Recognition: unknown
Toward Autonomous Long-Horizon Engineering for ML Research
Pith reviewed 2026-05-10 15:46 UTC · model grok-4.3
The pith
AiScientist achieves higher performance on long-horizon ML research benchmarks by using hierarchical orchestration and a File-as-Bus workspace.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
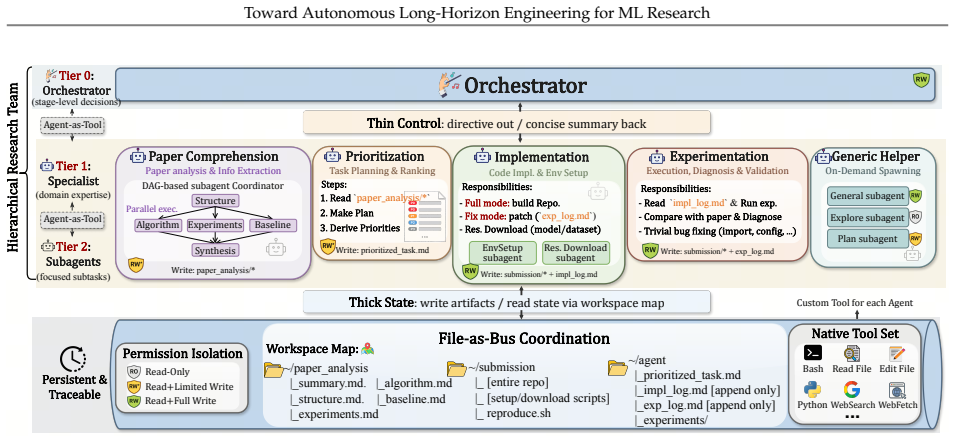
We present AiScientist as a system for long-horizon ML research engineering that integrates hierarchical orchestration with a permission-scoped File-as-Bus workspace. The orchestrator exerts thin control by issuing concise summaries and maintaining a workspace map, while specialized agents re-ground their work on durable artifacts including analyses, plans, code, and experimental evidence. This architecture produces coherent multi-stage progress and delivers measurable gains: an average 10.54-point improvement on PaperBench over the strongest baseline and 81.82 Any Medal% on MLE-Bench Lite. Ablation experiments identify the File-as-Bus protocol as a primary contributor to these outcomes.
What carries the argument
The File-as-Bus workspace under hierarchical orchestration: agents exchange and persist project state through files rather than conversation, with an orchestrator providing high-level direction via summaries and maps.
Load-bearing premise
The benchmarks used reflect real-world long-horizon ML research demands and the performance differences arise chiefly from the proposed orchestration and File-as-Bus components.
What would settle it
An experiment showing that a baseline agent with only conversational memory achieves similar scores on PaperBench and MLE-Bench Lite, or a new benchmark where the AiScientist design fails to maintain progress over longer periods.
Figures


read the original abstract
Autonomous AI research has advanced rapidly, but long-horizon ML research engineering remains difficult: agents must sustain coherent progress across task comprehension, environment setup, implementation, experimentation, and debugging over hours or days. We introduce AiScientist, a system for autonomous long-horizon engineering for ML research built on a simple principle: strong long-horizon performance requires both structured orchestration and durable state continuity. To this end, AiScientist combines hierarchical orchestration with a permission-scoped File-as-Bus workspace: a top-level Orchestrator maintains stage-level control through concise summaries and a workspace map, while specialized agents repeatedly re-ground on durable artifacts such as analyses, plans, code, and experimental evidence rather than relying primarily on conversational handoffs, yielding thin control over thick state. Across two complementary benchmarks, AiScientist improves PaperBench score by 10.54 points on average over the best matched baseline and achieves 81.82 Any Medal% on MLE-Bench Lite. Ablation studies further show that File-as-Bus protocol is a key driver of performance, reducing PaperBench by 6.41 points and MLE-Bench Lite by 31.82 points when removed. These results suggest that long-horizon ML research engineering is a systems problem of coordinating specialized work over durable project state, rather than a purely local reasoning problem.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes AiScientist, a system for autonomous long-horizon engineering in ML research. It combines hierarchical orchestration, where a top-level Orchestrator uses concise summaries and a workspace map for stage-level control, with specialized agents that rely on a durable File-as-Bus workspace for state continuity instead of conversational handoffs. Evaluations on PaperBench and MLE-Bench Lite show an average 10.54 point improvement on PaperBench over the best matched baseline and 81.82 Any Medal% on MLE-Bench Lite. Ablations indicate that removing the File-as-Bus protocol reduces scores by 6.41 on PaperBench and 31.82 on MLE-Bench Lite.
