Recognition: unknown
GlotOCR Bench: OCR Models Still Struggle Beyond a Handful of Unicode Scripts
Pith reviewed 2026-05-10 16:06 UTC · model grok-4.3
The pith
OCR models perform well on fewer than ten scripts and fail to generalize beyond thirty even among frontier systems.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
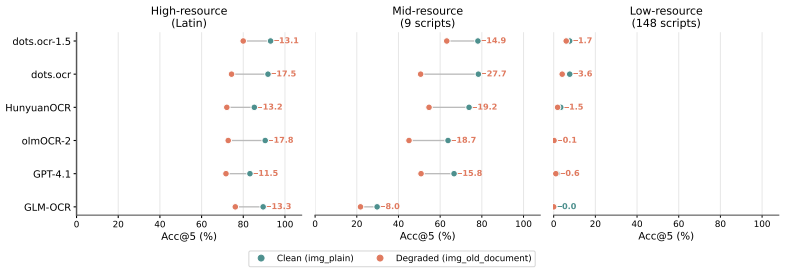
We present GlotOCR Bench, a benchmark of rendered images from real multilingual texts across 100+ Unicode scripts, including clean and degraded variants produced with Google Fonts, HarfBuzz, and FreeType. Testing a broad range of vision-language models reveals that most perform well on fewer than ten scripts and even frontier models fail to generalize beyond thirty. Performance tracks script-level pretraining coverage, and models faced with unfamiliar scripts output random noise or characters from scripts they already know.
What carries the argument
GlotOCR Bench, a collection of rendered text images across 100+ scripts with controlled clean and degraded variants, which measures how well OCR models generalize when script pretraining coverage is low.
If this is right
- Expanding pretraining data to include more scripts would directly raise OCR accuracy on additional writing systems.
- Models on unfamiliar scripts default to noise or borrowed characters, showing they lack independent visual recognition for new scripts.
- Applications that process documents in low-resource scripts will require targeted fine-tuning or post-processing steps.
- Frontier vision-language models remain unsuitable for truly script-agnostic document processing without further changes.
Where Pith is reading between the lines
- The benchmark suggests that separating visual feature extraction from language-model priors could produce more robust OCR for unseen scripts.
- Real deployment in multilingual settings may need hybrid systems that combine the benchmark with script-specific data collection.
- Future benchmarks could add handwritten or camera-captured text to test whether the current rendering pipeline underestimates practical difficulties.
Load-bearing premise
The rendered images from Google Fonts shaped by HarfBuzz accurately represent the visual challenges that real-world OCR faces for every script.
What would settle it
Measure the same models on actual scanned or photographed documents from the low-performing scripts and check whether error rates and hallucination patterns remain similar to the benchmark results.
Figures




read the original abstract
Optical character recognition (OCR) has advanced rapidly with the rise of vision-language models, yet evaluation has remained concentrated on a small cluster of high- and mid-resource scripts. We introduce GlotOCR Bench, a comprehensive benchmark evaluating OCR generalization across 100+ Unicode scripts. Our benchmark comprises clean and degraded image variants rendered from real multilingual texts. Images are rendered using fonts from the Google Fonts repository, shaped with HarfBuzz and rasterized with FreeType, supporting both LTR and RTL scripts. Samples of rendered images were manually reviewed to verify correct rendering across all scripts. We evaluate a broad suite of open-weight and proprietary vision-language models and find that most perform well on fewer than ten scripts, and even the strongest frontier models fail to generalize beyond thirty scripts. Performance broadly tracks script-level pretraining coverage, suggesting that current OCR systems rely on language model pretraining as much as on visual recognition. Models confronted with unfamiliar scripts either produce random noise or hallucinate characters from similar scripts they already know. We release the benchmark and pipeline for reproducibility. Pipeline Code: https://github.com/cisnlp/glotocr-bench, Benchmark: https://hf.co/datasets/cis-lmu/glotocr-bench.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces GlotOCR Bench, a benchmark for OCR generalization of vision-language models across 100+ Unicode scripts. Images are generated from real multilingual texts using Google Fonts, HarfBuzz shaping, and FreeType rasterization for both clean and degraded conditions, supporting LTR and RTL scripts. Evaluation of open-weight and proprietary models shows most succeed on fewer than 10 scripts, with even frontier models failing beyond 30; performance correlates with script-level pretraining coverage. Unfamiliar scripts lead to noise or hallucinations of known characters. The benchmark and rendering pipeline are released publicly.
