Recognition: unknown
Empirical Evidence of Complexity-Induced Limits in Large Language Models on Finite Discrete State-Space Problems with Explicit Validity Constraints
Pith reviewed 2026-05-10 14:08 UTC · model grok-4.3
The pith
Large language models undergo reasoning collapse beyond task-specific complexity thresholds in discrete reasoning problems.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
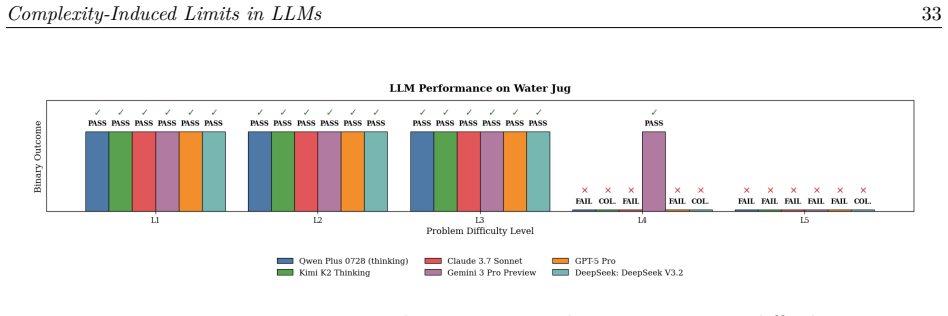
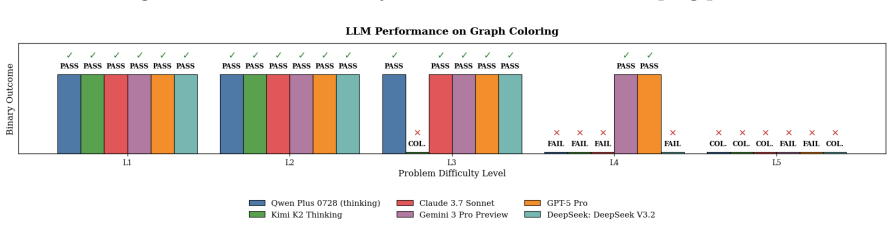
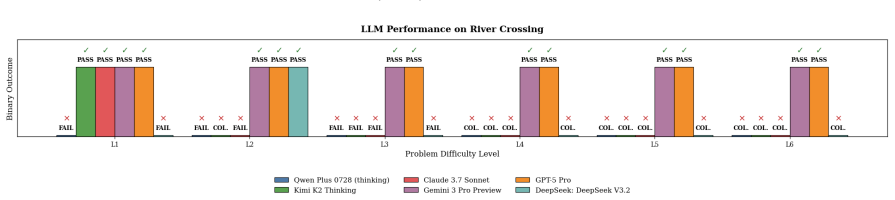
The authors establish that LLMs display consistent phase transition-like behavior on these tasks: high accuracy at low complexity regimes gives way to sharp degradation beyond specific thresholds, a phenomenon they term reasoning collapse, marked by accuracy drops often over 50 percent along with invalid and inconsistent outputs.
