Recognition: unknown
Can Cross-Layer Transcoders Replace Vision Transformer Activations? An Interpretable Perspective on Vision
Pith reviewed 2026-05-10 15:37 UTC · model grok-4.3
The pith
Cross-layer transcoders reconstruct Vision Transformer post-MLP activations from preceding layers to produce a linear, layer-resolved decomposition of the final representation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Cross-Layer Transcoders (CLTs) are encoder-decoder networks trained to reconstruct each post-MLP activation in a ViT from learned sparse embeddings of all preceding layers. When applied to CLIP ViT-B/32 and ViT-B/16 on CIFAR-100, COCO, and ImageNet-100, the resulting linear decomposition achieves high reconstruction fidelity while preserving or improving zero-shot classification accuracy. The associated cross-layer contribution scores identify a small subset of dominant layer-wise terms; retaining only those terms largely preserves performance, whereas their removal causes clear degradation.
What carries the argument
The Cross-Layer Transcoder, an encoder-decoder model that maps preceding-layer sparse embeddings to a reconstruction of a target post-MLP activation, thereby converting the final ViT representation into an explicit sum of layer-specific vectors for attribution.
If this is right
- CLTs can act as drop-in, sparse proxies for ViT MLP blocks without harming downstream zero-shot performance.
- The linear decomposition supplies per-layer attribution scores that correctly predict the performance impact of keeping or discarding individual terms.
- Final ViT representations concentrate their useful signal in a minority of dominant layer contributions rather than distributing it uniformly across depth.
- Selective retention of only the dominant terms in the decomposition recovers most of the original classification accuracy.
- Non-dominant layer terms can be ablated with measurable loss, confirming they carry limited unique information for the final output.
Where Pith is reading between the lines
- The same CLT construction could be applied to language-model transformers to expose which layers dominate next-token prediction.
- Dominant-layer concentration suggests a possible route to layer-pruning or early-exit strategies that keep accuracy while lowering compute.
- Faithful per-layer scores might support targeted interventions such as editing or regularizing specific depths for robustness or fairness.
- If the scores generalize, they could serve as a diagnostic for whether a ViT has learned redundant or shallow representations across its depth.
Load-bearing premise
High-fidelity reconstruction of post-MLP activations from preceding-layer sparse embeddings is enough to guarantee that the derived contribution scores faithfully reflect the original model's layer-wise computation and decision process.
What would settle it
An experiment that shows the CLT contribution scores assign high importance to layers whose actual removal (or zeroing of their term) leaves zero-shot accuracy essentially unchanged, or assigns low importance to layers whose removal sharply drops accuracy.
Figures













read the original abstract
Understanding the internal activations of Vision Transformers (ViTs) is critical for building interpretable and trustworthy models. While Sparse Autoencoders (SAEs) have been used to extract human-interpretable features, they operate on individual layers and fail to capture the cross-layer computational structure of Transformers, as well as the relative significance of each layer in forming the last-layer representation. Alternatively, we introduce the adoption of Cross-Layer Transcoders (CLTs) as reliable, sparse, and depth-aware proxy models for MLP blocks in ViTs. CLTs use an encoder-decoder scheme to reconstruct each post-MLP activation from learned sparse embeddings of preceding layers, yielding a linear decomposition that transforms the final representation of ViTs from an opaque embedding into an additive, layer-resolved construction that enables faithful attribution and process-level interpretability. We train CLTs on CLIP ViT-B/32 and ViT-B/16 across CIFAR-100, COCO, and ImageNet-100. We show that CLTs achieve high reconstruction fidelity with post-MLP activations while preserving and even improving, in some cases, CLIP zero-shot classification accuracy. In terms of interpretability, we show that the cross-layer contribution scores provide faithful attribution, revealing that the final representation is concentrated in a smaller set of dominant layer-wise terms whose removal degrades performance and whose retention largely preserves it. These results showcase the significance of adopting CLTs as an alternative interpretable proxy of ViTs in the vision domain.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Cross-Layer Transcoders (CLTs) as sparse, depth-aware proxy models for MLP blocks in Vision Transformers. CLTs reconstruct post-MLP activations from learned sparse embeddings of preceding layers via an encoder-decoder scheme, producing a linear decomposition of the final representation into additive layer-resolved terms. This enables attribution via cross-layer contribution scores. Experiments train CLTs on CLIP ViT-B/32 and ViT-B/16 using CIFAR-100, COCO, and ImageNet-100, reporting high reconstruction fidelity, preservation or improvement of zero-shot classification accuracy, and ablation results indicating that the final representation concentrates in a smaller set of dominant layer-wise terms.
