Recognition: unknown
A Study of Failure Modes in Two-Stage Human-Object Interaction Detection
Pith reviewed 2026-05-10 14:32 UTC · model grok-4.3
The pith
Organizing HOI images by interaction configurations shows two-stage models lack robust visual reasoning despite strong benchmark scores.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By curating images from an existing HOI dataset and organizing them according to human-object-interaction configurations, the study identifies distinct failure patterns in two-stage models and establishes that high overall benchmark performance does not necessarily reflect robust visual reasoning about human-object relationships.
What carries the argument
Configuration-based grouping of images combined with decomposition of HOI detection into multiple interpretable perspectives for measuring model behavior across scene compositions.
If this is right
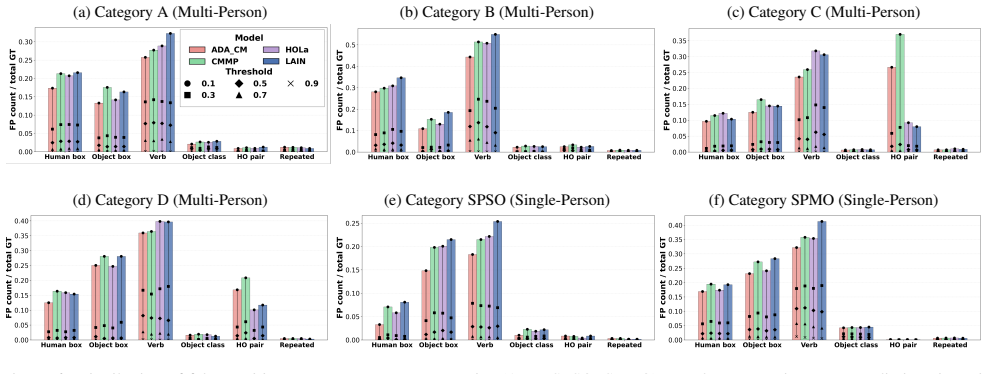
- Two-stage models exhibit increased errors on scenes with multiple people interacting simultaneously.
- Rare human-object interaction combinations produce systematic prediction failures not visible in aggregate metrics.
- Object sharing among humans triggers specific confusion patterns in detection outputs.
- Overall benchmark accuracy alone is insufficient to certify reliable HOI reasoning in varied scene compositions.
Where Pith is reading between the lines
- New evaluation protocols could require explicit reporting on these configuration groups to expose hidden weaknesses.
- Architectural changes that add explicit multi-agent relational modules might address the observed failure patterns.
- The same grouping method could transfer to other compositional vision tasks where averages obscure specific breakdowns.
Load-bearing premise
That grouping images by human-object-interaction configurations and measuring model behavior across those groups will reveal the underlying causes of prediction failures.
What would settle it
Re-evaluating the same two-stage models on the configuration-organized image subsets and finding no consistent performance drops or distinct failure patterns tied to multi-person or rare-interaction groups would falsify the identified modes.
Figures







read the original abstract
Human-object interaction (HOI) detection aims to detect interactions between humans and objects in images. While recent advances have improved performance on existing benchmarks, their evaluations mainly focus on overall prediction accuracy and provide limited insight into the underlying causes of model failures. In particular, modern models often struggle in complex scenes involving multiple people and rare interaction combinations. In this work, we present a study to better understand the failure modes of two-stage HOI models, which form the basis of many current HOI detection approaches. Rather than constructing a large-scale benchmark, we instead decompose HOI detection into multiple interpretable perspectives and analyze model behavior across these dimensions to study different types of failure patterns. We curate a subset of images from an existing HOI dataset organized by human-object-interaction configurations (e.g., multi-person interactions and object sharing), and analyze model behavior under these configurations to examine different failure modes. This design allows us to analyze how these HOI models behave under different scene compositions and why their predictions fail. Importantly, high overall benchmark performance does not necessarily reflect robust visual reasoning about human-object relationships. We hope that this study can provide useful insights into the limitations of HOI models and offer observations for future research in this area.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents an empirical study of failure modes in two-stage human-object interaction (HOI) detection models. The authors curate subsets from existing HOI datasets organized by interpretable configurations such as multi-person interactions and object sharing, then analyze model behavior across these dimensions to identify specific failure patterns. The central claim is that high overall benchmark performance does not necessarily reflect robust visual reasoning about human-object relationships.
Significance. If the observations hold after addressing potential confounds, the work supplies targeted diagnostic insights into why two-stage HOI models struggle with complex scene compositions. The strength of the approach lies in its decomposition into multiple interpretable perspectives for pattern discovery rather than a new large-scale benchmark or fitted model; this is a constructive contribution that could guide more informative evaluation protocols.
major comments (2)
- [§3 (Curation of Subsets)] §3 (Curation of Subsets): The paper organizes images by HOI configurations (multi-person, object sharing) but does not describe matching, stratification, or regression to control for confounders such as interaction rarity in the training set, object co-occurrence statistics, or scene density. Failures observed in these groups could therefore arise from data imbalance rather than deficient reasoning about relationships, which directly undermines the load-bearing claim that high benchmark performance fails to indicate robust visual reasoning.
