Recognition: unknown
Grasp in Gaussians: Fast Monocular Reconstruction of Dynamic Hand-Object Interactions
Pith reviewed 2026-05-10 14:57 UTC · model grok-4.3
The pith
GraG reconstructs dynamic hand-object interactions from monocular video 6.4 times faster than prior work using a compact Sum-of-Gaussians representation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
GraG recovers temporally coherent 3D hand-object interactions by initializing object pose and geometry from a video-adapted SAM3D pipeline then converting the dense representation to a lightweight Sum-of-Gaussians via subsampling, while refining hand motion from off-the-shelf monocular pose estimates using simple 2D joint and depth alignment losses, without per-frame detailed appearance refinement.
What carries the argument
Compact Sum-of-Gaussians (SoG) representation obtained by subsampling dense Gaussian initializations, which supports efficient tracking of both object geometry and hand articulation while preserving fidelity.
If this is right
- Long sequences of hand-object interactions become practical to reconstruct at interactive speeds.
- Object surface accuracy rises by 13.4 percent relative to prior neural methods.
- Hand per-joint position error drops by more than 65 percent while articulation stays stable.
- The pipeline runs without repeated optimization of detailed 3D appearance models per frame.
Where Pith is reading between the lines
- The subsampling step that turns dense Gaussians into SoG could be applied to other tracking tasks where full neural rendering is too slow.
- If similar pretrained initializers exist for new object categories, the same tracking strategy might extend beyond hands without retraining.
- Avoiding per-frame appearance refinement opens the door to running the method on live video streams rather than recorded sequences.
Load-bearing premise
The method assumes off-the-shelf pretrained models supply initializations accurate enough that simple 2D alignment losses and SoG subsampling can recover stable 3D motion without per-frame detailed appearance refinement.
What would settle it
Applying GraG to a video sequence where the pretrained SAM3D and hand-pose initializers contain large errors and checking whether the resulting 3D tracks remain coherent would directly test whether the simple refinement steps suffice.
Figures




read the original abstract
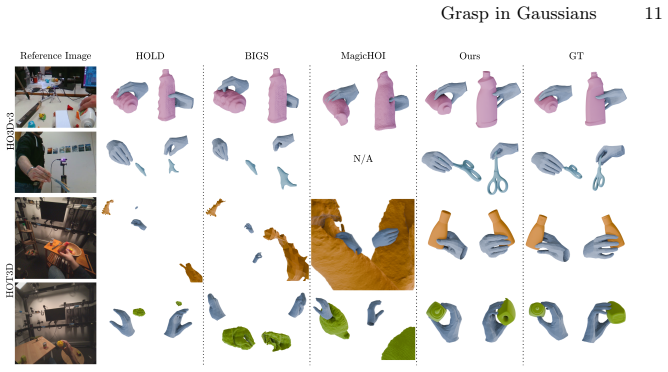
We present Grasp in Gaussians (GraG), a fast and robust method for reconstructing dynamic 3D hand-object interactions from a single monocular video. Unlike recent approaches that optimize heavy neural representations, our method focuses on tracking the hand and the object efficiently, once initialized from pretrained large models. Our key insight is that accurate and temporally stable hand-object motion can be recovered using a compact Sum-of-Gaussians (SoG) representation, revived from classical tracking literature and integrated with generative Gaussian-based initializations. We initialize object pose and geometry using a video-adapted SAM3D pipeline, then convert the resulting dense Gaussian representation into a lightweight SoG via subsampling. This compact representation enables efficient and fast tracking while preserving geometric fidelity. For the hand, we adopt a complementary strategy: starting from off-the-shelf monocular hand pose initialization, we refine hand motion using simple yet effective 2D joint and depth alignment losses, avoiding per-frame refinement of a detailed 3D hand appearance model while maintaining stable articulation. Extensive experiments on public benchmarks demonstrate that GraG reconstructs temporally coherent hand-object interactions on long sequences 6.4x faster than prior work while improving object reconstruction by 13.4% and reducing hand's per-joint position error by over 65%.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents Grasp in Gaussians (GraG), a fast monocular method for reconstructing dynamic 3D hand-object interactions. It initializes object geometry/pose from a video-adapted SAM3D pipeline (converted to subsampled Sum-of-Gaussians), initializes hand pose from off-the-shelf monocular estimators, and refines motion via simple 2D joint and depth alignment losses without per-frame dense appearance optimization. Experiments on public benchmarks claim 6.4x faster reconstruction than prior work on long sequences, 13.4% better object reconstruction, and over 65% reduction in hand per-joint position error.
