Recognition: unknown
MaMe & MaRe: Matrix-Based Token Merging and Restoration for Efficient Visual Perception and Synthesis
Pith reviewed 2026-05-10 13:02 UTC · model grok-4.3
The pith
Matrix-based token merging doubles ViT-B throughput with a 2% accuracy drop while its inverse speeds up image synthesis.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
MaMe is a training-free, differentiable token merging method based entirely on matrix operations. When applied to pre-trained models, MaMe doubles ViT-B throughput with a 2% accuracy drop. Notably, fine-tuning the last layer with MaMe boosts ViT-B accuracy by 1.0% at 1.1x speed. In image synthesis, the MaMe+MaRe pipeline enhances quality while reducing Stable Diffusion v2.1 generation latency by 31%. The same matrix approach yields 1.3x acceleration on SigLIP2 and 48.5% faster inference on VideoMAE-L with minimal accuracy loss.
What carries the argument
MaMe, the matrix-based token merging operation that computes merging decisions and applies reductions using only matrix multiplications and aggregations to lower token count while remaining GPU-efficient and differentiable.
Load-bearing premise
Matrix-based merging decisions preserve task-critical information across diverse inputs without needing task-specific tuning or introducing hidden biases.
What would settle it
Applying MaMe to ViT-B on ImageNet without fine-tuning and observing an accuracy drop larger than 4% or a speedup below 1.5x would indicate the matrix merging does not preserve information as claimed.
Figures





read the original abstract
Token compression is crucial for mitigating the quadratic complexity of self-attention mechanisms in Vision Transformers (ViTs), which often involve numerous input tokens. Existing methods, such as ToMe, rely on GPU-inefficient operations (e.g., sorting, scattered writes), introducing overheads that limit their effectiveness. We introduce MaMe, a training-free, differentiable token merging method based entirely on matrix operations, which is GPU-friendly to accelerate ViTs. Additionally, we present MaRe, its inverse operation, for token restoration, forming a MaMe+MaRe pipeline for image synthesis. When applied to pre-trained models, MaMe doubles ViT-B throughput with a 2% accuracy drop. Notably, fine-tuning the last layer with MaMe boosts ViT-B accuracy by 1.0% at 1.1x speed. In SigLIP2-B@512 zero-shot classification, MaMe provides 1.3x acceleration with negligible performance degradation. In video tasks, MaMe accelerates VideoMAE-L by 48.5% on Kinetics-400 with only a 0.84% accuracy loss. Furthermore, MaMe achieves simultaneous improvements in both performance and speed on some tasks. In image synthesis, the MaMe+MaRe pipeline enhances quality while reducing Stable Diffusion v2.1 generation latency by 31%. Collectively, these results demonstrate MaMe's and MaRe's effectiveness in accelerating vision models. The code is available at https://github.com/cominder/mame}{https://github.com/cominder/mame.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce MaMe, a training-free and differentiable token merging method for Vision Transformers that relies solely on matrix operations for improved GPU efficiency compared to methods like ToMe. MaRe is presented as the inverse operation to enable token restoration in synthesis tasks. Key empirical results include doubling the throughput of ViT-B with a 2% accuracy drop, achieving a 1% accuracy boost at 1.1x speed after last-layer fine-tuning, 1.3x acceleration on SigLIP2 with minimal degradation, 48.5% speedup on VideoMAE-L with 0.84% loss on Kinetics-400, and 31% reduced latency in Stable Diffusion v2.1 with quality gains.
Significance. If the results hold, this work offers a significant practical contribution to efficient visual perception and synthesis by providing a simple, matrix-based approach that is training-free and generalizes across tasks without per-task retuning. The reported cases of simultaneous accuracy and speed improvements are notable. The open-source code strengthens the reproducibility of the findings.
minor comments (1)
- The abstract contains a duplicated URL in the code availability statement: 'https://github.com/cominder/mame}{https://github.com/cominder/mame'.
Simulated Author's Rebuttal
We thank the referee for the positive summary, recognition of the practical significance of the matrix-only token merging approach, and the recommendation for minor revision. We appreciate the emphasis on reproducibility via open-source code and the noted cases of simultaneous accuracy and speed gains.