Significance. If the contribution scores are validated as faithful to the ViT's internal computations, the approach could provide a useful tool for cross-layer mechanistic interpretability in vision transformers, extending beyond per-layer SAEs by capturing relative layer significance in forming the final embedding. The multi-dataset training and downstream accuracy preservation are strengths that would support practical adoption as an interpretable proxy.
major comments (1)
- [Abstract] Abstract: The claim that 'the cross-layer contribution scores provide faithful attribution' is load-bearing for the interpretability contribution, yet the described procedure trains the CLT as an independent sparse proxy rather than deriving it from ViT weights or gradients. High reconstruction fidelity and ablation results (high-scoring terms degrade performance when removed) do not rule out an alternative factorization that does not match the actual additive contributions inside the transformer blocks. This leaves the faithfulness of the attribution open to question.
minor comments (2)
- The abstract references high fidelity and accuracy preservation but supplies no specific quantitative metrics, error bars, or ablation statistics; including these would allow readers to evaluate the strength of the empirical claims.
- Training details such as the exact loss function, sparsity penalty, hyperparameter choices, and layer selection criteria are not described in the abstract; adding them would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for identifying the need to strengthen the justification for our interpretability claims. We address the major comment point by point below.
read point-by-point responses
-
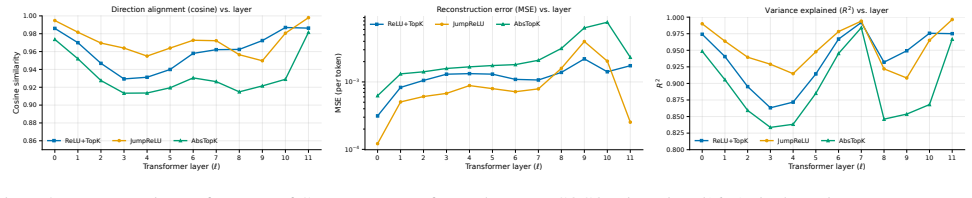
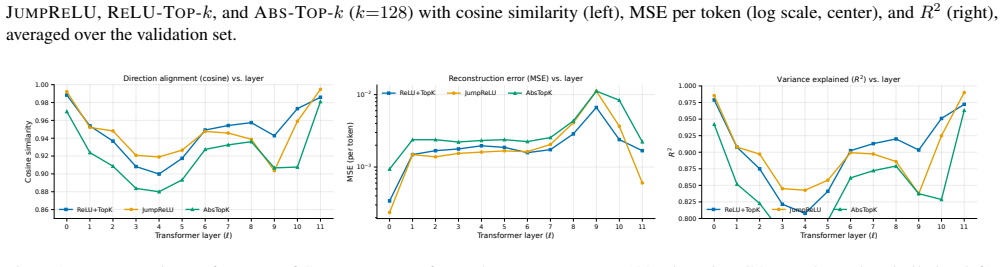
Referee: [Abstract] The claim that 'the cross-layer contribution scores provide faithful attribution' is load-bearing for the interpretability contribution, yet the described procedure trains the CLT as an independent sparse proxy rather than deriving it from ViT weights or gradients. High reconstruction fidelity and ablation results (high-scoring terms degrade performance when removed) do not rule out an alternative factorization that does not match the actual additive contributions inside the transformer blocks. This leaves the faithfulness of the attribution open to question.