Significance. If the performance claims hold, the work would provide a practical contribution to efficient 3D hand-object reconstruction by reviving compact classical Sum-of-Gaussians representations and integrating them with modern pretrained generative initializations. The emphasis on speed and avoidance of heavy per-frame neural refinement is a strength that could enable broader use in real-time applications. However, the heavy reliance on external pretrained models for initialization reduces the self-contained novelty and makes the gains harder to attribute directly to the proposed tracking strategy.
major comments (2)
- [Abstract] Abstract: The central claims of 6.4x speedup, 13.4% object improvement, and >65% hand error reduction on long sequences rest on the assumption that SAM3D and monocular hand-pose initializations are already sufficiently accurate that simple 2D alignment losses plus SoG subsampling can recover stable 3D motion without per-frame appearance refinement or drift. No ablations or robustness tests are reported for higher initialization error regimes, which is load-bearing for the temporally coherent reconstruction claims.
- [Method] Method description (initialization and optimization sections): The pipeline converts dense SAM3D output to lightweight SoG via subsampling and optimizes hand motion only with 2D joint + depth losses. Without quantitative evidence (e.g., error histograms or failure-case analysis) showing that these initializations lie close enough to true 3D motion for the lightweight tracker to succeed, the reported gains cannot be confidently separated from the quality of the off-the-shelf models.
minor comments (2)
- [Notation/Method] The Sum-of-Gaussians (SoG) representation is used throughout but lacks an early formal definition or equation; adding one would improve clarity for readers unfamiliar with the classical tracking literature.
- [Experiments] Timing results for the 6.4x speedup claim should explicitly state the hardware platform and whether baselines were re-run under identical conditions.
Simulated Author's Rebuttal
We thank the referee for the constructive review and for acknowledging the practical value of our efficient reconstruction pipeline. We respond to each major comment below and commit to revisions that directly address the concerns about initialization quality and attribution of gains.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claims of 6.4x speedup, 13.4% object improvement, and >65% hand error reduction on long sequences rest on the assumption that SAM3D and monocular hand-pose initializations are already sufficiently accurate that simple 2D alignment losses plus SoG subsampling can recover stable 3D motion without per-frame appearance refinement or drift. No ablations or robustness tests are reported for higher initialization error regimes, which is load-bearing for the temporally coherent reconstruction claims.
Authors: We agree that the reported performance depends on the quality of the SAM3D and monocular hand-pose initializers. GraG is explicitly designed to leverage current high-quality pretrained models for initialization and then apply lightweight tracking; this is stated in the abstract and method. To strengthen the claims, we will add a dedicated robustness ablation in the revision: we will inject controlled noise into the initial poses and geometries at multiple levels, report tracking success rates, final reconstruction errors, and drift metrics, and include these results in a new table and discussion. This will delineate the operating regime of the SoG tracker. revision: yes
-
Referee: [Method] Method description (initialization and optimization sections): The pipeline converts dense SAM3D output to lightweight SoG via subsampling and optimizes hand motion only with 2D joint + depth losses. Without quantitative evidence (e.g., error histograms or failure-case analysis) showing that these initializations lie close enough to true 3D motion for the lightweight tracker to succeed, the reported gains cannot be confidently separated from the quality of the off-the-shelf models.
