Recognition: unknown
AutoResearchBench: Benchmarking AI Agents on Complex Scientific Literature Discovery
Pith reviewed 2026-05-07 16:32 UTC · model grok-4.3
The pith
Current AI agents reach only 9 percent accuracy on tasks that require finding and understanding specific scientific papers through open-ended search.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
AutoResearchBench consists of Deep Research tasks that require tracking a specific target paper through multi-step probing and Wide Research tasks that require collecting all papers satisfying stated conditions. Even the strongest current LLMs achieve only 9.39 percent accuracy on Deep Research and 9.31 percent IoU on Wide Research, while many baselines fall below 5 percent, despite high performance on general agentic web-browsing benchmarks such as BrowseComp. The benchmark is distinguished by requiring in-depth scientific concept comprehension, fine-grained use of detailed paper information, and deliberate reasoning over an unknown number of relevant papers.
What carries the argument
The AutoResearchBench suite of two task types: Deep Research (progressive multi-step probing to locate one target paper) and Wide Research (comprehensive collection of all papers meeting open conditions).
If this is right
- Agents must develop stronger in-depth scientific concept comprehension to succeed on these tasks.
- Open-ended collection of unknown numbers of papers requires more deliberate, uncertainty-aware search strategies than current general web agents use.
- Future autonomous research systems will need specialized training or architectures beyond those sufficient for BrowseComp-style benchmarks.
- Releasing the dataset and evaluation pipeline allows direct measurement of progress on research-oriented literature discovery.
- Performance gaps highlight that literature-focused, research-oriented benchmarks are necessary to evaluate true autonomy beyond general web navigation.
Where Pith is reading between the lines
- If the benchmark tasks prove representative, then progress toward fully autonomous research will require new agent designs that integrate deeper semantic understanding of scientific text rather than surface-level retrieval.
- Similar benchmarks could be built for later research stages such as hypothesis generation or experimental design to create an end-to-end autonomy evaluation suite.
- The low scores suggest that current scaling trends alone may not close the gap without explicit training on scientific literature structures and uncertainty handling.
- The open-ended nature of Wide Research could serve as a test bed for studying how agents manage search under incomplete information, with direct relevance to other domains like legal or medical document discovery.
Load-bearing premise
That success or failure on the constructed Deep and Wide Research tasks will translate to success or failure at the real-world skill of autonomous scientific literature discovery.
What would settle it
A controlled study in which the same AI agents are tested on AutoResearchBench tasks and then on actual researcher-chosen literature searches for new problems, checking whether high benchmark scores predict high real-world retrieval quality and completeness.
Figures











read the original abstract
Autonomous scientific research is significantly advanced thanks to the development of AI agents. One key step in this process is finding the right scientific literature, whether to explore existing knowledge for a research problem, or to acquire evidence for verifying assumptions and supporting claims. To assess AI agents' capability in driving this process, we present AutoResearchBench, a dedicated benchmark for autonomous scientific literature discovery. AutoResearchBench consists of two complementary task types: (1) Deep Research, which requires tracking down a specific target paper through a progressive, multi-step probing process, and (2) Wide Research, which requires comprehensively collecting a set of papers satisfying given conditions. Compared to previous benchmarks on agentic web browsing, AutoResearchBench is distinguished along three dimensions: it is research-oriented, calling for in-depth comprehension of scientific concepts; literature-focused, demanding fine-grained utilization of detailed information; and open-ended, involving an unknown number of qualified papers and thus requiring deliberate reasoning and search throughout. These properties make AutoResearchBench uniquely suited for evaluating autonomous research capabilities, and extraordinarily challenging. Even the most powerful LLMs, despite having largely conquered general agentic web-browsing benchmarks such as BrowseComp, achieve only 9.39% accuracy on Deep Research and 9.31% IoU on Wide Research, while many other strong baselines fall below 5%. We publicly release the dataset and evaluation pipeline to facilitate future research in this direction. We publicly release the dataset, evaluation pipeline, and code at https://github.com/CherYou/AutoResearchBench.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces AutoResearchBench, a new benchmark for AI agents performing autonomous scientific literature discovery. It defines two tasks: Deep Research, which requires agents to locate a specific target paper via progressive multi-step probing, and Wide Research, which requires exhaustive collection of all papers meeting open-ended conditions. The authors evaluate multiple LLM-based agents and baselines on these tasks, reporting low scores (9.39% accuracy on Deep Research and 9.31% IoU on Wide Research) even for frontier models that perform well on general web-browsing benchmarks such as BrowseComp. They position the benchmark as uniquely challenging because it demands in-depth scientific concept comprehension, fine-grained use of literature details, and deliberate reasoning over an unknown number of relevant papers. The dataset, evaluation pipeline, and code are released publicly.