Significance. If the benchmark images faithfully represent real-world OCR challenges, the results demonstrate a critical limitation in current models' ability to generalize visually beyond pretraining data, with implications for multilingual document processing and VLM development. The public release of the dataset and code is a clear strength that enables reproducibility and follow-up work.
major comments (2)
- [Benchmark construction] Benchmark construction (rendering and validation subsection): The assertion that rendered images correctly represent source text for all 100+ scripts rests only on manual review of samples. For scripts with complex shaping (ligatures, diacritics, bidirectional reordering, rare Unicode blocks), this qualitative check is insufficient to rule out systematic rendering artifacts; such artifacts would produce failures orthogonal to pretraining coverage and undermine the central claim that observed gaps reflect model limitations.
- [Results and analysis] Results and analysis section: The claim that performance 'broadly tracks' script-level pretraining coverage is presented without a quantitative measure of coverage, a correlation coefficient, or statistical test; this weakens the interpretation that models rely on pretraining 'as much as on visual recognition.'
minor comments (2)
- [Abstract and methods] The abstract and methods would benefit from an explicit table or appendix listing the 100+ scripts, their script families, and the number of test instances per script to allow readers to assess coverage.
- [Benchmark construction] Clarify the exact criteria used for 'manual review' of rendered samples (e.g., number of samples per script, reviewer expertise) to strengthen the reproducibility claim.
Simulated Author's Rebuttal
We thank the referee for their careful reading and constructive feedback on our manuscript. Their comments have prompted us to strengthen the description of our benchmark construction and to add quantitative support for our analysis of pretraining coverage. We address each major comment below.
read point-by-point responses
-
Referee: Benchmark construction (rendering and validation subsection): The assertion that rendered images correctly represent source text for all 100+ scripts rests only on manual review of samples. For scripts with complex shaping (ligatures, diacritics, bidirectional reordering, rare Unicode blocks), this qualitative check is insufficient to rule out systematic rendering artifacts; such artifacts would produce failures orthogonal to pretraining coverage and undermine the central claim that observed gaps reflect model limitations.
Authors: We appreciate the referee's concern regarding potential rendering artifacts in complex scripts. Our pipeline employs HarfBuzz (the de-facto standard shaping engine used by browsers and operating systems) together with FreeType rasterization and professionally curated Google Fonts; these components are explicitly designed to handle ligatures, diacritics, bidirectional reordering, and rare Unicode blocks. The manual review we performed inspected multiple samples per script for correct visual output of these features. In the revision we will expand the rendering-and-validation subsection to (i) describe the review protocol in detail (number of samples examined per script, specific checks performed for shaping and reordering), (ii) add an appendix containing representative rendered images from scripts with complex features (e.g., Arabic ligatures, Hebrew bidirectional text, Devanagari conjuncts), and (iii) explicitly note that any systematic rendering error would be expected to affect all models uniformly, yet our results exhibit clear variation aligned with pretraining coverage. While a fully automated, script-by-script quantitative oracle is impractical within the scope of this work, we believe the combination of industry-standard tooling and targeted manual verification is sufficient to support the benchmark's validity. revision: partial
-
Referee: Results and analysis section: The claim that performance 'broadly tracks' script-level pretraining coverage is presented without a quantitative measure of coverage, a correlation coefficient, or statistical test; this weakens the interpretation that models rely on pretraining 'as much as on visual recognition.'
