Recognition: unknown
InfiniteScienceGym: An Unbounded, Procedurally-Generated Benchmark for Scientific Analysis
Pith reviewed 2026-05-10 15:36 UTC · model grok-4.3
The pith
A procedurally generated benchmark reveals that language models achieve no more than 45% accuracy on scientific data reasoning tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
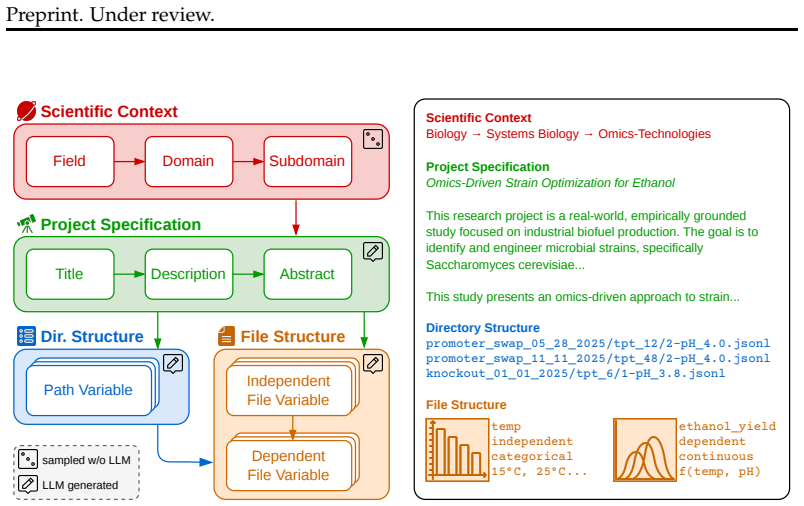
InfiniteScienceGym uses a deterministic simulator to generate realistic directory structures, files, and tabular data from a seed, along with a privileged generator that creates answerable and unanswerable questions with exact ground truth, enabling controlled evaluation of evidence-grounded reasoning and tool use in scientific analysis.
What carries the argument
The procedural generator that creates unbounded scientific repositories and verifiable question-answer pairs from seeds.
If this is right
- Current models, both proprietary and open, fail to exceed 45% overall accuracy on the benchmark.
- Models have significant difficulty recognizing when questions cannot be answered from the provided data.
- More capable models demonstrate better performance by using tools effectively instead of relying on increased token consumption.
Where Pith is reading between the lines
- Such a benchmark could be extended to generate more complex multi-file analysis tasks that mirror actual research workflows.
- It might help identify specific training data needs for improving abstention in scientific contexts.
- Performance on this benchmark could be compared to real-world scientific tasks to validate transfer.
Load-bearing premise
The synthetic repositories and questions sufficiently mimic the challenges of real scientific data analysis for model failures to indicate real-world deficiencies.
What would settle it
A model scoring under 45% on InfiniteScienceGym that performs well above that on a collection of actual published scientific analysis tasks would indicate the benchmark does not capture transferable skills.
Figures



read the original abstract
Large language models are emerging as scientific assistants, but evaluating their ability to reason from empirical data remains challenging. Benchmarks derived from published studies and human annotations inherit publication bias, known-knowledge bias, label noise, and substantial storage requirements. We present InfiniteScienceGym, a procedurally generated benchmark of scientific repositories paired with a verifiable question-answering task. From a seed, the simulator deterministically generates a self-contained repository with realistic directory structure, files, and tabular data, and a privileged QA generator produces both answerable and unanswerable questions with exact ground truth. This makes it possible to evaluate evidence-grounded reasoning, abstention, and tool-mediated analysis in a controlled setting without distributing a large static corpus. InfiniteScienceGym complements real scientific benchmarks by targeting blind spots and failure modes that are hard to evaluate using published datasets alone. Evaluating both proprietary and open-weight models, we find that none achieve more than 45% accuracy overall, that recognizing unanswerable questions remains a major weakness, and that stronger models tend to use tools more effectively rather than simply consuming more tokens.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces InfiniteScienceGym, a procedurally generated, unbounded benchmark consisting of self-contained scientific repositories (with realistic directory structures, files, and tabular data) paired with verifiable QA tasks. A deterministic simulator produces both answerable and unanswerable questions with exact ground truth, enabling evaluation of evidence-grounded reasoning, abstention, and tool use without distributing large static corpora. Evaluations of proprietary and open-weight LLMs show no model exceeding 45% overall accuracy, with particular weaknesses in recognizing unanswerable questions and a tendency for stronger models to use tools more effectively rather than consuming more tokens.
