TableNet A Large-Scale Table Dataset with LLM-Powered Autonomous
Pith reviewed 2026-05-15 19:06 UTC · model grok-4.3
The pith
An LLM-powered autonomous system generates large-scale table datasets and uses active learning to recognize table structures with fewer training samples.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that the first LLM-powered autonomous table generation and recognition multi-agent system can produce a wide array of semantically coherent tables with annotations and support efficient model finetuning through diversity-based active learning, achieving competitive performance on the new dataset while reducing the number of training samples by a large margin and improving generalization to real-world tables.
What carries the argument
The LLM-powered multi-agent system that synthesizes table images using controllable parameters for generation and applies diversity-based active learning to select training data for recognition.
If this is right
- Supports theoretically infinite and domain-agnostic generation of table images with annotations.
- Achieves competitive performance on TableNet with much fewer training samples than traditional methods.
- Delivers higher performance on web-crawled real-world tables compared to models trained on existing predominant datasets.
- Enables a comprehensive annotation taxonomy for advancing table-related research.
Where Pith is reading between the lines
- Similar active learning approaches could be adapted for other complex document structure tasks beyond tables.
- The controllable parameters might allow customization for specific domains like financial or scientific tables.
- Reducing training data needs could make table recognition more accessible for resource-constrained applications.
Load-bearing premise
LLM-generated tables with controllable parameters accurately capture the diversity, complexity, and distribution of real-world tables including merged cells and varied layouts.
What would settle it
Test the active learning model on a fresh collection of diverse web-crawled tables and check if its performance advantage over baseline models trained on standard datasets disappears or reverses.
Figures







read the original abstract
Table Structure Recognition (TSR) requires the logical reasoning ability of large language models (LLMs) to handle complex table layouts, but current datasets are limited in scale and quality, hindering effective use of this reasoning capacity. We thus present TableNet dataset, a new table structure recognition dataset collected and generated through multiple sources. Central to our approach is the first LLM-powered autonomous table generation and recognition multi-agent system that we developed. The generation part of our system integrates controllable visual, structural, and semantic parameters into the synthesis of table images. It facilitates the creation of a wide array of semantically coherent tables, adaptable to user-defined configurations along with annotations, thereby supporting large-scale and detailed dataset construction. This capability enables a comprehensive and nuanced table image annotation taxonomy, potentially advancing research in table-related domains. In contrast to traditional data collection methods, This approach facilitates the theoretically infinite, domain-agnostic, and style-flexible generation of table images, ensuring both efficiency and precision. The recognition part of our system is a diversity-based active learning paradigm that utilizes tables from multiple sources and selectively samples most informative data to finetune a model, achieving a competitive performance on TableNet test set while reducing training samples by a large margin compared with baselines, and a much higher performance on web-crawled real-world tables compared with models trained on predominant table datasets. To the best of our knowledge, this is the first work which employs active learning into the structure recognition of tables which is diverse in numbers of rows or columns, merged cells, cell contents, etc, which fits better for diversity-based active learning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces TableNet, a large-scale dataset for table structure recognition generated and annotated via a novel LLM-powered autonomous multi-agent system. The generation component synthesizes table images using controllable visual, structural, and semantic parameters; the recognition component applies diversity-based active learning to sample informative tables from multiple sources for model finetuning. The central claims are that this yields competitive performance on the TableNet test set while using far fewer training samples than baselines, plus substantially higher performance on web-crawled real-world tables than models trained on existing predominant datasets.
Significance. If the performance claims are substantiated with rigorous metrics, the work could enable scalable, annotation-light dataset construction for TSR and demonstrate the first application of active learning to tables with high structural and semantic diversity. This would reduce dependence on manually curated corpora and improve generalization to real-world layouts, with potential downstream benefits for document understanding pipelines.
major comments (3)
- [Abstract] Abstract: The claims of 'competitive performance on TableNet test set while reducing training samples by a large margin' and 'much higher performance on web-crawled real-world tables' are presented without any numerical results, baseline names, evaluation metrics (e.g., F1, IoU), error bars, or protocol details, rendering the central empirical assertions unverifiable from the manuscript.
