Can Coding Agents Be General Agents?
Pith reviewed 2026-05-10 16:29 UTC · model grok-4.3
The pith
Coding agents complete simple business tasks but fail on complex ones because they cannot reliably bridge domain logic with code execution.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
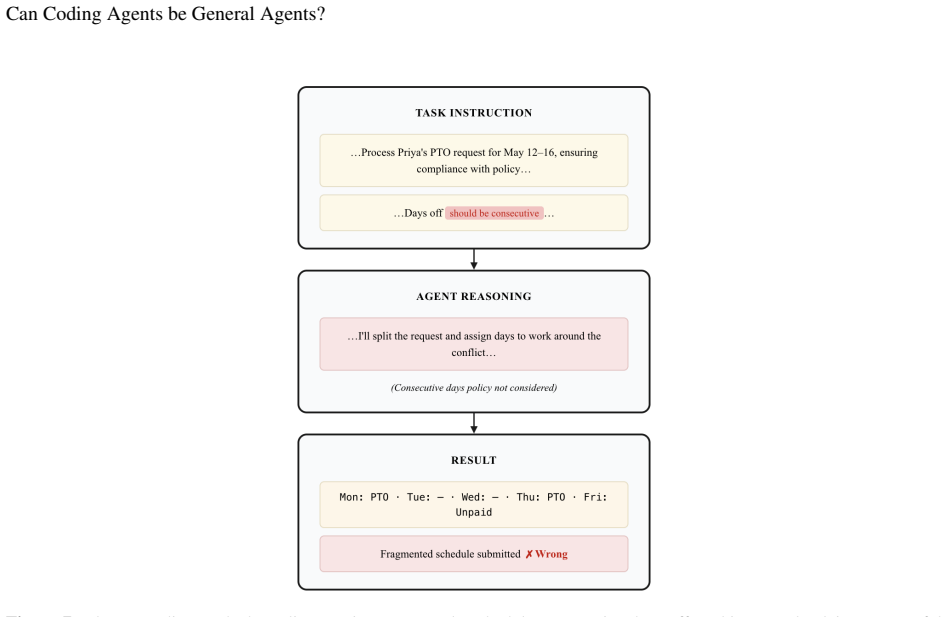
In evaluations of a coding agent on practical business tasks inside an open-core ERP system, the agent reliably completes simple tasks but exhibits characteristic failures on complex tasks. These failures arise when the agent must integrate domain-specific business logic with code execution, revealing a key bottleneck that prevents coding agents from generalizing to end-to-end business process automation.
What carries the argument
Case study evaluation of coding agent performance on simple versus complex tasks in an open-core ERP system, used to expose the domain-logic-to-code-execution gap.
If this is right
- Agents will need explicit mechanisms to connect business rules to code before they can automate end-to-end processes.
- Existing benchmarks miss the domain-logic integration problems that appear in real business systems.
- Simple-task success does not predict performance on tasks requiring coordinated logic across modules.
- General agent use cases will remain limited until the domain-code bridge is addressed.
Where Pith is reading between the lines
- Similar bottlenecks may appear in other non-coding domains where agents must apply specialized rules alongside code.
- Hybrid designs that pair coding agents with separate reasoning modules for domain logic could be tested as a direct remedy.
- Repeating the case study across different ERP platforms or agent architectures would clarify whether the pattern is widespread.
Load-bearing premise
The failures seen in this single open-core ERP case study are representative of coding agents in general rather than specific to the agent, the chosen tasks, or the system.
What would settle it
An experiment in which the same or similar coding agents successfully complete multiple complex multi-step business processes in the ERP system without the identified domain-logic failures would refute the bottleneck claim.
Figures






read the original abstract
As coding agents have seen rapid capability and adoption gains, users are applying them to general tasks beyond software engineering. In this post, we investigate whether coding agents can successfully generalize to end-to-end business process automation. We identify gaps in current evaluations, and conduct a case study to evaluate a coding agent on practical business tasks in an open-core Enterprise Resource Planning system. We find that the agent reliably completes simple tasks but exhibits characteristic failures on complex tasks, suggesting that bridging domain logic and code execution is a key bottleneck to generalizability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper investigates whether coding agents can generalize beyond software engineering to end-to-end business process automation. It presents a case study evaluating one coding agent on practical tasks in a single open-core ERP system and concludes that the agent reliably succeeds on simple tasks but shows characteristic failures on complex tasks, attributing this to a bottleneck in bridging domain logic with code execution.