Significance. If the tasks are shown to genuinely require progressive concept comprehension and exhaustive open-ended collection rather than surface-level keyword matching, the benchmark would be a valuable addition to the field by exposing a clear capability gap in current agents for research-oriented workflows. The public release of the dataset and code is a concrete strength that enables follow-on work. However, the headline performance gap with BrowseComp is only informative about research skills to the extent that the task construction prevents trivial solutions.
major comments (2)
- [Abstract and §3] Abstract and §3 (Benchmark Construction): The claim that the tasks are 'research-oriented, calling for in-depth comprehension of scientific concepts' and 'open-ended, involving an unknown number of qualified papers' is not supported by any explicit protocol for generating targets, conditions, or query seeds. Without this protocol or the generation code, it is impossible to rule out that agents could succeed via repeated title/abstract keyword searches on arXiv/Google Scholar without reading full texts or synthesizing concepts, which would make the 9.39% / 9.31% scores uninformative about the intended research capabilities.
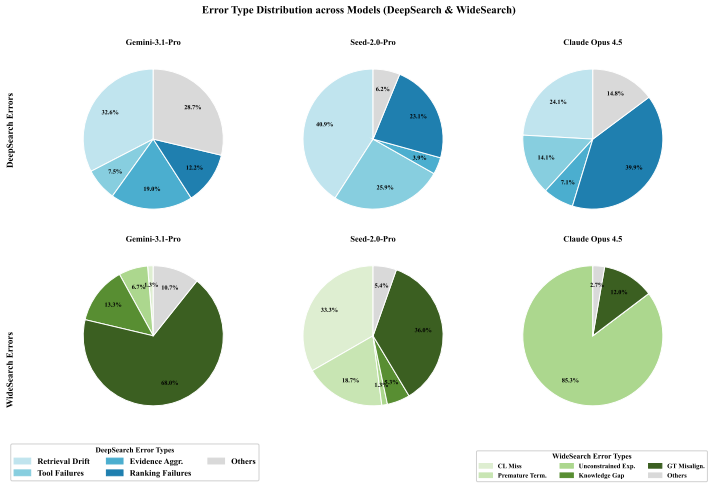
- [§5] §5 (Experiments and Results): The performance tables report aggregate accuracy and IoU but provide no error analysis, no breakdown by failure mode (e.g., search termination vs. incorrect paper selection), and no qualitative trajectory examples. This omission prevents readers from determining whether the low scores primarily reflect failures of comprehension, of long-horizon planning, or of tool use, weakening the diagnostic value of the benchmark.
minor comments (2)
- [Abstract] Abstract: The final paragraph contains two nearly identical sentences about public release; the repetition should be consolidated.
- [§3] The paper would be strengthened by adding a short appendix or supplementary note that lists the exact arXiv categories, date ranges, and filtering criteria used to source the underlying papers.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback on our manuscript. The comments have identified important areas where additional clarity and analysis will strengthen the presentation of AutoResearchBench. We respond to each major comment below and describe the revisions we will incorporate.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (Benchmark Construction): The claim that the tasks are 'research-oriented, calling for in-depth comprehension of scientific concepts' and 'open-ended, involving an unknown number of qualified papers' is not supported by any explicit protocol for generating targets, conditions, or query seeds. Without this protocol or the generation code, it is impossible to rule out that agents could succeed via repeated title/abstract keyword searches on arXiv/Google Scholar without reading full texts or synthesizing concepts, which would make the 9.39% / 9.31% scores uninformative about the intended research capabilities.