Authors: We agree that a quantitative correlation analysis would make the claim more rigorous. In the revised manuscript we will augment the Results and Analysis section with the following: (1) a proxy measure of script-level pretraining coverage derived from publicly documented training data statistics and tokenizer coverage where available; (2) Pearson correlation coefficients (with p-values) between this coverage proxy and each model's average character error rate across the 100+ scripts; and (3) separate reporting for open-weight and proprietary models (using the best available public information for the latter). These additions will directly support and quantify the statement that performance tracks pretraining coverage. revision: yes
Circularity Check
No circularity: purely empirical benchmark without derivations or fitted predictions
full rationale
The paper constructs GlotOCR Bench by rendering real texts via Google Fonts + HarfBuzz + FreeType, manually reviewing samples for correctness, and then running off-the-shelf vision-language models on the resulting images. No equations, ansatzes, fitted parameters, or predictive derivations appear anywhere in the described pipeline or results. Performance numbers are direct empirical measurements on the benchmark; they do not reduce by construction to any quantity defined inside the paper. Self-citations (if present) are not invoked to justify uniqueness or load-bearing premises. The central claims therefore remain independent of internal definitions and constitute a standard benchmark study.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Rendered images using Google Fonts, HarfBuzz, and FreeType accurately represent real text rendering for 100+ scripts including LTR and RTL
Reference graph
Works this paper leans on
-
[1]
A concise survey of OCR for low-resource lan- guages
Milind Agarwal and Antonios Anastasopoulos. A concise survey of OCR for low-resource lan- guages. In Manuel Mager, Abteen Ebrahimi, Shruti Rijhwani, Arturo Oncevay, Luis Chiruzzo, Robert Pugh, and Katharina von der Wense, editors,Proceedings of the 4th Workshop on Natural Language Processing for Indigenous Languages of the Americas (AmericasNLP 2024), pag...
-
[2]
Omniglot: Writing systems and languages of the world.https://www.omniglot
Simon Ager. Omniglot: Writing systems and languages of the world.https://www.omniglot. com, 2026
2026
-
[3]
CAMIO: A corpus for OCR in multiple languages
Michael Arrigo, Stephanie Strassel, Nolan King, Thao Tran, and Lisa Mason. CAMIO: A corpus for OCR in multiple languages. InProceedings of the Thirteenth Language Resources and Evaluation Conference, pages 1209–1216, Marseille, France, June 2022. European Language Resources Association. URLhttps://aclanthology.org/2022.lrec-1.129/
2022
-
[4]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, Wenbin Ge, Zhifang Guo, Qidong Huang, Jie Huang, Fei Huang, Binyuan Hui, Shutong Jiang, Zhaohai Li, Mingsheng Li, Mei Li, Kaixin Li, Zicheng Lin, Junyang Lin, Xuejing Liu, Jiawei Liu, Chenglong Liu, Yang Liu, Dayiheng Liu, Shixuan ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Le Khac, Sanath Narayan, Wamiq Reyaz Para, and Ankit Singh
Aviraj Bevli, Sofian Chaybouti, Yasser Dahou, Hakim Hacid, Ngoc Dung Huynh, Phuc H. Le Khac, Sanath Narayan, Wamiq Reyaz Para, and Ankit Singh. Falcon perception, 2026. URL https://arxiv.org/abs/2603.27365
-
[6]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities, 2025. URLhttps://arxiv.org/abs/2507.06261
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
PaddleOCR-VL-1.5: Towards a Multi-Task 0.9B VLM for Robust In-the-Wild Document Parsing
Cheng Cui, Ting Sun, Suyin Liang, Tingquan Gao, Zelun Zhang, Jiaxuan Liu, Xueqing Wang, Changda Zhou, Hongen Liu, Manhui Lin, Yue Zhang, Yubo Zhang, Yi Liu, Dianhai Yu, and Yanjun Ma. Paddleocr-vl-1.5: Towards a multi-task 0.9b vlm for robust in-the-wild document parsing, 2026. URLhttps://arxiv.org/abs/2601.21957
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[8]
Oxford University Press, 1996