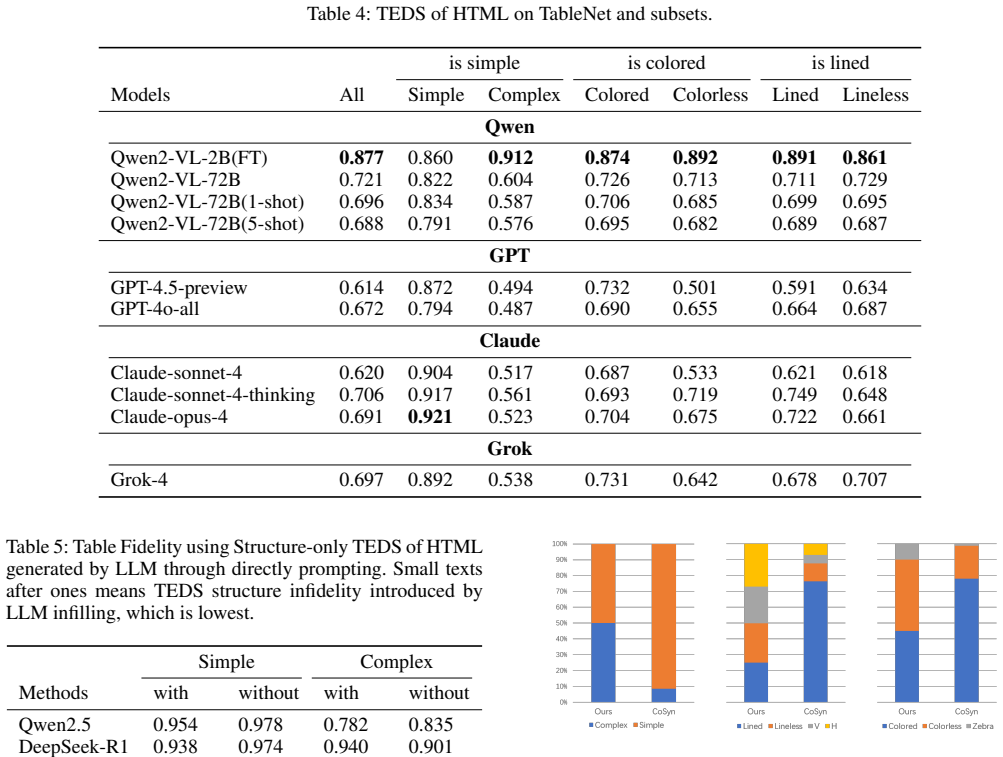
- [Recognition part of the system] Recognition / Active Learning section: No ablation or distributional analysis (e.g., histograms of row/column counts, merge-cell frequency, cell-value entropy) is provided to confirm that LLM-generated tables with controllable parameters match the joint distribution of the web-crawled evaluation set; without this, the reported generalization lift cannot be attributed to the method rather than domain mismatch or leakage.
- [Recognition part of the system] Evaluation: The manuscript supplies no details on the active-learning selection criterion (specific diversity metric), the finetuning protocol, or the composition of the 'multiple sources' used for sampling, all of which are load-bearing for the claim that diversity-based active learning is particularly suited to tables varying in rows, columns, and merged cells.
minor comments (2)
- [Abstract] Abstract: Capitalization error in 'In contrast to traditional data collection methods, This approach' (should be lowercase 'this').
- [Abstract] Abstract: The final sentence is grammatically awkward and repetitive ('which is diverse in numbers of rows or columns, merged cells, cell contents, etc, which fits better for diversity-based active learning'); rephrase for clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight opportunities to strengthen the verifiability and transparency of our empirical claims. We address each point below and will incorporate the requested details and analyses into the revised manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claims of 'competitive performance on TableNet test set while reducing training samples by a large margin' and 'much higher performance on web-crawled real-world tables' are presented without any numerical results, baseline names, evaluation metrics (e.g., F1, IoU), error bars, or protocol details, rendering the central empirical assertions unverifiable from the manuscript.