Significance. An empirically grounded identification of integration bottlenecks between domain knowledge and executable code would be useful for guiding agent research toward more generalizable systems. The work provides an initial observational data point in the under-explored area of business-process automation, but the single-system design limits the strength of any generalizability claims.
major comments (2)
- [Case study and results sections] The inference that observed failures are 'characteristic' and indicate a general 'bridging domain logic and code execution' bottleneck for coding agents rests on a single open-core ERP case study. No controls (different agents, different domains, or ablation of the domain-logic component) are reported, so the attribution cannot be distinguished from artifacts of the chosen agent, task set, or ERP data model/API surface. This directly undermines the central claim in the abstract and discussion.
- [Evaluation methodology and results] No task counts, success criteria, quantitative metrics, or statistical controls appear in the reported evaluation. Without these, it is impossible to determine whether the 'reliable' success on simple tasks or the 'characteristic failures' on complex tasks are robust or merely anecdotal.
minor comments (2)
- [Abstract] The abstract would be strengthened by briefly stating the number of tasks, the definition of success, and the agent/system versions used.
- [Case study description] Clarify how tasks were selected and categorized as 'simple' versus 'complex' to allow readers to assess potential selection bias.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments on our manuscript. The work is presented as an initial case study exploring the generalization of coding agents to business process automation, and we appreciate the opportunity to clarify its scope and strengthen the reporting of results. We respond point-by-point to the major comments below.
read point-by-point responses
-
Referee: [Case study and results sections] The inference that observed failures are 'characteristic' and indicate a general 'bridging domain logic and code execution' bottleneck for coding agents rests on a single open-core ERP case study. No controls (different agents, different domains, or ablation of the domain-logic component) are reported, so the attribution cannot be distinguished from artifacts of the chosen agent, task set, or ERP data model/API surface. This directly undermines the central claim in the abstract and discussion.
Authors: We agree that the study is limited to a single coding agent and one open-core ERP system, and we do not claim to have established a general bottleneck applicable to all coding agents. The manuscript is explicitly framed as a case study whose goal is to surface observable patterns in agent behavior on practical business tasks. The phrase 'characteristic failures' is used to describe recurring failure modes (e.g., inability to correctly map domain concepts to executable operations) that appeared consistently across the complex tasks we examined; these are documented with concrete examples in the results. We will revise the abstract, discussion, and a new limitations subsection to qualify the language, replacing stronger claims with statements such as 'observations from this case study suggest that bridging domain logic and code execution may be a bottleneck' and explicitly noting the absence of cross-agent or cross-domain controls. This revision will be made without altering the core empirical observations. revision: partial
-
Referee: [Evaluation methodology and results] No task counts, success criteria, quantitative metrics, or statistical controls appear in the reported evaluation. Without these, it is impossible to determine whether the 'reliable' success on simple tasks or the 'characteristic failures' on complex tasks are robust or merely anecdotal.