Authors: We agree that training CLTs as independent proxies (rather than extracting coefficients directly from ViT weights or gradients) means the resulting decomposition is not a direct mechanistic trace of the original transformer blocks. The high reconstruction fidelity demonstrates that the CLT accurately approximates the post-MLP activations, and the linear encoder-decoder structure then yields an additive decomposition of the final representation into layer-resolved terms. The ablation experiments show that high-scoring terms are empirically important: their removal degrades zero-shot accuracy while low-scoring terms can be dropped with little effect. These results establish that the scores provide a faithful attribution with respect to the reconstructed representation, even if they do not necessarily recover the precise internal additive contributions of the original ViT. We will revise the abstract, introduction, and discussion to explicitly qualify the scope of “faithful attribution” as applying to the CLT proxy model and to note the distinction from gradient- or weight-based attributions. No new experiments are required for this clarification. revision: partial
Circularity Check
CLT training and attribution are empirical; no derivation reduces to self-defined inputs
full rationale
The paper describes an empirical training procedure for Cross-Layer Transcoders that reconstruct post-MLP activations from preceding-layer sparse codes, followed by ablation-based validation of contribution scores on downstream CLIP accuracy. No equations or claims are presented that define the linear decomposition or contribution scores in terms of themselves or via a self-citation chain that would force the result. The central interpretability argument rests on observed reconstruction fidelity and ablation effects measured against external benchmarks (zero-shot classification), which are independent of the fitted parameters. This is a standard non-circular empirical proxy construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Sparse encoder-decoder models trained on preceding layers can faithfully reconstruct post-MLP activations in ViTs
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023. 1
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Circuit trac- ing: Revealing computational graphs in language models
Emmanuel Ameisen, Jack Lindsey, Adam Pearce, Wes Gurnee, Nicholas L Turner, Brian Chen, Craig Citro, David Abrahams, Shan Carter, Basil Hosmer, et al. Circuit trac- ing: Revealing computational graphs in language models. Transformer Circuits Thread, 6:16318–16352, 2025. 1, 3, 4
2025
-
[3]
Network dissection: Quantifying interpretability of deep visual representations
David Bau, Bolei Zhou, Aditya Khosla, Aude Oliva, and Anto- nio Torralba. Network dissection: Quantifying interpretability of deep visual representations. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 6541–6549, 2017. 3
2017
-
[4]
Interpreting clip with sparse linear concept embeddings (splice).Advances in Neural Information Processing Systems, 37:84298–84328, 2024
Usha Bhalla, Alex Oesterling, Suraj Srinivas, Flavio Calmon, and Himabindu Lakkaraju. Interpreting clip with sparse linear concept embeddings (splice).Advances in Neural Information Processing Systems, 37:84298–84328, 2024. 3
2024
-
[5]
Towards monose- manticity: Decomposing language models with dictionary learning.Transformer Circuits Thread, 2(5):6, 2023
Trenton Bricken, Adly Templeton, Joshua Batson, Brian Chen, Adam Jermyn, Tom Conerly, Nick Turner, Cem Anil, Carson Denison, Amanda Askell, et al. Towards monose- manticity: Decomposing language models with dictionary learning.Transformer Circuits Thread, 2(5):6, 2023. 1, 3
2023
-
[6]
Gerasimos Chatzoudis, Zhuowei Li, Gemma E Moran, Hao Wang, and Dimitris N Metaxas. Visual sparse steering: Im- proving zero-shot image classification with sparsity guided steering vectors.arXiv preprint arXiv:2506.01247, 2025. 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Towards auto- mated circuit discovery for mechanistic interpretability.Ad- vances in Neural Information Processing Systems, 36:16318– 16352, 2023
