Recognition: unknown
From Relevance to Authority: Authority-aware Generative Retrieval in Web Search Engines
Pith reviewed 2026-05-10 13:04 UTC · model grok-4.3
The pith
Authority-aware generative retriever improves both accuracy and trustworthiness in web search.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
AuthGR is the first framework to incorporate authority into generative information retrieval by combining multimodal authority scoring from a vision-language model, a three-stage training pipeline that progressively instills authority awareness, and a hybrid ensemble pipeline, yielding simultaneous gains in authority and accuracy with offline parity between 3B and 14B models and confirmed real-world improvements via online A/B tests.
What carries the argument
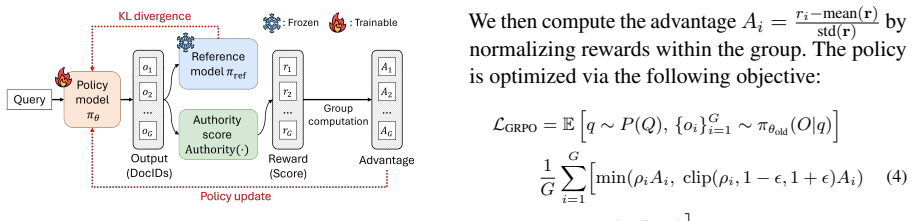
Multimodal Authority Scoring that quantifies document authority from textual and visual cues via a vision-language model, together with a Three-stage Training Pipeline and Hybrid Ensemble Pipeline.
If this is right
- A 3B-parameter generative retriever can match the authority and accuracy performance of a 14B baseline.
- Large-scale online deployment on commercial search platforms yields measurable gains in user engagement and reliability.
- High-stakes queries in healthcare and finance can be served with reduced risk of unreliable content.
- Authority can be treated as a first-class optimization target alongside relevance in generative retrieval.
Where Pith is reading between the lines
- The same staged-training approach could be applied to other trustworthiness signals such as recency or source reputation.
- Human evaluation protocols for retrieval may need to expand beyond relevance to include explicit authority judgments.
- Smaller models augmented with authority awareness could lower inference costs while maintaining or improving output quality in production search systems.
Load-bearing premise
Authority can be reliably quantified from textual and visual cues by a vision-language model without introducing new selection biases or diverging from actual user trust.
What would settle it
An independent expert rating study of document trustworthiness that shows low correlation with the model's authority scores, or an A/B test where authority-aware results produce no measurable lift in user-reported reliability or engagement.
Figures







read the original abstract
Generative information retrieval (GenIR) formulates the retrieval process as a text-to-text generation task, leveraging the vast knowledge of large language models. However, existing works primarily optimize for relevance while often overlooking document trustworthiness. This is critical in high-stakes domains like healthcare and finance, where relying solely on semantic relevance risks retrieving unreliable information. To address this, we propose an Authority-aware Generative Retriever (AuthGR), the first framework that incorporates authority into GenIR. AuthGR consists of three key components: (i) Multimodal Authority Scoring, which employs a vision-language model to quantify authority from textual and visual cues; (ii) a Three-stage Training Pipeline to progressively instill authority awareness into the retriever; and (iii) a Hybrid Ensemble Pipeline for robust deployment. Offline evaluations demonstrate that AuthGR successfully enhances both authority and accuracy, with our 3B model matching a 14B baseline. Crucially, large-scale online A/B tests and human evaluations conducted on the commercial web search platform confirm significant improvements in real-world user engagement and reliability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes AuthGR, the first authority-aware generative retriever for web search. It introduces three components: (i) Multimodal Authority Scoring via a vision-language model that quantifies authority from textual and visual cues, (ii) a three-stage training pipeline to instill authority awareness, and (iii) a hybrid ensemble for deployment. Offline results claim that a 3B model matches a 14B baseline in both authority and accuracy; large-scale online A/B tests and human evaluations on a commercial platform are said to confirm gains in user engagement and reliability.
Significance. If the authority scores validly capture trustworthiness rather than surface proxies, the work would meaningfully extend GenIR beyond relevance-only optimization, with particular value in high-stakes domains. The reported parameter efficiency (3B matching 14B) and real-world A/B validation would be notable strengths.
major comments (3)
- [Multimodal Authority Scoring] The Multimodal Authority Scoring component (described in the abstract and presumably §3) relies on VLM judgments of textual/visual cues to produce authority scores that drive training and retrieval. No ground-truth labeling procedure, expert validation set, inter-annotator agreement, or correlation with external authority signals (e.g., fact-checking databases or domain-expert ratings) is reported. Without such anchoring, it is unclear whether the scores reflect genuine credibility or optimize for proxies such as layout professionalism or image quality; this directly undermines the central claim that AuthGR improves reliability.
- [Offline Evaluations] Offline evaluations claim that the 3B AuthGR model matches a 14B baseline in authority and accuracy. No concrete metrics (e.g., authority precision, NDCG, or authority-augmented relevance scores), baseline models, statistical tests, confidence intervals, or exclusion criteria are supplied. This absence prevents assessment of whether the efficiency claim is load-bearing or merely suggestive.
