Recognition: unknown
Analog Optical Inference on Million-Record Mortgage Data
Pith reviewed 2026-05-10 16:10 UTC · model grok-4.3
The pith
Analog optical inference on mortgage data loses accuracy mainly to encoding and architecture, not hardware flaws.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
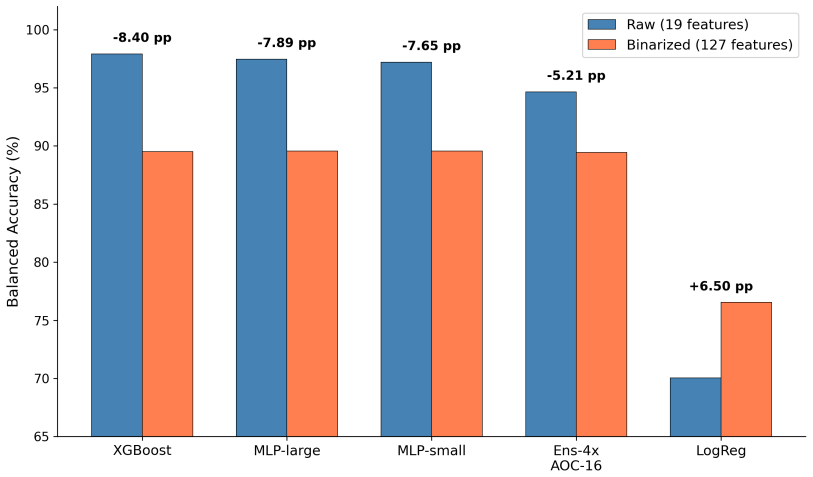
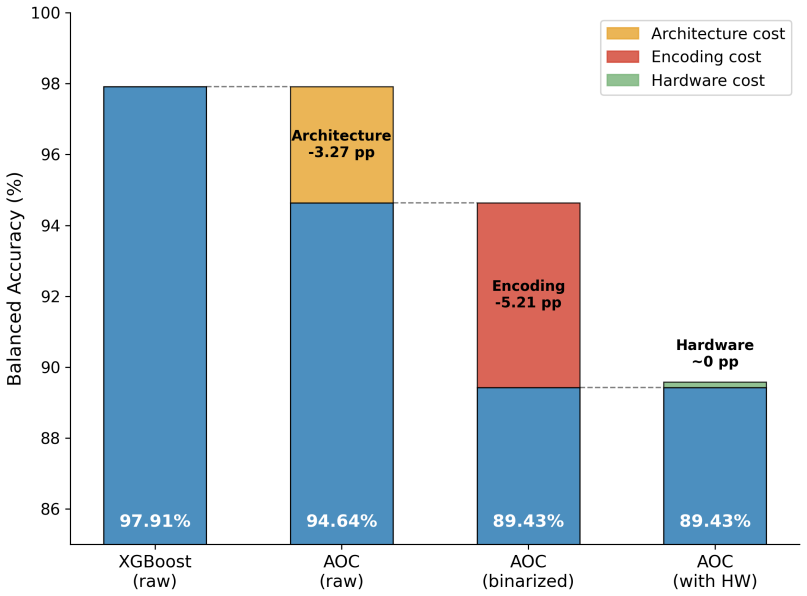
On the original 19 features, the AOC reaches 94.6% balanced accuracy with 5,126 parameters (1,024 optical), compared with 97.9% for XGBoost; the 3.3 percentage-point gap narrows by only 0.5pp when the optical core is widened from 16 to 48 channels, suggesting an architectural rather than hardware limitation. Restricting all models to a shared 127-bit binary encoding drops every model to 89.4--89.6%, with an encoding cost of 8pp for digital models and 5pp for the AOC. Seven calibrated hardware non-idealities impose no measurable penalty. The three resulting layers of limitation (encoding, architecture, hardware fidelity) locate where accuracy is lost and what to improve next.
What carries the argument
Digital twin benchmark that separates accuracy losses into encoding cost, architectural constraints, and hardware non-idealities on the analog optical computer.
If this is right
- Hardware non-idealities can be deprioritized since they impose no extra accuracy cost.
- Architectural redesign of the optical core is required because simply adding channels yields little gain.
- Improving the binary encoding step could raise performance for both optical and digital models by up to 8 points.
