Recognition: unknown
PackSELL: A Sparse Matrix Format for Precision-Agnostic High-Performance SpMV
Pith reviewed 2026-05-10 13:03 UTC · model grok-4.3
The pith
PackSELL packs delta-encoded column indices with values into single words to cut memory traffic and enable flexible precision in GPU SpMV.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
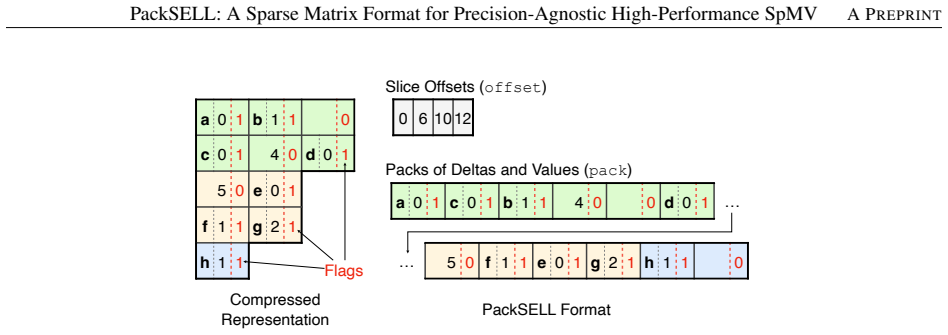
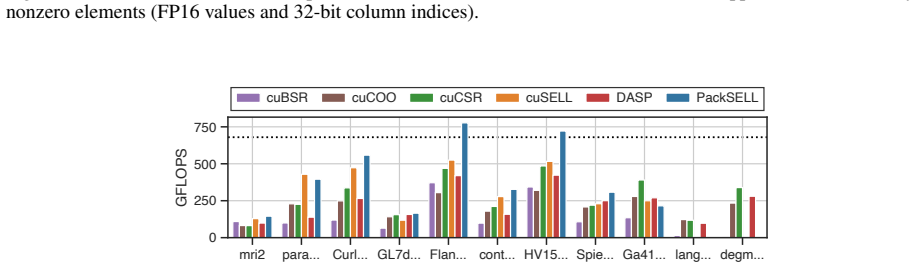
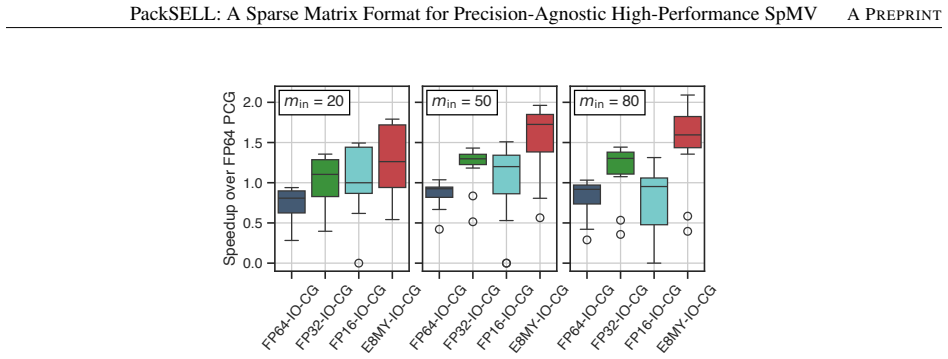
PackSELL stores sparse matrices by applying delta encoding to the column indices within each slice and packing each resulting delta together with its corresponding nonzero value into a single machine word. The format therefore shrinks data movement during SpMV and grants explicit control over how many bits are given to the delta versus the value, supporting arbitrary precisions and even custom floating-point layouts. On NVIDIA GPUs the approach produces SpMV kernels that run up to 1.63 times faster than cuSPARSE SELL in FP16 mode and, when tuned for custom formats, match FP32 accuracy while exceeding FP16 throughput; the same storage yields up to 2.09 times speedup in a mixed-precision PCG e
What carries the argument
The PackSELL format, which packs a delta-encoded column index together with its matrix value into a single word and permits explicit bit-width splits between the two fields.
If this is right
- SpMV at half precision runs up to 1.63 times faster than the cuSPARSE SELL baseline while using the same hardware.