Authors: We agree that the abstract should be self-contained with specific numbers. In the revision we will insert concrete metrics (e.g., F1 and IoU scores on the TableNet test set, the exact percentage reduction in training samples relative to baselines such as TableFormer and PubTabNet, and the absolute performance gains on the web-crawled set), along with a brief statement of the evaluation protocol and error-bar information where available. revision: yes
-
Referee: [Recognition part of the system] Recognition / Active Learning section: No ablation or distributional analysis (e.g., histograms of row/column counts, merge-cell frequency, cell-value entropy) is provided to confirm that LLM-generated tables with controllable parameters match the joint distribution of the web-crawled evaluation set; without this, the reported generalization lift cannot be attributed to the method rather than domain mismatch or leakage.
Authors: We acknowledge the need for explicit distributional evidence. We will add a new subsection containing histograms and summary statistics (row/column counts, merge-cell frequency, cell-value entropy) comparing the LLM-generated tables against the web-crawled evaluation set. These plots will be accompanied by a short discussion confirming alignment of the joint distributions, thereby supporting attribution of the observed generalization gains to the active-learning procedure rather than domain shift. revision: yes
-
Referee: [Recognition part of the system] Evaluation: The manuscript supplies no details on the active-learning selection criterion (specific diversity metric), the finetuning protocol, or the composition of the 'multiple sources' used for sampling, all of which are load-bearing for the claim that diversity-based active learning is particularly suited to tables varying in rows, columns, and merged cells.
Authors: We agree these implementation details are essential for reproducibility and for justifying the suitability of diversity-based active learning. In the revised manuscript we will (1) state the precise diversity metric (including its mathematical formulation over structural and semantic feature vectors), (2) provide the complete finetuning protocol (hyperparameters, optimizer, number of epochs, early-stopping criteria), and (3) report the exact composition of the sampled sources (e.g., proportions drawn from each generation configuration and external corpora). These additions will directly address why the diversity criterion is well-matched to tables that vary in row/column count and merge-cell structure. revision: yes
Circularity Check
No circularity: empirical claims rest on independent evaluation of new data and active learning
full rationale
The paper describes an LLM-powered table generation system with controllable parameters and a diversity-based active learning pipeline for table structure recognition. All performance numbers (competitive results on TableNet test set with fewer samples, higher accuracy on web-crawled tables) are presented as experimental outcomes from training on the synthesized data and evaluating on held-out and external real-world tables. No equations, fitted parameters renamed as predictions, self-definitional loops, or load-bearing self-citations appear in the derivation; the active-learning selection criterion is described procedurally rather than as a tautology that forces the reported metrics. The central claims therefore remain self-contained empirical statements.
Axiom & Free-Parameter Ledger
free parameters (1)
- controllable visual, structural, and semantic parameters
axioms (1)
- domain assumption LLMs have the logical reasoning ability to handle complex table layouts for both generation and recognition
invented entities (1)
-
LLM-powered autonomous table generation and recognition multi-agent system
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Gpt-4 technical report.arXiv preprint arXiv:2303.08774. Ajayi, K.; Zhang, L.; He, Y .; and Wu, J. 2024. Uncertainty Quan- tification in Table Structure Recognition. In2024 IEEE Interna- tional Conference on Information Reuse and Integration for Data Science (IRI), 1–6. IEEE. Anand, A.; Jaiswal, R.; Bhuyan, P.; Gupta, M.; Bangar, S.; Imam, M. M.; Shah, R. ...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
InProceedings of the IEEE conference on computer vision and pattern recognition, 9368–9377
The power of ensembles for active learning in image classi- fication. InProceedings of the IEEE conference on computer vision and pattern recognition, 9368–9377. Carbune, V .; Mansoor, H.; Liu, F.; Aralikatte, R.; Baechler, G.; Chen, J.; and Sharma, A. 2024. Chart-based reasoning: Transferring capabilities from llms to vlms.arXiv preprint arXiv:2403.12596...
-
[3]
Complicated table structure recognition.arXiv preprint arXiv:1908.04729. Fang, J.; Tao, X.; Tang, Z.; Qiu, R.; and Liu, Y . 2012. Dataset, ground-truth and performance metrics for table detection evalu- ation. In2012 10th IAPR International Workshop on Document Analysis Systems, 445–449. IEEE. Gal, Y .; Islam, R.; and Ghahramani, Z. 2017. Deep bayesian ac...