- [§4 (Model Analysis and Results)] §4 (Model Analysis and Results): The analysis relies on qualitative examples of prediction failures across configurations but supplies no quantitative metrics (e.g., per-configuration mAP, error-type breakdowns, or statistical comparisons against baseline difficulty). Without these, the prevalence and specificity of the identified failure modes remain unclear, weakening support for the central claim.
minor comments (2)
- [Abstract] Abstract: The abstract states that the study examines 'why their predictions fail' but does not name the specific two-stage models evaluated or provide even one illustrative quantitative performance drop.
- [§2 (Related Work)] §2 (Related Work): Additional references to prior empirical analyses of HOI model failures would help situate the contribution.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. The comments highlight important aspects of experimental design and analysis that will strengthen the presentation of our diagnostic study. We address each major comment point by point below.
read point-by-point responses
-
Referee: §3 (Curation of Subsets): The paper organizes images by HOI configurations (multi-person, object sharing) but does not describe matching, stratification, or regression to control for confounders such as interaction rarity in the training set, object co-occurrence statistics, or scene density. Failures observed in these groups could therefore arise from data imbalance rather than deficient reasoning about relationships, which directly undermines the load-bearing claim that high benchmark performance fails to indicate robust visual reasoning.
Authors: We agree that potential confounds such as interaction rarity and object co-occurrence must be considered when interpreting failures. Our curation isolates specific scene configurations (e.g., multi-person and object-sharing) that are underrepresented or challenging in aggregate benchmarks, and the observed failure patterns are consistent across multiple two-stage models. While we did not perform explicit matching or regression controls, the study’s aim is to surface configuration-specific behaviors that overall mAP obscures, rather than to claim purely causal reasoning deficits. In the revision we will add a dedicated paragraph in §3 describing the rarity and co-occurrence statistics of the curated subsets relative to the full dataset and will explicitly qualify our claims to note that data imbalance may contribute to the observed failures. revision: partial
-
Referee: §4 (Model Analysis and Results): The analysis relies on qualitative examples of prediction failures across configurations but supplies no quantitative metrics (e.g., per-configuration mAP, error-type breakdowns, or statistical comparisons against baseline difficulty). Without these, the prevalence and specificity of the identified failure modes remain unclear, weakening support for the central claim.
Authors: We acknowledge that the current §4 relies primarily on qualitative illustrations. To provide a more rigorous quantification of the failure modes, the revised manuscript will include per-configuration mAP breakdowns for the evaluated models, a categorization of error types (e.g., human/object detection errors versus interaction classification errors), and direct comparisons of performance on the curated subsets versus the full test set. These additions will clarify both the prevalence and the specificity of the patterns we report. revision: yes
Circularity Check
No circularity: purely empirical observational study
full rationale
The paper conducts an empirical analysis by curating image subsets from prior HOI datasets and measuring model behavior across human-object-interaction configurations. No equations, derivations, fitted parameters, or predictions are present that could reduce to inputs by construction. Central claims rest on direct observation of failure patterns rather than any self-referential logic, self-citation chains, or ansatz smuggling. This is a standard non-circular empirical study.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2. 5-vl technical report.arXiv preprint arXiv:2502.13923, 2025. 1
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Learning to detect human-object interactions
Yu-Wei Chao, Yunfan Liu, Xieyang Liu, Huayi Zeng, and Jia Deng. Learning to detect human-object interactions. In2018 ieee winter conference on applications of computer vision (wacv), pages 381–389. IEEE, 2018. 2
2018
-
[3]
Learning to detect human-object interactions
Yu-Wei Chao, Yunfan Liu, Xieyang Liu, Huayi Zeng, and Jia Deng. Learning to detect human-object interactions. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision, 2018. 1, 2, 3
2018
-
[4]
Human–robot in- teraction: a survey.Foundations and trends® in human– computer interaction, 1(3):203–275, 2008