- Custom bit-width allocations inside PackSELL can deliver FP32-level solution accuracy at throughput higher than standard FP16 kernels.
- Mixed-precision preconditioned conjugate gradient solvers built on PackSELL reach up to 2.09 times speedup over full-precision PCG.
- The same packed storage works for any sparse linear solver that repeatedly performs SpMV, extending the benefit beyond isolated kernels.
Where Pith is reading between the lines
- If index locality is low, the delta-encoding benefit shrinks and an alternative index compression scheme would be needed to retain the speedups.
- The single-word packing idea could be applied to other bandwidth-bound sparse kernels such as sparse matrix-matrix multiplication on the same GPUs.
- Because bit allocation is under explicit control, the format offers a practical route to explore non-standard number systems without rewriting the entire solver stack.
Load-bearing premise
Column indices in the input matrices must exhibit enough locality that delta encoding produces net compression, and the chosen bit splits must preserve numerical stability without matrix-specific retuning.
What would settle it
Measure PackSELL SpMV runtime and accuracy on a matrix whose column indices are randomly permuted within each row; if speed falls below cuSPARSE SELL or errors exceed FP32 tolerance under the reported bit allocations, the central claim does not hold.
Figures









read the original abstract
We propose a new sparse matrix format, PackSELL, designed to support diverse data representations and enable efficient sparse matrix-vector multiplication (SpMV) on GPUs. Building on sliced ELLPACK (SELL), PackSELL incorporates delta encoding of column indices and a novel packing scheme that stores each index-delta-value pair in a single word, thereby reducing memory footprint and data movement. This design further enables fine-grained control over the bit allocation between deltas and values, allowing flexible data representations, including non-IEEE formats. Experimental results show that, when configured for half precision (FP16), the PackSELL-based SpMV kernel outperforms the cuSPARSE SELL-based kernel by up to $1.63\times$. Moreover, with configurations using customized formats, PackSELL achieves FP32-level accuracy while exceeding the performance of FP16 cuSPARSE. These benefits extend to sparse linear solvers; for example, a mixed-precision preconditioned conjugate gradient (PCG) solver using PackSELL achieves up to a $2.09\times$ speedup over the standard full-precision PCG.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes PackSELL, an extension of the sliced ELLPACK (SELL) sparse matrix format that incorporates delta encoding of column indices and packs each index-delta-value triple into a single word. This enables reduced memory footprint, flexible bit-width allocation between deltas and values (including non-IEEE representations), and high-performance SpMV on GPUs. The central claims are that PackSELL in FP16 configuration outperforms cuSPARSE SELL by up to 1.63×, that custom bit allocations achieve FP32-level accuracy at speeds exceeding FP16 cuSPARSE, and that these gains translate to up to 2.09× speedup in a mixed-precision PCG solver.
Significance. If the performance and accuracy claims are substantiated with a representative matrix suite, statistical error bars, and ablation of the delta-encoding benefit, PackSELL would represent a practical advance in GPU sparse linear algebra by addressing memory-bandwidth limits while supporting precision flexibility. The packing scheme and locality exploitation via deltas are technically interesting contributions that could inform future sparse formats, though the design's dependence on index locality within SELL slices limits its universality.
major comments (3)
- [Abstract / §4] Abstract and §4 (Experimental Results): The reported speedups (1.63× over cuSPARSE SELL in FP16 and 2.09× in PCG) are presented without any description of the matrix collection (e.g., SuiteSparse matrices), number of test cases, or error-bar statistics. This absence prevents verification of the central performance claims and makes it impossible to assess whether gains hold on irregular matrices where delta-encoding locality may be weak.
- [§3] §3 (PackSELL Format and Bit Allocation): The paper asserts that bit allocation between delta and value fields can be chosen to maintain FP32-level accuracy without matrix-specific tuning, yet provides no quantitative error analysis, stability bounds, or ablation showing that fixed global allocations preserve accuracy across the test suite. This is load-bearing for the precision-agnostic claim.
