Recognition: unknown
Event-Adaptive State Transition and Gated Fusion for RGB-Event Object Tracking
Pith reviewed 2026-05-10 13:06 UTC · model grok-4.3
The pith
MambaTrack adapts state transition matrices to event density and uses gated fusion for robust RGB-Event object tracking.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
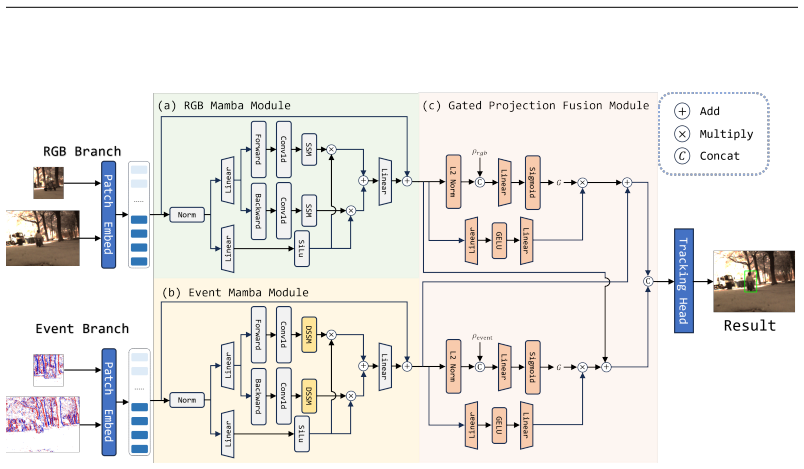
MambaTrack is a multimodal and efficient tracking framework built upon a Dynamic State Space Model whose first contribution is an event-adaptive state transition mechanism that dynamically modulates the state transition matrix based on event stream density, with a learnable scalar governing the state evolution rate to enable differentiated modeling of sparse and dense event flows. Its second contribution is a Gated Projection Fusion module that projects RGB features into the event feature space and generates adaptive gates from event density and RGB confidence scores to precisely control fusion intensity.
What carries the argument
Event-adaptive state transition mechanism in a Dynamic State Space Model, which modulates the transition matrix according to event density with a learnable scalar, paired with the Gated Projection Fusion module that uses density and confidence to control cross-modal integration.
If this is right
- Better balance in modeling sparse versus dense event streams, reducing underfitting and overfitting.
- More precise suppression of noise during fusion while retaining complementary RGB and event information.
- State-of-the-art tracking accuracy on the FE108 and FELT datasets.
- Lightweight design that supports potential real-time embedded deployment.
Where Pith is reading between the lines
- The density-based adaptation could transfer to other state-space models handling variable-rate sensor inputs, such as in audio-visual or radar-vision fusion.
- If the learnable scalar proves sensitive to initialization, adding constraints derived from event statistics might stabilize training across domains.
- Extending the gated projection idea to multi-frame temporal fusion could further improve tracking in long sequences with changing conditions.
Load-bearing premise
That modulating the state transition matrix dynamically via event density and a learnable scalar, together with gates based on density and RGB confidence, will deliver stable robust fusion without introducing instability or needing heavy per-dataset tuning.
What would settle it
An ablation or comparison on a dataset with controlled extreme variations in event density where removing the adaptive modulation or the gates causes no performance drop or even improvement over the full MambaTrack model.