Significance. If the generated repositories and questions are shown to be sufficiently representative of real empirical science, the benchmark would provide a scalable, bias-reduced complement to existing datasets by allowing controlled, unlimited testing of LLM limitations in scientific analysis. The reported patterns in tool use versus token consumption and abstention failures would be useful observations for guiding model improvements in evidence-based reasoning.
major comments (2)
- The central claims that the benchmark reveals 'meaningful blind spots' and that observed failures (45% accuracy cap, unanswerable question weakness) transfer to real scientific analysis rest on the procedural generator producing realistic data. However, no quantitative validation is described comparing generated distributions (e.g., variable correlations, missing-data patterns, or question complexity) to real empirical datasets; this is load-bearing for the transferability argument in the abstract.
- The evaluation results (including the 45% accuracy ceiling and tool-use observations) are stated without details on model selection criteria, the number and diversity of generated QA pairs, question generation validation procedures, or statistical significance testing. These omissions make it difficult to assess whether the reported model weaknesses are robust or sensitive to generation artifacts.
minor comments (1)
- The abstract would be strengthened by briefly specifying the range of scientific domains or data modalities covered by the simulator to clarify the benchmark's intended scope.
Simulated Author's Rebuttal
We are grateful to the referee for their constructive feedback on our manuscript. We address each major comment point by point below, indicating where revisions have been made.
read point-by-point responses
-
Referee: The central claims that the benchmark reveals 'meaningful blind spots' and that observed failures (45% accuracy cap, unanswerable question weakness) transfer to real scientific analysis rest on the procedural generator producing realistic data. However, no quantitative validation is described comparing generated distributions (e.g., variable correlations, missing-data patterns, or question complexity) to real empirical datasets; this is load-bearing for the transferability argument in the abstract.
Authors: We thank the referee for highlighting this point. The abstract states that InfiniteScienceGym 'complements real scientific benchmarks by targeting blind spots and failure modes that are hard to evaluate using published datasets alone,' rather than claiming statistical equivalence or direct transfer of results. The generator is designed to capture structural and procedural elements common in empirical science (e.g., directory hierarchies, mixed tabular data with realistic missingness), but we acknowledge the absence of quantitative distribution matching. In the revised manuscript we have added a dedicated 'Generator Design' subsection with qualitative justification for parameter choices and explicit caveats that results are indicative of potential limitations rather than proven on real data. Full quantitative validation against proprietary corpora lies outside the current scope, so this is a partial revision focused on clarification and softening of transferability language. revision: partial
-
Referee: The evaluation results (including the 45% accuracy ceiling and tool-use observations) are stated without details on model selection criteria, the number and diversity of generated QA pairs, question generation validation procedures, or statistical significance testing. These omissions make it difficult to assess whether the reported model weaknesses are robust or sensitive to generation artifacts.