Authors: We appreciate the referee raising this point about transparency in task construction. The manuscript states that the dataset, evaluation pipeline, and code are released at https://github.com/CherYou/AutoResearchBench, and the repository does contain the scripts used to generate the tasks. To make this fully self-contained and address concerns about potential trivial solutions, we will revise §3 to include an explicit description of the generation protocol. This will detail the criteria for selecting target papers and conditions (e.g., requirements for multi-hop concept linking and exhaustive coverage that cannot be satisfied by title/abstract keyword matching alone), along with examples of query seeds and verification steps. We will also add a pointer to the specific generation code in the text. These changes will allow readers to directly assess why surface-level searches are insufficient for high performance. revision: yes
-
Referee: [§5] §5 (Experiments and Results): The performance tables report aggregate accuracy and IoU but provide no error analysis, no breakdown by failure mode (e.g., search termination vs. incorrect paper selection), and no qualitative trajectory examples. This omission prevents readers from determining whether the low scores primarily reflect failures of comprehension, of long-horizon planning, or of tool use, weakening the diagnostic value of the benchmark.
Authors: We agree that the current results section would benefit from greater diagnostic detail to help readers interpret the sources of the observed performance gaps. In the revised manuscript, we will add a dedicated error analysis subsection to §5. This will include a quantitative breakdown of failure modes (e.g., premature termination of search, selection of incorrect papers, and tool invocation errors) derived from the logged agent trajectories. We will also incorporate 3–4 qualitative examples of representative trajectories for both Deep Research and Wide Research tasks, illustrating specific points where agents succeeded or failed in concept comprehension, planning, or tool use. These additions will improve the benchmark's utility for diagnosing capability limitations in current agents. revision: yes
Circularity Check
Empirical benchmark definition with no derivation chain or self-referential reductions
full rationale
The paper introduces AutoResearchBench as a new evaluation suite consisting of Deep Research and Wide Research tasks, then reports direct empirical accuracy and IoU metrics from running various LLM agents on the released dataset. No equations, fitted parameters, predictions, or first-principles derivations are present. Task construction and evaluation protocols are defined explicitly in the paper itself without reducing to prior self-citations or renaming known results. The reported performance gaps (e.g., 9.39% Deep Research accuracy) are measured outcomes rather than quantities forced by construction or self-citation chains. The work is therefore self-contained as an empirical benchmark contribution.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Scientific literature discovery requires in-depth comprehension of concepts and handling of open-ended searches with unknown result counts.