Circularity Check
No significant circularity in derivation chain
full rationale
The paper defines MaMe explicitly as a sequence of matrix operations (similarity matrix construction, differentiable selection, and weighted averaging) that are training-free and end-to-end differentiable by construction of the primitives themselves. All headline performance numbers (2x throughput with 2% drop on ViT-B, 1% gain after last-layer fine-tuning, 31% latency reduction in Stable Diffusion, etc.) are presented as direct empirical measurements on standard public benchmarks rather than as outputs of any fitted parameter or self-referential prediction. No self-citations, uniqueness theorems, or ansatzes imported from prior author work are invoked to justify the core method; the derivation from matrix formulation to reported speed/accuracy trade-offs therefore remains independent of the evaluation results and externally falsifiable via the released code.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
TTF: Temporal Token Fusion for Efficient Video-Language Model
TTF fuses temporally redundant visual tokens via local similarity search in a plug-and-play way, cutting ~67% tokens on Qwen3-VL-8B while retaining 99.5% accuracy with minimal overhead.
Reference graph
Works this paper leans on
-
[1]
Dosovitskiy, L
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, et al., An image is worth 16x16 words: Transformers for image recognition at scale, Inter- national Conference on Learning Representations (ICLR) (2021)
2021
-
[2]
Vaswani, N
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, I. Polosukhin, Attention is all you need, Advances in Neural Information Processing Sys- tems (NeurIPS) 30 (2017)
2017
-
[3]
Y . Rao, W. Zhao, B. Liu, J. Lu, J. Zhou, C.-J. Hsieh, Dy- namicvit: Efficient vision transformers with dynamic to- ken sparsification, Advances in neural information pro- cessing systems 34 (2021) 13937–13949
2021
-
[4]
Not all patches are what you need: Expediting vision transformers via token reorganizations,
Y . Liang, C. Ge, Z. Tong, Y . Song, J. Wang, P. Xie, Not all patches are what you need: Expediting vision transformers via token reorganizations (2022).arXiv: 2202.07800. URLhttps://arxiv.org/abs/2202.07800
-
[5]
Bolya, C.-Y
D. Bolya, C.-Y . Fu, X. Dai, P. Zhang, C. Feichtenhofer, J. Hoffman, Token merging: Your vit but faster, Interna- tional Conference on Learning Representations (2022)
2022
-
[6]
D. Marin, J.-H. R. Chang, A. Ranjan, A. Prabhu, M. Rastegari, O. Tuzel, Token pooling in vision trans- formers for image classification, in: 2023 IEEE/CVF Winter Conference on Applications of Computer Vi- sion (W ACV), 2023, pp. 12–21.doi:10.1109/ WACV56688.2023.00010
-
[7]
M. Chen, W. Shao, P. Xu, M. Lin, K. Zhang, F. Chao, R. Ji, Y . Qiao, P. Luo, Diffrate: Differentiable compres- sion rate for efficient vision transformers, in: Proceedings of the IEEE/CVF international conference on computer vision, 2023, pp. 17164–17174
2023
- [8]
-
[9]
Shang, M
Y . Shang, M. Cai, B. Xu, Y . J. Lee, Y . Yan, Llava- prumerge: Adaptive token reduction for efficient large multimodal models, in: International Conference on Computer Vision (ICCV), 2025
2025
-
[10]
S. Yang, Y . Chen, Z. Tian, C. Wang, J. Li, B. Yu, J. Jia, Visionzip: Longer is better but not necessary in vi- sion language models, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025
2025
-
[11]
L. Meng, H. Li, B.-C. Chen, S. Lan, Z. Wu, Y .-G. Jiang, S.-N. Lim, Adavit: Adaptive vision transformers for effi- cient image recognition, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 12309–12318