-
[4]
R., Zhang, D., and Chaudhuri, S
Springer. Koci, E.; Thiele, M.; Romero, O.; and Lehner, W. 2019. A genetic- based search for adaptive table recognition in spreadsheets. In2019 International Conference on Document Analysis and Recognition (ICDAR), 1274–1279. IEEE. Le-Khac, P. H.; Healy, G.; and Smeaton, A. F. 2020. Contrastive representation learning: A framework and review.Ieee Access, ...
-
[5]
Active Learning for Convolutional Neural Networks: A Core-Set Approach
IEEE. Raja, S.; Mondal, A.; and Jawahar, C. 2020. Table structure recog- nition using top-down and bottom-up cues. InComputer Vision– ECCV 2020: 16th European Conference, Glasgow, UK, August 23– 28, 2020, Proceedings, Part XXVIII 16, 70–86. Springer. Rus, D.; and Subramanian, D. 1997. Customizing information cap- ture and access.ACM Transactions on Inform...
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[6]
BERTScore: Evaluating Text Generation with BERT
Bertscore: Evaluating text generation with bert.arXiv preprint arXiv:1904.09675. Zheng, M.; Feng, X.; Si, Q.; She, Q.; Lin, Z.; Jiang, W.; and Wang, W. 2024. Multimodal table understanding.arXiv preprint arXiv:2406.08100. Zheng, X.; Burdick, D.; Popa, L.; Zhong, X.; and Wang, N. X. R
work page internal anchor Pith review Pith/arXiv arXiv 1904
-
[7]
In Proceedings of the IEEE/CVF winter conference on applications of computer vision, 697–706
Global table extractor (gte): A framework for joint table identification and cell structure recognition using visual context. In Proceedings of the IEEE/CVF winter conference on applications of computer vision, 697–706. Zhong, X.; ShafieiBavani, E.; and Jimeno Yepes, A. 2020. Image- based table recognition: data, model, and evaluation. InEuropean conferen...
work page 2020
-
[8]
Zhou, Y .; Cheng, M.; Mao, Q.; Liu, Q.; Xu, F.; Li, X.; and Chen, E
IEEE. Zhou, Y .; Cheng, M.; Mao, Q.; Liu, Q.; Xu, F.; Li, X.; and Chen, E
-
[9]
Enhancing Table Recognition with Vision LLMs: A Bench- mark and Neighbor-Guided Toolchain Reasoner.arXiv preprint arXiv:2412.20662. Zhu, Y .; and Yang, K. 2019. Tripartite active learning for interac- tive anomaly discovery.IEEE Access, 7: 63195–63203. Supplementary Experiment Results Experiments on Multiple Industries To evaluate the semantic consistency...
-
[10]
General Paper Structure 1.1. Includes a conceptual outline and/or pseudocode description of AI methods introduced (yes/partial/no/NA) yes 1.2. Clearly delineates statements that are opinions, hypothesis, and speculation from objective facts and results (yes/no) yes 1.3. Provides well-marked pedagogical references for less- familiar readers to gain backgro...
-
[11]
Theoretical Contributions 2.1. Does this paper make theoretical contributions? (yes/no) no If yes, please address the following points: 2.2. All assumptions and restrictions are stated clearly and for- mally (yes/partial/no) Type your response here 2.3. All novel claims are stated formally (e.g., in theorem state- ments) (yes/partial/no) Type your respons...
-
[12]
Dataset Usage 3.1. Does this paper rely on one or more datasets? (yes/no) yes If yes, please address the following points: 3.2. A motivation is given for why the experiments are con- ducted on the selected datasets (yes/partial/no/NA) yes 3.3. All novel datasets introduced in this paper are included in a data appendix (yes/partial/no/NA) yes 3.4. All nove...
-
[13]
Computational Experiments 4.1. Does this paper include computational experiments? (yes/no) yes If yes, please address the following points: 4.2. This paper states the number and range of values tried per (hyper-) parameter during development of the paper, along with the criterion used for selecting the final parameter set- ting (yes/partial/no/NA) no 4.3....
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.