What carries the argument
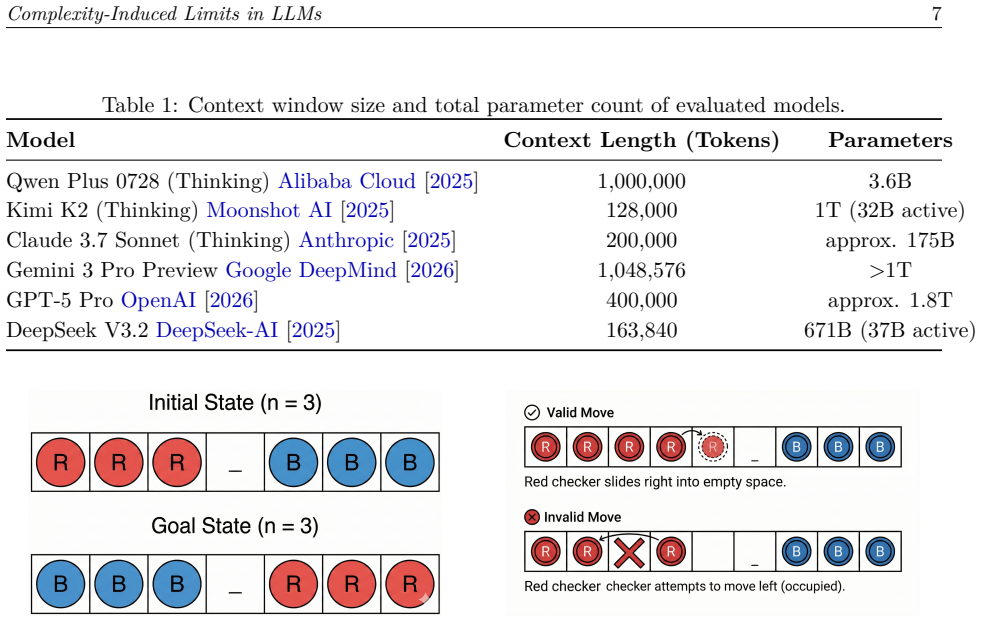
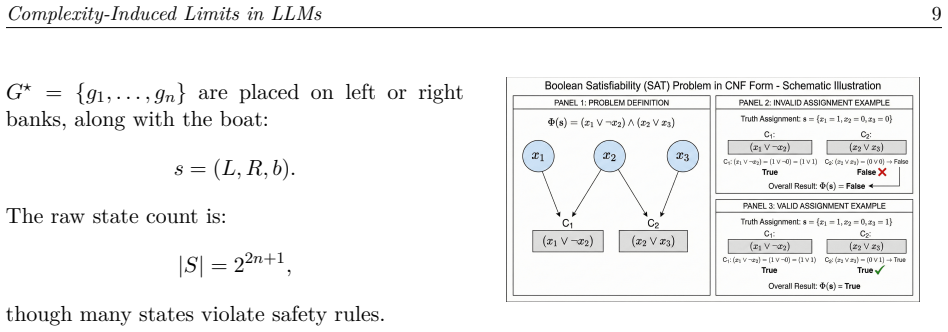
A suite of nine parameterized classical reasoning tasks equipped with deterministic validators that enforce explicit validity constraints on solutions.
If this is right
- Accuracy declines often exceed 50% past the thresholds.
- Longer reasoning traces do not reliably increase correctness.
- Gains on one problem family fail to generalize to others.
- Current models lose state tracking and produce confidently incorrect outputs at high complexity.
- Static benchmarks are insufficient for measuring reasoning robustness.
Where Pith is reading between the lines
- These limits may stem from the autoregressive nature of LLMs struggling with long-horizon state maintenance.
- Architectures with explicit memory or search mechanisms could potentially raise the collapse thresholds.
- The identified thresholds provide a quantitative way to compare reasoning capabilities across models.
- Similar collapse phenomena might appear in other domains like code generation or theorem proving when complexity is scaled.
Load-bearing premise
The specific ways complexity is increased in each of the nine tasks accurately reflect greater reasoning demands without adding unrelated biases to the problem space.
What would settle it
Observing no significant accuracy drop across low, medium, and high complexity versions of these tasks in a new model or evaluation would falsify the existence of reasoning collapse.