Significance. Should the results prove robust under controlled conditions, the work is significant in demonstrating that long-horizon ML research tasks benefit from systems-level designs emphasizing structured coordination and persistent state management. The explicit use of benchmarks with reported ablations strengthens the case for this approach over purely reasoning-focused methods.
major comments (1)
- The manuscript states that baselines are 'best matched' and reports ablation results for File-as-Bus removal, but does not detail whether the ablation maintains identical agent sets, model choices, total token budgets, and interaction limits as the full AiScientist system. This information is necessary to attribute the performance differences specifically to the hierarchical orchestration and File-as-Bus design rather than other implementation factors.
minor comments (1)
- The abstract could specify the number of experimental runs or include variance measures for the reported average improvements.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the major comment below and will revise the manuscript to provide the requested experimental controls.
read point-by-point responses
-
Referee: The manuscript states that baselines are 'best matched' and reports ablation results for File-as-Bus removal, but does not detail whether the ablation maintains identical agent sets, model choices, total token budgets, and interaction limits as the full AiScientist system. This information is necessary to attribute the performance differences specifically to the hierarchical orchestration and File-as-Bus design rather than other implementation factors.
Authors: We agree that the manuscript should explicitly document these controls to allow readers to attribute the ablation results to the File-as-Bus protocol. In the revised version we will add a dedicated paragraph in the Experiments section (and update the ablation table caption) stating that the File-as-Bus ablation uses identical agent sets, the same model choices and backends, the same total token budgets, and the same interaction limits as the full AiScientist system. This clarification will be added without altering any reported numbers. revision: yes
Circularity Check
No circularity: empirical benchmark results with no derivations or self-referential loops
full rationale
The paper describes an implemented system (AiScientist) and reports measured performance on external benchmarks (PaperBench, MLE-Bench Lite) plus ablation deltas. No equations, first-principles derivations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text. Claims reduce to observed scores rather than any quantity defined in terms of itself or smuggled via prior author work. Attribution concerns (baseline matching, component isolation) are experimental-validity issues, not circularity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Specialized agents can effectively re-ground on durable file artifacts such as analyses, plans, code, and experimental evidence
invented entities (1)
-
File-as-Bus workspace
no independent evidence
Forward citations
Cited by 2 Pith papers
-
AutoResearchBench: Benchmarking AI Agents on Complex Scientific Literature Discovery
AutoResearchBench is a new benchmark showing top AI agents achieve under 10% success on complex scientific literature discovery tasks that demand deep comprehension and open-ended search.
-
GEAR: Genetic AutoResearch for Agentic Code Evolution
GEAR applies genetic algorithms to maintain and evolve multiple research states in autonomous code agents, outperforming single-path baselines by continuing to discover improvements over extended runs.
Reference graph
Works this paper leans on
-
[1]
Cemri, M
M. Cemri, M. Z. Pan, S. Yang, L. A. Agrawal, B. Chopra, R. Tiwari, K. Keutzer, A. Parameswaran, D. Klein, K. Ramchandran, M. Zaharia, J. E. Gonzalez, and I. Stoica. Why do multi-agent LLM systems fail? 2025. URL https://openreview.net/forum?id=fAjbYBmonr
2025
-
[2]
J. S. Chan, N. Chowdhury, O. Jaffe, J. Aung, D. Sherburn, E. Mays, G. Starace, K. Liu, L. Maksin, T. Patwardhan, A. Madry, and L. Weng. MLE -bench: Evaluating machine learning agents on machine learning engineering. In The Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/forum?id=6s5uXNWGIh
2025
- [3]
-
[4]
Gemini 3 flash
Google DeepMind . Gemini 3 flash. https://deepmind.google/models/gemini/flash/, 2025
2025
-
[5]
S. Hong, M. Zhuge, J. Chen, X. Zheng, Y. Cheng, J. Wang, C. Zhang, Z. Wang, S. K. S. Yau, Z. Lin, et al. Metagpt: Meta programming for a multi-agent collaborative framework. In The twelfth international conference on learning representations, 2023
2023
- [6]
-
[7]
Karpathy
A. Karpathy. autoresearch: AI agents running research on single- GPU nanochat training automatically. https://github.com/karpathy/autoresearch, 2026. Released March 7, 2026
2026
- [8]
-
[9]
G. Li, H. Hammoud, H. Itani, D. Khizbullin, and B. Ghanem. Camel: Communicative agents for" mind" exploration of large language model society. Advances in neural information processing systems, 36: 0 51991--52008, 2023
2023
- [10]
- [11]
-
[12]
C. Lu, C. Lu, R. T. Lange, J. Foerster, J. Clune, and D. Ha. The AI scientist: Towards fully automated open-ended scientific discovery. arXiv preprint arXiv:2408.06292, 2024
work page internal anchor Pith review arXiv 2024
-
[13]
A. Nadafian, A. Mohammadshahi, and M. Yazdani. Kapso: A knowledge-grounded framework for autonomous program synthesis and optimization. arXiv preprint arXiv:2601.21526, 2026
-
[14]
Introducing GPT -5.4, 2026
OpenAI . Introducing GPT -5.4, 2026. URL https://openai.com/index/introducing-gpt-5-4/
2026
-
[15]
C. Qian, W. Liu, H. Liu, N. Chen, Y. Dang, J. Li, C. Yang, W. Chen, Y. Su, X. Cong, J. Xu, D. Li, Z. Liu, and M. Sun. C hat D ev: Communicative agents for software development. In L.-W. Ku, A. Martins, and V. Srikumar, editors, Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 15174--151...