2022
-
[12]
L. Chen, H. Zhao, T. Liu, S. Bai, J. Lin, C. Zhou, B. Chang, An image is worth 1/2 tokens after layer 2: Plug-and-play inference acceleration for large vision- language models, in: European Conference on Computer Vision (ECCV), 2024
2024
-
[13]
Z. Lin, M. Lin, L. Lin, R. Ji, Boosting multimodal large language models with visual tokens withdrawal for rapid inference, in: Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), 2025
2025
-
[14]
H. Song, Y .-J. Kim, S.-W. Oh, S.-J. Chun, ToFu: To- ken fusion for fast and accurate vision transformers, arXiv preprint arXiv:2403.14950 (2024)
- [15]
-
[16]
B. Li, W. Zhao, Z. Zhang, LTPM: A learnable token prun- ing and merging method for vision transformer, Journal of Machine Learning Research (2024)
2024
-
[17]
W. Zeng, S. Jin, L. Xu, W. Liu, C. Qian, W. Ouyang, P. Luo, X. Wang, Tcformer: Visual recognition via to- ken clustering transformer, IEEE Transactions on Pattern Analysis and Machine Intelligence 46 (12) (2024) 9521– 9535.doi:10.1109/TPAMI.2024.3425768
- [18]
-
[19]
P. Jin, R. Takanobu, W. Zhang, X. Cao, L. Yuan, Chat- univi: Unified visual representation empowers large lan- guage models with image and video understanding, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
2024
-
[20]
Fayyaz, S
M. Fayyaz, S. A. Koohpayegani, F. R. Jafari, S. Sengupta, H. R. V . Joze, E. Sommerlade, H. Pirsiavash, J. Gall, Adaptive token sampling for efficient vision transformers, in: European conference on computer vision, Springer, 2022, pp. 396–414
2022
-
[21]
Y . Wang, Y . Chen, L. Wang, J. Chen, Token morphing for vision transformer, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 16584–16593
2023
-
[22]
Kim, H.-J
D.-H. Kim, H.-J. Kim, T.-H. Kim, Gumbel-gate: A gumbel-based gating network for vision transformers, in: Proceedings of the AAAI Conference on Artificial Intelli- gence, V ol. 37, 2023, pp. 1454–1462
2023
-
[23]
Y . Li, C. Wang, J. Jia, Llama-vid: An image is worth 2 to- kens in large language models, in: European Conference on Computer Vision (ECCV), 2024
2024
-
[24]
Touvron, M
H. Touvron, M. Cord, M. Douze, F. Massa, A. Sablay- rolles, H. Jégou, Training data-efficient image transform- ers & distillation through attention, in: International con- ference on machine learning, PMLR, 2021, pp. 10347– 10357
2021
-
[25]
K. He, X. Chen, S. Xie, Y . Li, P. Dollár, R. Girshick, Masked autoencoders are scalable vision learners, in: Pro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 16000–16009
2022
-
[26]
Z. Liu, Y . Lin, Y . Cao, H. Hu, Y . Wei, Z. Zhang, S. Lin, B. Guo, Swin transformer: Hierarchical vision trans- former using shifted windows, in: Proceedings of the IEEE/CVF international conference on computer vision, 2021, pp. 10012–10022
2021
-
[27]
Learning Transferable Visual Models From Natural Language Supervision
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, G. Krueger, I. Sutskever, Learning transferable vi- sual models from natural language supervision (2021). arXiv:2103.00020. URLhttps://arxiv.org/abs/2103.00020
work page internal anchor Pith review Pith/arXiv arXiv 2021
- [28]
-
[29]
M. Tschannen, A. Gritsenko, X. Wang, M. F. Naeem, I. Alabdulmohsin, N. Parthasarathy, T. Evans, L. Beyer, Y . Xia, B. Mustafa, O. Hénaff, J. Harmsen, A. Steiner, X. Zhai, Siglip 2: Multilingual vision-language encoders with improved semantic understanding, localization, and dense features (2025).arXiv:2502.14786. URLhttps://arxiv.org/abs/2502.14786