- Analog optical systems are ready for large-scale tabular inference tasks once encoding and architecture are addressed.
Where Pith is reading between the lines
- The same loss-separation method could be applied to other tabular datasets to test whether architectural limits are general.
- An encoding scheme designed around optical hardware constraints might shrink the 5-point penalty seen for the AOC.
- Hybrid optical-digital pipelines could combine the efficiency of analog inference with digital encoding recovery.
Load-bearing premise
The digital twin faithfully reproduces the physical analog optical hardware and the 127-bit binary encoding gives an unbiased comparison across models.
What would settle it
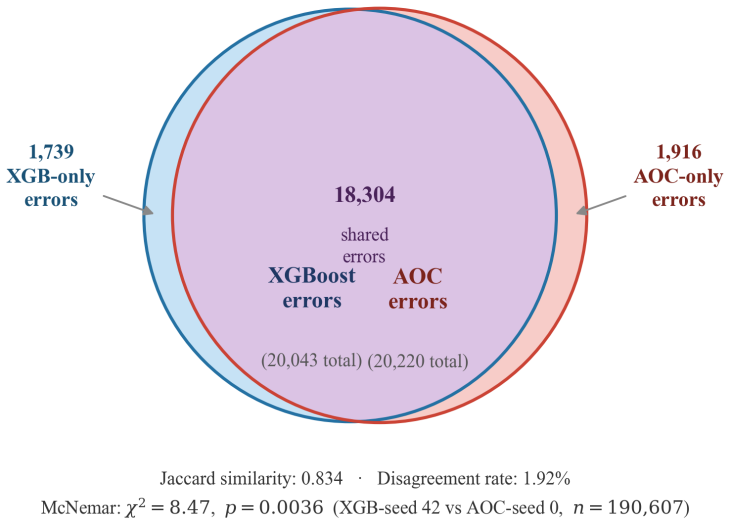
Running the actual physical analog optical hardware on the same 5.84 million HMDA records and checking whether balanced accuracy stays at 94.6 percent or drops from unmodeled physical effects.
Figures


read the original abstract
Analog optical computers promise large efficiency gains for machine learning inference, yet no demonstration has moved beyond small-scale image benchmarks. We benchmark the analog optical computer (AOC) digital twin on mortgage approval classification from 5.84 million U.S. HMDA records and separate three sources of accuracy loss. On the original 19 features, the AOC reaches 94.6% balanced accuracy with 5,126 parameters (1,024 optical), compared with 97.9% for XGBoost; the 3.3 percentage-point gap narrows by only 0.5pp when the optical core is widened from 16 to 48 channels, suggesting an architectural rather than hardware limitation. Restricting all models to a shared 127-bit binary encoding drops every model to 89.4--89.6%, with an encoding cost of 8pp for digital models and 5pp for the AOC. Seven calibrated hardware non-idealities impose no measurable penalty. The three resulting layers of limitation (encoding, architecture, hardware fidelity) locate where accuracy is lost and what to improve next.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper benchmarks an analog optical computer (AOC) digital twin on mortgage approval classification using 5.84 million HMDA records. It reports that the AOC achieves 94.6% balanced accuracy with 5,126 parameters (1,024 optical) versus 97.9% for XGBoost on the original 19 features; widening the optical core from 16 to 48 channels narrows the gap by only 0.5pp. A shared 127-bit binary encoding reduces all models to 89.4-89.6% accuracy, and seven calibrated hardware non-idealities impose no measurable penalty. The work decomposes accuracy losses into encoding, architecture, and hardware layers.
Significance. If the digital twin faithfully reproduces physical hardware behavior on this dataset and encoding, the result is significant for scaling analog optical inference beyond small image benchmarks to large tabular data and for isolating where future gains must come from (encoding and architecture rather than hardware fidelity). The explicit separation of loss sources and the parameter counts provide a concrete, falsifiable basis for co-design.
major comments (2)
- [Abstract / Results (hardware non-idealities)] Abstract and results on hardware non-idealities: the central claim that 'seven calibrated hardware non-idealities impose no measurable penalty' and that the 3.3pp gap is 'architectural rather than hardware limitation' rests entirely on the digital twin reproducing physical error accumulation (noise, crosstalk, quantization) for the 5.84M HMDA records under 127-bit encoding. No cross-validation of the twin against physical hardware measurements on this task or data distribution is described, which directly undermines the separation of loss sources.