Authors: We concur that explicit quantitative evidence on initialization-to-final error reduction would help isolate the contribution of the tracking stage. The current experiments already compare against prior methods on identical benchmarks and initializers, showing both accuracy gains and the 6.4x speedup from avoiding per-frame dense optimization. In the revision we will expand the method and experiments sections with (i) histograms of per-frame initialization vs. optimized errors on the evaluated sequences and (ii) selected failure-case visualizations with corresponding error analysis. These additions will provide the requested evidence without altering the core pipeline. revision: yes
Circularity Check
No significant circularity; pipeline uses external initializations and empirical validation
full rationale
The paper presents an engineering pipeline for hand-object reconstruction: object geometry/pose is initialized from a video-adapted SAM3D (external pretrained model) then subsampled to a compact Sum-of-Gaussians (SoG) representation drawn from classical tracking literature; hand motion starts from an off-the-shelf monocular pose estimator and is refined only via 2D joint and depth alignment losses without per-frame dense appearance optimization. Reported gains (6.4x speed, 13.4% object improvement, >65% hand-error reduction) are framed as experimental outcomes on public benchmarks, not as first-principles derivations or predictions that reduce to quantities defined inside the paper. No equations, fitted parameters, or self-citations are shown that would make any central claim equivalent to its own inputs by construction. The approach is therefore self-contained against external benchmarks and does not trigger any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
free parameters (2)
- SoG subsampling density
- 2D alignment loss weights
axioms (2)
- domain assumption Pretrained monocular estimators supply sufficiently accurate initial hand poses and object geometry
- domain assumption Object and hand motions remain trackable with rigid or articulated SoG models over long sequences
Reference graph
Works this paper leans on
-
[1]
In: Thirteenth Interna- tional Conference on 3D Vision (2026)
Aytekin, A.I., Rhodin, H., Dabral, R., Theobalt, C.: Follow my hold: Hand-object interaction reconstruction through geometric guidance. In: Thirteenth Interna- tional Conference on 3D Vision (2026)
2026
-
[2]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Banerjee, P., Shkodrani, S., Moulon, P., Hampali, S., Han, S., Zhang, F., Zhang, L., Fountain, J., Miller, E., Basol, S., et al.: Hot3d: Hand and object tracking in 3d from egocentric multi-view videos. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 7061–7071 (2025)
2025
-
[3]
In: Automatic Face and Gesture Recognition
Bretzner, L., Laptev, I., Lindeberg, T.: Hand gesture recognition using multi-scale colour features, hierarchical models and particle filtering. In: Automatic Face and Gesture Recognition. pp. 423–428 (2002).https://doi.org/10.1109/AFGR.2002. 1004190
-
[4]
In: Proceedings of the IEEE/CVF international conference on computer vision
Cao, Z., Radosavovic, I., Kanazawa, A., Malik, J.: Reconstructing hand-object interactions in the wild. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 12417–12426 (2021)
2021
-
[5]
SAM 3: Segment Anything with Concepts
Carion, N., Gustafson, L., Hu, Y.T., Debnath, S., Hu, R., Suris, D., Ryali, C., Alwala,K.V.,Khedr,H.,Huang,A.,etal.:Sam3:Segmentanythingwithconcepts. arXiv preprint arXiv:2511.16719 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
SAM 3D: 3Dfy Anything in Images
Chen, X., Chu, F.J., Gleize, P., Liang, K.J., Sax, A., Tang, H., Wang, W., Guo, M., Hardin, T., Li, X., et al.: Sam 3d: 3dfy anything in images. arXiv preprint arXiv:2511.16624 (2025)
work page internal anchor Pith review arXiv 2025
-
