Recognition: unknown
RiskWebWorld: A Realistic Interactive Benchmark for GUI Agents in E-commerce Risk Management
Pith reviewed 2026-05-10 13:38 UTC · model grok-4.3
The pith
RiskWebWorld benchmark shows top generalist models reach 49.1 percent success on e-commerce risk tasks where specialized GUI agents fail nearly completely.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
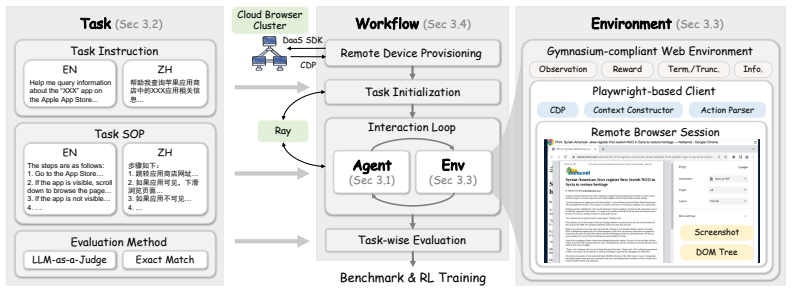
We present RiskWebWorld, the first highly realistic interactive benchmark for evaluating GUI agents in e-commerce risk management. RiskWebWorld features 1,513 tasks sourced from production risk-control pipelines across 8 core domains, and captures the authentic challenges of risk operations on uncooperative websites, partially environmental hijackments. Our evaluation across diverse models reveals a dramatic capability gap: top-tier generalist models achieve 49.1% success, while specialized open-weights GUI models lag at near-total failure. This highlights that foundation model scale currently matters more than zero-shot interface grounding in long-horizon professional tasks. We also show an
What carries the argument
RiskWebWorld benchmark of 1,513 production-sourced tasks together with its Gymnasium-compliant infrastructure that separates policy planning from environment mechanics to enable scalable evaluation and agentic reinforcement learning.
Load-bearing premise
The 1,513 tasks drawn from production pipelines accurately reflect the real difficulties of risk management on uncooperative websites and partially hijacked environments.
What would settle it
A direct comparison where the same agents are run on live production risk systems and their success rates are measured against the 49.1 percent benchmark score.
Figures










read the original abstract
Graphical User Interface (GUI) agents show strong capabilities for automating web tasks, but existing interactive benchmarks primarily target benign, predictable consumer environments. Their effectiveness in high-stakes, investigative domains such as authentic e-commerce risk management remains underexplored. To bridge this gap, we present RiskWebWorld, the first highly realistic interactive benchmark for evaluating GUI agents in e-commerce risk management. RiskWebWorld features 1,513 tasks sourced from production risk-control pipelines across 8 core domains, and captures the authentic challenges of risk operations on uncooperative websites, partially environmental hijackments. To support scalable evaluation and agentic reinforcement learning (RL), we further build a Gymnasium-compliant infrastructure that decouples policy planning from environment mechanics. Our evaluation across diverse models reveals a dramatic capability gap: top-tier generalist models achieve 49.1% success, while specialized open-weights GUI models lag at near-total failure. This highlights that foundation model scale currently matters more than zero-shot interface grounding in long-horizon professional tasks. We also demonstrate the viability of our infrastructure through agentic RL, which improves open-source models by 16.2%. These results position RiskWebWorld as a practical testbed for developing robust digital workers.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces RiskWebWorld, the first highly realistic interactive benchmark for GUI agents in e-commerce risk management. It comprises 1,513 tasks sourced from production risk-control pipelines across 8 core domains, simulating uncooperative websites and partial environmental hijackments (e.g., injected pop-ups, altered DOM states, session timeouts). A Gymnasium-compliant infrastructure decouples policy planning from mechanics to enable scalable evaluation and agentic RL. Evaluations show top-tier generalist models achieving 49.1% success while specialized open-weights GUI models fail near-totally; agentic RL improves open-source models by 16.2%.
Significance. If the production-sourced task curation and hijackment simulations hold, the benchmark fills a critical gap by moving GUI agent evaluation from benign consumer tasks to high-stakes professional domains. It provides concrete evidence that foundation-model scale outperforms zero-shot interface grounding in long-horizon risk operations and demonstrates a viable RL training loop via the Gymnasium wrapper. The explicit decoupling of planning and mechanics, together with the reported numerical gaps, makes the work a practical, falsifiable testbed for robust digital workers.
major comments (1)
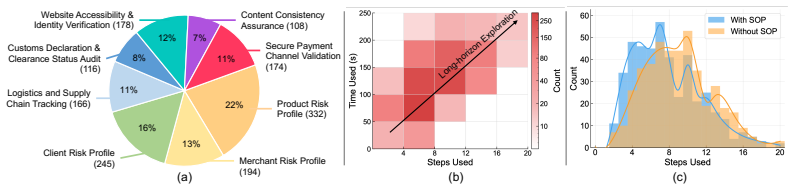
- [Methods] Methods (task curation subsection): The claim that the 1,513 tasks 'accurately capture the authentic challenges' rests on sourcing from production pipelines, but the manuscript provides only high-level description of domain coverage and hijackment injection without quantitative metrics (e.g., distribution of hijackment types, inter-task difficulty calibration, or inter-rater agreement on realism). This is load-bearing for the central realism claim and the interpretation of the 49.1% vs. near-zero gap.
minor comments (3)
- [Abstract] Abstract: 'partially environmental hijackments' is grammatically awkward and should be clarified as 'partial environmental hijackments' or expanded with a parenthetical example.
