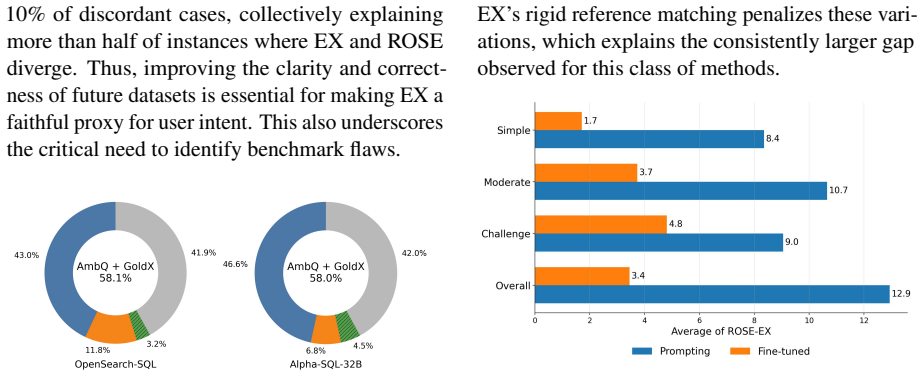
Recognition: unknown
ROSE: An Intent-Centered Evaluation Metric for NL2SQL
Pith reviewed 2026-05-10 13:36 UTC · model grok-4.3
The pith
ROSE evaluates NL2SQL predictions by whether they fulfill user intent rather than matching a reference SQL query.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ROSE is an intent-centered metric for NL2SQL that determines whether a predicted SQL query answers the user's question by employing an adversarial Prover-Refuter cascade. The SQL Prover assesses semantic correctness against user intent independently of any reference, while the Adversarial Refuter uses the ground-truth SQL as evidence to challenge and refine the judgment. This design yields the highest agreement with human experts on the ROSE-VEC validation set, outperforming the next-best metric by nearly 24 percent in Cohen's Kappa, and supports a large-scale re-evaluation of nineteen NL2SQL methods that reveals four insights.
What carries the argument
The adversarial Prover-Refuter cascade, in which the SQL Prover judges semantic correctness against user intent and the Adversarial Refuter challenges that judgment using ground-truth SQL as evidence.
If this is right
- ROSE reduces sensitivity to syntactic variations among semantically equivalent SQL answers.
- ROSE can still produce reliable scores even when the provided ground-truth SQL contains errors.
- Re-evaluation of nineteen NL2SQL methods with ROSE surfaces four previously obscured insights into their relative strengths.
- Release of the ROSE metric and ROSE-VEC dataset enables more consistent and human-aligned benchmarking in future NL2SQL work.
Where Pith is reading between the lines
- Similar adversarial intent-checking cascades could be adapted to evaluate other natural-language-to-structured-output systems where multiple correct answers exist.
- Model training pipelines might incorporate ROSE-style signals to reward intent fidelity rather than surface-level SQL matching.
- The ROSE-VEC construction process offers a template for building expert-aligned test sets in related tasks such as text-to-code generation.
Load-bearing premise
The Prover-Refuter cascade can reliably judge whether predicted SQL matches user intent without introducing systematic biases from the ground-truth SQL or from how the cascade is implemented.
What would settle it
A new collection of NL2SQL examples labeled by human experts where ROSE's judgments disagree with the experts on a substantial fraction of cases or where ROSE's Cohen's Kappa with experts falls below that of execution accuracy.