Authors: We agree that these details are required for assessing robustness. The revised manuscript expands the Experiments and Evaluation Setup sections to specify: model selection criteria (proprietary models GPT-4o and Claude-3 alongside open-weight models Llama-3-70B and Mixtral-8x7B for capability and accessibility diversity); scale (500 repositories from distinct seeds, each with 20 QA pairs for a total of 10,000 questions balanced across answerable/unanswerable); validation (automated ground-truth consistency checks plus manual review of a 5% random sample by two domain experts); and statistical testing (bootstrap 95% confidence intervals over 1,000 resamples plus paired t-tests for model comparisons). These additions are now included. revision: yes
Circularity Check
No significant circularity; results are direct empirical measurements on new simulator-generated data
full rationale
The paper presents a new benchmark constructed via procedural generation from seeds, with ground-truth labels produced by the same deterministic simulator. The reported evaluation results (model accuracies, tool-use patterns, abstention failures) are direct measurements of LLM performance against these independently generated QA pairs and repositories. No equations, predictions, or central claims reduce by construction to fitted parameters, prior self-citations, or renamed inputs; the benchmark is self-contained and the findings are falsifiable by running the provided generator. Minor unstated assumptions in the procedural rules affect realism but do not create circularity in the derivation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Procedurally generated scientific repositories and questions can simulate realistic empirical data analysis challenges without inheriting publication or annotation biases.
Reference graph
Works this paper leans on
-
[1]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
-
[2]
Autodiscovery: Open-ended scientific discovery via bayesian surprise
Dhruv Agarwal, Bodhisattwa Prasad Majumder, Reece Adamson, Megha Chakravorty, Satvika Reddy Gavireddy, Aditya Parashar, Harshit Surana, Bhavana Dalvi Mishra, Andrew McCallum, Ashish Sabharwal, and Peter Clark. Autodiscovery: Open-ended scientific discovery via bayesian surprise. In The Thirty-ninth Annual Conference on Neural Information Processing System...
2025
-
[3]
Artifact review and badging
Association for Computing Machinery . Artifact review and badging. https://www.acm.org/publications/policies/artifact-review-and-badging-current, 2024. Accessed: 2026-03-29
2024
-
[4]
Tabfact: A large-scale dataset for table-based fact verification
Wenhu Chen, Hongmin Wang, Jianshu Chen, Yunkai Zhang, Hong Wang, Shiyang Li, Xiyou Zhou, and William Yang Wang. Tabfact: A large-scale dataset for table-based fact verification. In International Conference on Learning Representations, 2020. URL https://openreview.net/forum?id=rkeJRhNYDH
2020
-
[5]
Baker, Benjamin Burns, Daniel Adu-Ampratwum, Xuhui Huang, Xia Ning, Song Gao, Yu Su, and Huan Sun
Ziru Chen, Shijie Chen, Yuting Ning, Qianheng Zhang, Boshi Wang, Botao Yu, Yifei Li, Zeyi Liao, Chen Wei, Zitong Lu, Vishal Dey, Mingyi Xue, Frazier N. Baker, Benjamin Burns, Daniel Adu-Ampratwum, Xuhui Huang, Xia Ning, Song Gao, Yu Su, and Huan Sun. Scienceagentbench: Toward rigorous assessment of language agents for data-driven scientific discovery. In ...
2025
-
[6]
Publication bias: the problem that won't go away
K Dickersin and Y I Min. Publication bias: the problem that won't go away. Ann N Y Acad Sci, 703: 0 135--46; discussion 146--8, December 1993
1993
-
[7]
Don ' t hallucinate, abstain: Identifying LLM knowledge gaps via multi- LLM collaboration
Shangbin Feng, Weijia Shi, Yike Wang, Wenxuan Ding, Vidhisha Balachandran, and Yulia Tsvetkov. Don ' t hallucinate, abstain: Identifying LLM knowledge gaps via multi- LLM collaboration. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar (eds.), Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), p...
-
[8]
Towards Autonomous Mathematics Research.arXiv preprint arXiv:2602.10177, 2026
Tony Feng, Trieu H. Trinh, Garrett Bingham, Dawsen Hwang, Yuri Chervonyi, Junehyuk Jung, Joonkyung Lee, Carlo Pagano, Sang hyun Kim, Federico Pasqualotto, Sergei Gukov, Jonathan N. Lee, Junsu Kim, Kaiying Hou, Golnaz Ghiasi, Yi Tay, YaGuang Li, Chenkai Kuang, Yuan Liu, Hanzhao Lin, Evan Zheran Liu, Nigamaa Nayakanti, Xiaomeng Yang, Heng-Tze Cheng, Demis H...