Reference graph
Works this paper leans on
-
[1]
The AI Scientist: Towards Fully Automated Open-Ended Scientific Discovery
Chris Lu, Cong Lu, Robert Tjarko Lange, Jakob Foerster, Jeff Clune, and David Ha. The ai scien- tist: Towards fully automated open-ended scientific discovery.arXiv preprint arXiv:2408.06292, 2024
work page internal anchor Pith review arXiv 2024
-
[3]
Juraj Gottweis, Wei-Hung Weng, Alexander Daryin, Tao Tu, Anil Palepu, Petar Sirkovic, Artiom Myaskovsky, Felix Weissenberger, Keran Rong, Ryutaro Tanno, et al. Towards an ai co-scientist. arXiv preprint arXiv:2502.18864, 2025
work page internal anchor Pith review arXiv 2025
-
[4]
Jiabin Tang, Lianghao Xia, Zhonghang Li, and Chao Huang. Ai-researcher: Autonomous scientific innovation.arXiv preprint arXiv:2505.18705, 2025
-
[5]
Agent laboratory: Using llm agents as research assistants.Findings of the Association for Computational Linguistics: EMNLP 2025, pages 5977–6043, 2025
Samuel Schmidgall, Yusheng Su, Ze Wang, Ximeng Sun, Jialian Wu, Xiaodong Yu, Jiang Liu, Michael Moor, Zicheng Liu, and Emad Barsoum. Agent laboratory: Using llm agents as research assistants.Findings of the Association for Computational Linguistics: EMNLP 2025, pages 5977–6043, 2025
2025
-
[6]
Minju Seo, Jinheon Baek, Seongyun Lee, and Sung Ju Hwang. Paper2code: Automating code generation from scientific papers in machine learning.arXiv preprint arXiv:2504.17192, 2025
-
[7]
In NeurIPS 2025 AI for Science Workshop
Tengyue Xu, Zhuoyang Qian, Gaoge Liu, Li Ling, Zhentao Zhang, Biao Wu, Shuo Zhang, Ke Lu, Wei Shi, Ziqi Wang, et al. Idea2story: An automated pipeline for transforming research concepts into complete scientific narratives.arXiv preprint arXiv:2601.20833, 2026
-
[8]
https: //arxiv.org/abs/2512.07921
Zongwei Li, Zhonghang Li, Zirui Guo, Xubin Ren, and Chao Huang. Deepcode: Open agentic coding.arXiv preprint arXiv:2512.07921, 2025
-
[9]
Toward Autonomous Long-Horizon Engineering for ML Research
Guoxin Chen, Jie Chen, Lei Chen, Jiale Zhao, Fanzhe Meng, Wayne Xin Zhao, Ruihua Song, Cheng Chen, Ji-Rong Wen, and Kai Jia. Toward autonomous long-horizon engineering for ml research.arXiv preprint arXiv:2604.13018, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[10]
International Conference on Learning Representations (ICLR) , year =
Yixuan Weng, Minjun Zhu, Qiujie Xie, Qiyao Sun, Zhen Lin, Sifan Liu, and Yue Zhang. Deepscientist: Advancing frontier-pushing scientific findings progressively.arXiv preprint arXiv:2509.26603, 2025
-
[11]
Deepxiv-sdk: An agentic data interface for scientific papers
Hongjin Qian, Ziyi Xia, Ze Liu, Jianlv Chen, Kun Luo, Minghao Qin, Chaofan Li, Lei Xiong, Sen Wang, Zhengyang Liang, et al. Deepxiv-sdk: An agentic data interface for scientific papers. arXiv preprint arXiv:2603.00084, 2026
-
[12]
Litsearch: A retrieval benchmark for scientific literature search
Anirudh Ajith, Mengzhou Xia, Alexis Chevalier, Tanya Goyal, Danqi Chen, and Tianyu Gao. Litsearch: A retrieval benchmark for scientific literature search. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 15068–15083, 2024
2024
-
[13]
RPC-Bench: A Fine-grained Benchmark for Research Paper Comprehension
Yelin Chen, Fanjin Zhang, Suping Sun, Yunhe Pang, Yuanchun Wang, Jian Song, Xiaoyan Li, Lei Hou, Shu Zhao, Jie Tang, et al. Rpc-bench: A fine-grained benchmark for research paper comprehension.arXiv preprint arXiv:2601.14289, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[14]
WideSearch: Benchmarking agentic broad info-seeking.arXiv preprint arXiv:2508.07999, 2025