- [Channel-width experiments] Channel-width ablation: the claim that widening from 16 to 48 channels narrows the gap by only 0.5pp (supporting architectural limit) lacks reported error bars, multiple random seeds, or statistical tests; without these, the 0.5pp difference cannot be distinguished from noise and does not robustly support the architectural-limitation conclusion.
minor comments (3)
- [Methods] The abstract and methods should explicitly state the digital-twin implementation details, calibration procedure, and any validation metrics against physical hardware even on a subset of the data.
- [Results] All accuracy figures (94.6%, 97.9%, 89.4-89.6%) should be accompanied by standard deviations or confidence intervals from repeated runs.
- [Encoding section] The 127-bit binary encoding procedure and how it is applied uniformly to XGBoost, AOC, and other baselines needs a dedicated paragraph or algorithm box for reproducibility.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed review. The comments highlight important aspects of rigor in our claims about loss decomposition. We respond point-by-point below and will revise the manuscript accordingly to strengthen the presentation while remaining faithful to the experiments performed.
read point-by-point responses
-
Referee: Abstract and results on hardware non-idealities: the central claim that 'seven calibrated hardware non-idealities impose no measurable penalty' and that the 3.3pp gap is 'architectural rather than hardware limitation' rests entirely on the digital twin reproducing physical error accumulation (noise, crosstalk, quantization) for the 5.84M HMDA records under 127-bit encoding. No cross-validation of the twin against physical hardware measurements on this task or data distribution is described, which directly undermines the separation of loss sources.
Authors: We acknowledge that the manuscript does not describe a direct cross-validation of the digital twin on the HMDA dataset itself. The twin was calibrated using physical hardware measurements from prior smaller-scale experiments, with non-idealities modeled as additive, data-independent effects (e.g., Gaussian noise, fixed crosstalk matrices, quantization). These properties are hardware characteristics rather than task-specific, supporting transfer to the tabular mortgage data. However, we agree that explicit discussion of this assumption is needed. In the revised manuscript we will add a dedicated paragraph in the Methods section detailing the calibration sources, citing the original hardware measurements, and stating the transferability assumption along with its limitations. This will clarify the basis for attributing the gap to architecture rather than hardware. revision: partial
-
Referee: Channel-width ablation: the claim that widening from 16 to 48 channels narrows the gap by only 0.5pp (supporting architectural limit) lacks reported error bars, multiple random seeds, or statistical tests; without these, the 0.5pp difference cannot be distinguished from noise and does not robustly support the architectural-limitation conclusion.
Authors: We agree that the ablation requires statistical support to be conclusive. The reported 0.5pp narrowing was obtained from single-run experiments with a fixed initialization. In the revised manuscript we will repeat the 16- and 48-channel experiments over 10 independent random seeds, report mean balanced accuracy with standard deviation error bars, and include a paired t-test (or equivalent) to assess whether the observed difference is statistically significant. These additions will either confirm the architectural-limitation interpretation or qualify it appropriately. revision: yes
Circularity Check
No circularity; results from direct empirical benchmarking on public data
full rationale
The paper presents experimental accuracy measurements obtained by running the AOC digital twin and XGBoost baselines on the fixed 5.84 M HMDA records under controlled variations (19 features vs. 127-bit encoding; with vs. without seven non-idealities). The separation into encoding, architecture, and hardware layers is performed by comparing these distinct experimental configurations rather than by any equation that defines one quantity in terms of another. No self-citation, uniqueness theorem, or ansatz is invoked to justify the central claims. All reported numbers are direct outputs of the benchmarking procedure on externally available data and are therefore independent of the paper's internal definitions.
Axiom & Free-Parameter Ledger
free parameters (1)
- optical channel count
axioms (1)
- domain assumption The digital twin of the analog optical computer accurately captures real hardware behavior including non-idealities.