Figures


























read the original abstract
Large Language Models (LLMs) are increasingly described as possessing strong reasoning capabilities, supported by high performance on mathematical, logical, and planning benchmarks. However, most existing evaluations rely on aggregate accuracy over fixed datasets, obscuring how reasoning behavior evolves as task complexity increases. In this work, we introduce a controlled benchmarking framework to systematically evaluate the robustness of reasoning in Large Reasoning Models (LRMs) under progressively increasing problem complexity. We construct a suite of nine classical reasoning tasks: Boolean Satisfiability, Cryptarithmetic, Graph Coloring, River Crossing, Tower of Hanoi, Water Jug, Checker Jumping, Sudoku, and Rubik's Cube, each parameterized to precisely control complexity while preserving underlying semantics. Using deterministic validators, we evaluate multiple open and proprietary LRMs across low, intermediate, and high complexity regimes, ensuring that only fully valid solutions are accepted. Our results reveal a consistent phase transition like behavior: models achieve high accuracy at low complexity but degrade sharply beyond task specific complexity thresholds. We formalize this phenomenon as reasoning collapse. Across tasks, we observe substantial accuracy declines, often exceeding 50%, accompanied by inconsistent reasoning traces, constraint violations, loss of state tracking, and confidently incorrect outputs. Increased reasoning length does not reliably improve correctness, and gains in one problem family do not generalize to others. These findings highlight the need for evaluation methodologies that move beyond static benchmarks and explicitly measure reasoning robustness under controlled complexity.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces a controlled benchmarking framework using nine classical reasoning tasks (Boolean Satisfiability, Cryptarithmetic, Graph Coloring, River Crossing, Tower of Hanoi, Water Jug, Checker Jumping, Sudoku, Rubik's Cube) parameterized by increasing complexity levels while preserving semantics. It evaluates multiple open and proprietary Large Reasoning Models with deterministic validators, reporting high accuracy at low complexity but sharp degradation (often >50%) beyond task-specific thresholds, accompanied by inconsistent traces, constraint violations, and loss of state tracking. The authors formalize this as 'reasoning collapse' and argue that increased reasoning length does not reliably improve performance and that gains do not generalize across problem families, calling for evaluation methods beyond static benchmarks.
Significance. If the complexity controls are shown to isolate reasoning demand without confounds, the work would provide valuable empirical evidence of phase-transition-like limits in LLM reasoning robustness, shifting focus from aggregate benchmark scores to controlled scaling studies. The use of deterministic validators and a diverse task suite strengthens the empirical grounding, though the absence of detailed controls and statistics limits immediate generalizability to broader reasoning capabilities.
major comments (2)
- [Abstract] Abstract and described methodology: The claim that tasks are 'parameterized to precisely control complexity while preserving underlying semantics' does not specify how parameters (e.g., clause count in SAT, disk count in Hanoi, clue count in Sudoku) hold solution length or state-space cardinality fixed while varying only logical depth. This is load-bearing for the central 'reasoning collapse' claim, as the observed accuracy drops could arise from token-budget exhaustion or increased constraint-violation probability rather than any collapse in reasoning.
- [Results] Results and evaluation sections: No details are provided on sample sizes per complexity regime, number of trials, statistical tests for the phase-transition behavior, or full per-task/per-model accuracy tables. This makes the assertions of 'consistent' behavior and 'often exceeding 50%' declines unverifiable and weakens the cross-task generalization claim.
minor comments (2)
- [Abstract] The phrase 'phase transition like behavior' should be hyphenated as 'phase-transition-like' for clarity.
- [Introduction] The manuscript would benefit from explicit comparison to prior work on LLM reasoning limits (e.g., studies on chain-of-thought scaling or constraint satisfaction benchmarks) to better situate the novelty of the 'reasoning collapse' formalization.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments, which help clarify the presentation of our controlled benchmarking framework and strengthen the empirical claims. We address each major comment below and commit to revisions that enhance methodological transparency and statistical rigor without altering the core findings.
read point-by-point responses
-
Referee: [Abstract] Abstract and described methodology: The claim that tasks are 'parameterized to precisely control complexity while preserving underlying semantics' does not specify how parameters (e.g., clause count in SAT, disk count in Hanoi, clue count in Sudoku) hold solution length or state-space cardinality fixed while varying only logical depth. This is load-bearing for the central 'reasoning collapse' claim, as the observed accuracy drops could arise from token-budget exhaustion or increased constraint-violation probability rather than any collapse in reasoning.