work page internal anchor Pith review arXiv 2025
-
[30]
H. Liu, C. Li, Q. Wu, Y . J. Lee, Visual instruction tuning (2023)
2023
-
[31]
H. Duan, J. Yang, Y . Qiao, X. Fang, L. Chen, Y . Liu, X. Dong, Y . Zang, P. Zhang, J. Wang, et al., Vlmevalkit: An open-source toolkit for evaluating large multi-modality models, in: Proceedings of the 32nd ACM International Conference on Multimedia, 2024, pp. 11198–11201
2024
-
[32]
T.-Y . Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan, P. Dollár, C. L. Zitnick, Microsoft coco: Common objects in context, in: Computer vision–ECCV 2014: 13th European conference, zurich, Switzerland, September 6-12, 2014, proceedings, part v 13, Springer, 2014, pp. 740–755
2014
-
[33]
Z. Tong, Y . Song, J. Wang, L. Wang, VideoMAE: Masked autoencoders are data-efficient learners for self- supervised video pre-training, in: Advances in Neural In- formation Processing Systems, 2022
2022
-
[34]
W. Kay, J. Carreira, K. Simonyan, B. Zhang, C. Hillier, S. Vijayanarasimhan, F. Viola, T. Green, T. Back, P. Nat- sev, M. Suleyman, A. Zisserman, The kinetics hu- man action video dataset, CoRR abs/1705.06950 (2017). arXiv:1705.06950. URLhttp://arxiv.org/abs/1705.06950
work page internal anchor Pith review arXiv 2017
-
[35]
Rombach, A
R. Rombach, A. Blattmann, D. Lorenz, P. Esser, B. Om- mer, High-resolution image synthesis with latent diffusion models, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022, pp. 10684–10695
2022
-
[36]
Available: https://arxiv.org/abs/2303.17604
D. Bolya, J. Hoffman, Token merging for fast stable dif- fusion, arXiv preprint arXiv:2303.17604 (2023)
-
[37]
Y . Guo, H. Liu, H. Wen, Gemrec: Towards generative model recommendation, in: Proceedings of the 17th ACM International Conference on Web Search and Data Min- ing, V ol. 9 of WSDM ’24, ACM, 2024, p. 1054–1057. doi:10.1145/3616855.3635700. 13 URLhttp://dx.doi.org/10.1145/3616855. 3635700
-
[38]
Heusel, H
M. Heusel, H. Ramsauer, T. Unterthiner, B. Nessler, S. Hochreiter, Gans trained by a two time-scale update rule converge to a local nash equilibrium, Advances in Neural Information Processing Systems 30 (2017)
2017
-
[39]
Improved Techniques for Training GANs
T. Salimans, I. Goodfellow, W. Zaremba, V . Cheung, A. Radford, X. Chen, Improved techniques for training gans, arXiv preprint arXiv:1606.03498 (2016)
work page Pith review arXiv 2016
-
[40]
Zhang, P
R. Zhang, P. Isola, A. A. Efros, E. Shechtman, O. Wang, The unreasonable effectiveness of deep features as a per- ceptual metric, in: CVPR, 2018
2018
-
[41]
R. C. Gonzalez, R. E. Woods, Digital image processing, Pearson Education India, 2008
2008
-
[42]
Z. Wang, A. C. Bovik, H. R. Sheikh, E. P. Simoncelli, Im- age Quality Assessment: From Error Visibility to Struc- tural Similarity, IEEE Transactions on Image Processing 13 (4) (2004) 600–612
2004
-
[43]
Dong, J.-B
Y . Dong, J.-B. Cordonnier, A. Loukas, Attention is not all you need: Pure attention loses rank doubly exponen- tially with depth, in: International conference on machine learning, PMLR, 2021, pp. 2793–2803
2021
-
[44]
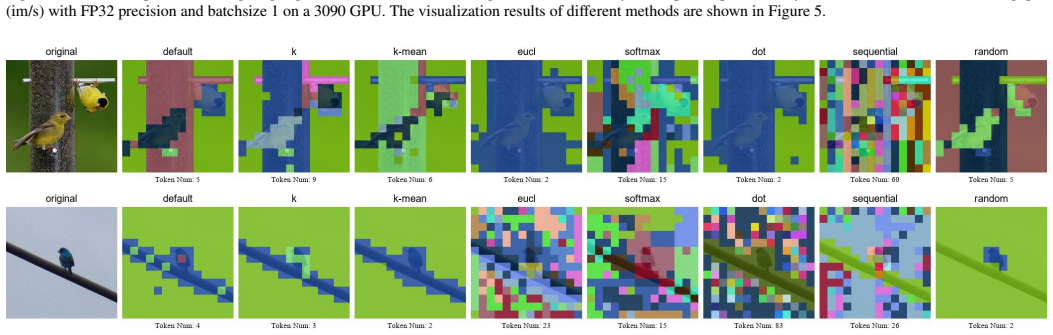
This image depicts
T. Dao, FlashAttention-2: Faster attention with better par- allelism and work partitioning, in: International Confer- ence on Learning Representations (ICLR), 2024. 14 Appendix A. Appendix 15 Figure A.7: The visualization in the 8th block of the AugReg ViT-B/16 using MaMe with different settings. Each color square represents a distinct type of token. Defa...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.