Arthur Conmy, Augustine Mavor-Parker, Aengus Lynch, Ste- fan Heimersheim, and Adri`a Garriga-Alonso. Towards auto- mated circuit discovery for mechanistic interpretability.Ad- vances in Neural Information Processing Systems, 36:16318– 16352, 2023. 3
2023
-
[8]
Sparse Autoencoders Find Highly Interpretable Features in Language Models
Hoagy Cunningham, Aidan Ewart, Logan Riggs, Robert Huben, and Lee Sharkey. Sparse autoencoders find highly interpretable features in language models.arXiv preprint arXiv:2309.08600, 2023. 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[9]
The faiss library
Matthijs Douze, Alexandr Guzhva, Chengqi Deng, Jeff John- son, Gergely Szilvasy, Pierre-Emmanuel Mazar ´e, Maria Lomeli, Lucas Hosseini, and Herv´e J´egou. The faiss library. IEEE Transactions on Big Data, 2025. 1
2025
-
[10]
Transcoders find interpretable llm feature circuits.Advances in Neural Information Processing Systems, 37:24375–24410,
Jacob Dunefsky, Philippe Chlenski, and Neel Nanda. Transcoders find interpretable llm feature circuits.Advances in Neural Information Processing Systems, 37:24375–24410,
-
[11]
A mathematical framework for transformer circuits.Transformer Circuits Thread, 1(1):12, 2021
Nelson Elhage, Neel Nanda, Catherine Olsson, Tom Henighan, Nicholas Joseph, Ben Mann, Amanda Askell, Yun- tao Bai, Anna Chen, Tom Conerly, et al. A mathematical framework for transformer circuits.Transformer Circuits Thread, 1(1):12, 2021. 3
2021
-
[12]
Nelson Elhage, Tristan Hume, Catherine Olsson, Nicholas Schiefer, Tom Henighan, Shauna Kravec, Zac Hatfield-Dodds, Robert Lasenby, Dawn Drain, Carol Chen, et al. Toy models of superposition.arXiv preprint arXiv:2209.10652, 2022. 3
work page internal anchor Pith review arXiv 2022
-
[13]
Thomas Fel, Ekdeep Singh Lubana, Jacob S Prince, Matthew Kowal, Victor Boutin, Isabel Papadimitriou, Binxu Wang, Martin Wattenberg, Demba Ba, and Talia Konkle. Archety- pal sae: Adaptive and stable dictionary learning for con- cept extraction in large vision models.arXiv preprint arXiv:2502.12892, 2025. 3
-
[14]
Scaling and evaluating sparse autoencoders
Leo Gao, Tom Dupr´e la Tour, Henk Tillman, Gabriel Goh, Rajan Troll, Alec Radford, Ilya Sutskever, Jan Leike, and Jeffrey Wu. Scaling and evaluating sparse autoencoders.arXiv preprint arXiv:2406.04093, 2024. 3
work page internal anchor Pith review arXiv 2024
-
[15]
Circuit-tracer: A new library for finding feature circuits
Michael Hanna, Mateusz Piotrowski, Jack Lindsey, and Em- manuel Ameisen. Circuit-tracer: A new library for finding feature circuits. InProceedings of the 8th BlackboxNLP Work- shop: Analyzing and Interpreting Neural Networks for NLP, pages 239–249, 2025. 3
2025
-
[16]
Billion-scale similarity search with gpus.IEEE transactions on big data, 7 (3):535–547, 2019
Jeff Johnson, Matthijs Douze, and Herv´e J´egou. Billion-scale similarity search with gpus.IEEE transactions on big data, 7 (3):535–547, 2019. 1
2019
-
[17]
Steering clip’s vision transformer with sparse autoencoders
Sonia Joseph, Praneet Suresh, Ethan Goldfarb, Lorenz Hufe, Yossi Gandelsman, Robert Graham, Danilo Bzdok, Wojciech Samek, and Blake Aaron Richards. Steering clip’s vision transformer with sparse autoencoders. InMechanistic Inter- pretability for Vision at CVPR 2025 (Non-proceedings Track),
2025
-
[18]
Segment any- thing
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer White- head, Alexander C Berg, Wan-Yen Lo, et al. Segment any- thing. InProceedings of the IEEE/CVF international confer- ence on computer vision, pages 4015–4026, 2023. 1
2023
-
[19]
Hyesu Lim, Jinho Choi, Jaegul Choo, and Steffen Schneider. Sparse autoencoders reveal selective remapping of visual concepts during adaptation.arXiv preprint arXiv:2412.05276,