- [Online A/B Tests and Human Evaluations] The online A/B tests and human evaluations are presented as confirming significant improvements in user engagement and reliability. No details on sample size, effect sizes, p-values, primary metrics, or controls for confounding factors (e.g., position bias, query distribution) are given, leaving the real-world impact claim unsupported by the reported evidence.
minor comments (1)
- [Abstract] The abstract would be strengthened by including at least one or two key quantitative results (e.g., the exact authority or relevance delta) rather than qualitative statements of improvement.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We appreciate the emphasis on rigorous validation and experimental details. We will revise the paper to incorporate additional descriptions, metrics, and clarifications as outlined below.
read point-by-point responses
-
Referee: [Multimodal Authority Scoring] The Multimodal Authority Scoring component (described in the abstract and presumably §3) relies on VLM judgments of textual/visual cues to produce authority scores that drive training and retrieval. No ground-truth labeling procedure, expert validation set, inter-annotator agreement, or correlation with external authority signals (e.g., fact-checking databases or domain-expert ratings) is reported. Without such anchoring, it is unclear whether the scores reflect genuine credibility or optimize for proxies such as layout professionalism or image quality; this directly undermines the central claim that AuthGR improves reliability.
Authors: We acknowledge that the current manuscript does not include a dedicated validation subsection for the authority scores. In the revision we will add a detailed description of the VLM prompting strategy, any internal consistency checks performed during scoring, and correlations between the resulting authority scores and available platform signals such as domain-level engagement and known high-trust sources. While we do not possess a newly collected expert-annotated validation set, we will report how the scores align with downstream user metrics in high-stakes query categories to help distinguish credibility signals from superficial proxies. revision: yes
-
Referee: [Offline Evaluations] Offline evaluations claim that the 3B AuthGR model matches a 14B baseline in authority and accuracy. No concrete metrics (e.g., authority precision, NDCG, or authority-augmented relevance scores), baseline models, statistical tests, confidence intervals, or exclusion criteria are supplied. This absence prevents assessment of whether the efficiency claim is load-bearing or merely suggestive.
Authors: We agree that the offline results section lacks sufficient quantitative detail. The revised manuscript will include explicit metrics (authority precision@K, NDCG@K, and combined authority-relevance scores), the precise baseline configurations (including the 14B model architecture and training), statistical tests with p-values, confidence intervals, and any query filtering criteria applied. Numerical tables will be added to substantiate the claim that the 3B model matches the 14B baseline. revision: yes
-
Referee: [Online A/B Tests and Human Evaluations] The online A/B tests and human evaluations are presented as confirming significant improvements in user engagement and reliability. No details on sample size, effect sizes, p-values, primary metrics, or controls for confounding factors (e.g., position bias, query distribution) are given, leaving the real-world impact claim unsupported by the reported evidence.
Authors: We recognize that the online and human evaluation sections are underspecified. In the revision we will report sample sizes (queries and users), effect sizes, p-values, primary metrics (CTR, dwell time, authority-related engagement), and the controls used for position bias and query distribution. For the human evaluations we will add annotation guidelines, inter-annotator agreement statistics, and how reliability was measured. These additions will provide the requested evidentiary support. revision: yes
Circularity Check
No circularity in framework proposal or evaluations
full rationale
The paper introduces AuthGR as a new engineering framework with three explicit components (multimodal VLM-based authority scoring, staged training pipeline, hybrid ensemble) whose definitions and interactions are stated independently rather than derived from one another. No equations or predictions are presented that reduce by construction to fitted parameters or self-referential inputs. Offline and online A/B results are reported as empirical measurements on held-out data and live traffic, not as outputs forced by the model's own training objectives. Self-citations, if present, are not load-bearing for the core claims. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Pinrec: Outcome-conditioned, multi-token generative retrieval for industry-scale recommenda- tion systems.CoRR, abs/2504.10507. Michele Bevilacqua, Giuseppe Ottaviano, Patrick S. H. Lewis, Scott Yih, Sebastian Riedel, and Fabio Petroni
-
[2]
InNeurIPS
Autoregressive search engines: Generating substrings as document identifiers. InNeurIPS. Sergey Brin and Lawrence Page. 1998. The anatomy of a large-scale hypertextual web search engine.Com- put. Networks, 30(1-7):107–117. Nicola De Cao, Gautier Izacard, Sebastian Riedel, and Fabio Petroni. 2021. Autoregressive entity retrieval. InICLR. Jiangui Chen, Ruqi...
1998
-
[3]
In SIGIR, pages 1448–1457
A unified generative retriever for knowledge- intensive language tasks via prompt learning. In SIGIR, pages 1448–1457. Jiangui Chen, Ruqing Zhang, Jiafeng Guo, Yiqun Liu, Yixing Fan, and Xueqi Cheng. 2022. Corpusbrain: Pre-train a generative retrieval model for knowledge- intensive language tasks. InCIKM, pages 191–200. Wei Chen, Yixin Ji, Zeyuan Chen, Ji...