-
[9]
Alfredo Guevara, Alexandru Lupsasca, David Skinner, Andrew Strominger, and Kevin Weil. Single-minus gluon tree amplitudes are nonzero, 2026. URL https://arxiv.org/abs/2602.12176
-
[10]
INFOTABS: Inference on tables as semi-structured data
Vivek Gupta, Maitrey Mehta, Pegah Nokhiz, and Vivek Srikumar. INFOTABS : Inference on tables as semi-structured data. In Dan Jurafsky, Joyce Chai, Natalie Schluter, and Joel Tetreault (eds.), Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pp.\ 2309--2324, Online, July 2020. Association for Computational Linguistic...
-
[11]
S imul B ench: Evaluating language models with creative simulation tasks
Qi Jia, Xiang Yue, Tuney Zheng, Jie Huang, and Bill Yuchen Lin. S imul B ench: Evaluating language models with creative simulation tasks. In Luis Chiruzzo, Alan Ritter, and Lu Wang (eds.), Findings of the Association for Computational Linguistics: NAACL 2025, pp.\ 8133--8146, Albuquerque, New Mexico, April 2025. Association for Computational Linguistics. ...
-
[12]
SWE -bench: Can language models resolve real-world github issues? In The Twelfth International Conference on Learning Representations, 2024
Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik R Narasimhan. SWE -bench: Can language models resolve real-world github issues? In The Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=VTF8yNQM66
2024
-
[13]
Why Language Models Hallucinate
Adam Tauman Kalai, Ofir Nachum, Santosh S. Vempala, and Edwin Zhang. Why language models hallucinate, 2025. URL https://arxiv.org/abs/2509.04664
work page internal anchor Pith review arXiv 2025
-
[14]
Content analysis: An introduction to its methodology
Klaus Krippendorff. Content analysis: An introduction to its methodology. Sage, Thousand Oaks, CA, 2nd edition, 2004
2004
-
[15]
Spider 2.0: Evaluating language models on real-world enterprise text-to- SQL workflows
Fangyu Lei, Jixuan Chen, Yuxiao Ye, Ruisheng Cao, Dongchan Shin, Hongjin SU, ZHAOQING SUO, Hongcheng Gao, Wenjing Hu, Pengcheng Yin, Victor Zhong, Caiming Xiong, Ruoxi Sun, Qian Liu, Sida Wang, and Tao Yu. Spider 2.0: Evaluating language models on real-world enterprise text-to- SQL workflows. In The Thirteenth International Conference on Learning Represen...
2025
-
[16]
Can llm already serve as a database interface? a big bench for large-scale database grounded text-to-sqls
Jinyang Li, Binyuan Hui, Ge Qu, Jiaxi Yang, Binhua Li, Bowen Li, Bailin Wang, Bowen Qin, Ruiying Geng, Nan Huo, et al. Can llm already serve as a database interface? a big bench for large-scale database grounded text-to-sqls. Advances in Neural Information Processing Systems, 36, 2024
2024
-
[17]
RepoBench : Benchmarking repository-level code auto-completion systems
Tianyang Liu, Canwen Xu, and Julian McAuley. Repobench: Benchmarking repository-level code auto-completion systems, 2024. URL https://arxiv.org/abs/2306.03091
-
[18]
Discoverybench: Towards data-driven discovery with large language models
Bodhisattwa Prasad Majumder, Harshit Surana, Dhruv Agarwal, Bhavana Dalvi Mishra, Abhijeetsingh Meena, Aryan Prakhar, Tirth Vora, Tushar Khot, Ashish Sabharwal, and Peter Clark. Discoverybench: Towards data-driven discovery with large language models. In The Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/...