Ryan Wong, Jiawei Wang, Junjie Zhao, Li Chen, Yan Gao, Long Zhang, Xuan Zhou, Zuo Wang, Kai Xiang, Ge Zhang, et al. Widesearch: Benchmarking agentic broad info-seeking.arXiv preprint arXiv:2508.07999, 2025
-
[15]
Gaia: a benchmark for general ai assistants
Grégoire Mialon, Clémentine Fourrier, Thomas Wolf, Yann LeCun, and Thomas Scialom. Gaia: a benchmark for general ai assistants. InThe Twelfth International Conference on Learning Representations, 2023
2023
-
[16]
BrowseComp: A Simple Yet Challenging Benchmark for Browsing Agents
Jason Wei, Zhiqing Sun, Spencer Papay, Scott McKinney, Jeffrey Han, Isa Fulford, Hyung Won Chung, Alex Tachard Passos, William Fedus, and Amelia Glaese. Browsecomp: A simple yet challenging benchmark for browsing agents.arXiv preprint arXiv:2504.12516, 2025. 11
work page internal anchor Pith review arXiv 2025
-
[17]
Zijian Chen, Xueguang Ma, Shengyao Zhuang, Ping Nie, Kai Zou, Andrew Liu, Joshua Green, Kshama Patel, Ruoxi Meng, Mingyi Su, et al. Browsecomp-plus: A more fair and transparent evaluation benchmark of deep-research agent.arXiv preprint arXiv:2508.06600, 2025
-
[18]
Webdancer: Towards autonomous information seeking agency, 2025
Jialong Wu, Baixuan Li, Runnan Fang, Wenbiao Yin, Liwen Zhang, Zhengwei Tao, Dingchu Zhang, Zekun Xi, Gang Fu, Yong Jiang, Pengjun Xie, Fei Huang, and Jingren Zhou. Webdancer: Towards autonomous information seeking agency, 2025
2025
-
[19]
Websailor: Navigating super-human reasoning for web agent.arXiv preprint arXiv:2507.02592, 2025
Kuan Li, Zhongwang Zhang, Huifeng Yin, Liwen Zhang, Litu Ou, Jialong Wu, Wenbiao Yin, Baixuan Li, Zhengwei Tao, Xinyu Wang, et al. Websailor: Navigating super-human reasoning for web agent.arXiv preprint arXiv:2507.02592, 2025
-
[20]
Kun Luo, Hongjin Qian, Zheng Liu, Ziyi Xia, Shitao Xiao, Siqi Bao, Jun Zhao, and Kang Liu. Infoflow: Reinforcing search agent via reward density optimization.arXiv preprint arXiv:2510.26575, 2025
-
[21]
Search-o1: Agentic Search-Enhanced Large Reasoning Models
Xiaoxi Li, Guanting Dong, Jiajie Jin, Yuyao Zhang, Yujia Zhou, Yutao Zhu, Peitian Zhang, and Zhicheng Dou. Search-o1: Agentic search-enhanced large reasoning models.CoRR, abs/2501.05366, 2025
work page internal anchor Pith review arXiv 2025
-
[22]
Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning
Bowen Jin, Hansi Zeng, Zhenrui Yue, Dong Wang, Hamed Zamani, and Jiawei Han. Search- r1: Training llms to reason and leverage search engines with reinforcement learning.CoRR, abs/2503.09516, 2025
work page internal anchor Pith review arXiv 2025
-
[23]
Pradeep Dasigi, Kyle Lo, Iz Beltagy, Arman Cohan, Noah A Smith, and Matt Gardner. A dataset of information-seeking questions and answers anchored in research papers.arXiv preprint arXiv:2105.03011, 2021
-
[24]
Sage: Benchmarking and improving retrieval for deep research agents.ArXiv, abs/2602.05975,
Tiansheng Hu, Yilun Zhao, Canyu Zhang, Arman Cohan, and Chen Zhao. Sage: Benchmarking and improving retrieval for deep research agents.arXiv preprint arXiv:2602.05975, 2026
-
[25]
Michael D Skarlinski, Sam Cox, Jon M Laurent, James D Braza, Michaela Hinks, Michael J Hammerling, Manvitha Ponnapati, Samuel G Rodriques, and Andrew D White. Language agents achieve superhuman synthesis of scientific knowledge.arXiv preprint arXiv:2409.13740, 2024
-
[26]
Daoyu Wang, Mingyue Cheng, Shuo Yu, Zirui Liu, Ze Guo, Xin Li, and Qi Liu. Paperarena: An evaluation benchmark for tool-augmented agentic reasoning on scientific literature.arXiv preprint arXiv:2510.10909, 2025