Authors: We agree that explicit parameterization details are essential to substantiate the isolation of reasoning demand. The revised manuscript will expand the methodology section with a per-task table and description showing how parameters were selected: for SAT, clause-to-variable ratio is increased while holding variable count fixed (thus controlling state-space size); for Tower of Hanoi, disk count is varied but solution length grows predictably with the standard recursive strategy; for Sudoku, clue count is reduced while preserving unique solvability and minimal solution steps. We will explicitly note that complete decoupling of logical depth from state-space cardinality is not always feasible across all tasks and will add a limitations subsection discussing potential confounds such as token limits and validator strictness. These additions will allow readers to evaluate whether the observed drops reflect reasoning collapse rather than resource exhaustion. revision: yes
-
Referee: [Results] Results and evaluation sections: No details are provided on sample sizes per complexity regime, number of trials, statistical tests for the phase-transition behavior, or full per-task/per-model accuracy tables. This makes the assertions of 'consistent' behavior and 'often exceeding 50%' declines unverifiable and weakens the cross-task generalization claim.
Authors: We concur that the current presentation lacks sufficient statistical detail for full verifiability. In the revision we will add a new 'Evaluation Protocol' subsection specifying: 100 problem instances per complexity level per task, 3 independent trials per instance with temperature 0 for determinism where possible, and use of binomial confidence intervals plus paired t-tests to assess significance of accuracy drops across regimes. Complete per-task, per-model accuracy tables (including exact decline percentages) will be moved to the appendix, with summary statistics in the main results section. These changes will directly support the claims of consistent phase-transition behavior and cross-task patterns. revision: yes
Circularity Check
No circularity: purely empirical evaluation with explicit task parameterization
full rationale
The paper conducts a controlled empirical study across nine fixed tasks with manually defined complexity parameters (e.g., clause count, disk count). No mathematical derivations, fitted parameters renamed as predictions, or self-referential definitions appear. 'Reasoning collapse' is introduced as a descriptive label for observed accuracy drops, not derived from prior equations or self-citations. Complexity controls are stated directly in the task construction and evaluated against external deterministic validators, keeping the chain self-contained and non-circular.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The nine selected classical reasoning tasks can be parameterized to control complexity while preserving underlying semantics and validity constraints.
- domain assumption Deterministic validators provide accurate, unbiased assessment of solution validity across all complexity levels.
invented entities (1)
-
reasoning collapse
no independent evidence
Reference graph
Works this paper leans on
-
[1]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in ":" * " " * FUNCTION f...
-
[2]
Chi, Quoc V
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed H. Chi, Quoc V. Le, and Denny Zhou. Chain-of-thought prompting elicits reasoning in Large Language Models , 2022
2022
-
[3]
Large Language Models are zero-shot reasoners, 2022
Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yutaka Matsuo, and Yusuke Iwasawa. Large Language Models are zero-shot reasoners, 2022
2022
-
[4]
Le, Ed H
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc V. Le, Ed H. Chi, and Denny Zhou. Self-consistency improves chain of thought reasoning in language models, 2022 a