2025
-
[19]
Publication bias and the canonization of false facts
Silas Boye Nissen, Tali Magidson, Kevin Gross, and Carl T Bergstrom. Publication bias and the canonization of false facts. Elife, 5, December 2016
2016
-
[20]
Alexander Novikov, Ngân Vũ, Marvin Eisenberger, Emilien Dupont, Po-Sen Huang, Adam Zsolt Wagner, Sergey Shirobokov, Borislav Kozlovskii, Francisco J. R. Ruiz, Abbas Mehrabian, M. Pawan Kumar, Abigail See, Swarat Chaudhuri, George Holland, Alex Davies, Sebastian Nowozin, Pushmeet Kohli, and Matej Balog. Alphaevolve: A coding agent for scientific and algori...
work page internal anchor Pith review arXiv 2025
-
[21]
OpenAI, :, Sandhini Agarwal, Lama Ahmad, Jason Ai, Sam Altman, Andy Applebaum, Edwin Arbus, Rahul K. Arora, Yu Bai, Bowen Baker, Haiming Bao, Boaz Barak, Ally Bennett, Tyler Bertao, Nivedita Brett, Eugene Brevdo, Greg Brockman, Sebastien Bubeck, Che Chang, Kai Chen, Mark Chen, Enoch Cheung, Aidan Clark, Dan Cook, Marat Dukhan, Casey Dvorak, Kevin Fives, V...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
`smolagents`: a smol library to build great agentic systems
Aymeric Roucher, Albert Villanova del Moral, Thomas Wolf, Leandro von Werra, and Erik Kaunismäki. `smolagents`: a smol library to build great agentic systems. https://github.com/huggingface/smolagents, 2025
2025
-
[23]
Parshin Shojaee, Ngoc-Hieu Nguyen, Kazem Meidani, Amir Barati Farimani, Khoa D Doan, and Chandan K. Reddy. LLM - SRB ench: A new benchmark for scientific equation discovery with large language models. In Forty-second International Conference on Machine Learning, 2025. URL https://openreview.net/forum?id=SyQPiZJVWY
2025
-
[24]
Core-bench: Fostering the credibility of published research through a computational reproducibility agent benchmark
\ Zachary S.\ Siegel, Sayash Kapoor, Nitya Nadgir, Benedikt Stroebl, and Arvind Narayanan. Core-bench: Fostering the credibility of published research through a computational reproducibility agent benchmark. Transactions on Machine Learning Research, 2025-January: 0 1--31, January 2025. ISSN 2835-8856. Publisher Copyright: 2025, Transactions on Machine Le...
2025
-
[25]
Scaling LLM test-time compute optimally can be more effective than scaling parameters for reasoning
Charlie Victor Snell, Jaehoon Lee, Kelvin Xu, and Aviral Kumar. Scaling LLM test-time compute optimally can be more effective than scaling parameters for reasoning. In The Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/forum?id=4FWAwZtd2n
2025
-
[26]
Xuemei Tang, Xufeng Duan, and Zhenguang Cai. Large language models for automated literature review: An evaluation of reference generation, abstract writing, and review composition. In Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng (eds.), Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing...
-
[27]
Gemma Team. Gemma 3. 2025 a . URL https://goo.gle/Gemma3Report
2025
-
[28]
Qwen Team. Qwen3 technical report, 2025 b . URL https://arxiv.org/abs/2505.09388
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
Scicode: A research coding benchmark curated by scientists
Minyang Tian, Luyu Gao, Dylan Zhang, Xinan Chen, Cunwei Fan, Xuefei Guo, Roland Haas, Pan Ji, Kittithat Krongchon, Yao Li, Shengyan Liu, Di Luo, Yutao Ma, HAO TONG, Kha Trinh, Chenyu Tian, Zihan Wang, Bohao Wu, Shengzhu Yin, Minhui Zhu, Kilian Lieret, Yanxin Lu, Genglin Liu, Yufeng Du, Tianhua Tao, Ofir Press, Jamie Callan, Eliu A Huerta, and Hao Peng. Sc...