-
[27]
Pasa: An llm agent for comprehensive academic paper search
Yichen He, Guanhua Huang, Peiyuan Feng, Yuan Lin, Yuchen Zhang, Hang Li, et al. Pasa: An llm agent for comprehensive academic paper search. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 11663–11679, 2025
2025
-
[28]
React: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models. InInternational Conference on Learning Representations (ICLR), 2023
2023
-
[29]
Qwen3.5: Towards native multimodal agents, February 2026
Qwen Team. Qwen3.5: Towards native multimodal agents, February 2026
2026
-
[30]
Deepseek-v3.2: Pushing the frontier of open large language models, 2025
DeepSeek-AI. Deepseek-v3.2: Pushing the frontier of open large language models, 2025
2025
-
[31]
Minimax m2.5: Built for real-world productivity
MiniMax. Minimax m2.5: Built for real-world productivity. https://www.minimax.io/ news/minimax-m25, 2026
2026
-
[32]
Kimi K2.5: Visual Agentic Intelligence
Kimi Team et al. Kimi k2.5: Visual agentic intelligence.https://arxiv.org/abs/2602.02276, 2026
work page internal anchor Pith review arXiv 2026
-
[33]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review arXiv 2025
-
[34]
Seed 2.0 official launch
ByteDance Seed Team. Seed 2.0 official launch. https://seed.bytedance.com/en/blog/ seed-2-0-official-launch, 2026. 12
2026
-
[35]
Gemini 3 flash
Google DeepMind. Gemini 3 flash. https://deepmind.google/models/gemini/flash/, 2026
2026
-
[36]
Gemini 3.1 pro
Google DeepMind. Gemini 3.1 pro. https://deepmind.google/models/gemini/pro/, 2026
2026
-
[37]
Introducing GPT-5.4
OpenAI. Introducing GPT-5.4. https://openai.com/index/introducing-gpt-5-4/ , 2026
2026
-
[38]
Introducing Claude Sonnet 4.6
Anthropic. Introducing Claude Sonnet 4.6. https://www.anthropic.com/news/ claude-sonnet-4-6, Feb 2026
2026
-
[39]
Introducing Claude Opus 4.6
Anthropic. Introducing Claude Opus 4.6. https://www.anthropic.com/news/ claude-opus-4-6, 2026
2026
-
[40]
Alphaxiv: The ai-native platform for scientific discovery
Alphaxiv. Alphaxiv: The ai-native platform for scientific discovery. https://www.alphaxiv. org/, 2026
2026
-
[41]
Introducing deep research, 2025
OpenAI. Introducing deep research, 2025
2025
-
[42]
Google AI studio.https://aistudio.google.com/, 2026
Google. Google AI studio.https://aistudio.google.com/, 2026
2026
-
[43]
Webthinker: Empowering large reasoning models with deep research capability,
Xiaoxi Li, Jiajie Jin, Guanting Dong, Hongjin Qian, Yutao Zhu, Yongkang Wu, Ji-Rong Wen, and Zhicheng Dou. Webthinker: Empowering large reasoning models with deep research capability.arXiv preprint arXiv:2504.21776, 2025
-
[44]
Try deep research and our new experimental model in gemini, your ai assistant
Dave Citron. Try deep research and our new experimental model in gemini, your ai assistant. https://blog.google/products/gemini/google-gemini-deep-research/, 2024
2024
-
[45]
Tongyi deepresearch technical report.arXiv preprint arXiv:2510.24701,
Tongyi DeepResearch Team, Baixuan Li, Bo Zhang, Dingchu Zhang, Fei Huang, Guangyu Li, Guoxin Chen, Huifeng Yin, Jialong Wu, Jingren Zhou, et al. Tongyi deepresearch technical report.arXiv preprint arXiv:2510.24701, 2025
-
[46]
Pasa: An llm agent for comprehensive academic paper search, 2025
Yichen He, Guanhua Huang, Peiyuan Feng, Yuan Lin, Yuchen Zhang, Hang Li, and Weinan E. Pasa: An llm agent for comprehensive academic paper search, 2025
2025
-
[47]
Spar: Scholar paper retrieval with llm-based agents for enhanced academic search, 2025