- [Evaluation] Evaluation section: Success rates are reported without error bars, number of evaluation episodes per model, or statistical significance tests; adding these would improve reproducibility of the 49.1% and +16.2% figures.
- [Infrastructure] Infrastructure description: The Gymnasium wrapper is presented as decoupling planning from mechanics, but no pseudocode or interface signature is given; a short listing of the key observation/action spaces would aid readers implementing their own agents.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation and the constructive comment on strengthening the quantitative support for our realism claims. We address the point below and have revised the manuscript accordingly.
read point-by-point responses
-
Referee: [Methods] Methods (task curation subsection): The claim that the 1,513 tasks 'accurately capture the authentic challenges' rests on sourcing from production pipelines, but the manuscript provides only high-level description of domain coverage and hijackment injection without quantitative metrics (e.g., distribution of hijackment types, inter-task difficulty calibration, or inter-rater agreement on realism). This is load-bearing for the central realism claim and the interpretation of the 49.1% vs. near-zero gap.
Authors: We agree that additional quantitative metrics would further substantiate the central realism claim. While the tasks are sourced directly from production risk-control pipelines (ensuring ecological validity by construction), the original manuscript indeed provided only high-level descriptions. In the revised version, we have expanded the task curation subsection with: (1) the empirical distribution of hijackment types across all 1,513 tasks (e.g., 37% pop-up injections, 29% DOM state alterations, 22% session timeouts, 12% other), (2) inter-task difficulty calibration via expert-rated complexity scores (mean 6.8/10, std 1.9) with inter-rater agreement (Cohen's kappa = 0.81), and (3) per-domain task counts with realism ratings. These additions directly support the 49.1% vs. near-zero performance gap without changing any results or conclusions. revision: yes
Circularity Check
No significant circularity
full rationale
The paper is an empirical benchmark release with no equations, derivations, fitted parameters, or mathematical claims. Its core contribution is the construction of 1,513 production-sourced tasks and Gymnasium infrastructure, followed by direct model evaluations; these steps are externally verifiable and do not reduce to self-definition, self-citation chains, or renaming of prior results. The 'first highly realistic' positioning is a descriptive claim supported by implementation details rather than a load-bearing theorem.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Claude sonnet 4.5 system card, 2025
Anthropic. Claude sonnet 4.5 system card, 2025
2025
-
[2]
Computer use (beta)
Anthropic. Computer use (beta). https://docs.anthropic.com/en/docs/ agents-and-tools/computer-use, n.d. Accessed: 2025-05-03
2025
-
[3]
WebGym: Scaling Training Environments for Visual Web Agents with Realistic Tasks
Hao Bai, Alexey Taymanov, Tong Zhang, Aviral Kumar, and Spencer Whitehead. Web- gym: Scaling training environments for visual web agents with realistic tasks.arXiv preprint arXiv:2601.02439, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[4]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, Wenbin Ge, Zhifang Guo, Qidong Huang, Jie Huang, Fei Huang, Binyuan Hui, Shutong Jiang, Zhaohai Li, Mingsheng Li, Mei Li, Kaixin Li, Zicheng Lin, Junyang Lin, Xuejing Liu, Jiawei Liu, Chenglong Liu, Yang Liu, Dayiheng Liu, Shixuan ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
RISK: A Framework for GUI Agents in E-commerce Risk Management
Renqi Chen, Zeyin Tao, Jianming Guo, Jingzhe Zhu, Yiheng Peng, Qingqing Sun, Tianyi Zhang, and Shuai Chen. Risk: A framework for gui agents in e-commerce risk management.arXiv preprint arXiv:2509.21982, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Mind2web: Towards a generalist agent for the web.Advances in Neural Information Processing Systems, 36:28091–28114, 2023