Figures




read the original abstract
Execution Accuracy (EX), the widely used metric for evaluating the effectiveness of Natural Language to SQL (NL2SQL) solutions, is becoming increasingly unreliable. It is sensitive to syntactic variation, ignores that questions may admit multiple interpretations, and is easily misled by erroneous ground-truth SQL. To address this, we introduce ROSE, an intent-centered metric that focuses on whether the predicted SQL answers the question, rather than consistency with the ground-truth SQL under the reference-dependent paradigm. ROSE employs an adversarial Prover-Refuter cascade: SQL Prover assesses the semantic correctness of a predicted SQL against the user's intent independently, while Adversarial Refuter uses the ground-truth SQL as evidence to challenge and refine this judgment. On our expert-aligned validation set ROSE-VEC, ROSE achieves the best agreement with human experts, outperforming the next-best metric by nearly 24% in Cohen's Kappa. We also conduct a largescale re-evaluation of 19 NL2SQL methods, revealing four valuable insights. We release ROSE and ROSE-VEC to facilitate more reliable NL2SQL research.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper argues that Execution Accuracy (EX) is unreliable for NL2SQL evaluation due to sensitivity to syntactic variation, multiple valid interpretations, and erroneous ground-truth SQL. It proposes ROSE, an intent-centered metric using an adversarial Prover-Refuter cascade where the Prover judges predicted SQL against user intent independently and the Refuter uses ground-truth SQL to challenge and refine the assessment. On the expert-aligned ROSE-VEC validation set, ROSE achieves the highest human agreement, outperforming the next-best metric by nearly 24% Cohen's Kappa, and the authors re-evaluate 19 NL2SQL methods to derive four insights while releasing the metric and dataset.
Significance. If the central claims hold after addressing implementation details, ROSE could meaningfully improve evaluation reliability in NL2SQL by shifting focus from reference-dependent matching to intent alignment, enabling more trustworthy comparisons of methods and reducing misleading results from flawed metrics like EX. The release of ROSE and ROSE-VEC supports reproducibility and further research.
major comments (3)
- [Abstract, §3] Abstract and §3 (Prover-Refuter cascade description): The claim that ROSE is 'intent-centered' and assesses 'independently' of ground-truth is load-bearing for the superiority claim, yet the Refuter explicitly incorporates ground-truth SQL as evidence to challenge judgments. This risks introducing the exact reference-dependent bias criticized in EX (e.g., if the cascade systematically favors or penalizes based on GT presence even when GT is erroneous), potentially making the reported Kappa gain on ROSE-VEC artifactual rather than a genuine advance in reference-independent evaluation.
- [§4] §4 (ROSE-VEC construction and results): The 24% Kappa improvement over the next-best metric is the primary empirical support for the central claim, but the manuscript provides no details on how the expert-aligned validation set was constructed, how experts were selected or instructed, inter-annotator agreement statistics, or validation against potential biases in the cascade itself. Without this, it is impossible to verify that the human agreement reflects true intent alignment rather than alignment with the authors' own procedure.
- [§3.1–3.2] §3.1–3.2 (implementation and prompts): The Prover-Refuter cascade is an LLM-based procedure whose output depends critically on prompt engineering, model choice, and aggregation rules, yet no specifics are given on these (e.g., exact prompts, temperature, or how conflicting Prover/Refuter outputs are resolved). This undermines reproducibility and makes it difficult to assess whether the reported human agreement is robust or sensitive to implementation choices.
minor comments (2)
- [Abstract] The abstract mentions 'four valuable insights' from the re-evaluation of 19 methods but does not preview them; a brief enumeration in the abstract or introduction would improve readability.
- [§3] Notation for the cascade components (Prover, Refuter, final judgment) should be formalized with equations or pseudocode in §3 to clarify the exact procedure.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments, which help clarify key aspects of our work. We respond point-by-point to the major comments below, indicating where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract, §3] Abstract and §3 (Prover-Refuter cascade description): The claim that ROSE is 'intent-centered' and assesses 'independently' of ground-truth is load-bearing for the superiority claim, yet the Refuter explicitly incorporates ground-truth SQL as evidence to challenge judgments. This risks introducing the exact reference-dependent bias criticized in EX (e.g., if the cascade systematically favors or penalizes based on GT presence even when GT is erroneous), potentially making the reported Kappa gain on ROSE-VEC artifactual rather than a genuine advance in reference-independent evaluation.