Peter T Daniels and William Bright.The world’s writing systems. Oxford University Press, 1996
1996
-
[9]
sococrbench: An OCR benchmark for social science documents
Noah Dasanaike. sococrbench: An OCR benchmark for social science documents. Working paper, 2026. URLhttps://noahdasanaike.github.io/posts/sococrbench.html
2026
-
[10]
Chandra ocr 2, 2026
Datalab. Chandra ocr 2, 2026. URL https://huggingface.co/datalab-to/ chandra-ocr-2
2026
-
[11]
Xiaolei Diao, Rite Bo, Yanling Xiao, Lida Shi, Zhihan Zhou, Hao Xu, Chuntao Li, Xiongfeng Tang, Massimo Poesio, Cédric M. John, and Daqian Shi. Ancient script image recognition and processing: A review, 2025. URLhttps://arxiv.org/abs/2506.19208
-
[12]
arXiv preprint arXiv:2603.13398 , year=
Daxiang Dong, Mingming Zheng, Dong Xu, Chunhua Luo, Bairong Zhuang, Yuxuan Li, Ruoyun He, Haoran Wang, Wenyu Zhang, Wenbo Wang, Yicheng Wang, Xue Xiong, Ayong Zheng, Xiaoying Zuo, Ziwei Ou, Jingnan Gu, Quanhao Guo, Jianmin Wu, Dawei Yin, and Dou Shen. Qianfan-ocr: A unified end-to-end model for document intelligence, 2026. URL https://arxiv.org/abs/2603.13398. 10
-
[13]
Glm-ocr technical report.arXiv preprint arXiv:2603.10910,
Shuaiqi Duan, Yadong Xue, Weihan Wang, Zhe Su, Huan Liu, Sheng Yang, Guobing Gan, Guo Wang, Zihan Wang, Shengdong Yan, Dexin Jin, Yuxuan Zhang, Guohong Wen, Yanfeng Wang, Yutao Zhang, Xiaohan Zhang, Wenyi Hong, Yukuo Cen, Da Yin, Bin Chen, Wenmeng Yu, Xiaotao Gu, and Jie Tang. GLM-OCR Technical Report, 2026. URL https://arxiv. org/abs/2603.10910
-
[14]
HarfBuzz: A text shaping engine, 2026
Behdad Esfahbod et al. HarfBuzz: A text shaping engine, 2026. URL https://github.com/ harfbuzz/harfbuzz
2026
-
[15]
OCRBench v2: An improved benchmark for evaluating large multimodal models on visual text localization and reasoning
Ling Fu, Zhebin Kuang, Jiajun Song, Mingxin Huang, Biao Yang, Yuzhe Li, Linghao Zhu, Qidi Luo, Xinyu Wang, Hao Lu, Zhang Li, Guozhi Tang, Bin Shan, Chunhui Lin, Qi Liu, Binghong Wu, Hao Feng, Hao Liu, Can Huang, Jingqun Tang, Wei Chen, Lianwen Jin, Yuliang Liu, and Xiang Bai. OCRBench v2: An improved benchmark for evaluating large multimodal models on vis...
2025
-
[16]
Gemini 3.1 flash-lite: Built for intelligence at scale, 2026
Google DeepMind. Gemini 3.1 flash-lite: Built for intelligence at scale, 2026. URL https://blog.google/innovation-and-ai/models-and-research/ gemini-models/gemini-3-1-flash-lite/
2026
-
[17]
Google fonts
Google Fonts Team. Google fonts. GitHub, 2026. URL https://github.com/google/ fonts
2026
-
[18]
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun
Gavin Greif, Niclas Griesshaber, and Robin Greif. Multimodal LLMs for OCR, OCR Post- Correction, and Named Entity Recognition in Historical Documents, 2025. URL https: //arxiv.org/abs/2504.00414
-
[19]
Augraphy: A data augmentation library for document images
Alexander Groleau, Kok Wei Chee, Stefan Larson, Samay Maini, and Jonathan Boarman. Augraphy: A data augmentation library for document images, 2023. URL https://arxiv. org/abs/2208.14558
-
[20]
Synthetic data for text localisation in natural images
Ankush Gupta, Andrea Vedaldi, and Andrew Zisserman. Synthetic data for text localisation in natural images. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2016. URLhttps://openaccess.thecvf.com/content_cvpr_ 2016/html/Gupta_Synthetic_Data_for_CVPR_2016_paper.html
2016
-
[21]
Haibin He, Maoyuan Ye, Jing Zhang, Xiantao Cai, Juhua Liu, Bo Du, and Dacheng Tao. Reasoning-OCR: Can large multimodal models solve complex logical reasoning problems from ocr cues?, 2025. URLhttps://arxiv.org/abs/2505.12766
-
[22]
KITAB-bench: A comprehensive multi-domain benchmark for Arabic OCR and document understanding
Ahmed Heakl, Muhammad Abdullah Sohail, Mukul Ranjan, Rania Elbadry, Ghazi Shazan Ahmad, Mohamed El-Geish, Omar Maher, Zhiqiang Shen, Fahad Shahbaz Khan, and Salman Khan. KITAB-bench: A comprehensive multi-domain benchmark for Arabic OCR and document understanding. InFindings of the Association for Computational Linguistics: ACL 2025, pages 22006–22024, Vi...