2022
-
[5]
Beyond the imitation game: Quantifying and extrapolating the capabilities of language models, 2022
Aarohi Srivastava, Abhinav Rastogi, Abhishek Sharma, et al. Beyond the imitation game: Quantifying and extrapolating the capabilities of language models, 2022
2022
-
[6]
Training verifiers to solve math word problems, 2021
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, and Reiichiro Nakano. Training verifiers to solve math word problems, 2021
2021
-
[7]
Measuring mathematical problem solving with the MATH dataset, 2021
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the MATH dataset, 2021
2021
-
[8]
Proving test set contamination in black-box language models, 2023
Yonatan Oren, Nicole Meister, Nitish Gupta, Tuhin Chakrabarty, Jonathan Valter, Thomas Steinke, Matt Tancik, Danqi Chen, Percy Liang, Sergey Levine, et al. Proving test set contamination in black-box language models, 2023
2023
-
[9]
The illusion of thinking: Understanding the strengths and limitations of reasoning models via the lens of problem complexity, 2025
Parshin Shojaee, Iman Mirzadeh, Keivan Alizadeh, Maxwell Horton, Samy Bengio, and Mehrdad Farajtabar. The illusion of thinking: Understanding the strengths and limitations of reasoning models via the lens of problem complexity, 2025. URL https://machinelearning.apple.com/research/illusion-of-thinking. Apple Machine Learning Research, published June 2025
2025
-
[11]
A survey on Large Language Model benchmarks, 2025
Shiwen Ni, Guhong Chen, Shuaimin Li, Xuanang Chen, Siyi Li, Bingli Wang, Qiyao Wang, Xingjian Wang, Yifan Zhang, Liyang Fan, Chengming Li, Ruifeng Xu, Le Sun, and Min Yang. A survey on Large Language Model benchmarks, 2025
2025
-
[13]
Bean, Ryan Othniel Kearns, et al
Andrew M. Bean, Ryan Othniel Kearns, et al. Measuring what matters: Construct validity in large language model benchmarks. In Advances in Neural Information Processing Systems, 2025. NeurIPS 2025 Datasets and Benchmarks Track
2025
-
[14]
ReasonBENCH : Benchmarking the (in)stability of LLM reasoning, 2025
Nearchos Potamitis, Lars Klein, and Akhil Arora. ReasonBENCH : Benchmarking the (in)stability of LLM reasoning, 2025
2025
-
[15]
Dyval: Dynamic evaluation of large language models for reasoning tasks
Kaijie Zhu, Jiaao Chen, Jindong Wang, Neil Zhenqiang Gong, Diyi Yang, and Xing Xie. Dyval: Dynamic evaluation of large language models for reasoning tasks. In The Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=gjfOL9z5Xr
2024
-
[16]
Benchmarking rule-based reasoning abilities of large language models
Jiayi Gui, Yiming Liu, Jiale Cheng, et al. Benchmarking rule-based reasoning abilities of large language models. In Findings of the Association for Computational Linguistics: ACL 2025, 2025 a . URL https://aclanthology.org/2025.findings-acl.77
2025
-
[18]
Alibaba cloud model studio: Qwen Plus , 2025
Alibaba Cloud . Alibaba cloud model studio: Qwen Plus , 2025. URL https://www.alibabacloud.com/help/en/model-studio/models
2025
-
[19]
Kimi K2 : Open agentic intelligence, 2025
Moonshot AI . Kimi K2 : Open agentic intelligence, 2025. URL https://github.com/MoonshotAI/Kimi-K2.5
2025
-
[20]
Claude 3.7 Sonnet system card
Anthropic . Claude 3.7 Sonnet system card. Technical report, Anthropic, 2025
2025
-
[21]
Gemini 3 Pro preview documentation, 2026
Google DeepMind . Gemini 3 Pro preview documentation, 2026. URL https://deepmind.google/technologies/gemini/
2026
-
[22]
GPT-5 architecture and capabilities, 2026
OpenAI . GPT-5 architecture and capabilities, 2026. URL https://openai.com/research/
2026
-
[23]
DeepSeek-V3.2 : Pushing the frontier of open Large Language Models , 2025
DeepSeek-AI . DeepSeek-V3.2 : Pushing the frontier of open Large Language Models , 2025
2025
-
[24]
A survey on evaluation of Large Language Models , 2023
Anonymous. A survey on evaluation of Large Language Models , 2023