Authors: We appreciate this observation on the distinction between components. The Prover indeed evaluates predicted SQL solely against user intent without GT access, establishing the intent-centered core. The Refuter then uses GT adversarially to challenge and refine, aiming to reduce false positives (e.g., from ambiguous intent) rather than enforce reference matching as in EX. This hybrid design intentionally tempers pure independence to improve robustness against erroneous GT, which the paper critiques in EX. We do not claim complete reference-independence but a meaningful shift toward intent alignment. The Kappa gains on ROSE-VEC reflect agreement with human experts focused on intent, not an artifact, though we acknowledge the referee's concern about potential bias. We will revise the abstract and §3 to more precisely delineate the Prover's independence from the Refuter's role and discuss this trade-off explicitly. revision: partial
-
Referee: [§4] §4 (ROSE-VEC construction and results): The 24% Kappa improvement over the next-best metric is the primary empirical support for the central claim, but the manuscript provides no details on how the expert-aligned validation set was constructed, how experts were selected or instructed, inter-annotator agreement statistics, or validation against potential biases in the cascade itself. Without this, it is impossible to verify that the human agreement reflects true intent alignment rather than alignment with the authors' own procedure.
Authors: We agree these details are essential for verifying the validation process and ruling out procedural bias. The current manuscript summarizes ROSE-VEC but omits full construction specifics. In the revision, we will expand §4 with: (1) the dataset construction methodology, including source queries and SQL pairs; (2) expert selection criteria (e.g., SQL proficiency and NL2SQL research experience) and recruitment process; (3) annotation instructions provided to experts; (4) inter-annotator agreement metrics (e.g., Cohen's or Fleiss' Kappa); and (5) steps to mitigate bias, such as independent annotation without cascade exposure and post-hoc comparison of expert judgments against ROSE outputs. This will allow readers to assess alignment with true intent. revision: yes
-
Referee: [§3.1–3.2] §3.1–3.2 (implementation and prompts): The Prover-Refuter cascade is an LLM-based procedure whose output depends critically on prompt engineering, model choice, and aggregation rules, yet no specifics are given on these (e.g., exact prompts, temperature, or how conflicting Prover/Refuter outputs are resolved). This undermines reproducibility and makes it difficult to assess whether the reported human agreement is robust or sensitive to implementation choices.
Authors: We acknowledge the omission of these critical implementation details, which limits reproducibility. The manuscript describes the cascade at a high level but does not include the underlying prompts or hyperparameters. In the revised version, we will add a dedicated subsection (or appendix) specifying: the exact prompts for Prover and Refuter (including any few-shot examples), the LLM model and version used, temperature and other generation parameters, and the precise aggregation logic for resolving Prover-Refuter conflicts (e.g., priority rules or consensus mechanisms). We will also include a brief sensitivity analysis where feasible to demonstrate robustness. revision: yes
Circularity Check
No circularity: ROSE is a procedurally defined metric evaluated empirically on an independent human-aligned set
full rationale
The paper introduces ROSE via an explicit adversarial cascade definition (Prover assesses predicted SQL vs. user intent; Refuter refines using GT SQL) and reports its superiority as an empirical Cohen's Kappa gain on the newly constructed ROSE-VEC expert validation set. No equations, fitted parameters, or self-citations are shown to make the reported agreement reduce by construction to the metric's own inputs or prior author results. The derivation chain is self-contained as a new evaluation procedure whose validity claim rests on external human judgments rather than tautological re-labeling or self-referential fitting.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption User intent can be assessed independently of any ground-truth SQL
Reference graph
Works this paper leans on
-
[1]
C3: Zero -shot text-to-SQL with ChatGPT
C3: Zero-shot Text-to-SQL with ChatGPT. Preprint, arXiv:2307.07306. Dawei Gao, Haibin Wang, Yaliang Li, Xiuyu Sun, Yichen Qian, Bolin Ding, and Jingren Zhou. 2024. Text-to-SQL Empowered by Large Language Mod- els: A Benchmark Evaluation.Proceedings of the VLDB Endowment, 17(5):1132–1145. Google DeepMind. 2025. Gemini 2.5: Our most intelli- gent AI model. ...
-
[2]
https://api.semanticscholar.org/CorpusID:282389107
A Survey of Data Agents: Emerging Paradigm or Overstated Hype?Preprint, arXiv:2510.23587. A Mathematical Definitions of NL2SQL Metrics • Exact Match (EM).Given a predicted SQL Sp and a ground-truth SQL Sg, with their nor- malized forms denoted as ˆSp and ˆSg respec- tively: EM(Sp, Sg) = ( ˆSp ≡ ˆSg) • Component Match (CM).The score is the proportion of th...
