Recognition: unknown
Distorted or Fabricated? A Survey on Hallucination in Video LLMs
Pith reviewed 2026-05-10 16:29 UTC · model grok-4.3
The pith
Hallucinations in video LLMs divide into dynamic distortion and content fabrication from weak temporal representation and visual grounding.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that hallucinations in Vid-LLMs appear as dynamic distortion, where temporal elements of the video are misrepresented, or content fabrication, where nonexistent elements are added, and that these arise primarily from limited capacity for temporal representation and insufficient visual grounding.
What carries the argument
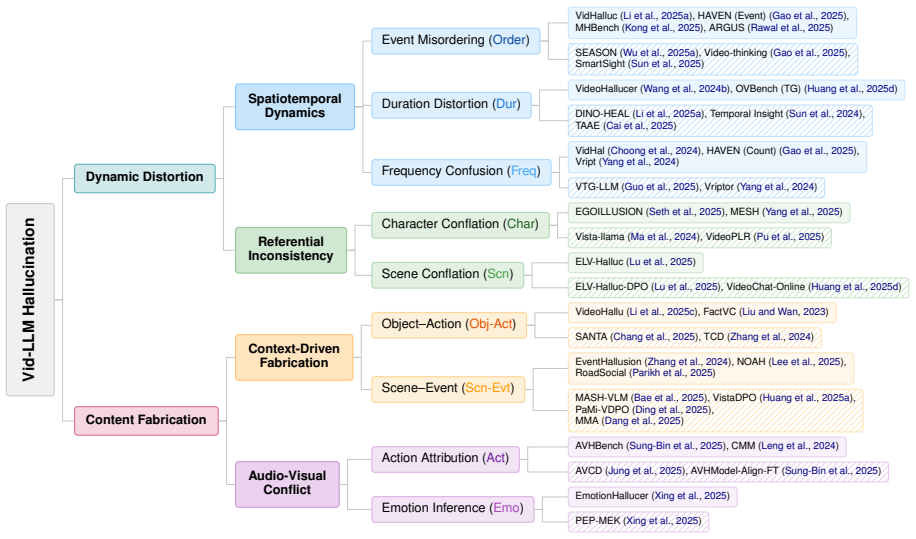
The two-type taxonomy of hallucinations consisting of dynamic distortion and content fabrication, each with two subtypes, which organizes observed cases to analyze causes, evaluations, and mitigation approaches.
If this is right
- Benchmarks and metrics can be built to measure specific hallucination subtypes separately.
- Mitigation methods should target improvements in temporal modeling and visual grounding.
- Motion-aware visual encoders can reduce dynamic distortion in future models.
- Counterfactual learning can help limit content fabrication by encouraging grounding in actual video content.
Where Pith is reading between the lines
- The taxonomy could be tested on newer Vid-LLMs to check if the two types still dominate.
- Insights on temporal and grounding limits may extend to improving related tasks like video question answering or captioning.
- The survey's review of intervention strategies suggests combining multiple fixes rather than addressing only one root cause at a time.
Load-bearing premise
The proposed taxonomy of two core types with subtypes fully covers the hallucinations seen in current Vid-LLMs without major overlaps or missing categories.
What would settle it
Observation of a common hallucination pattern in Vid-LLMs that fits neither dynamic distortion nor content fabrication would show the taxonomy is incomplete.
Figures


read the original abstract
Despite significant progress in video-language modeling, hallucinations remain a persistent challenge in Video Large Language Models (Vid-LLMs), referring to outputs that appear plausible yet contradict the content of the input video. This survey presents a comprehensive analysis of hallucinations in Vid-LLMs and introduces a systematic taxonomy that categorizes them into two core types: dynamic distortion and content fabrication, each comprising two subtypes with representative cases. Building on this taxonomy, we review recent advances in the evaluation and mitigation of hallucinations, covering key benchmarks, metrics, and intervention strategies. We further analyze the root causes of dynamic distortion and content fabrication, which often result from limited capacity for temporal representation and insufficient visual grounding. These insights inform several promising directions for future work, including the development of motion-aware visual encoders and the integration of counterfactual learning techniques. This survey consolidates scattered progress to foster a systematic understanding of hallucinations in Vid-LLMs, laying the groundwork for building robust and reliable video-language systems. An up-to-date curated list of related works is maintained at https://github.com/hukcc/Awesome-Video-Hallucination .
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. This manuscript is a survey on hallucinations in Video Large Language Models (Vid-LLMs). It defines hallucinations as plausible outputs that contradict the input video content. The paper introduces a taxonomy classifying hallucinations into two core types—dynamic distortion and content fabrication—each with two subtypes, supported by representative cases. It then reviews advances in evaluation (benchmarks and metrics) and mitigation strategies. The authors analyze root causes, attributing them primarily to limited temporal representation capacity and insufficient visual grounding. Finally, it outlines future directions such as developing motion-aware visual encoders and integrating counterfactual learning techniques, while maintaining a GitHub repository of related works.