Figures


read the original abstract
Existing Vision Mamba-based RGB-Event(RGBE) tracking methods suffer from using static state transition matrices, which fail to adapt to variations in event sparsity. This rigidity leads to imbalanced modeling-underfitting sparse event streams and overfitting dense ones-thus degrading cross-modal fusion robustness. To address these limitations, we propose MambaTrack, a multimodal and efficient tracking framework built upon a Dynamic State Space Model(DSSM). Our contributions are twofold. First, we introduce an event-adaptive state transition mechanism that dynamically modulates the state transition matrix based on event stream density. A learnable scalar governs the state evolution rate, enabling differentiated modeling of sparse and dense event flows. Second, we develop a Gated Projection Fusion(GPF) module for robust cross-modal integration. This module projects RGB features into the event feature space and generates adaptive gates from event density and RGB confidence scores. These gates precisely control the fusion intensity, suppressing noise while preserving complementary information. Experiments show that MambaTrack achieves state-of-the-art performance on the FE108 and FELT datasets. Its lightweight design suggests potential for real-time embedded deployment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces MambaTrack, a multimodal RGB-Event tracking framework built on a Dynamic State Space Model (DSSM). It proposes an event-adaptive state transition mechanism that modulates the state transition matrix according to event stream density using a learnable scalar, and a Gated Projection Fusion (GPF) module that projects RGB features into event space and applies adaptive gates derived from event density and RGB confidence scores. The paper claims that these components enable robust cross-modal fusion and achieve state-of-the-art performance on the FE108 and FELT datasets.
Significance. If the proposed mechanisms can be shown to drive measurable robustness gains over static-transition baselines, the work would address a practical limitation in handling variable event sparsity for efficient multimodal tracking. The emphasis on a lightweight design is a strength that could support real-time deployment, but the current lack of verifiable experimental support limits the assessed impact.
major comments (3)
- Abstract: The central claim of SOTA performance on FE108 and FELT is presented without any quantitative metrics, baseline comparisons, or ablation results, leaving the attribution of gains specifically to the event-adaptive state transition and GPF unsupported.
- Method section (DSSM and event-adaptive transition): No equations or explicit formulations are supplied for the density-based modulation of the state transition matrix or the learnable scalar's role in governing evolution rate, preventing verification that the mechanism avoids the stated underfitting/overfitting problems.
- Experiments section: Absence of ablation studies comparing the full model against a static-transition Mamba variant or non-gated fusion baseline means it is impossible to confirm that the proposed adaptations, rather than backbone choice or optimization details, produce the reported improvements.
minor comments (1)
- Abstract: The phrase 'Experiments show that MambaTrack achieves state-of-the-art performance' should be accompanied by at least the primary metrics (e.g., success rate, precision) and the number of compared methods for immediate context.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We agree that the current presentation can be strengthened by adding quantitative support in the abstract, explicit formulations in the method, and targeted ablations in the experiments. We will revise the manuscript accordingly to better substantiate the contributions of the event-adaptive state transition and Gated Projection Fusion modules.
read point-by-point responses
-
Referee: Abstract: The central claim of SOTA performance on FE108 and FELT is presented without any quantitative metrics, baseline comparisons, or ablation results, leaving the attribution of gains specifically to the event-adaptive state transition and GPF unsupported.
Authors: We acknowledge that the abstract would be more informative with key quantitative results. In the revised version we will update the abstract to report specific metrics (e.g., success rate and precision on FE108 and FELT) together with the main baseline comparisons, thereby directly linking the reported gains to the proposed components. revision: yes
-
Referee: Method section (DSSM and event-adaptive transition): No equations or explicit formulations are supplied for the density-based modulation of the state transition matrix or the learnable scalar's role in governing evolution rate, preventing verification that the mechanism avoids the stated underfitting/overfitting problems.
Authors: We agree that explicit mathematical formulations are necessary for verification. Although the manuscript describes the mechanism at a conceptual level, we will insert the full set of equations for the density-modulated state transition matrix and the learnable scalar in the revised Method section, together with a short derivation showing how the adaptation mitigates under- and overfitting across event densities. revision: yes
-
Referee: Experiments section: Absence of ablation studies comparing the full model against a static-transition Mamba variant or non-gated fusion baseline means it is impossible to confirm that the proposed adaptations, rather than backbone choice or optimization details, produce the reported improvements.