-
[3]
Determine what the expected answer content should be based on the question and evidence
-
[4]
Understand what the predicted SQL is trying to accomplish and what it achieves
-
[5]
Assess whether the SQL results meet the question requirements under the chosen interpretation
-
[6]
What percentage of refunds are from euro payments?
Make a judgment based on the analysis. ### Judging Principles - Anchor requirements: verify explicit constraints implied by the question, evidence. If a required anchor cannot be validated from the provided inputs, return false and name the missing anchor in reason. - Ambiguity handling: when wording admits multiple reasonable interpretations not contradi...
2023
-
[7]
First, determine what the expected answer content should be based on the question and evidence
-
[8]
Then, analyze what the predicted SQL is trying to accomplish and what it achieves
-
[9]
Next, assess whether the SQL results meet the question requirements
-
[10]
"" O.2 Adversarial Refuter Prompt system_prompt_refuter =
Finally, make your judgment based on the analysis Return ONLY the JSON object directly. ###### Question {question} ###### Evidence {evidence} ###### Predicted SQL {predicted_sql} ###### Database Information {db_info} ###### SQL Execution Result {sql_result} """ O.2 Adversarial Refuter Prompt system_prompt_refuter = """ You are a **SQL Refuter** judge for ...
-
[11]
Check for structural or syntax differences between the two SQL queries and compare their execution results
**Observe differences**: Start by examining SQL syntax and execution result differences between prediction and gold standard. Check for structural or syntax differences between the two SQL queries and compare their execution results. If results differ, note the specific discrepancy
-
[12]
First, check if the SQL queries are logically correct and aligned with the question 's goal
**Analyze semantics**: Understand what each query actually means in answering the question. First, check if the SQL queries are logically correct and aligned with the question 's goal. Then, examine whether the queries are trying to accomplish the same thing, such as filtering or joining tables to provide a correct answer to the question. Ensure that the ...
-
[13]
ambiguous question
**Classify the cause**: Determine if differences stem from ambiguous schema or ambiguous question (valid alternative interpretations). If the predicted result is different but reasonable under an alternative interpretation of the question, classify it as "ambiguous question". If the error in either the predicted or gold query is due to the schema being to...
-
[14]
**Apply decision**: Based on the analysis, provide the judgement and verdict. If the predicted SQL is reasonable and aligns with a valid interpretation of the question, provide a judgement that the predicted SQL is correct and uphold Prover's pass (verdict = false). If the predicted SQL is incorrect or results in errors, provide a judgement that the predi...
-
[15]
Anchor missing or violations: The prediction breaks explicit requirements from the question/ evidence/schema
-
[16]
how many
Schema misuse: The prediction uses wrong columns/tables, invalid join keys, or semantics that contradict the provided schema. - Do not overturn for: - Logically equivalent formulations. - Benign representation changes that preserve meaning. - Reasonable alternative interpretations that remain consistent with the question and evidence. - Tie-handling diffe...
2023
-
[17]
Check for structural or syntax differences between the two SQL queries and compare their execution results
First, observe differences: examine SQL syntax and execution result differences between prediction and gold standard. Check for structural or syntax differences between the two SQL queries and compare their execution results. If results differ, note the specific discrepancy
-
[18]
Check if the SQL queries are logically correct and aligned with the question's goal
Then, analyze semantics: understand what each query actually means in answering the question. Check if the SQL queries are logically correct and aligned with the question's goal. Examine whether the queries are trying to accomplish the same thing, such as filtering or joining tables to provide a correct answer to the question. Ensure that the semantics of...
-
[19]
ambiguous question
Next, classify the cause: determine if differences stem from ambiguous schema or ambiguous question (valid alternative interpretations). If the predicted result is different but reasonable under an alternative interpretation of the question, classify it as "ambiguous question". If the error in either the predicted or gold query is due to the schema being ...
-
[20]
"" user_prompt_refuter_without_results =
Finally, apply decision: based on the analysis, provide the judgement and verdict. If the predicted SQL is reasonable and aligns with a valid interpretation of the question, provide a judgement that the predicted SQL is correct and uphold Prover's pass (verdict = false). If the predicted SQL is incorrect or results in errors, provide a judgement that the ...
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.