[7]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Collins, J., Goel, S., Deng, K., Luthra, A., Xu, L., Gundogdu, E., Zhang, X., Vicente, T.F.Y., Dideriksen, T., Arora, H., et al.: Abo: Dataset and benchmarks for real-world 3d object understanding. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 21126–21136 (2022)
2022
-
[8]
Comanici, G., Bieber, E., Schaekermann, M., Pasupat, I., Sachdeva, N., Dhillon, I., Blistein, M., Ram, O., Zhang, D., Rosen, E., et al.: Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities. arXiv preprint arXiv:2507.06261 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
DyTact: Capturing Dynamic Contacts in Hand-Object Manipulation
Cong, X., Xing, A., Pokhariya, C., Fu, R., Sridhar, S.: Dytact: Capturing dynamic contacts in hand-object manipulation. arXiv preprint arXiv:2506.03103 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Corona, E., Pumarola, A., Alenya, G., Moreno-Noguer, F., Rogez, G.: Ganhand: Predicting human grasp affordances in multi-object scenes. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 5031–5041 (2020)
2020
-
[11]
Advances in Neural Information Processing Systems36, 35799–35813 (2023)
Deitke, M., Liu, R., Wallingford, M., Ngo, H., Michel, O., Kusupati, A., Fan, A., Laforte, C., Voleti, V., Gadre, S.Y., et al.: Objaverse-xl: A universe of 10m+ 3d objects. Advances in Neural Information Processing Systems36, 35799–35813 (2023)
2023
-
[12]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Deitke, M., Schwenk, D., Salvador, J., Weihs, L., Michel, O., VanderBilt, E., Schmidt, L., Ehsani, K., Kembhavi, A., Farhadi, A.: Objaverse: A universe of annotated 3d objects. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 13142–13153 (2023)
2023
-
[13]
In: CVPR (2015)
Elhayek, A., Aguiar, E., Jain, A., Tompson, J., Pishchulin, L., Andriluka, M., Bregler, C., Schiele, B., Theobalt, C.: Efficient ConvNet-based marker-less motion capture in general scenes with a low number of cameras. In: CVPR (2015)
2015
-
[14]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Fan, Z., Parelli, M., Kadoglou, M.E., Chen, X., Kocabas, M., Black, M.J., Hilliges, O.: Hold: Category-agnostic 3d reconstruction of interacting hands and objects from video. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 494–504 (2024) 16 A. I. Aytekin et al
2024
-
[15]
In: Pro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition
Fan, Z., Taheri, O., Tzionas, D., Kocabas, M., Kaufmann, M., Black, M.J., Hilliges, O.: Arctic: A dataset for dexterous bimanual hand-object manipulation. In: Pro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 12943–12954 (2023)
2023
-
[16]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Hampali, S., Hodan,T., Tran, L., Ma, L., Keskin,C., Lepetit,V.: In-hand 3d object scanning from an rgb sequence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 17079–17088 (2023)
2023
-
[17]
arXiv preprint arXiv:2107.00887 (2021)
Hampali, S., Sarkar, S.D., Lepetit, V.: Ho-3d_v3: Improving the accuracy of hand- object annotations of the ho-3d dataset. arXiv preprint arXiv:2107.00887 (2021)
-
[18]
Cam- bridge University Press, Cambridge, England, 2 edn
Hartley, R., Zisserman, A.: Multiple View Geometry in Computer Vision. Cam- bridge University Press, Cambridge, England, 2 edn. (Jan 2011)
2011
-
[19]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Hasson, Y., Tekin, B., Bogo, F., Laptev, I., Pollefeys, M., Schmid, C.: Leveraging photometric consistency over time for sparsely supervised hand-object reconstruc- tion. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 571–580 (2020)
2020
-
[20]
In: 2021 International Conference on 3D Vision (3DV)
Hasson, Y., Varol, G., Schmid, C., Laptev, I.: Towards unconstrained joint hand- object reconstruction from rgb videos. In: 2021 International Conference on 3D Vision (3DV). pp. 659–668. IEEE (2021)
2021
-
[21]
