Recognition: unknown
English is Not All You Need: Systematically Exploring the Role of Multilinguality in LLM Post-Training
Pith reviewed 2026-05-10 15:02 UTC · model grok-4.3
The pith
Adding languages during post-training improves LLM performance on English and other languages alike.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
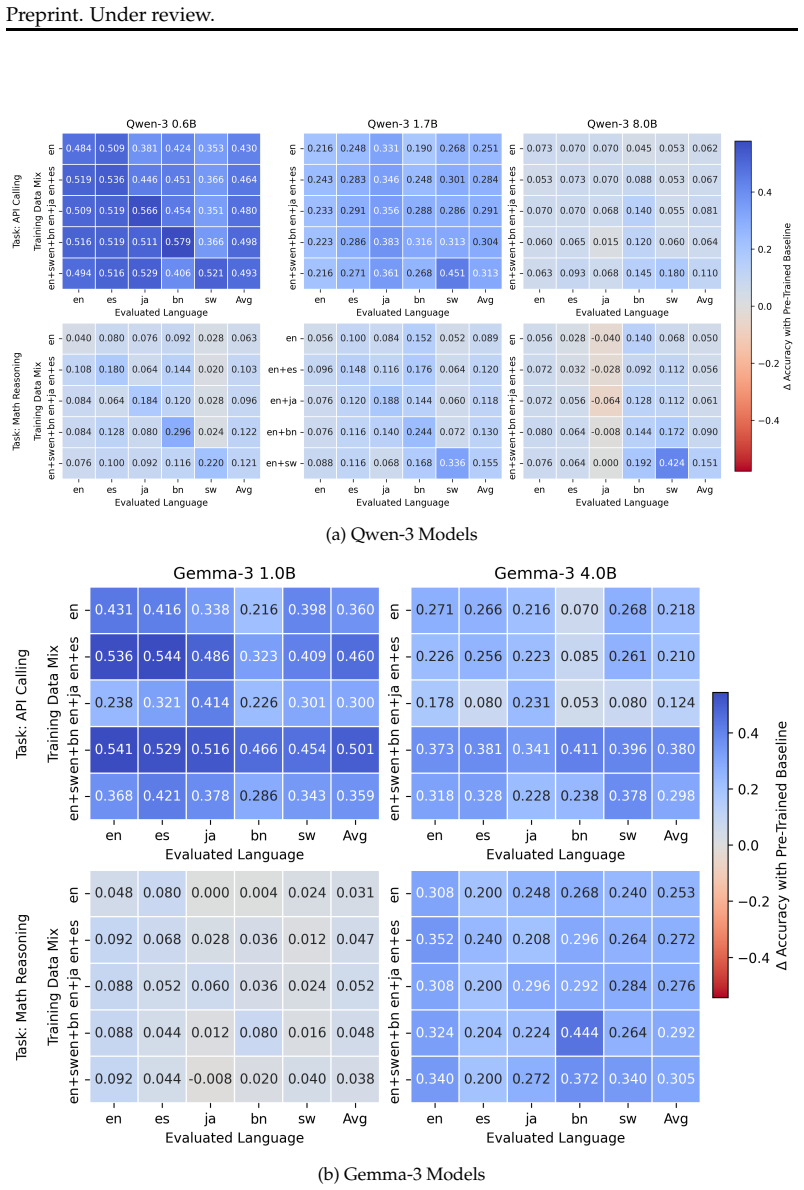
Through systematic experiments, the authors show that increasing language coverage during post-training is largely beneficial across tasks and model scales, with low-resource languages benefiting the most and high-resource languages plateauing rather than degrading. Even minimal multilinguality helps: incorporating a single non-English language improves both English performance and cross-lingual generalization, making English-only post-training largely suboptimal. Moreover, at sufficient language diversity, zero-shot cross-lingual transfer can match or exceed the effects of direct language inclusion in a low-diversity setting, although gains remain limited for typologically distant, low-ress
What carries the argument
The controlled variation of language coverage in parallel translated multilingual data mixtures for supervised fine-tuning on mathematical reasoning and API calling tasks.
If this is right
- Low-resource languages receive the largest performance gains as more languages enter the post-training mix.
- High-resource languages maintain stable performance rather than declining with added language diversity.
- English task accuracy rises when even one non-English language is included in the data.
- Zero-shot cross-lingual transfer becomes competitive with direct training once overall language diversity is high.
- The benefits appear consistently across model sizes up to 8 billion parameters.
Where Pith is reading between the lines
- Post-training pipelines could default to multilingual mixtures to raise overall capability without separate English-only runs.
- Typologically distant languages may still need targeted methods beyond simple data inclusion to reach full performance.
- Similar language-coverage effects might appear in other post-training stages such as preference tuning if tested the same way.
Load-bearing premise
The translated data mixtures preserve task meaning and difficulty across languages without introducing translation artifacts or quality loss.