-
[23]
Hunyuan Vision Team, Pengyuan Lyu, Xingyu Wan, Gengluo Li, Shangpin Peng, Weinong Wang, Liang Wu, Huawen Shen, Yu Zhou, Canhui Tang, Qi Yang, Qiming Peng, Bin Luo, Hower Yang, Xinsong Zhang, Jinnian Zhang, Houwen Peng, Hongming Yang, Senhao Xie, Longsha Zhou, Ge Pei, Binghong Wu, Rui Yan, Kan Wu, Jieneng Yang, Bochao Wang, Kai Liu, Jianchen Zhu, Jie Jiang...
-
[24]
Generating errors: OCR post-processing for Icelandic
Atli Jasonarson, Steinþór Steingrímsson, Einar Sigurðsson, Árni Magnússon, and Finnur Ingimundarson. Generating errors: OCR post-processing for Icelandic. In Tanel Alumäe and Mark Fishel, editors,Proceedings of the 24th Nordic Conference on Computational Linguistics (NoDaLiDa), pages 286–291, Tórshavn, Faroe Islands, May 2023. University of Tartu Library....
2023
-
[25]
Evaluating multimodal language models as visual assistants for visually impaired users
Antonia Karamolegkou, Malvina Nikandrou, Georgios Pantazopoulos, Danae Sanchez Villegas, Phillip Rust, Ruchira Dhar, Daniel Hershcovich, and Anders Søgaard. Evaluating multimodal language models as visual assistants for visually impaired users. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar, editors,Proceedings of the 63rd ...
-
[26]
Mohammed Kharma, Soohyeon Choi, Mohammed AlKhanafseh, and David Mohaisen
Amir Hossein Kargaran, Ayyoob Imani, François Yvon, and Hinrich Schuetze. GlotLID: Language identification for low-resource languages. In Houda Bouamor, Juan Pino, and Kalika Bali, editors,Findings of the Association for Computational Linguistics: EMNLP 2023, pages 6155–6218, Singapore, December 2023. Association for Computational Linguis- tics. doi: 10.1...
-
[27]
GlotCC: An open broad- coverage commoncrawl corpus and pipeline for minority languages
Amir Hossein Kargaran, François Yvon, and Hinrich Schuetze. GlotCC: An open broad- coverage commoncrawl corpus and pipeline for minority languages. InThe Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2024. URLhttps://openreview.net/forum?id=aJ1yse8GEr
2024
-
[28]
GlotScript: A resource and tool for low resource writing system identification
Amir Hossein Kargaran, François Yvon, and Hinrich Schütze. GlotScript: A resource and tool for low resource writing system identification. In Nicoletta Calzolari, Min-Yen Kan, Veronique Hoste, Alessandro Lenci, Sakriani Sakti, and Nianwen Xue, editors,Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources a...
2024
-
[29]
Nayana OCR: A scalable framework for document OCR in low-resource languages
Adithya Kolavi, Samarth P, and Vyoman Jain. Nayana OCR: A scalable framework for document OCR in low-resource languages. In Sang Truong, Rifki Afina Putri, Duc Nguyen, Angelina Wang, Daniel Ho, Alice Oh, and Sanmi Koyejo, editors,Proceedings of the 1st Workshop on Language Models for Underserved Communities (LM4UC 2025), pages 86–103, Albuquerque, New Mex...