In: Proceed- ings of the IEEE/CVF conference on computer vision and pattern recognition
Hasson, Y., Varol, G., Tzionas, D., Kalevatykh, I., Black, M.J., Laptev, I., Schmid, C.: Learning joint reconstruction of hands and manipulated objects. In: Proceed- ings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 11807–11816 (2019)
2019
-
[22]
In: SIGGRAPH Asia 2022 Conference Papers
Huang, D., Ji, X., He, X., Sun, J., He, T., Shuai, Q., Ouyang, W., Zhou, X.: Reconstructing hand-held objects from monocular video. In: SIGGRAPH Asia 2022 Conference Papers. pp. 1–9 (2022)
2022
-
[23]
In: 2020 Inter- national Conference on 3D Vision (3DV)
Karunratanakul, K., Yang, J., Zhang, Y., Black, M.J., Muandet, K., Tang, S.: Grasping field: Learning implicit representations for human grasps. In: 2020 Inter- national Conference on 3D Vision (3DV). pp. 333–344. IEEE (2020)
2020
-
[24]
ACM Transactions on Graphics42(4) (July 2023),https://repo-sam.inria.fr/fungraph/3d-gaussian-splatting/
Kerbl, B., Kopanas, G., Leimkühler, T., Drettakis, G.: 3d gaussian splatting for real-time radiance field rendering. ACM Transactions on Graphics42(4) (July 2023),https://repo-sam.inria.fr/fungraph/3d-gaussian-splatting/
2023
-
[25]
arXiv preprint arXiv:2506.16504 , year=
Lai, Z., Zhao, Y., Liu, H., Zhao, Z., Lin, Q., Shi, H., Yang, X., Yang, M., Yang, S., Feng, Y., et al.: Hunyuan3d 2.5: Towards high-fidelity 3d assets generation with ultimate details. arXiv preprint arXiv:2506.16504 (2025)
-
[26]
GitHub repository (January 2025),https://github.com/devinli123/MV-SAM3D
Li, B.: MV-SAM3D: SAM 3d objects with multi-view images. GitHub repository (January 2025),https://github.com/devinli123/MV-SAM3D
2025
-
[27]
Depth Anything 3: Recovering the Visual Space from Any Views
Lin, H., Chen, S., Liew, J.H., Chen, D.Y., Li, Z., Shi, G., Feng, J., Kang, B.: Depth anything 3: Recovering the visual space from any views. arXiv preprint arXiv:2511.10647 (2025)
work page internal anchor Pith review arXiv 2025
-
[28]
In: Proceedings of the IEEE/CVF inter- national conference on computer vision
Liu, R., Wu, R., Van Hoorick, B., Tokmakov, P., Zakharov, S., Vondrick, C.: Zero- 1-to-3: Zero-shot one image to 3d object. In: Proceedings of the IEEE/CVF inter- national conference on computer vision. pp. 9298–9309 (2023)
2023
-
[29]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Liu, S., Jiang, H., Xu, J., Liu, S., Wang, X.: Semi-supervised 3d hand-object poses estimation with interactions in time. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 14687–14697 (2021)
2021
-
[30]
In: The Thirty-ninth Annual Conference on Neural Information Processing Systems (2025) Grasp in Gaussians 17
Liu, X., Ren, P., Qi, Q., Sun, H., Zhuang, Z., Wang, J., Liao, J., Wang, J.: Gen- eralizable hand-object modeling from monocular rgb images via 3d gaussians. In: The Thirty-ninth Annual Conference on Neural Information Processing Systems (2025) Grasp in Gaussians 17
2025
-
[31]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Liu, Y., Long, X., Yang, Z., Liu, Y., Habermann, M., Theobalt, C., Ma, Y., Wang, W.: Easyhoi: Unleashing the power of large models for reconstructing hand-object interactions in the wild. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 7037–7047 (2025)
2025
-
[32]
Decoupled Weight Decay Regularization
Loshchilov, I., Hutter, F.: Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[33]
CVIU104(2), 90–126 (2006).https://doi
Moeslund, T.B., Hilton, A., Krüger, V.: A survey of advances in vision-based hu- man motion capture and analysis. CVIU104(2), 90–126 (2006).https://doi. org/10.1016/j.cviu.2006.08.002
-
[34]
In: Proceedings of the Computer Vision and Pattern Recogni- tion Conference
On, J., Gwak, K., Kang, G., Cha, J., Hwang, S., Hwang, H., Baek, S.: Bigs: Bi- manual category-agnostic interaction reconstruction from monocular videos via 3d gaussian splatting. In: Proceedings of the Computer Vision and Pattern Recogni- tion Conference. pp. 17437–17447 (2025)