2023
-
[25]
Construct validity in Large Language Model benchmarks, 2025
Anonymous. Construct validity in Large Language Model benchmarks, 2025. NeurIPS 2025 Datasets and Benchmarks Track
2025
-
[26]
Zhu et al
K. Zhu et al. DyVal : Dynamic evaluation of Large Language Models for controlled complexity, 2025. OpenReview: DyVal framework
2025
-
[27]
Gui et al
J. Gui et al. Benchmarking rule-based reasoning abilities of Large Language Models . In Findings of the Association for Computational Linguistics (ACL), 2025 b
2025
-
[28]
Saha et al
S. Saha et al. Learning to plan & reason for evaluation with thinking LLM-as-a-Judge , 2025 b
2025
-
[29]
Beyond accuracy: Evaluating the reasoning behavior of Large Language Models , 2024
Philipp Mondorf and Barbara Plank. Beyond accuracy: Evaluating the reasoning behavior of Large Language Models , 2024
2024
-
[30]
The vulnerability of language model benchmarks: Do they accurately reflect true LLM performance?, 2024
Sourav Banerjee, Ayushi Agarwal, and Eishkaran Singh. The vulnerability of language model benchmarks: Do they accurately reflect true LLM performance?, 2024
2024
-
[31]
Magistral : Mistral's first reasoning model, 2025
Mistral AI . Magistral : Mistral's first reasoning model, 2025
2025
-
[32]
title Alibaba cloud model studio: Qwen Plus
author Alibaba Cloud , year 2025 . title Alibaba cloud model studio: Qwen Plus . https://www.alibabacloud.com/help/en/model-studio/models
2025
-
[33]
author Anonymous , year 2023 . title A survey on evaluation of Large Language Models . arXiv:2307.03109 http://arxiv.org/abs/2307.03109
-
[34]
title Construct validity in Large Language Model benchmarks
author Anonymous , year 2025 . title Construct validity in Large Language Model benchmarks . note NeurIPS 2025 Datasets and Benchmarks Track
2025
-
[35]
title Claude 3.7 Sonnet System Card
author Anthropic , year 2025 . title Claude 3.7 Sonnet System Card . type Technical Report . Anthropic
2025
-
[36]
author Banerjee, S. , author Agarwal, A. , author Singh, E. , year 2024 . title The vulnerability of language model benchmarks: Do they accurately reflect true LLM performance? arXiv:2412.03597 http://arxiv.org/abs/2412.03597
-
[37]
Training Verifiers to Solve Math Word Problems
author Cobbe, K. , author Kosaraju, V. , author Bavarian, M. , author Chen, M. , author Jun, H. , author Kaiser, L. , author Plappert, M. , author Tworek, J. , author Hilton, J. , author Nakano, R. , year 2021 . title Training verifiers to solve math word problems . arXiv:2110.14168 http://arxiv.org/abs/2110.14168
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[38]
DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models
author DeepSeek-AI , year 2025 . title DeepSeek-V3.2 : Pushing the frontier of open Large Language Models . arXiv:2512.02556 http://arxiv.org/abs/2512.02556
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
title Gemini 3 Pro preview documentation
author Google DeepMind , year 2026 . title Gemini 3 Pro preview documentation . https://deepmind.google/technologies/gemini/
2026
-
[40]
, et al., year 2025
author Gui, J. , et al., year 2025 . title Benchmarking rule-based reasoning abilities of Large Language Models , in: booktitle Findings of the Association for Computational Linguistics (ACL)
2025
-
[41]
Measuring Mathematical Problem Solving With the MATH Dataset
author Hendrycks, D. , author Burns, C. , author Basart, S. , author Zou, A. , author Mazeika, M. , author Song, D. , author Steinhardt, J. , year 2021 . title Measuring mathematical problem solving with the MATH dataset . arXiv:2103.03874 http://arxiv.org/abs/2103.03874
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[42]
Large Language Models are Zero-Shot Reasoners
author Kojima, T. , author Gu, S.S. , author Reid, M. , author Matsuo, Y. , author Iwasawa, Y. , year 2022 . title Large Language Models are zero-shot reasoners . arXiv:2205.11916 http://arxiv.org/abs/2205.11916