- [§4] §4 (Performance Evaluation): No ablation isolates the memory-traffic reduction from delta encoding versus the packing overhead itself, nor reports memory-footprint measurements on matrices with varying column-index locality. Without these, it is unclear whether the format yields net compression or merely shifts costs, directly affecting the claimed speedups.
minor comments (1)
- [§3] Notation for the packed word layout and delta computation could be clarified with an explicit diagram or pseudocode in §3 to aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review. We address each major comment below, providing clarifications and indicating the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract / §4] Abstract and §4 (Experimental Results): The reported speedups (1.63× over cuSPARSE SELL in FP16 and 2.09× in PCG) are presented without any description of the matrix collection (e.g., SuiteSparse matrices), number of test cases, or error-bar statistics. This absence prevents verification of the central performance claims and makes it impossible to assess whether gains hold on irregular matrices where delta-encoding locality may be weak.
Authors: We agree that the experimental section requires more explicit details for reproducibility and to fully substantiate the claims. The manuscript evaluates PackSELL on 22 matrices drawn from the SuiteSparse collection, selected to include both high-locality and irregular patterns. In the revised version we will add an explicit table listing the matrices, their dimensions, nnz, and average delta bit-widths, state that all reported speedups are averages over these 22 cases, and include error bars computed from five independent runs per kernel to quantify measurement variability. This will allow direct assessment of behavior on irregular matrices. revision: yes
-
Referee: [§3] §3 (PackSELL Format and Bit Allocation): The paper asserts that bit allocation between delta and value fields can be chosen to maintain FP32-level accuracy without matrix-specific tuning, yet provides no quantitative error analysis, stability bounds, or ablation showing that fixed global allocations preserve accuracy across the test suite. This is load-bearing for the precision-agnostic claim.
Authors: We acknowledge that the current manuscript provides only summary accuracy comparisons in §4 and lacks a dedicated quantitative error analysis. We will revise §3 and §4 to include (i) maximum relative error versus FP32 for the fixed global allocations (e.g., 10-bit delta + 16-bit custom value) across all 22 test matrices, (ii) a short stability discussion explaining why delta encoding of indices does not amplify value errors, and (iii) an ablation table showing error for several fixed bit-width pairs. These additions will directly support the claim that a single global allocation suffices for FP32-level accuracy on the evaluated suite. revision: yes
-
Referee: [§4] §4 (Performance Evaluation): No ablation isolates the memory-traffic reduction from delta encoding versus the packing overhead itself, nor reports memory-footprint measurements on matrices with varying column-index locality. Without these, it is unclear whether the format yields net compression or merely shifts costs, directly affecting the claimed speedups.
Authors: The referee correctly notes the absence of an explicit ablation. While the manuscript reports aggregate memory-footprint reductions and performance numbers, it does not separate the contributions of delta encoding from the word-packing scheme nor stratify results by index locality. In the revision we will add (i) measured memory footprints for each matrix under PackSELL versus plain SELL, (ii) an ablation comparing delta-encoded PackSELL against a non-delta variant that uses the same packing, and (iii) a scatter plot of speedup versus average delta bit-width to show the correlation with locality. These changes will clarify the net benefit of the delta-encoding component. revision: partial
Circularity Check
No circularity: performance claims are direct empirical measurements against external baseline
full rationale
The paper introduces PackSELL as an engineering extension of SELL with delta encoding and bit-packing, then validates it solely through GPU benchmark timings and accuracy comparisons to cuSPARSE. No equations, fitted parameters, or predictions are defined in terms of the reported speedups; the 1.63× and 2.09× figures are measured quantities, not quantities that reduce by construction to the authors' own tuning constants or prior self-citations. The design is self-contained against external library baselines and does not invoke any uniqueness theorems or ansatzes that loop back to the present work.