Michael A Goodrich and Alan C Schultz. Human–robot in- teraction: a survey.Foundations and trends® in human– computer interaction, 1(3):203–275, 2008. 1
2008
-
[5]
Visual semantic role la- beling
Saurabh Gupta and Jitendra Malik. Visual semantic role la- beling.arXiv preprint arXiv:1505.04474, 2015. 1, 3
-
[6]
Learn- ing human-object interaction as groups.arXiv preprint arXiv:2510.18357, 2025
Jiajun Hong, Jianan Wei, and Wenguan Wang. Learn- ing human-object interaction as groups.arXiv preprint arXiv:2510.18357, 2025. 2
-
[7]
Vi- sual compositional learning for human-object interaction de- tection
Zhi Hou, Xiaojiang Peng, Yu Qiao, and Dacheng Tao. Vi- sual compositional learning for human-object interaction de- tection. InComputer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceed- ings, Part XV 16, pages 584–600. Springer, 2020. 2
2020
-
[8]
Detecting human-object interaction via fab- ricated compositional learning
Zhi Hou, Baosheng Yu, Yu Qiao, Xiaojiang Peng, and Dacheng Tao. Detecting human-object interaction via fab- ricated compositional learning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14646–14655, 2021. 2
2021
-
[9]
Relational context learning for human-object interaction detection
Sanghyun Kim, Deunsol Jung, and Minsu Cho. Relational context learning for human-object interaction detection. In Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition, pages 2925–2934, 2023. 2
2023
-
[10]
Locality- aware zero-shot human-object interaction detection
Sanghyun Kim, Deunsol Jung, and Minsu Cho. Locality- aware zero-shot human-object interaction detection. InPro- ceedings of the Computer Vision and Pattern Recognition Conference, pages 20190–20200, 2025. 5, 7
2025
-
[11]
Qinqian Lei, Bo Wang, and Robby T. Tan. Ez-hoi: Vlm adaptation via guided prompt learning for zero-shot hoi de- tection. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. 2
2024
-
[12]
Hola: Zero-shot hoi detection with low-rank decomposed vlm feature adapta- tion
Qinqian Lei, Bo Wang, and Tan Robby T. Hola: Zero-shot hoi detection with low-rank decomposed vlm feature adapta- tion. InIn Proceedings of the IEEE/CVF international con- ference on computer vision, 2025. 5, 7
2025
-
[13]
Qinqian Lei, Bo Wang, and Robby T. Tan. Crosshoi- bench: A unified benchmark for hoi evaluation across vision- language models and hoi-specific methods. InProceedings of the IEEE/CVF Conference on Computer Vision and Pat- tern Recognition (CVPR), 2026. 1, 2, 3
2026
-
[14]
Efficient adaptive human-object interac- tion detection with concept-guided memory
Ting Lei, Fabian Caba, Qingchao Chen, Hailin Jin, Yuxin Peng, and Yang Liu. Efficient adaptive human-object interac- tion detection with concept-guided memory. InProceedings of the IEEE/CVF International Conference on Computer Vi- sion, pages 6480–6490, 2023. 2, 5
2023
-
[15]
Explor- ing conditional multi-modal prompts for zero-shot hoi de- tection
Ting Lei, Shaofeng Yin, Yuxin Peng, and Yang Liu. Explor- ing conditional multi-modal prompts for zero-shot hoi de- tection. InEuropean Conference on Computer Vision, pages 1–19. Springer, 2024. 2, 5
2024
-
[16]
Blip: Bootstrapping language-image pre-training for uni- fied vision-language understanding and generation
Junnan Li, Dongxu Li, Caiming Xiong, and Steven Hoi. Blip: Bootstrapping language-image pre-training for uni- fied vision-language understanding and generation. InIn- ternational Conference on Machine Learning, pages 12888– 12900. PMLR, 2022. 1
2022
-
[17]
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models.arXiv preprint arXiv:2301.12597, 2023. 1
work page internal anchor Pith review arXiv 2023
-
[18]
Neural- logic human-object interaction detection.Advances in Neu- ral Information Processing Systems, 36, 2024
Liulei Li, Jianan Wei, Wenguan Wang, and Yi Yang. Neural- logic human-object interaction detection.Advances in Neu- ral Information Processing Systems, 36, 2024. 2
2024
-
[19]
Gen-vlkt: Simplify association and enhance interaction understanding for hoi detection
Yue Liao, Aixi Zhang, Miao Lu, Yongliang Wang, Xiaobo Li, and Si Liu. Gen-vlkt: Simplify association and enhance interaction understanding for hoi detection. InProceedings of the IEEE/CVF Conference on Computer Vision and Pat- tern Recognition (CVPR), pages 20123–20132, 2022. 2
2022
-
[20]
Microsoft coco: Common objects in context
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Doll´ar, and C Lawrence Zitnick. Microsoft coco: Common objects in context. In Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part V 13, pages 740–755. Springer, 2014. 2
2014
-
[21]
Visual instruction tuning.Advances in neural information processing systems, 36, 2024
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.Advances in neural information processing systems, 36, 2024. 1
2024
-
[22]