-
[20]
Sparse cross- coders for cross-layer features and model diffing.Transformer Circuits Thread, pages 3982–3992, 2024
Jack Lindsey, Adly Templeton, Jonathan Marcus, Thomas Conerly, Joshua Batson, and Christopher Olah. Sparse cross- coders for cross-layer features and model diffing.Transformer Circuits Thread, pages 3982–3992, 2024. 3
2024
-
[21]
Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023. 1
2023
-
[22]
Sparse Feature Circuits: Discovering and Editing Interpretable Causal Graphs in Language Models
Samuel Marks, Can Rager, Eric J Michaud, Yonatan Belinkov, David Bau, and Aaron Mueller. Sparse feature circuits: Dis- covering and editing interpretable causal graphs in language models.arXiv preprint arXiv:2403.19647, 2024. 3
work page internal anchor Pith review arXiv 2024
-
[23]
Robustly identifying concepts introduced during chat fine-tuning using crosscoders
Julian Minder, Cl ´ement Dumas, Bilal Chughtai, and Neel Nanda. Robustly identifying concepts introduced during chat fine-tuning using crosscoders. InSparsity in LLMs (SLLM): Deep Dive into Mixture of Experts, Quantization, Hardware, and Inference. 3
-
[24]
Julian Minder, Cl´ement Dumas, Caden Juang, Bilal Chugtai, and Neel Nanda. Overcoming sparsity artifacts in crosscoders to interpret chat-tuning.arXiv preprint arXiv:2504.02922,
-
[25]
Tuomas Oikarinen and Tsui-Wei Weng. Clip-dissect: Auto- matic description of neuron representations in deep vision networks.arXiv preprint arXiv:2204.10965, 2022. 3
-
[26]
Feature visualization.Distill, 2(11):e7, 2017
Chris Olah, Alexander Mordvintsev, and Ludwig Schubert. Feature visualization.Distill, 2(11):e7, 2017. 3
2017
-
[27]
Zoom in: An introduction to circuits.Distill, 5(3):e00024–001, 2020
Chris Olah, Nick Cammarata, Ludwig Schubert, Gabriel Goh, Michael Petrov, and Shan Carter. Zoom in: An introduction to circuits.Distill, 5(3):e00024–001, 2020. 3
2020
-
[28]
Learning transferable visual models from natural language supervi- sion
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervi- sion. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021. 1
2021
-
[29]
Jumping Ahead: Improving Reconstruction Fidelity with JumpReLU Sparse Autoencoders
Senthooran Rajamanoharan, Tom Lieberum, Nicolas Son- nerat, Arthur Conmy, Vikrant Varma, J ´anos Kram ´ar, and Neel Nanda. Jumping ahead: Improving reconstruction fi- delity with jumprelu sparse autoencoders.arXiv preprint arXiv:2407.14435, 2024. 3
work page internal anchor Pith review arXiv 2024
-
[30]
Taking fea- tures out of superposition with sparse autoencoders
Lee Sharkey, Dan Braun, and Beren Millidge. Taking fea- tures out of superposition with sparse autoencoders. InAI Alignment Forum, pages 12–13, 2022. 3
2022
-
[31]
Deep Inside Convolutional Networks: Visualising Image Classification Models and Saliency Maps
Karen Simonyan, Andrea Vedaldi, and Andrew Zisserman. Deep inside convolutional networks: Visualising image classi- fication models and saliency maps, corr abs/1312.6034.arXiv preprint arXiv:1312.6034, 2014. 3
work page Pith review arXiv 2014
-
[32]
Sparse autoencoders for scientifically rigorous interpre- tation of vision models.arXiv e-prints, pages arXiv–2502,
Samuel Stevens, Wei-Lun Chao, Tanya Berger-Wolf, and Yu Su. Sparse autoencoders for scientifically rigorous interpre- tation of vision models.arXiv e-prints, pages arXiv–2502,
-
[33]
Viacheslav Surkov, Chris Wendler, Antonio Mari, Mikhail Terekhov, Justin Deschenaux, Robert West, Caglar Gul- cehre, and David Bau. One-step is enough: Sparse autoen- coders for text-to-image diffusion models.arXiv preprint arXiv:2410.22366, 2024. 3
-
[34]
Anthropic, 2024
Adly Templeton.Scaling monosemanticity: Extracting in- terpretable features from claude 3 sonnet. Anthropic, 2024. 3
2024
-
[35]
Universal sparse au- toencoders: Interpretable cross-model concept alignment