2025
-
[30]
URL https://aclanthology.org/2025.lm4uc-1
doi: 10.18653/v1/2025.lm4uc-1.11. URL https://aclanthology.org/2025.lm4uc-1. 11/
-
[31]
FinePDFs
Hynek Kydlí ˇcek, Guilherme Penedo, and Leandro von Werra. FinePDFs. https:// huggingface.co/datasets/HuggingFaceFW/finepdfs, 2025
2025
-
[32]
Yumeng Li, Guang Yang, Hao Liu, Bowen Wang, and Colin Zhang. dots.ocr: Multilingual document layout parsing in a single vision-language model, 2025. URL https://arxiv.org/ abs/2512.02498
-
[33]
Zhang Li, Yuliang Liu, Qiang Liu, Zhiyin Ma, Ziyang Zhang, Shuo Zhang, Biao Yang, Zidun Guo, Jiarui Zhang, Xinyu Wang, and Xiang Bai. Monkeyocr: Document parsing with a structure- recognition-relation triplet paradigm, 2026. URLhttps://arxiv.org/abs/2506.05218
-
[34]
Omniocr: Generalist ocr for ethnic minority languages, 2026
Bonan Liu, Zeyu Zhang, Bingbing Meng, Han Wang, Hanshuo Zhang, Chengping Wang, Daji Ergu, and Ying Cai. Omniocr: Generalist ocr for ethnic minority languages, 2026. URL https://arxiv.org/abs/2602.21042
-
[35]
Ancient yi script handwriting sample repository.Scientific Data, 11(1):1183, 2024
Xiaojuan Liu, Xu Han, Shanxiong Chen, Weijia Dai, and Qiuyue Ruan. Ancient yi script handwriting sample repository.Scientific Data, 11(1):1183, 2024. URL https://doi.org/ 10.1038/s41597-024-03918-5
-
[36]
Yuliang Liu, Zhang Li, Mingxin Huang, Biao Yang, Wenwen Yu, Chunyuan Li, Xu-Cheng Yin, Cheng-Lin Liu, Lianwen Jin, and Xiang Bai. OCRBench: On the hidden mystery of ocr in large multimodal models.Science China Information Sciences, 67(12):220102, 2024. doi: 10.1007/s11432-024-4235-6. URLhttps://doi.org/10.1007/s11432-024-4235-6
-
[37]
Multiple attentional aggregation network for handwritten Dongba character recognition.Expert Systems with Applications, 213:118865,
Yanlong Luo, Yiwen Sun, and Xiaojun Bi. Multiple attentional aggregation network for handwritten Dongba character recognition.Expert Systems with Applications, 213:118865,
-
[38]
doi: https://doi.org/10.1016/j.eswa.2022.118865
ISSN 0957-4174. doi: https://doi.org/10.1016/j.eswa.2022.118865. URL https: //www.sciencedirect.com/science/article/pii/S0957417422018838. 12
-
[39]
Haq Nawaz Malik, Kh Mohmad Shafi, and Tanveer Ahmad Reshi. synthocr-gen: A synthetic OCR dataset generator for low-resource languages- breaking the data barrier, 2026. URL https://arxiv.org/abs/2601.16113
-
[40]
Nanonets-OCR2: A model for transforming documents into structured markdown with intel- ligent content recognition and semantic tagging, 2025
Souvik Mandal, Ashish Talewar, Siddhant Thakuria, Paras Ahuja, and Prathamesh Juvatkar. Nanonets-OCR2: A model for transforming documents into structured markdown with intel- ligent content recognition and semantic tagging, 2025. URL https://huggingface.co/ nanonets/Nanonets-OCR2-3B
2025
-
[41]
Nemotron ocr v2
NVIDIA. Nemotron ocr v2. https://huggingface.co/nvidia/nemotron-ocr-v2, 2026
2026
-
[42]
OpenAI, Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Floren- cia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report, 2024. URLhttps://arxiv.org/abs/2303.08774
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[43]
OmniDocBench: Benchmarking diverse pdf document parsing with comprehensive annotations
Linke Ouyang, Yuan Qu, Hongbin Zhou, Jiawei Zhu, Rui Zhang, Qunshu Lin, Bin Wang, Zhiyuan Zhao, Man Jiang, Xiaomeng Zhao, Jin Shi, Fan Wu, Pei Chu, Minghao Liu, Zhenxiang Li, Chao Xu, Bo Zhang, Botian Shi, Zhongying Tu, and Conghui He. OmniDocBench: Benchmarking diverse pdf document parsing with comprehensive annotations. InProceedings of the IEEE/CVF Con...