What would settle it
Repeating the experiments on naturally occurring non-translated multilingual data and observing that performance stops improving or declines as language coverage increases.
Figures








read the original abstract
Despite the widespread multilingual deployment of large language models, post-training pipelines remain predominantly English-centric, contributing to performance disparities across languages. We present a systematic, controlled study of the interplay between training language coverage, model scale, and task domain, based on 220 supervised fine-tuning runs on parallel translated multilingual data mixtures spanning mathematical reasoning and API calling tasks, with models up to 8B parameters. We find that increasing language coverage during post-training is largely beneficial across tasks and model scales, with low-resource languages benefiting the most and high-resource languages plateauing rather than degrading. Even minimal multilinguality helps: incorporating a single non-English language improves both English performance and cross-lingual generalization, making English-only post-training largely suboptimal. Moreover, at sufficient language diversity, zero-shot cross-lingual transfer can match or exceed the effects of direct language inclusion in a low-diversity setting, although gains remain limited for typologically distant, low-resource languages.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper reports a controlled empirical study of 220 supervised fine-tuning runs on models up to 8B parameters, using parallel translated mixtures of mathematical reasoning and API calling tasks. It claims that increasing language coverage during post-training is largely beneficial, with low-resource languages gaining the most and high-resource languages plateauing; that even a single non-English language improves both English performance and cross-lingual generalization; and that, at sufficient diversity, zero-shot transfer can match direct inclusion.
Significance. If the translation fidelity holds, the scale of the controlled experiments (220 runs across scales and tasks) and the finding that minimal multilinguality improves English performance would provide actionable guidance against English-only post-training pipelines. The systematic variation of language coverage, model size, and task domain strengthens the potential contribution to multilingual LLM training practices.
major comments (1)
- [Experimental setup / data mixtures] The description of the parallel translated multilingual data mixtures (abstract and experimental setup): the headline claims rest on translated versions of the original English problems for both mathematical reasoning and API calling. No back-translation accuracy, human task-fidelity checks, or controls isolating translation artifacts from genuine language-coverage effects are reported. Because translation errors in numbers, operators, or API descriptions would directly alter task difficulty or functional equivalence, gains attributed to multilinguality could instead reflect increased token volume, regularization from noise, or data-quality artifacts; this assumption is load-bearing for the central empirical result.
minor comments (2)
- [Abstract / Results] The abstract states that the study comprises 220 controlled runs but provides no visible details on statistical significance testing, variance across seeds, or exact data-mixture token counts per language; adding these would strengthen the reported improvements.
- [Results] The paper would benefit from an explicit error analysis or qualitative examples showing how performance changes with added languages, particularly for the typologically distant low-resource languages where gains remain limited.
Simulated Author's Rebuttal
We thank the referee for the careful reading and for identifying a key assumption in our experimental design. We address the concern regarding translation fidelity below and outline concrete revisions.
read point-by-point responses
-
Referee: [Experimental setup / data mixtures] The description of the parallel translated multilingual data mixtures (abstract and experimental setup): the headline claims rest on translated versions of the original English problems for both mathematical reasoning and API calling. No back-translation accuracy, human task-fidelity checks, or controls isolating translation artifacts from genuine language-coverage effects are reported. Because translation errors in numbers, operators, or API descriptions would directly alter task difficulty or functional equivalence, gains attributed to multilinguality could instead reflect increased token volume, regularization from noise, or data-quality artifacts; this assumption is load-bearing for the central empirical result.
Authors: We agree that translation quality is a load-bearing assumption and that the absence of explicit fidelity checks leaves open the possibility of confounding artifacts. In the original experiments the data were produced via a high-quality neural machine translation pipeline applied to the English sources, but we did not quantify fidelity or run controls. In the revised manuscript we will add a dedicated subsection that reports: (i) back-translation BLEU scores on held-out samples for both the mathematical-reasoning and API-calling mixtures, (ii) human evaluation of task equivalence on a stratified sample of 200 instances (100 per task) performed by native speakers, and (iii) a control condition in which the English-only training set is augmented with synthetic noise and extra tokens to match the volume and approximate noise characteristics of the multilingual mixtures. These additions will allow readers to assess whether the reported gains are driven by language coverage rather than data artifacts. revision: yes
Circularity Check
No circularity: purely empirical measurements from controlled SFT runs
full rationale
The paper presents results exclusively from 220 supervised fine-tuning experiments on parallel translated data mixtures for math reasoning and API calling tasks. No derivation chain, equations, fitted parameters renamed as predictions, or self-citation load-bearing uniqueness theorems appear in the abstract or described methodology. All headline claims (benefits of language coverage, minimal multilinguality effects, zero-shot transfer) are stated as direct experimental outcomes rather than reductions to prior inputs or self-referential definitions. The study is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Parallel translated data mixtures accurately preserve task semantics and difficulty across languages.