Axiom & Free-Parameter Ledger
free parameters (1)
- bit allocation between delta and value
axioms (1)
- domain assumption Delta encoding of column indices yields net storage reduction for the target sparse matrices
Reference graph
Works this paper leans on
-
[1]
The International Journal of High Performance Computing Applications35, 4 (July 2021), 344–369
A Survey of Numerical Linear Algebra Methods Utilizing Mixed-Precision Arithmetic. The International Journal of High Performance Computing Applications35, 4 (July 2021), 344–369. doi: 10.1177/ 10943420211003313 José I. Aliaga, Hartwig Anzt, Thomas Grützmacher, Enrique S. Quintana-Ortí, and Andrés E. Tomás
2021
-
[2]
doi:10.1002/cpe.6515 Patrick Amestoy, Alfredo Buttari, Nicholas J
Compression and Load Balancing for Efficient Sparse Matrix-vector Product on Multicore Processors and Graphics Processing Units.Concurrency and Computation34, 14 (June 2022), e6515. doi:10.1002/cpe.6515 Patrick Amestoy, Alfredo Buttari, Nicholas J. Higham, Jean-Yves L’Excellent, Theo Mary, and Bastien Vieublé
-
[3]
Five-Precision GMRES-Based Iterative Refinement.SIAM J. Matrix Anal. Appl.45, 1 (March 2024), 529–552. doi:10.1137/23M1549079 Andrew Anderson and David Gregg
-
[4]
Vectorization of Multibyte Floating Point Data Formats. InProc. 2016 Int. Conf. Parallel Archit. Compil. (PACT ’16). Association for Computing Machinery, New York, NY , USA, 363–372. doi:10.1145/2967938.2967966 Hartwig Anzt, Terry Cojean, Chen Yen-Chen, Jack Dongarra, Goran Flegar, Pratik Nayak, Stanimire Tomov, Yuhsiang M. Tsai, and Weichung Wang
-
[5]
Parallel Comput.7, 1 (March 2020), 1–26
Load-Balancing Sparse Matrix Vector Product Kernels on GPUs.ACM Trans. Parallel Comput.7, 1 (March 2020), 1–26. doi:10.1145/3380930 Hartwig Anzt, Stanimire Tomov, and Jack Dongarra. 2014.Implementing a Sparse Matrix V ector Product for the SELL-C/SELL-C-σF ormats on NVIDIA GPUs. Technical Report. University of Tennessee. Arash Ashari, Naser Sedaghati, Joh...
-
[6]
Fast Sparse Matrix- Vector Multiplication on GPUs for Graph Applications. InSC14 Int. Conf. High Perform. Comput. Netw. Storage Anal.IEEE, New Orleans, LA, USA, 781–792. doi:10.1109/SC.2014.69 Richard Barrett, Michael Berry, Tony F. Chan, James Demmel, June Donato, Jack Dongarra, Victor Eijkhout, Roldan Pozo, Charles Romine, and Henk van der V orst. 1994....
-
[7]
Implementing Sparse Matrix-Vector Multiplication on Throughput-Oriented Processors. InProc. Conf. High Perform. Comput. Netw. Storage Anal. (SC ’09). Association for Computing Machinery, New York, NY , USA, 1–11. doi:10.1145/1654059.1654078 Alfredo Buttari, Jack Dongarra, Jakub Kurzak, Piotr Luszczek, and Stanimir Tomov
-
[8]
Using Mixed Precision for Sparse Matrix Computations to Enhance the Performance While Achieving 64-Bit Accuracy.ACM Trans. Math. Softw.34, 4 (July 2008), 1–22. doi:10.1145/1377596.1377597 Yanxiang Chen, Pablo De Oliveira Castro, Paolo Bientinesi, Niclas Jansson, and Roman Iakymchuk