2024
-
[30]
Asking a language model for diverse responses
Sergey Troshin, Irina Saparina, Antske Fokkens, and Vlad Niculae. Asking a language model for diverse responses. In Bryan Eikema, Ra \'u l V \'a zquez, Jonathan Berant, Marie-Catherine de Marneffe, Barbara Plank, Artem Shelmanov, Swabha Swayamdipta, J \"o rg Tiedemann, Chrysoula Zerva, and Wilker Aziz (eds.), Proceedings of the 2nd Workshop on Uncertainty...
-
[31]
Bingbing Wen, Jihan Yao, Shangbin Feng, Chenjun Xu, Yulia Tsvetkov, Bill Howe, and Lucy Lu Wang. Know your limits: A survey of abstention in large language models. Transactions of the Association for Computational Linguistics, 13: 0 529--556, 2025. doi:10.1162/tacl_a_00754. URL https://aclanthology.org/2025.tacl-1.26/
-
[32]
Tablebench: a comprehensive and complex benchmark for table question answering
Xianjie Wu, Jian Yang, Linzheng Chai, Ge Zhang, Jiaheng Liu, Xeron Du, Di Liang, Daixin Shu, Xianfu Cheng, Tianzhen Sun, Tongliang Li, Zhoujun Li, and Guanglin Niu. Tablebench: a comprehensive and complex benchmark for table question answering. In Proceedings of the Thirty-Ninth AAAI Conference on Artificial Intelligence and Thirty-Seventh Conference on I...
-
[33]
In: Che, W., Nabende, J., Shutova, E., Pilehvar, M.T
Zhiqiu Xia, Jinxuan Xu, Yuqian Zhang, and Hang Liu. A survey of uncertainty estimation methods on large language models. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar (eds.), Findings of the Association for Computational Linguistics: ACL 2025, pp.\ 21381--21396, Vienna, Austria, July 2025. Association for Computational Lin...
-
[34]
ReAct : Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. ReAct : Synergizing reasoning and acting in language models. In International Conference on Learning Representations (ICLR), 2023
2023
-
[35]
ALCUNA : Large language models meet new knowledge
Xunjian Yin, Baizhou Huang, and Xiaojun Wan. ALCUNA : Large language models meet new knowledge. In The 2023 Conference on Empirical Methods in Natural Language Processing, 2023. URL https://openreview.net/forum?id=toUPGCAMic
2023
-
[36]
@esa (Ref
\@ifxundefined[1] #1\@undefined \@firstoftwo \@secondoftwo \@ifnum[1] #1 \@firstoftwo \@secondoftwo \@ifx[1] #1 \@firstoftwo \@secondoftwo [2] @ #1 \@temptokena #2 #1 @ \@temptokena \@ifclassloaded agu2001 natbib The agu2001 class already includes natbib coding, so you should not add it explicitly Type <Return> for now, but then later remove the command n...
-
[37]
\@lbibitem[] @bibitem@first@sw\@secondoftwo \@lbibitem[#1]#2 \@extra@b@citeb \@ifundefined br@#2\@extra@b@citeb \@namedef br@#2 \@nameuse br@#2\@extra@b@citeb \@ifundefined b@#2\@extra@b@citeb @num @parse #2 @tmp #1 NAT@b@open@#2 NAT@b@shut@#2 \@ifnum @merge>\@ne @bibitem@first@sw \@firstoftwo \@ifundefined NAT@b*@#2 \@firstoftwo @num @NAT@ctr \@secondoft...
-
[38]
Hippocampus, Natalia Cerebro & Amelie P
@open @close @open @close and [1] URL: #1 \@ifundefined chapter * \@mkboth \@ifxundefined @sectionbib * \@mkboth * \@mkboth\@gobbletwo \@ifclassloaded amsart * \@ifclassloaded amsbook * \@ifxundefined @heading @heading NAT@ctr thebibliography [1] @ \@biblabel @NAT@ctr \@bibsetup #1 @NAT@ctr @ @openbib .11em \@plus.33em \@minus.07em 4000 4000 `\.\@m @bibit...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.