Reference graph
Works this paper leans on
-
[1]
Kalinin et al., Analog optical computer for AI inference and combinatorial optimization, Nature 645, 354--361 (2025)
K.P. Kalinin et al., Analog optical computer for AI inference and combinatorial optimization, Nature 645, 354--361 (2025)
2025
-
[2]
Shen et al., Deep learning with coherent nanophotonic circuits, Nature Photonics 11, 441--446 (2017)
Y. Shen et al., Deep learning with coherent nanophotonic circuits, Nature Photonics 11, 441--446 (2017)
2017
-
[3]
Xu et al., 11 TOPS photonic convolutional accelerator for optical neural networks, Nature 589, 44--51 (2021)
X. Xu et al., 11 TOPS photonic convolutional accelerator for optical neural networks, Nature 589, 44--51 (2021)
2021
-
[4]
Wetzstein et al., Inference in artificial intelligence with deep optics and photonics, Nature 588, 39--47 (2020)
G. Wetzstein et al., Inference in artificial intelligence with deep optics and photonics, Nature 588, 39--47 (2020)
2020
-
[5]
McMahon, The physics of optical computing, Nature Reviews Physics 5, 717--734 (2023)
P.L. McMahon, The physics of optical computing, Nature Reviews Physics 5, 717--734 (2023)
2023
-
[6]
Stroev and N.G
N. Stroev and N.G. Berloff, Analog photonics computing for information processing, inference, and optimization, Advanced Quantum Technologies 6, 2300055 (2023)
2023
-
[7]
Grinsztajn, E
L. Grinsztajn, E. Oyallon, and G. Varoquaux, Why do tree-based models still outperform deep learning on typical tabular data? Advances in Neural Information Processing Systems 35, 507--520 (2022)
2022
-
[8]
Shwartz-Ziv and A
R. Shwartz-Ziv and A. Armon, Tabular data: Deep learning is not all you need, Information Fusion 81, 84--90 (2022)
2022
-
[9]
Gorishniy et al., Revisiting deep learning models for tabular data, Advances in Neural Information Processing Systems 34, 18932--18943 (2021)
Y. Gorishniy et al., Revisiting deep learning models for tabular data, Advances in Neural Information Processing Systems 34, 18932--18943 (2021)
2021
-
[10]
Consumer Financial Protection Bureau, Home M ortgage D isclosure A ct ( HMDA ) data, https://ffiec.cfpb.gov/data-publication/ (2024)
2024
-
[11]
Chen and C
T. Chen and C. Guestrin, XGBoost : A scalable tree boosting system, Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 785--794 (2016)
2016
-
[12]
Bai, J.Z
S. Bai, J.Z. Kolter, and V. Koltun, Deep equilibrium models, Advances in Neural Information Processing Systems 32 (2019)
2019
-
[13]
Borisov et al., Deep neural networks and tabular data: A survey, IEEE Trans.\ Neural Networks and Learning Systems 35(6), 7499--7519 (2024)
V. Borisov et al., Deep neural networks and tabular data: A survey, IEEE Trans.\ Neural Networks and Learning Systems 35(6), 7499--7519 (2024)
2024
-
[14]
McNemar, Note on the sampling error of the difference between correlated proportions or percentages, Psychometrika 12, 153--157 (1947)
Q. McNemar, Note on the sampling error of the difference between correlated proportions or percentages, Psychometrika 12, 153--157 (1947)
1947
-
[15]
Adam: A Method for Stochastic Optimization
D.P. Kingma and J. Ba, Adam: A method for stochastic optimization, arXiv:1412.6980, ICLR (2015)
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[16]
Gorishniy, A
Y. Gorishniy, A. Kotelnikov, and A. Babenko, TabM : Advancing tabular deep learning with parameter-efficient ensembling, ICLR (2025)
2025
-
[17]
Erickson et al., TabArena : A living benchmark for machine learning on tabular data, NeurIPS Datasets and Benchmarks (2025)
N. Erickson et al., TabArena : A living benchmark for machine learning on tabular data, NeurIPS Datasets and Benchmarks (2025)
2025
-
[18]
TabPFN-2.5: Advancing the State of the Art in Tabular Foundation Models
L. Grinsztajn et al., TabPFN-2.5 : Advancing the state of the art in tabular foundation models, arXiv:2511.08667 (2025)
work page internal anchor Pith review arXiv 2025
-
[19]
Rubachev, N
I. Rubachev, N. Kartashev, Y. Gorishniy, and A. Babenko, TabReD : Analyzing pitfalls and filling the gaps in tabular deep learning benchmarks, ICLR (2025)
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.