Authors: We recognize the value of isolating the contribution of each proposed module. The revised Experiments section will include new ablation tables that compare the full MambaTrack model against (i) a static-transition DSSM variant and (ii) a non-gated fusion baseline, while keeping the backbone and training protocol fixed. These results will quantify the incremental gains attributable to the event-adaptive transition and GPF. revision: yes
Circularity Check
No circularity in proposed mechanisms or claims
full rationale
The paper introduces MambaTrack via two new modules—an event-adaptive state transition that modulates the matrix using event density plus a learnable scalar, and a Gated Projection Fusion module with density-and-confidence gates—without any equations, derivations, or predictions that reduce by construction to fitted inputs, self-referential terms, or prior self-citations. No load-bearing uniqueness theorems, ansatzes smuggled via citation, or renamings of known results appear; the SOTA claims rest on empirical results on FE108 and FELT rather than tautological definitions. The architecture is presented as independent additions addressing static-matrix limitations, making the derivation chain self-contained.
Axiom & Free-Parameter Ledger
free parameters (1)
- learnable scalar governing state evolution rate
axioms (1)
- domain assumption Static state transition matrices in Vision Mamba fail to adapt to variations in event sparsity, causing underfitting or overfitting
invented entities (2)
-
Event-adaptive state transition mechanism
no independent evidence
-
Gated Projection Fusion module
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Fusion-mamba for cross-modality object detection.arXiv preprint arXiv:2404.09146, 2024
Wenhao Dong, Haodong Zhu, Shaohui Lin, Xiaoyan Luo, Yunhang Shen, Xuhui Liu, Juan Zhang, Guodong Guo, and Baochang Zhang. Fusion-mamba for cross-modality object detection.arXiv preprint arXiv:2404.09146,
-
[2]
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
Albert Gu and Tri Dao. Mamba: Linear-time sequence modeling with selective state spaces.arXiv preprint arXiv:2312.00752,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Efficiently Modeling Long Sequences with Structured State Spaces
10 Albert Gu, Karan Goel, and Christopher R ´e. Efficiently modeling long sequences with structured state spaces.arXiv preprint arXiv:2111.00396,
work page internal anchor Pith review arXiv
-
[4]
Gaussian Error Linear Units (GELUs)
Dan Hendrycks and Kevin Gimpel. Gaussian error linear units (gelus).arXiv preprint arXiv:1606.08415,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
T., Warrington, A., and Linderman, S
Jimmy TH Smith, Andrew Warrington, and Scott W Linderman. Simplified state space layers for sequence modeling.arXiv preprint arXiv:2208.04933,
-
[7]
Revisiting color-event based tracking: A unified network, dataset, and metric
Chuanming Tang, Xiao Wang, Ju Huang, Bo Jiang, Lin Zhu, Jianlin Zhang, Yaowei Wang, and Yonghong Tian. Revisiting color-event based tracking: A unified network, dataset, and metric. arXiv preprint arXiv:2211.11010,
-
[8]
Xiao Wang, Jianing Li, Lin Zhu, Zhipeng Zhang, Zhe Chen, Xin Li, Yaowei Wang, Yonghong Tian, and Feng Wu. Visevent: Reliable object tracking via collaboration of frame and event flows.IEEE Transactions on Cybernetics, 54(3):1997–2010, 2023a. Xiao Wang, Ju Huang, Shiao Wang, Chuanming Tang, Bo Jiang, Yonghong Tian, Jin Tang, and Bin Luo. Long-term frame-ev...
-
[9]
Vision Mamba: Efficient Visual Representation Learning with Bidirectional State Space Model
Jiawen Zhu, Simiao Lai, Xin Chen, Dong Wang, and Huchuan Lu. Visual prompt multi-modal tracking. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 9516–9526, 2023a. Lianghui Zhu, Bencheng Liao, Qian Zhang, Xinlong Wang, Wenyu Liu, and Xinggang Wang. Vi- sion mamba: Efficient visual representation learning with bidire...
work page internal anchor Pith review arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.