Xiaofeng Shi, Yuduo Li, Qian Kou, Longbin Yu, Jinxin Xie, and Hua Zhou. Spar: Scholar paper retrieval with llm-based agents for enhanced academic search, 2025
2025
-
[48]
In- fodeepseek: Benchmarking agentic information seeking for retrieval-augmented generation
Yunjia Xi, Jianghao Lin, Menghui Zhu, Yongzhao Xiao, Zhuoying Ou, Jiaqi Liu, Tong Wan, Bo Chen, Weiwen Liu, Yasheng Wang, Ruiming Tang, Weinan Zhang, and Yong Yu. In- fodeepseek: Benchmarking agentic information seeking for retrieval-augmented generation. arXiv preprint arXiv:2505.15872, 2025
-
[49]
Deepwidesearch: Benchmarking depth and width in agentic information seeking, 2025
Tian Lan, Bin Zhu, Qianghuai Jia, Junyang Ren, Haijun Li, Longyue Wang, Zhao Xu, Weihua Luo, and Kaifu Zhang. Deepwidesearch: Benchmarking depth and width in agentic information seeking, 2025
2025
-
[50]
Gisa: A benchmark for general information seeking assistant.CoRR, abs/2602.08543, 2026
Yutao Zhu, Xingshuo Zhang, Maosen Zhang, Jiajie Jin, Liancheng Zhang, Xiaoshuai Song, Kangzhi Zhao, Wencong Zeng, Ruiming Tang, Han Li, Ji-Rong Wen, and Zhicheng Dou. Gisa: A benchmark for general information seeking assistant.CoRR, abs/2602.08543, 2026
-
[51]
Table-as-search: Formulate long-horizon agentic information seeking as table completion, 2026
Tian Lan, Felix Henry, Bin Zhu, Qianghuai Jia, Junyang Ren, Qihang Pu, Haijun Li, Longyue Wang, Zhao Xu, and Weihua Luo. Table-as-search: Formulate long-horizon agentic information seeking as table completion, 2026
2026
-
[52]
Tiansheng Hu, Yilun Zhao, Canyu Zhang, Arman Cohan, and Chen Zhao. Sage: Benchmarking and improving retrieval for deep research agents, 2026. 13 A Ethic Statement This benchmark is constructed from publicly accessible scientific papers in arXiv/DeepXiv and does not involve private personal data or direct interaction with human subjects. Human annotators a...
-
[53]
Locate the sub-question that is the most independent and bottom-level
-
[54]
Use the search tool to solve that sub-question and to clarify the user intent
-
[55]
Plug the answer of the sub-question back into the original problem to form a new, more direct search query
-
[56]
Deal with the new sub-question in the next round
-
[57]
name": "search
When the Multi-Hop query is clarified and resolved to single-hop query, search one last time for final candidates. 1.3. Candidate Paper Evaluation - Evaluate the paper list provided in the latest user message within the `<tool_response>` tag. This list contains the results from your most recent search action. Identify which papers are useful and relevant ...
-
[58]
**Thinking**: Your reasoning process here for intent understanding and planning
-
[59]
Then output a list of selected paper IDs from that list within `<candidates>...</candidates>` tags
**Candidate Selection**: Your brief analysis of searched paper from the latest tool response and decide what paper to add as candidates. Then output a list of selected paper IDs from that list within `<candidates>...</candidates>` tags. If you mistakenly keep the previous IDs, it will lead to errors in your results
-
[60]
query\": \
**Action**: EITHER a tool call in <tool_call>...</tool_call> tags OR the finish signal <answer>Done</answer>. SYSTEM PROMPT-2 Figure 13: System prompt-2 of evaluation pipeline. 26 Opus inference case: Correct Trajectory-1 I'm searching for a research work where the authors conducted a comparative evaluation of architectural variants for a computational ma...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.