-
[16]
doi: 10.18653/v1/2025.findings-emnlp.320
S. Schmidgall, Y. Su, Z. Wang, X. Sun, J. Wu, X. Yu, J. Liu, M. Moor, Z. Liu, and E. Barsoum. Agent laboratory: Using LLM agents as research assistants. In C. Christodoulopoulos, T. Chakraborty, C. Rose, and V. Peng, editors, Findings of the Association for Computational Linguistics: EMNLP 2025, pages 5977--6043, Suzhou, China, Nov. 2025. Association for ...
-
[17]
M. Seo, J. Baek, S. Lee, and S. J. Hwang. Paper2Code : Automating code generation from scientific papers in machine learning. 2026. URL https://openreview.net/forum?id=3DcaUTjdKc
2026
-
[18]
Starace, O
G. Starace, O. Jaffe, D. Sherburn, J. Aung, J. S. Chan, L. Maksin, R. Dias, E. Mays, B. Kinsella, W. Thompson, J. Heidecke, A. Glaese, and T. Patwardhan. Paperbench: Evaluating AI s ability to replicate AI research. In Forty-second International Conference on Machine Learning, 2025. URL https://openreview.net/forum?id=xF5PuTLPbn
2025
-
[19]
J. Tang, L. Xia, Z. Li, and C. Huang. AI-Researcher : Autonomous scientific innovation. 2025. URL https://openreview.net/forum?id=kQWyOYUAC4
2025
-
[20]
Toledo, K
E. Toledo, K. Hambardzumyan, M. Josifoski, R. HAZRA, N. Baldwin, A. Audran-Reiss, M. Kuchnik, D. Magka, M. Jiang, A. M. Lupidi, A. Lupu, R. Raileanu, T. Shavrina, K. Niu, J.-C. Gagnon-Audet, M. Shvartsman, S. Sodhani, A. H. Miller, A. Charnalia, D. Dunfield, C.-J. Wu, P. Stenetorp, N. Cancedda, J. N. Foerster, and Y. Bachrach. AI research agents for machi...
2025
- [21]
-
[22]
Y. Weng, M. Zhu, Q. Xie, Q. Sun, Z. Lin, S. Liu, and Y. Zhang. Deepscientist: Advancing frontier-pushing scientific findings progressively. In The Fourteenth International Conference on Learning Representations, 2026. URL https://openreview.net/forum?id=cZFgsLq8Gs
2026
- [23]
-
[24]
The AI Scientist-v2: Workshop-Level Automated Scientific Discovery via Agentic Tree Search
Y. Yamada, R. T. Lange, C. Lu, S. Hu, C. Lu, J. Foerster, J. Clune, and D. Ha. The ai scientist-v2: Workshop-level automated scientific discovery via agentic tree search. arXiv preprint arXiv:2504.08066, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [25]
- [26]
-
[27]
A. Zeng, X. Lv, Z. Hou, Z. Du, Q. Zheng, B. Chen, D. Yin, C. Ge, C. Huang, C. Xie, et al. Glm-5: from vibe coding to agentic engineering. arXiv preprint arXiv:2602.15763, 2026
work page internal anchor Pith review arXiv 2026
-
[28]
Zhang, P
R. Zhang, P. Qin, Q. Cao, L. Zhang, and P. Xie. Aibuildai: An ai agent that automatically builds ai models, 2026
2026
- [29]
- [30]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.