Authors: The evaluation section currently emphasizes qualitative description of task outcomes and failure modes rather than aggregate statistics. We accept that this presentation makes it difficult for readers to gauge the scale and consistency of the results. In the revised manuscript we will add an explicit 'Evaluation Setup' subsection that states: (1) the total number of tasks attempted, (2) the breakdown into simple versus complex categories, (3) the precise success criteria applied (completion of the end-to-end business process with correct data state and no manual intervention required), and (4) the observed success counts per category. These counts will be presented in a table. Because the study was designed as an observational case study rather than a controlled experiment, we did not pre-specify statistical tests; we will note this limitation while still providing the raw counts so readers can form their own assessment of robustness. revision: yes
Circularity Check
No circularity: purely observational case study with no derivations or fitted predictions
full rationale
The paper reports results from a single open-core ERP case study, observing that a coding agent succeeds on simple tasks but shows failures on complex ones. It offers an interpretive suggestion that bridging domain logic and code execution is a bottleneck, but this is not derived from any equations, parameters, or formal chain that reduces to inputs by construction. There are no mathematical predictions, self-definitional loops, fitted inputs renamed as predictions, or load-bearing self-citations. The work is self-contained as an empirical report; its claims rest on direct task outcomes rather than any internal reduction. This matches the default non-circular outcome for observational studies without derivations.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Unified pre-training for program understanding and generation.arXiv preprint arXiv:2103.06333,
Wasi Uddin Ahmad, Saikat Chakraborty, Baishakhi Ray, and Kai-Wei Chang. Unified pre-training for program understanding and generation.arXiv preprint, arXiv:2103.06333, 2021
-
[2]
Evaluating Large Language Models Trained on Code
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde De Oliveira Pinto, Jared Kaplan, Harri Edwards, et al. Evaluating large language models trained on code.arXiv preprint, arXiv:2107.03374, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[3]
SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. Swe-bench: Can language models resolve real-world github issues?arXiv preprint, arXiv:2310.06770, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
Introducing swe bench verified.OpenAI Blog, 2024
OpenAI-Research. Introducing swe bench verified.OpenAI Blog, 2024
work page 2024
-
[5]
Terminal bench.TerminalBench Leaderboard, 2024
TerminalBench-Team. Terminal bench.TerminalBench Leaderboard, 2024
work page 2024
-
[6]
@anthropic-ai/claude-code.npm package, 2025
Anthropic-Research. @anthropic-ai/claude-code.npm package, 2025
work page 2025
-
[7]
Claude code is my computer.Blog post, 2025
Peter Steinberger. Claude code is my computer.Blog post, 2025
work page 2025
-
[8]
Building agents with the claude agent sdk.Anthropic Engineering Blog, 2024
Anthropic-Research. Building agents with the claude agent sdk.Anthropic Engineering Blog, 2024. 9 Can Coding Agents be General Agents?
work page 2024
-
[9]
Toolformer: Language Models Can Teach Themselves to Use Tools
Timo Schick, Jane Dwivedi-Yu, Roberto Dessi, Roberta Raileanu, Maria Lomeli, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. Toolformer: Language models can teach themselves to use tools.arXiv preprint, arXiv:2302.04761, 2023
work page internal anchor Pith review arXiv 2023
-
[10]
To code, or not to code? exploring impact of code in pre-training
Viraat Aryabumi, Yixuan Su, Raymond Ma, Adrien Morisot, Ivan Zhang, Acyr Locatelli, Marzieh Fadaee, Ahmet Ustun, and Sara Hooker. To code, or not to code? exploring impact of code in pre-training.arXiv preprint, arXiv:2408.10914, 2024
-
[11]
Executable code actions elicit better LLM agents
Xingyao Wang, Yangyi Chen, Lifan Yuan, Yizhe Zhang, Yunzhu Li, Hao Peng, and Heng Ji. Executable code actions elicit better llm agents.arXiv preprint, arXiv:2402.01030, 2024
-
[12]
Gpt-5.1 codex max.OpenAI Blog, 2025
OpenAI-Research. Gpt-5.1 codex max.OpenAI Blog, 2025
work page 2025
-
[13]
$\tau$-bench: A Benchmark for Tool-Agent-User Interaction in Real-World Domains
Shunyu Yao, Noah Shinn, Pedram Razavi, and Karthik Narasimhan. Tau-bench: A benchmark for tool-agent-user interaction in real-world domains.arXiv preprint, arXiv:2406.12045, 2024
work page internal anchor Pith review arXiv 2024
-
[14]
Gorilla-Team. The berkeley function calling leaderboard (bfcl): From tool use to agentic evaluation of large language models.UC Berkeley, 2024
work page 2024
-
[15]
Sycophancy to Subterfuge: Investigating Reward-Tampering in Large Language Models
Carson Denison, Monte MacDiarmid, Fazl Barez, David Duvenaud, Shauna Kravec, Samuel Marks, Nicholas Schiefer, Ryan Soklaski, Alex Tamkin, Jared Kaplan, Buck Shlegeris, Samuel R. Bowman, Ethan Perez, and Evan Hubinger. Sycophancy to subterfuge: Investigating reward tampering in language models.arXiv preprint, arXiv:2406.10162, 2024
work page internal anchor Pith review arXiv 2024
-
[16]
Richard S. Sutton. The bitter lesson.Essay, 2019. 10
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.