2025
-
[44]
Fineweb2: One pipeline to scale them all — adapting pre-training data processing to every language
Guilherme Penedo, Hynek Kydlí ˇcek, Vinko Sabol ˇcec, Bettina Messmer, Negar Foroutan, Amir Hossein Kargaran, Colin Raffel, Martin Jaggi, Leandro V on Werra, and Thomas Wolf. Fineweb2: One pipeline to scale them all — adapting pre-training data processing to every language. InSecond Conference on Language Modeling, 2025. URL https://openreview. net/forum?...
2025
-
[45]
Jake Poznanski, Aman Rangapur, Jon Borchardt, Jason Dunkelberger, Regan Huff, Daniel Lin, Aman Rangapur, Christopher Wilhelm, Kyle Lo, and Luca Soldaini. olmOCR: Unlocking trillions of tokens in pdfs with vision language models, 2025. URL https://arxiv.org/ abs/2502.18443
-
[46]
olmOCR 2: Unit test rewards for document ocr,
Jake Poznanski, Luca Soldaini, and Kyle Lo. olmOCR 2: Unit test rewards for document ocr,
- [47]
-
[48]
Aksharamukha: Script conversion web tool
Vinodh Rajan. Aksharamukha: Script conversion web tool. https://www.aksharamukha. com/converter, 2024
2024
-
[49]
Rolmocr: A faster, lighter open-source ocr model, 2025
Reducto AI. Rolmocr: A faster, lighter open-source ocr model, 2025. URL https://reducto. ai/blog
2025
-
[50]
Ocr synthetic benchmark dataset for indic languages, 2022
Naresh Saini, Promodh Pinto, Aravinth Bheemaraj, Deepak Kumar, Dhiraj Daga, Saurabh Yadav, and Srihari Nagaraj. Ocr synthetic benchmark dataset for indic languages, 2022. URL https://arxiv.org/abs/2205.02543
-
[51]
Printed ocr for extremely low-resource indic languages
Alik Sarkar, Ajoy Mondal, Gurpreet Singh Lehal, and CV Jawahar. Printed ocr for extremely low-resource indic languages. InInternational Conference on Computer Vision and Image Processing, pages 108–122. Springer, 2024. URL https://ilocr.iiit.ac.in/dataset/ static/assets/img/publication/printed/printed_ocr.pdf
2024
-
[52]
GlotWeb: Web indexing for minority languages
Abdullah Al Sefat, Amir Hossein Kargaran, François Yvon, and Hinrich Schütze. GlotWeb: Web indexing for minority languages. InProceedings of the ACM Web Conference 2026, pages 8469–8472, 2026. URLhttps://dl.acm.org/doi/abs/10.1145/3774904.3792887
-
[53]
Deciphering the underserved: Benchmarking llm ocr for low-resource scripts, 2024
Muhammad Abdullah Sohail, Salaar Masood, and Hamza Iqbal. Deciphering the underserved: Benchmarking llm ocr for low-resource scripts, 2024. URL https://arxiv.org/abs/2412. 16119
2024
-
[54]
Said Taghadouini, Adrien Cavaillès, and Baptiste Aubertin. Lightonocr: A 1b end-to-end multilingual vision-language model for state-of-the-art ocr, 2026. URL https://arxiv.org/ abs/2601.14251. 13
-
[55]
FreeType: A free, high-quality and portable font engine, 2024
David Turner, Robert Wilhelm, and Werner Lemberg. FreeType: A free, high-quality and portable font engine, 2024. URLhttps://freetype.org
2024
-
[56]
Ocr uv scripts
Daniel van Strien. Ocr uv scripts. Hugging Face, 2026. URL https://huggingface.co/ datasets/uv-scripts/ocr
2026
-
[57]
Deepseek-ocr 2: Visual causal flow.arXiv preprint arXiv:2601.20552,
Haoran Wei, Yaofeng Sun, and Yukun Li. DeepSeek-OCR 2: Visual causal flow, 2026. URL https://arxiv.org/abs/2601.20552
-
[58]
Wikisource: The free online library
Wikimedia Foundation. Wikisource: The free online library. https://wikisource.org, 2026
2026
-
[59]
Wiktionary, the free dictionary, 2026
Wiktionary Contributors. Wiktionary, the free dictionary, 2026. URL https://www. wiktionary.org/
2026
-
[60]
Firered-ocr technical report, 2026
Hao Wu, Haoran Lou, Xinyue Li, Zuodong Zhong, Zhaojun Sun, Phellon Chen, Xuanhe Zhou, Kai Zuo, Yibo Chen, Xu Tang, Yao Hu, Boxiang Zhou, Jian Wu, Yongji Wu, Wenxin Yu, Yingmiao Liu, Yuhao Huang, Manjie Xu, Gang Liu, Yidong Ma, Zhichao Sun, and Changhao Qiao. Firered-ocr technical report, 2026. URLhttps://arxiv.org/abs/2603.01840
-
[61]
CC-OCR: A comprehensive and challenging ocr benchmark for evaluating large multimodal models in literacy
Zhibo Yang, Jun Tang, Zhaohai Li, Pengfei Wang, Jianqiang Wan, Humen Zhong, Xuejing Liu, Mingkun Yang, Peng Wang, Shuai Bai, Lianwen Jin, and Junyang Lin. CC-OCR: A comprehensive and challenging ocr benchmark for evaluating large multimodal models in literacy. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 21744–21...