Significance. The survey provides a valuable synthesis of the emerging literature on Vid-LLM hallucinations. By organizing the problem into a clear taxonomy and linking it to underlying technical limitations in current models, it offers a structured way to approach this challenge. The review of evaluation and mitigation methods, combined with the root cause analysis, can help guide both empirical and theoretical work in the field. The curated list of works is a practical contribution that enhances the paper's utility as a reference.
minor comments (2)
- The abstract states that each core type comprises 'two subtypes with representative cases' but does not name the subtypes; adding their names (even briefly) would improve scannability without lengthening the abstract substantially.
- The root-cause section links dynamic distortion to limited temporal representation; including one short, concrete example from a cited Vid-LLM paper would make the causal claim more tangible for readers.
Simulated Author's Rebuttal
We thank the referee for their positive assessment of our survey and for recommending minor revision. The recognition of the taxonomy's clarity, the value of the evaluation and mitigation reviews, the root cause analysis, and the curated GitHub repository is appreciated. As the report lists no specific major comments, we have no point-by-point items to address.
Circularity Check
No significant circularity identified
full rationale
This is a literature survey paper that synthesizes prior work on hallucinations in Vid-LLMs into an organizing taxonomy of two core types (dynamic distortion and content fabrication) with subtypes, plus root-cause discussion drawn from existing studies on temporal modeling and visual grounding. No equations, derivations, fitted parameters, predictions, or self-referential reductions appear in the manuscript. The taxonomy is explicitly offered as a framework for consolidation rather than a mathematically derived partition, and all claims are supported by citations to independent prior literature without load-bearing self-citation chains or ansatzes that collapse to the paper's own inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Hallucination of Multimodal Large Language Models: A Survey
Hallucination of multimodal large language models: A survey.CoRR, abs/2404.18930. Jianfeng Cai, Wengang Zhou, Zongmeng Zhang, Jiale Hong, Nianji Zhan, and Houqiang Li. 2025. Miti- gating hallucination in videollms via temporal-aware activation engineering.CoRR, abs/2505.12826. Kai-Po Chang, Wei-Yuan Cheng, Chi-Pin Huang, Fu-En Yang, and Yu-Chiang Frank Wa...
work page internal anchor Pith review arXiv 2025
-
[2]
Ming Kong, Xianzhou Zeng, Luyuan Chen, Yadong Li, Bo Yan, and Qiang Zhu
A VCD: mitigating hallucinations in audio- visual large language models through contrastive de- coding.CoRR, abs/2505.20862. Ming Kong, Xianzhou Zeng, Luyuan Chen, Yadong Li, Bo Yan, and Qiang Zhu. 2025. Mhbench: Demys- tifying motion hallucination in videollms. InAAAI, pages 4401–4409. AAAI Press. Wei Lan, Wenyi Chen, Qingfeng Chen, Shirui Pan, Huiyu Zho...
-
[3]
Noah: Benchmarking narrative prior driven hallucination and omission in video large language models.arXiv preprint arXiv:2511.06475. Sicong Leng, Yun Xing, Zesen Cheng, Yang Zhou, Hang Zhang, Xin Li, Deli Zhao, Shijian Lu, Chun- yan Miao, and Lidong Bing. 2024. The curse of multi-modalities: Evaluating hallucinations of large multimodal models across lang...
-
[4]
Hao Lu, Jiahao Wang, Yaolun Zhang, Ruohui Wang, Xuanyu Zheng, Yepeng Tang, Dahua Lin, and Lewei Lu
Association for Computational Linguistics. Hao Lu, Jiahao Wang, Yaolun Zhang, Ruohui Wang, Xuanyu Zheng, Yepeng Tang, Dahua Lin, and Lewei Lu. 2025. Elv-halluc: Benchmarking semantic ag- gregation hallucinations in long video understanding. CoRR, abs/2508.21496. Fan Ma, Xiaojie Jin, Heng Wang, Yuchen Xian, Jiashi Feng, and Yi Yang. 2024. Vista-llama: Redu...
-
[5]
InICPR (7), volume 15307 ofLecture Notes in Computer Science, pages 455–473
Temporal insight enhancement: Mitigating temporal hallucination in video understanding by multimodal large language models. InICPR (7), volume 15307 ofLecture Notes in Computer Science, pages 455–473. Springer. Yiming Sun, Mi Zhang, Feifei Li, Geng Hong, and Min Yang. 2025. Smartsight: Mitigating hallucina- tion in video-llms without compromising video un...
-
[6]
Luowei Zhou, Chenliang Xu, and Jason J
Videoperceiver: Enhancing fine-grained tem- poral perception in video multimodal large language models.CoRR, abs/2511.18823. Luowei Zhou, Chenliang Xu, and Jason J. Corso. 2018. Towards automatic learning of procedures from web instructional videos. InAAAI, pages 7590–7598. AAAI Press. A Detailed Analysis of Benchmarks Benchmarks for video hallucination d...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.