work page internal anchor Pith review arXiv 2022
-
[43]
Jiang, Andy Lo, Gabrielle Berrada, Guillaume Lample, et al
author Mistral AI , year 2025 . title Magistral : Mistral's first reasoning model . arXiv:2506.10910 http://arxiv.org/abs/2506.10910
-
[44]
author Mondorf, P. , author Plank, B. , year 2024 . title Beyond accuracy: Evaluating the reasoning behavior of Large Language Models . arXiv:2404.01869 http://arxiv.org/abs/2404.01869
-
[45]
title Kimi K2 : Open agentic intelligence
author Moonshot AI , year 2025 . title Kimi K2 : Open agentic intelligence . https://github.com/MoonshotAI/Kimi-K2.5
2025
-
[46]
A survey on large language model benchmarks.arXiv preprint arXiv:2508.15361,
author Ni, S. , author Chen, G. , author Li, S. , author Chen, X. , author Li, S. , author Wang, B. , author Wang, Q. , author Wang, X. , author Zhang, Y. , author Fan, L. , author Li, C. , author Xu, R. , author Sun, L. , author Yang, M. , year 2025 . title A survey on Large Language Model benchmarks . arXiv:2508.15361 http://arxiv.org/abs/2508.15361
-
[47]
title GPT-5 architecture and capabilities
author OpenAI , year 2026 . title GPT-5 architecture and capabilities . https://openai.com/research/
2026
-
[48]
Proving test set contamination in black box language models
author Oren, Y. , author Meister, N. , author Gupta, N. , author Chakrabarty, T. , author Valter, J. , author Steinke, T. , author Tancik, M. , author Chen, D. , author Liang, P. , author Levine, S. , et al., year 2023 . title Proving test set contamination in black-box language models . arXiv:2310.17623 http://arxiv.org/abs/2310.17623
-
[49]
author Potamitis, N. , author Klein, L. , author Arora, A. , year 2025 . title ReasonBENCH : Benchmarking the (in)stability of LLM reasoning . arXiv:2512.07795 http://arxiv.org/abs/2512.07795
-
[50]
Learning to plan & reason for evaluation with thinking-llm-as-a-judge, 2025
author Saha, S. , et al., year 2025 . title Learning to plan & reason for evaluation with thinking LLM-as-a-Judge . arXiv:2501.18099 http://arxiv.org/abs/2501.18099
-
[51]
, author Mirzadeh, I
author Shojaee, P. , author Mirzadeh, I. , author Alizadeh, K. , author Horton, M. , author Bengio, S. , author Farajtabar, M. , year 2025 . title The illusion of thinking: Understanding the strengths and limitations of reasoning models via the lens of problem complexity . https://machinelearning.apple.com/research/illusion-of-thinking. note apple Machine...
2025
-
[52]
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
author Srivastava, A. , author Rastogi, A. , author Sharma, A. , et al., year 2022 . title Beyond the imitation game: Quantifying and extrapolating the capabilities of language models . arXiv:2206.04615 http://arxiv.org/abs/2206.04615
work page internal anchor Pith review arXiv 2022
-
[53]
Self-Consistency Improves Chain of Thought Reasoning in Language Models
author Wang, X. , author Wei, J. , author Schuurmans, D. , author Le, Q.V. , author Chi, E.H. , author Zhou, D. , year 2022 . title Self-consistency improves chain of thought reasoning in language models . arXiv:2203.11171 http://arxiv.org/abs/2203.11171
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[54]
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
author Wei, J. , author Wang, X. , author Schuurmans, D. , author Bosma, M. , author Xia, F. , author Chi, E.H. , author Le, Q.V. , author Zhou, D. , year 2022 . title Chain-of-thought prompting elicits reasoning in Large Language Models . arXiv:2201.11903 http://arxiv.org/abs/2201.11903
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[55]
, et al., year 2025
author Zhu, K. , et al., year 2025 . title DyVal : Dynamic evaluation of Large Language Models for controlled complexity . note OpenReview: DyVal framework
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.