2025
-
[35]
PAMI25(9), 1182–1187 (2003)
Plankers, R., Fua, P.: Articulated soft objects for multiview shape and motion capture. PAMI25(9), 1182–1187 (2003)
2003
-
[36]
DreamFusion: Text-to-3D using 2D Diffusion
Poole, B., Jain, A., Barron, J.T., Mildenhall, B.: Dreamfusion: Text-to-3d using 2d diffusion. arXiv preprint arXiv:2209.14988 (2022)
work page internal anchor Pith review arXiv 2022
-
[37]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Rajič, F., Xu, H., Mihajlovic, M., Li, S., Demir, I., Gündoğdu, E., Ke, L., Prokudin, S., Pollefeys, M., Tang, S.: Multi-view 3d point tracking. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 59–68 (2025)
2025
-
[38]
Ren, C.Y., Prisacariu, V., Kaehler, O., Reid, I., Murray, D.: 3D tracking of mul- tiple objects with identical appearance using RGB-D input. In: 3DV. pp. 47–54 (2014).https://doi.org/10.1109/3DV.2014.39,http://ieeexplore.ieee.org/ lpdocs/epic03/wrapper.htm?arnumber=7035808
-
[39]
ACM Transactions on Graphics (TOG)35(6), 1–11 (2016)
Rhodin, H., Richardt, C., Casas, D., Insafutdinov, E., Shafiei, M., Seidel, H.P., Schiele, B., Theobalt, C.: Egocap: egocentric marker-less motion capture with two fisheye cameras. ACM Transactions on Graphics (TOG)35(6), 1–11 (2016)
2016
-
[40]
In: European conference on computer vision
Rhodin, H., Robertini, N., Casas, D., Richardt, C., Seidel, H.P., Theobalt, C.: General automatic human shape and motion capture using volumetric contour cues. In: European conference on computer vision. pp. 509–526. Springer (2016)
2016
-
[41]
In: Proceedings of the IEEE international conference on computer vision
Rhodin, H., Robertini, N., Richardt, C., Seidel, H.P., Theobalt, C.: A versatile scene model with differentiable visibility applied to generative pose estimation. In: Proceedings of the IEEE international conference on computer vision. pp. 765–773 (2015)
2015
-
[42]
Romero, J., Tzionas, D., Black, M.J.: Embodied hands: Modeling and capturing hands and bodies together. arXiv preprint arXiv:2201.02610 (2022)
-
[43]
In: Proceedings of the IEEE/CVF confer- ence on computer vision and pattern recognition
Sarlin, P.E., Cadena, C., Siegwart, R., Dymczyk, M.: From coarse to fine: Robust hierarchical localization at large scale. In: Proceedings of the IEEE/CVF confer- ence on computer vision and pattern recognition. pp. 12716–12725 (2019)
2019
-
[44]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Sarlin, P.E., DeTone, D., Malisiewicz, T., Rabinovich, A.: Superglue: Learning feature matching with graph neural networks. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 4938–4947 (2020)
2020
-
[45]
In: Proceedings IEEE Workshop on Stereo and Multi-Baseline Vision (SMBV 2001)
Scharstein, D., Szeliski, R., Zabih, R.: A taxonomy and evaluation of dense two- frame stereo correspondence algorithms. In: Proceedings IEEE Workshop on Stereo and Multi-Baseline Vision (SMBV 2001). IEEE Comput. Soc (2002)
2001
-
[46]
In: CVPR (2015),http://handtracker
Sridhar, S., Mueller, F., Oulasvirta, A., Theobalt, C.: Fast and robust hand track- ing using detection-guided optimization. In: CVPR (2015),http://handtracker. mpi-inf.mpg.de/projects/FastHandTracker/
2015
-
[47]
In: 2014 2nd International Conference on 3D Vision
Sridhar, S., Rhodin, H., Seidel, H.P., Oulasvirta, A., Theobalt, C.: Real-time hand tracking using a sum of anisotropic gaussians model. In: 2014 2nd International Conference on 3D Vision. vol. 1, pp. 319–326. IEEE (2014) 18 A. I. Aytekin et al
2014
-
[48]
International Journal of Computer Vision130(4), 1008–1030 (2022)
Stoiber, M., Pfanne, M., Strobl, K.H., Triebel, R., Albu-Schäffer, A.: Srt3d: A sparse region-based 3d object tracking approach for the real world. International Journal of Computer Vision130(4), 1008–1030 (2022)
2022
-
[49]
In: 2011 international conference on computer vision
