **modularization program- ming**. You can call external functions to represent or compose every subproblems. There are two cases of this external function: (The first case has a higher priority) I. The function already exists in the *heuristic database* (which I’ll give you later). You ...
-
[71]
Enclose your hyperparameter list with two ”#Hyperparameter#”
Put the definitions of all the hyperparameters on top of everything. Enclose your hyperparameter list with two ”#Hyperparameter#”. Your hyperparame- ters must be float or int. If a hyperparameter is int, add ”# int” right after the definition inline
-
[72]
Include MAX TIME ={timeout}in your hyperparameter list
We only have{timeout}seconds to perform the algorithm, so you must set your code a timeout- second-clock. Include MAX TIME ={timeout}in your hyperparameter list. In the code, please make frequent check whether the time is up
-
[73]
{prior knowledge} f) fill 1func.txt:This prompt is used in MCTS, where LLM need to temperately fill in only one function to choose the best one to really fill into the structure
Let your code print out the best objectives after each iteration. {prior knowledge} f) fill 1func.txt:This prompt is used in MCTS, where LLM need to temperately fill in only one function to choose the best one to really fill into the structure. An algorithm solving{problem}will be given be- low, with some of the functions realized and others unrealized. {...
2026
-
[74]
Your design must fully satisfy the requirements specified in the provided function templates
-
[75]
Your design must maintain the same parameters as the given function templates
-
[76]
Your response must include the complete heuristic code with all necessary functions filled in
Your design should work correctly within the context of the heuristic, which will be provided below. Your response must include the complete heuristic code with all necessary functions filled in. Your response outputs Python code and nothing else. Format your code as a Python code string: ”```python ...```”. k) heubase common.txt:This prompt is used to pr...
2026
-
[77]
Maintains three-phase structure but with improved ,→time allocation
-
[78]
Uses capacity-based scoring inspired by elitist code
-
[79]
Incorporates more aggressive fill threshold from ,→elitist version
-
[80]
Optimized time checks and weight distribution """ start_time = time.time() # Phase 0: Fast exact fit check (immediate return if ,→found) if time.time() - start_time > MAX_TIME: return np.zeros_like(bins_remain_cap) exact_fit_mask = (bins_remain_cap == item) if np.any(exact_fit_mask): return np.where(exact_fit_mask, np.inf, -np.inf) # Initialize scores wit...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.