-
[9]
Enabling Mixed-Precision in Spectral Element Codes.Future Generation Computer Systems174 (Jan. 2026), 107990. doi:10.1016/j.future.2025.107990 16 PackSELL: A Sparse Matrix Format for Precision-Agnostic High-Performance SpMVA PREPRINT Xing Cong, FuKai Sun, YiFan Chen, Chenhao Xie, Yi Liu, and Depei Qian
-
[10]
CB-SpMV:A Data Aggregating and Balance Algorithm for for Cache-Friendly Block-Based SpMV on GPUs. InProc. 39th ACM Int. Conf. Supercomput. ACM, Salt Lake City USA, 149–160. doi:10.1145/3721145.3725746 Timothy A Davis and Yifan Hu
-
[11]
The University of Florida Sparse Matrix Collection.ACM Trans. Math. Softw. 38, 1 (2011), 1–25. doi:10.1145/2049662.2049663 Jack Dongarra, Michael A Heroux, and Piotr Luszczek
-
[12]
High-Performance Conjugate-Gradient Benchmark: A New Metric for Ranking High-Performance Computing Systems.The International Journal of High Performance Computing Applications30, 1 (Feb. 2016), 3–10. doi:10.1177/1094342015593158 Salvatore Filippone, Valeria Cardellini, Davide Barbieri, and Alessandro Fanfarillo
-
[13]
Sparse Matrix-Vector Multiplication on GPGPUs.ACM Trans. Math. Softw.43, 4 (Jan. 2017), 30:1–30:49. doi:10.1145/3017994 Dimitrios Galanopoulos, Panagiotis Mpakos, Petros Anastasiadis, Nectarios Koziris, and Georgios Goumas
-
[14]
DIV: An Index & Value Compression Method for SpMV on Large Matrices. InProc. 39th ACM Int. Conf. Supercomput. ACM, Salt Lake City USA, 705–717. doi:10.1145/3721145.3725767 Jianhua Gao, Bingjie Liu, Weixing Ji, and Hua Huang
-
[15]
A Systematic Literature Survey of Sparse Matrix-Vector Multiplication. arXiv:2404.06047 [cs] doi:10.48550/arXiv.2404.06047 Stef Graillat, Fabienne Jézéquel, Théo Mary, and Roméo Molina. 2024a. Adaptive Precision Sparse Matrix–Vector Product and Its Application to Krylov Solvers.SIAM J. Sci. Comput.46, 1 (2024), C30–C56. doi: 10.1137/ 22M1522619 Stef Grail...
-
[16]
arXiv:2505.04155 [math] doi:10.48550/arXiv.2505.04155 Laslo Hunhold and James Quinlan
An Adaptive Mixed Precision and Dynamically Scaled Preconditioned Conjugate Gradient Algorithm. arXiv:2505.04155 [math] doi:10.48550/arXiv.2505.04155 Laslo Hunhold and James Quinlan
-
[17]
Evaluation of Bfloat16, Posit, and Takum Arithmetics in Sparse Linear Solvers. In2025 IEEE 32nd Symp. Comput. Arith. ARITH. IEEE, 61–68. doi: 10.1109/ARITH64983.2025.00019 Tsuyoshi Ichimura, Kohei Fujita, Takuma Yamaguchi, Akira Naruse, Jack C. Wells, Thomas C. Schulthess, Tjerk P. Straatsma, Christopher J. Zimmer, Maxime Martinasso, Kengo Nakajima, Muneo...
-
[18]
A Fast Scalable Implicit Solver for Nonlinear Time-Evolution Earthquake City Problem on Low-Ordered Unstructured Finite Elements with Artificial Intelligence and Transprecision Computing. InSC18 Int. Conf. High Perform. Comput. Netw. Storage Anal.IEEE, Dallas, TX, USA, 627–637. doi:10.1109/SC.2018.00052 Soichiro Ikuno, Yuki Kawaguchi, Norihisa Fujita, Tak...