Reference graph
Works this paper leans on
-
[1]
When is multilinguality a curse? language modeling for 250 high-and low-resource languages
Tyler A Chang, Catherine Arnett, Zhuowen Tu, and Ben Bergen. When is multilinguality a curse? language modeling for 250 high-and low-resource languages. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pp. 4074–4096,
2024
-
[2]
Monolingual or multilingual instruction tuning: Which makes a better alpaca
Pinzhen Chen, Shaoxiong Ji, Nikolay Bogoychev, Andrey Kutuzov, Barry Haddow, and Kenneth Heafield. Monolingual or multilingual instruction tuning: Which makes a better alpaca. InFindings of the Association for Computational Linguistics: EACL 2024, pp. 1347–1356,
2024
-
[3]
Julen Etxaniz, Gorka Azkune, Aitor Soroa, Oier Lopez de Lacalle, and Mikel Artetxe. Do multilingual language models think better in english? InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language T echnologies (Volume 2: Short Papers), pp. 550–564,
2024
-
[4]
Benchmax: A comprehensive multilingual evaluation suite for large language models
Xu Huang, Wenhao Zhu, Hanxu Hu, Conghui He, Lei Li, Shujian Huang, and Fei Yuan. Benchmax: A comprehensive multilingual evaluation suite for large language models. arXiv preprint arXiv:2502.07346,
-
[5]
Aishwarya Kamath, Johan Ferret, Shreya Pathak, Nino Vieillard, Ramona Merhej, Sarah Perrin, Tatiana Matejovicova, Alexandre Ramé, Morgane Rivière, Louis Rouillard, et al. Gemma 3 technical report.arXiv preprint arXiv:2503.19786, 4,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Turning english-centric llms into poly- glots: How much multilinguality is needed? InFindings of the Association for Computational Linguistics: EMNLP 2024, pp
Tannon Kew, Florian Schottmann, and Rico Sennrich. Turning english-centric llms into poly- glots: How much multilinguality is needed? InFindings of the Association for Computational Linguistics: EMNLP 2024, pp. 13097–13124,
2024
-
[7]
Evaluating the diversity, equity, and inclusion of nlp technology: A case study for indian languages
Simran Khanuja, Sebastian Ruder, and Partha Talukdar. Evaluating the diversity, equity, and inclusion of nlp technology: A case study for indian languages. InFindings of the Association for Computational Linguistics: EACL 2023, pp. 1763–1777,
2023
-
[8]
Massive-agents: A benchmark for multilingual function-calling in 52 languages
Mayank Kulkarni, Vittorio Mazzia, Judith Gaspers, Christopher Hench, Jack FitzGerald, and AGI Amazon. Massive-agents: A benchmark for multilingual function-calling in 52 languages. InFindings of the Association for Computational Linguistics: EMNLP 2025, pp. 20193–20215,
2025
-
[9]
Huiyuan Lai and Malvina Nissim. mcot: Multilingual instruction tuning for reasoning consistency in language models.arXiv preprint arXiv:2406.02301,
-
[10]
arXiv preprint arXiv:2304.08244 , year=
Minghao Li, Yingxiu Zhao, Bowen Yu, Feifan Song, Hangyu Li, Haiyang Yu, Zhoujun Li, Fei Huang, and Yongbin Li. Api-bank: A comprehensive benchmark for tool-augmented llms.arXiv preprint arXiv:2304.08244,
-
[11]
Niklas Muennighoff, Alexander M
Shayne Longpre, Sneha Kudugunta, Niklas Muennighoff, I Hsu, Isaac Caswell, Alex Pent- land, Sercan Arik, Chen-Yu Lee, Sayna Ebrahimi, et al. Atlas: Adaptive transfer scaling laws for multilingual pretraining, finetuning, and decoding the curse of multilinguality. arXiv preprint arXiv:2510.22037,
-
[12]
Do multilingual llms think in english?arXiv preprint arXiv:2502.15603,
Lisa Schut, Yarin Gal, and Sebastian Farquhar. Do multilingual llms think in english?arXiv preprint arXiv:2502.15603,
-
[13]
10 Preprint. Under review. Uri Shaham, Jonathan Herzig, Roee Aharoni, Idan Szpektor, Reut Tsarfaty, and Matan Eyal. Multilingual instruction tuning with just a pinch of multilinguality.arXiv preprint arXiv:2401.01854,
-
[14]
arXiv preprint arXiv:2210.03057 , year=
Freda Shi, Mirac Suzgun, Markus Freitag, Xuezhi Wang, Suraj Srivats, Soroush Vosoughi, Hyung Won Chung, Yi Tay, Sebastian Ruder, Denny Zhou, et al. Language models are multilingual chain-of-thought reasoners.arXiv preprint arXiv:2210.03057,
-
[15]
Luisa Shimabucoro, Ahmet Ustun, Marzieh Fadaee, and Sebastian Ruder. A post-trainer’s guide to multilingual training data: Uncovering cross-lingual transfer dynamics.arXiv preprint arXiv:2504.16677,
-
[16]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388,
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.