2025
-
[62]
Ocrturk: A comprehensive ocr benchmark for turkish, 2026
Deniz Yılmaz, Evren Ayberk Munis, Ça ˘grı Toraman, Süha Ka ˘gan Köse, Burak Akta¸ s, Mehmet Can Baytekin, and Bilge Kaan Görür. Ocrturk: A comprehensive ocr benchmark for turkish, 2026. URLhttps://arxiv.org/abs/2602.03693
-
[63]
Synthtiger: Synthetic text image generator towards better text recognition models
Moonbin Yim, Yoonsik Kim, Han-Cheol Cho, and Sungrae Park. Synthtiger: Synthetic text image generator towards better text recognition models. InDocument Analysis and Recognition – ICDAR 2021, pages 109–124, Cham, 2021. Springer International Publishing
2021
-
[64]
Tibetanmnist: Tibetan handwritten digit dataset,
Mingqi Yuan, Cairang Xianmu, Jian Tang, et al. Tibetanmnist: Tibetan handwritten digit dataset,
-
[65]
URLhttps://www.heywhale.com/mw/dataset/5bfe734a954d6e0010683839
-
[66]
Multimodal OCR: Parse anything from documents, 2026
Handong Zheng, Yumeng Li, Kaile Zhang, Liang Xin, Guangwei Zhao, Hao Liu, Jiayu Chen, Jie Lou, Jiyu Qiu, Qi Fu, Rui Yang, Shuo Jiang, Weijian Luo, Weijie Su, Weijun Zhang, Xingyu Zhu, Yabin Li, Yiwei ma, Yu Chen, Zhaohui Yu, Guang Yang, Colin Zhang, Lei Zhang, Yuliang Liu, and Xiang Bai. Multimodal OCR: Parse anything from documents, 2026. URL https://arx...
-
[67]
Paper background and rotation.The image is placed onto a randomly cropped scanned paper texture, then rotated by up to±2 ◦ to simulate page tilt
-
[68]
Elastic deformation and Gaussian noise.A smooth displacement field ( 17×17 Gaussian kernel, ±8px amplitude) warps the image; independent Gaussian noise ( σ= 8 ) is then added
-
[69]
Ink effects.Between 10 and 30 white rectangular patches ( ≤40×15 px) simulate ink dropout; pixel intensities are then scaled to 50–85% with texture noise (σ= 10 ) to simulate ink fading
-
[70]
Resolution and compression.Images are downsampled to 40–70% of original resolution and upscaled back (area/bilinear interpolation), then JPEG-compressed at quality 30–80
-
[71]
Additionally, at the glyph level during rendering, character spacing is perturbed by −2 to +4 pixels, each glyph is independently dilated (prob
Perspective distortion.The four corners are independently warped by up to 10% of the image dimensions. Additionally, at the glyph level during rendering, character spacing is perturbed by −2 to +4 pixels, each glyph is independently dilated (prob. 0.4) or eroded (prob. 0.25) with a 2×2 kernel, each line is vertically jittered by up to ±3 pixels, and glyph...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.