Stoll, C., Hasler, N., Gall, J., Seidel, H.P., Theobalt, C.: Fast articulated motion tracking using a sums of gaussians body model. In: 2011 international conference on computer vision. pp. 951–958. IEEE (2011)
2011
-
[50]
Texts in computer science, Springer, London, Eng- land (Oct 2010)
Szeliski, R.: Computer Vision. Texts in computer science, Springer, London, Eng- land (Oct 2010)
2010
-
[51]
Team, V., Hong, W., Yu, W., et al.: Glm-4.5 v and glm-4.1 v-thinking: Towards versatile multimodal reasoning with scalable reinforcement learning. arXiv preprint arXiv:2507.01006 (2025)
work page internal anchor Pith review arXiv 2025
-
[52]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Tekin, B., Bogo, F., Pollefeys, M.: H+ o: Unified egocentric recognition of 3d hand-object poses and interactions. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 4511–4520 (2019)
2019
-
[53]
Tomasi, C., Kanade, T.: Shape and motion from image streams under orthography: a factorization method. Int. J. Comput. Vis.9(2), 137–154 (Nov 1992)
1992
-
[54]
arXiv preprint arXiv:2508.05506 (2025)
Wang, S., He, H., Parelli, M., Gebhardt, C., Fan, Z., Song, J.: Magichoi: Leveraging 3d priors for accurate hand-object reconstruction from short monocular video clips. arXiv preprint arXiv:2508.05506 (2025)
- [55]
-
[56]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Xiang, J., Lv, Z., Xu, S., Deng, Y., Wang, R., Zhang, B., Chen, D., Tong, X., Yang, J.: Structured 3d latents for scalable and versatile 3d generation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 21469–21480 (June 2025)
2025
-
[57]
In: Proceedings of the IEEE/CVF international conference on computer vision
Yang, L., Zhan, X., Li, K., Xu, W., Li, J., Lu, C.: Cpf: Learning a contact poten- tial field to model the hand-object interaction. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 11097–11106 (2021)
2021
-
[58]
Ye, C., Wu, Y., Lu, Z., Chang, J., Guo, X., Zhou, J., Zhao, H., Han, X.: Hi3dgen: High-fidelity 3d geometry generation from images via normal bridging. arXiv preprint arXiv:2503.222363, 2 (2025)
-
[59]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Ye, Y., Gupta, A., Tulsiani, S.: What’s in your hands? 3d reconstruction of generic objects in hands. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 3895–3905 (2022)
2022
-
[60]
In: Proceedings of the IEEE/CVF interna- tional conference on computer vision
Ye, Y., Hebbar, P., Gupta, A., Tulsiani, S.: Diffusion-guided reconstruction of everyday hand-object interaction clips. In: Proceedings of the IEEE/CVF interna- tional conference on computer vision. pp. 19717–19728 (2023)
2023
-
[61]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Yu, Z., Zafeiriou, S., Birdal, T.: Dyn-hamr: Recovering 4d interacting hand motion from a dynamic camera. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 27716–27726 (2025)
2025
-
[62]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Zheng, C., Xue, L., Zarate, J., Song, J.: Gaustar: Gaussian surface tracking and reconstruction. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 16543–16553 (2025)
2025
-
[63]
In: 2024 International Conference on 3D Vision (3DV)
Zhong, L., Yang, L., Li, K., Zhen, H., Han, M., Lu, C.: Color-neus: Reconstructing neural implicit surfaces with color. In: 2024 International Conference on 3D Vision (3DV). pp. 631–640. IEEE (2024)
2024
-
[64]
Analyze this video frame-by-frame and determine EXACTLY when the hand transitions
Zhong, Y., Jain, A.K., Dubuisson-Jolly, M.P.: Object tracking using deformable templates. IEEE transactions on pattern analysis and machine intelligence22(5), 544–549 (2000) Grasp in Gaussians 19 Supplementary Material A Additional Evaluation Following ARCTIC [15], we also report interaction metrics in Tab. S1 such as Contact Deviation (CDev) that measure...
2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.