-
[19]
Iterative Solver for Linear System Obtained by Edge Element: Variable Preconditioned Method With Mixed Precision on GPU.IEEE Trans. Magn.48, 2 (Feb. 2012), 467–470. doi:10.1109/TMAG.2011.2175375 Takeshi Iwashita, Kengo Suzuki, and Takeshi Fukaya
-
[20]
In2020 IEEEACM 11th Workshop Latest Adv
An Integer Arithmetic-Based Sparse Linear Solver Using a GMRES Method and Iterative Refinement. In2020 IEEEACM 11th Workshop Latest Adv. Scalable Algorithms Large-Scale Syst. ScalA. IEEE, 1–8. doi:10.1109/ScalA51936.2020.00006 Juan Luis Jerez, George A. Constantinides, and Eric C. Kerrigan
-
[21]
A Low Complexity Scaling Method for the Lanczos Kernel in Fixed-Point Arithmetic.IEEE Trans. Comput.64, 2 (2015), 303–315. doi:10.1109/TC.2013.162 Masatoshi Kawai and Kengo Nakajima
-
[22]
Low/Adaptive Precision Computation in Preconditioned Iterative Solvers for Ill-Conditioned Problems. InInt. Conf. High Perform. Comput. Asia-Pac. Reg. (HPCAsia ’22). Association for Computing Machinery, New York, NY , USA, 30–40. doi:10.1145/3492805.3492813 Moritz Kreutzer, Georg Hager, Gerhard Wellein, Holger Fehske, and Alan R. Bishop
-
[23]
A Unified Sparse Matrix Data Format for Efficient General Sparse Matrix-Vector Multiply on Modern Processors with Wide SIMD Units. SIAM J. Sci. Comput.36, 5 (Jan. 2014), C401–C423. arXiv:1307.6209 [cs] doi:10.1137/130930352 Neil Lindquist. 2023.Reducing Communication in the Solution of Linear Systems. Ph. D. Dissertation. The University of Tennessee, Knox...
-
[24]
Accelerating Restarted GMRES With Mixed Precision Arithmetic.IEEE Trans. Parallel Distrib. Syst.33, 4 (April 2022), 1027–1037. doi: 10.1109/TPDS.2021.3090757 Weifeng Liu and Brian Vinter
-
[25]
CSR5: An Efficient Storage Format for Cross-Platform Sparse Matrix-Vector Multiplication. InProc. 29th ACM Int. Conf. Supercomput. (ICS ’15). Association for Computing Machinery, New York, NY , USA, 339–350. doi:10.1145/2751205.2751209 17 PackSELL: A Sparse Matrix Format for Precision-Agnostic High-Performance SpMVA PREPRINT Yuechen Lu and Weifeng Liu
-
[26]
DASP: Specific Dense Matrix Multiply-Accumulate Units Accelerated General Sparse Matrix-Vector Multiplication. InProc. Int. Conf. High Perform. Comput. Netw. Storage Anal.ACM, Denver CO USA, 1–14. doi:10.1145/3581784.3607051 Marco Maggioni and Tanya Berger-Wolf
-
[27]
CoAdELL: Adaptivity and Compression for Improving Sparse Matrix- Vector Multiplication on GPUs. In2014 IEEE Int. Parallel Distrib. Process. Symp. Workshop. IEEE, 933–940. doi:10.1109/IPDPSW.2014.106 Alexander Monakov, Anton Lokhmotov, and Arutyun Avetisyan
-
[28]
doi:10.1007/978-3-642-11515-8_10 Daichi Mukunoki, Masatoshi Kawai, and Toshiyuki Imamura
Springer Berlin Heidelberg, Berlin, Heidelberg, 111–125. doi:10.1007/978-3-642-11515-8_10 Daichi Mukunoki, Masatoshi Kawai, and Toshiyuki Imamura
-
[29]
Sparse Matrix-Vector Multiplication with Reduced- Precision Memory Accessor. In2023 IEEE 16th Int. Symp. Embed. MulticoreMany-Core Syst.–Chip MCSoC. IEEE, 608–615. doi:10.1109/MCSoC60832.2023.00094 Shun Murakami, Kazunori Yoneda, Takashi Iwamura, Masahiro Watanabe, and Yasushi Inoguchi
-
[30]
doi:10.1109/ACCESS.2026.3659140 Yusuke Nagasaka, Akira Nukada, and Satoshi Matsuoka
CoD-SELL: A Non-Zero Location Dictionary Compression Sparse Matrix Format for SpMV on GPU.IEEE Access14 (2026), 17058–17068. doi:10.1109/ACCESS.2026.3659140 Yusuke Nagasaka, Akira Nukada, and Satoshi Matsuoka