2022
-
[4]
OneRec: Unifying Retrieve and Rank with Generative Recommender and Iterative Preference Alignment
Onerec: Unifying retrieve and rank with gen- erative recommender and iterative preference align- ment.CoRR, abs/2502.18965. Xin Luna Dong, Evgeniy Gabrilovich, Kevin Murphy, Van Dang, Wilko Horn, Camillo Lugaresi, Shaohua Sun, and Wei Zhang. 2015. Knowledge-based trust: Estimating the trustworthiness of web sources.Proc. VLDB Endow., 8(9):938–949. Abhiman...
work page internal anchor Pith review arXiv 2015
-
[5]
REINFORCE++: Stabilizing Critic-Free Policy Optimization with Global Advantage Normalization
Reinforce++: A simple and efficient ap- proach for aligning large language models.CoRR, abs/2501.03262. Aaron Hurst, Adam Lerer, Adam P. Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Os- trow, Akila Welihinda, Alan Hayes, Alec Radford, and 1 others. 2024. Gpt-4o system card.CoRR, abs/2410.21276. Clark Mingxuan Ju, Liam Collins, Leonardo Neves, Bh...
work page internal anchor Pith review arXiv 2024
-
[6]
Deepseek-v3 technical report.arXiv preprint arXiv: 2412.19437. Kidist Amde Mekonnen, Yubao Tang, and Maarten de Rijke. 2025. Lightweight and direct document relevance optimization for generative information re- trieval. InSIGIR, pages 1327–1338. Meta AI. 2025. The Llama 4 herd: The beginning of a new era of natively multimodal AI innovation. http s://ai.a...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Rethinking search: making domain experts out of dilettantes.SIGIR Forum, 55(1):13:1–13:27. NA VER Cloud. 2025. Hyperclova x think technical report.arXiv preprint arXiv: 2506.22403. Ming Pang, Chunyuan Yuan, Xiaoyu He, Zheng Fang, Donghao Xie, Fanyi Qu, Xue Jiang, Changping Peng, Zhangang Lin, Zheng Luo, and Jingping Shao. 2025. Generative retrieval and al...
-
[8]
Learning to tokenize for generative retrieval. InNeurIPS. Yi Tay, Vinh Tran, Mostafa Dehghani, Jianmo Ni, Dara Bahri, Harsh Mehta, Zhen Qin, Kai Hui, Zhe Zhao, Jai Prakash Gupta, Tal Schuster, William W. Cohen, and Donald Metzler. 2022. Transformer memory as a differentiable search index. InNeurIPS, pages 21831–21843. Yujing Wang, Yingyan Hou, Haonan Wang...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[9]
url": "",
Adapting large language models by integrat- ing collaborative semantics for recommendation. In ICDE, pages 1435–1448. Yujia Zhou, Zhicheng Dou, and Ji-Rong Wen. 2023. Enhancing generative retrieval with reinforcement learning from relevance feedback. InEMNLP, pages 12481–12490. Yujia Zhou, Jing Yao, Zhicheng Dou, Ledell Wu, Peitian Zhang, and Ji-Rong Wen....
2023
-
[10]
and URLs (Zhou et al., 2022; Chen et al., 2022), various DocIDs have been explored to bridge the gap between identifiers and document semantics. These include N-grams for substring- based retrieval (Cao et al., 2021; Bevilacqua et al., 2022; Chen et al., 2023), or hierarchical code- books (Zhang et al., 2023; Zeng et al., 2024a,b). Optimization and Learni...
2022
-
[11]
The website must be a trustworthy domain (e.g., .gov, .edu, official institutions, etc.)
-
[12]
Generate a website that contains appropriate in- formation to fulfill the user’s request
-
[13]
The output should only include the website
-
[14]
Even if the input is incomplete, analyze the user’s intent to generate the most suitable website
-
[15]
Which result is better overall?
If no suitable website is found, return an empty output. Input: - Query:{query} Output: - Site:[Website URL ID] Figure 7: Prompts used for the SFT stage. The {query} field is a placeholder for the user query. CLOVAX-SEED-Text-Instruct-0.5B, naver-hyperclovax/HyperCLOVAX-SEED-Tex t-Instruct-1.5B,naver-hyperclovax/Hyp erCLOVAX-SEED-Think-14B •LLaMA 3.2: met...
-
[16]
Which result is better overall?
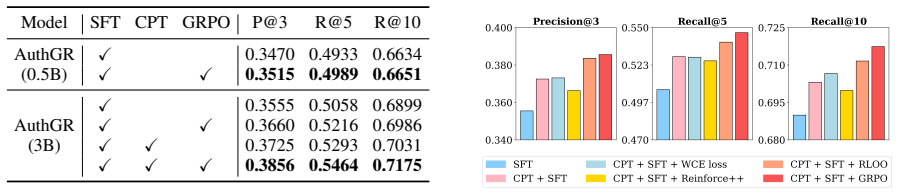
and GRPO-Linear (using raw scores). The Lin- ear formulation proves most effective, achieving 7.1% gain in Recall over the baseline and increased average confidence. This confirms that fine-grained linear rewards provide superior calibration com- pared to coarse binary signals, enabling the model to retrieve ground-truth documents with greater confidence....
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.