Interactiveness field in human- object interactions
Xinpeng Liu, Yong-Lu Li, Xiaoqian Wu, Yu-Wing Tai, Cewu Lu, and Chi-Keung Tang. Interactiveness field in human- object interactions. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 20113–20122, 2022. 2
2022
-
[23]
Clip4hoi: Towards adapting clip for practi- cal zero-shot hoi detection.Advances in Neural Information Processing Systems, 36, 2024
Yunyao Mao, Jiajun Deng, Wengang Zhou, Li Li, Yao Fang, and Houqiang Li. Clip4hoi: Towards adapting clip for practi- cal zero-shot hoi detection.Advances in Neural Information Processing Systems, 36, 2024. 2
2024
-
[24]
Hoiclip: Efficient knowledge transfer for hoi detection with vision-language models
Shan Ning, Longtian Qiu, Yongfei Liu, and Xuming He. Hoiclip: Efficient knowledge transfer for hoi detection with vision-language models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 23507–23517, 2023. 2
2023
-
[25]
Shoe: Semantic hoi open-vocabulary evaluation metric.arXiv preprint arXiv:2604.01586, 2026
Maja Noack, Qinqian Lei, Taipeng Tian, Bihan Dong, Robby T Tan, Yixin Chen, John Young, Saijun Zhang, and Bo Wang. Shoe: Semantic hoi open-vocabulary evaluation metric.arXiv preprint arXiv:2604.01586, 2026. 2
-
[26]
Viplo: Vision transformer based pose-conditioned self-loop graph for human-object interaction detection
Jeeseung Park, Jin-Woo Park, and Jong-Seok Lee. Viplo: Vision transformer based pose-conditioned self-loop graph for human-object interaction detection. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 17152–17162, 2023. 2
2023
-
[27]
Distillation using oracle queries for transformer-based human-object interaction detection
Xian Qu, Changxing Ding, Xingao Li, Xubin Zhong, and Dacheng Tao. Distillation using oracle queries for transformer-based human-object interaction detection. In Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition, pages 19558–19567, 2022. 2
2022
-
[28]
Learning transferable visual models from natural language supervi- sion
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervi- sion. InInternational conference on machine learning, pages 8748–8763. PMLR, 2021. 1
2021
-
[29]
Discovering human interac- tions with large-vocabulary objects via query and multi-scale detection
Suchen Wang, Kim-Hui Yap, Henghui Ding, Jiyan Wu, Jun- song Yuan, and Yap-Peng Tan. Discovering human interac- tions with large-vocabulary objects via query and multi-scale detection. In2021 IEEE/CVF International Conference on Computer Vision (ICCV), pages 13455–13464, 2021. 1, 3
2021
-
[30]
Learning transferable human-object interaction detector with natural language su- pervision
Suchen Wang, Yueqi Duan, Henghui Ding, Yap-Peng Tan, Kim-Hui Yap, and Junsong Yuan. Learning transferable human-object interaction detector with natural language su- pervision. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 939–948,
-
[31]
End-to-end zero-shot hoi detec- tion via vision and language knowledge distillation
Mingrui Wu, Jiaxin Gu, Yunhang Shen, Mingbao Lin, Chao Chen, and Xiaoshuai Sun. End-to-end zero-shot hoi detec- tion via vision and language knowledge distillation. InPro- ceedings of the AAAI Conference on Artificial Intelligence, pages 2839–2846, 2023. 2
2023
-
[32]
Bangpeng Yao and Li Fei-Fei. Recognizing human-object interactions in still images by modeling the mutual context of objects and human poses.IEEE transactions on pattern analysis and machine intelligence, 34(9):1691–1703, 2012. 1
2012
-
[33]
Spatially conditioned graphs for detecting human-object in- teractions
Frederic Z Zhang, Dylan Campbell, and Stephen Gould. Spatially conditioned graphs for detecting human-object in- teractions. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 13319–13327, 2021. 2
2021
-
[34]
Efficient two-stage detection of human-object interactions with a novel unary-pairwise transformer
Frederic Z Zhang, Dylan Campbell, and Stephen Gould. Efficient two-stage detection of human-object interactions with a novel unary-pairwise transformer. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 20104–20112, 2022
2022
-
[35]
Exploring predicate visual con- text in detecting of human-object interactions
Frederic Z Zhang, Yuhui Yuan, Dylan Campbell, Zhuoyao Zhong, and Stephen Gould. Exploring predicate visual con- text in detecting of human-object interactions. InProceed- ings of the IEEE/CVF International Conference on Com- puter Vision, pages 10411–10421, 2023. 2
2023
-
[36]
End-to-end human object interaction detection with hoi transformer
Cheng Zou, Bohan Wang, Yue Hu, Junqi Liu, Qian Wu, Yu Zhao, Boxun Li, Chenguang Zhang, Chi Zhang, Yichen Wei, et al. End-to-end human object interaction detection with hoi transformer. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11825– 11834, 2021. 2
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.