-
[31]
Adaptive Multi-level Blocking Optimization for Sparse Matrix Vector Multiplication on GPU.Procedia Computer Science80 (2016), 131–142. doi: 10.1016/j.procs. 2016.05.304 Kengo Nakajima, Takseshi Ogita, and Masatoshi Kawai
-
[32]
Efficient Parallel Multigrid Methods on Manycore Clusters with Double/Single Precision Computing. In2021 IEEE Int. Parallel Distrib. Process. Symp. Workshop IPDPSW. IEEE, 760–769. doi:10.1109/IPDPSW52791.2021.00114 Yuyao Niu, Zhengyang Lu, Meichen Dong, Zhou Jin, Weifeng Liu, and Guangming Tan
-
[33]
Extending sparse tensor accelerators to support multiple compression formats,
TileSpMV: A Tiled Algorithm for Sparse Matrix-Vector Multiplication on GPUs. In2021 IEEE Int. Parallel Distrib. Process. Symp. IPDPS. IEEE, 68–78. doi:10.1109/IPDPS49936.2021.00016 Yvan Notay
-
[34]
Flexible Conjugate Gradients.SIAM J. Sci. Comput.22, 4 (Jan. 2000), 1444–1460. doi: 10.1137/ S1064827599362314 Antony Spyropoulos and Christos Antonopoulos
2000
-
[35]
doi:10.1007/s11075-025-02102-z Markus Steinberger, Rhaleb Zayer, and Hans-Peter Seidel
Numerical Study of Mixed Precision GMRES(m) Precondi- tioned by Deflation.Numer Algor101 (May 2025), 2631–2657. doi:10.1007/s11075-025-02102-z Markus Steinberger, Rhaleb Zayer, and Hans-Peter Seidel
-
[36]
Globally Homogeneous, Locally Adaptive Sparse Matrix-Vector Multiplication on the GPU. InProc. Int. Conf. Supercomput. (ICS ’17). Association for Computing Machinery, New York, NY , USA, 1–11. doi:10.1145/3079079.3079086 Kengo Suzuki. 2025.suzuki-hpc/F3R: v1.0.2. doi:10.5281/zenodo.16882405 Kengo Suzuki, Takeshi Fukaya, and Takeshi Iwashita
-
[37]
A New AINV Preconditioner for the CG Method in Hybrid CPU-GPU Computing Environment.Journal of Information Processing30, 0 (2022), 755–765. doi:
2022
-
[38]
An Integer Arithmetic-Based AMG Preconditioned FGMRES Solver.ACM Trans. Math. Softw.51, 1 (March 2025), 1:1–1:25. doi:10.1145/3704726 Kengo Suzuki and Takeshi Iwashita
-
[39]
A Nested Krylov Method Using Half-Precision Arithmetic. InProc. Int. Conf. High Perform. Comput. Netw. Storage Anal. (SC ’25). Association for Computing Machinery, New York, NY , USA, 711–727. doi:10.1145/3712285.3759807 Seth Wolfgang, Skyler Ruiter, Marc Tunnell, Timothy Triche, Erin Carrier, and Zachary DeBruine
-
[40]
Value- Compressed Sparse Column (VCSC): Sparse Matrix Storage for Single-cell Omics Data. In2024 IEEE Int. Conf. Big Data BigData. IEEE, Washington, DC, USA, 4952–4958. doi:10.1109/BigData62323.2024.10825091 Ichitaro Yamazaki, Erin Carson, and Brian Kelley. 2022a. Mixed Precision S-Step Conjugate Gradient with Residual Replacement on GPUs. In2022 IEEE Int...
-
[41]
Can Tensor Cores Benefit Memory-Bound Kernels? (NO!). InProc. 17th Workshop Gen. Purp. Process. Using GPU (GPGPU ’25). Association for Computing Machinery, New York, NY , USA, 28–34. doi:10.1145/3725798.3725803 Yingqi Zhao, Takeshi Fukaya, and Takeshi Iwashita
-
[42]
Numerical Behavior of Mixed Precision Iterative Refinement Using the BiCGSTAB Method.Journal of Information Processing31 (2023), 860–874. doi: 10.2197/ipsjjip.31. 860 Yingqi Zhao, Takeshi Fukaya, Linjie Zhang, and Takeshi Iwashita
-
[43]
Numerical Investigation into the Mixed Precision GMRES(m) Method Using FP64 and FP32.J. Inf. Process.30 (2022), 525–537. doi: 10.2197/ipsjjip. 30.525 19
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.