Harrish Thasarathan, Julian Forsyth, Thomas Fel, Matthew Kowal, and Konstantinos G Derpanis. Universal sparse au- toencoders: Interpretable cross-model concept alignment. In Forty-second International Conference on Machine Learning,
-
[36]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Am- jad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models.arXiv preprint arXiv:2307.09288, 2023. 1
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[37]
Zeiler and Rob Fergus
Matthew D. Zeiler and Rob Fergus. Visualizing and under- standing convolutional networks. InComputer Vision – ECCV 2014, pages 818–833, Cham, 2014. Springer International Publishing. 3
2014
-
[38]
doi:10.48550/arxiv.2510.00404 , url=
Xudong Zhu, Mohammad Mahdi Khalili, and Zhihui Zhu. Abstopk: Rethinking sparse autoencoders for bidirectional features.arXiv preprint arXiv:2510.00404, 2025. 3 Can Cross-Layer Transcoders Replace Vision Transformer Activations? An Interpretable Perspective on Vision Supplementary Material
-
[39]
To obtain example-based explanations of cross-layer influence, we provide some evi- dence of a retrieval-based framework that operates directly on the CLT sparse codes
Visually Explainable Cross-Layer Contribu- tion The contribution scores Cs→ℓ quantifywhichlayers mat- ter, but notwhatthey represent. To obtain example-based explanations of cross-layer influence, we provide some evi- dence of a retrieval-based framework that operates directly on the CLT sparse codes. Recall that a target post-MLP representationˆyL at the...
-
[40]
Additional Metrics for CLTs’ faithfulness To provide further evidence of CLT’s faithfulness to the original model, we evaluate distributional alignment (KL, flip rate), top- k agreement, embedding geometry (cos/CKA/Spearman), and prompt sensitivity across 18 tem- plates for the ViT-B/32 model on CIFAR100. Table 5 shows that in the regimes the CLTs faithfu...
-
[41]
For each backbone, we consider three datasets: CIFAR-100, COCO, and ImageNet-100
Training Details Teacher models and datasets.All Cross-Layer Transcoders (CLTs) are trained on top of frozen CLIP image encoders with ViT-B/32 and ViT-B/16 backbones. For each backbone, we consider three datasets: CIFAR-100, COCO, and ImageNet-100. For every (dataset, backbone) pair we train three separate CLT variants, one for each sparsifier: JumpReLU, ...
-
[42]
Reconstruction Accuracy across Layers In Figures 6–10, we report the reconstruction quality of Cross-Layer Transcoders (CLTs) across all transformer lay- ers on three datasets (CIFAR-100, COCO, and ImageNet-
-
[43]
and two CLIP backbones (ViT-B/32 and ViT-B/16). For each configuration, we compare three sparsity variants, i.e., JUMPRELU, RELU-TOP- k, and ABS-TOP- k, using co- sine similarity, mean squared error (log scale), and variance explained (R2), averaged over all tokens in the test set
-
[44]
For each dataset (CIFAR-100, COCO, ImageNet-
Classification Accuracy under Cascaded CLT Replacement We report top-1 classification accuracy (%) under cascaded CLT replacement across all layers ( s→11 ) in Figures 6–23. For each dataset (CIFAR-100, COCO, ImageNet-
-
[45]
The replacement is performed progressively from early to late layers ( s= 0 to s= 11 ), and results are compared to the frozen ViT baseline
and ViT backbone (ViT-B/32, ViT-B/16), we evaluate three sparsity mechanisms: JUMPRELU (JR), RELU-TOP- k (RTK), and ABS-TOP- k (ATK), under three token settings (CLS-only, patch-only, and all tokens). The replacement is performed progressively from early to late layers ( s= 0 to s= 11 ), and results are compared to the frozen ViT baseline. We observe that...
-
[46]
Cross-Layer Contribution Scores To better understand the internal attribution structure of Cross-Layer Transcoders (CLTs), we visualize in Figures 11–16 the contribution scores Cs→ℓ, which quantify the influence of each source layer s on the reconstruction of acti- vations at target layer ℓ. These heatmaps reveal a clear depth- aware structure across all ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.