Xiang Deng, Yu Gu, Boyuan Zheng, Shijie Chen, Sam Stevens, Boshi Wang, Huan Sun, and Yu Su. Mind2web: Towards a generalist agent for the web.Advances in Neural Information Processing Systems, 36:28091–28114, 2023
2023
-
[7]
Group-in-Group Policy Optimization for LLM Agent Training
Lang Feng, Zhenghai Xue, Tingcong Liu, and Bo An. Group-in-group policy optimization for llm agent training.arXiv preprint arXiv:2505.10978, 2025
work page internal anchor Pith review arXiv 2025
-
[8]
Chengguang Gan, Yoshihiro Tsujii, Yunhao Liang, Tatsunori Mori, Shiwen Ni, and Hiroki Itoh. Guideweb: A benchmark for automatic in-app guide generation on real-world web uis.arXiv preprint arXiv:2602.01917, 2026
-
[9]
Ui-venus-1.5 technical report.arXiv preprint arXiv:2602.09082, 2026
Changlong Gao, Zhangxuan Gu, Yulin Liu, Xinyu Qiu, Shuheng Shen, Yue Wen, Tianyu Xia, Zhenyu Xu, Zhengwen Zeng, Beitong Zhou, et al. Ui-venus-1.5 technical report.arXiv preprint arXiv:2602.09082, 2026
-
[10]
Assistgui: Task-oriented pc graphical user interface automation
Difei Gao, Lei Ji, Zechen Bai, Mingyu Ouyang, Peiran Li, Dongxing Mao, Qinchen Wu, Weichen Zhang, Peiyi Wang, Xiangwu Guo, et al. Assistgui: Task-oriented pc graphical user interface automation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13289–13298, 2024
2024
-
[11]
Gemini 3 pro, 2025
Google. Gemini 3 pro, 2025
2025
-
[12]
Li Gu, Zihuan Jiang, Zhixiang Chi, Huan Liu, Ziqiang Wang, Yuanhao Yu, Glen Berseth, and Yang Wang. Generalization in online reinforcement learning for mobile agents.arXiv preprint arXiv:2603.07432, 2026. 10
-
[13]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
Longjie Guo, Chenjie Yuan, Mingyuan Zhong, Robert Wolfe, Ruican Zhong, Yue Xu, Bingbing Wen, Hua Shen, Lucy Lu Wang, and Alexis Hiniker. Susbench: An online benchmark for evaluating dark pattern susceptibility of computer-use agents.arXiv preprint arXiv:2510.11035, 2025
-
[15]
Webvoyager: Building an end-to-end web agent with large multimodal models,
Hongliang He, Wenlin Yao, Kaixin Ma, Wenhao Yu, Yong Dai, Hongming Zhang, Zhenzhong Lan, and Dong Yu. Webvoyager: Building an end-to-end web agent with large multimodal models.arXiv preprint arXiv:2401.13919, 2024
-
[16]
Wenyi Hong, Wenmeng Yu, Xiaotao Gu, Guo Wang, Guobing Gan, Haomiao Tang, Jiale Cheng, Ji Qi, Junhui Ji, Lihang Pan, et al. Glm-4.5 v and glm-4.1 v-thinking: Towards versatile multimodal reasoning with scalable reinforcement learning.arXiv preprint arXiv:2507.01006, 2025
work page internal anchor Pith review arXiv 2025
-
[17]
MobiBench: Multi-Branch, Modular Benchmark for Mobile GUI Agents
Youngmin Im, Byeongung Jo, Jaeyoung Wi, Seungwoo Baek, Tae Hoon Min, Joo Hyung Lee, Sangeun Oh, Insik Shin, and Sunjae Lee. Modular and multi-path-aware offline benchmarking for mobile gui agents.arXiv preprint arXiv:2512.12634, 2025
work page internal anchor Pith review arXiv 2025
-
[18]
Appagentx: Evolving gui agents as proficient smartphone users.arXiv preprint arXiv:2503.02268, 2025
Wenjia Jiang, Yangyang Zhuang, Chenxi Song, Xu Yang, Joey Tianyi Zhou, and Chi Zhang. Ap- pagentx: Evolving gui agents as proficient smartphone users.arXiv preprint arXiv:2503.02268, 2025
-
[19]
Omniact: A dataset and benchmark for enabling multimodal generalist autonomous agents for desktop and web
Raghav Kapoor, Yash Parag Butala, Melisa Russak, Jing Yu Koh, Kiran Kamble, Waseem AlShikh, and Ruslan Salakhutdinov. Omniact: A dataset and benchmark for enabling multimodal generalist autonomous agents for desktop and web. InEuropean Conference on Computer Vision, pages 161–178. Springer, 2024
2024
-
[20]
Quyu Kong, Xu Zhang, Zhenyu Yang, Nolan Gao, Chen Liu, Panrong Tong, Chenglin Cai, Hanzhang Zhou, Jianan Zhang, Liangyu Chen, et al. Mobileworld: Benchmarking autonomous mobile agents in agent-user interactive and mcp-augmented environments.arXiv preprint arXiv:2512.19432, 2025
-
[21]
Shrinidhi Kumbhar, Haofu Liao, Srikar Appalaraju, and Kunwar Yashraj Singh. Towards gui agents: Vision-language diffusion models for gui grounding.arXiv preprint arXiv:2603.26211, 2026
-
[22]
Juyong Lee, Taywon Min, Minyong An, Dongyoon Hahm, Haeone Lee, Changyeon Kim, and Kimin Lee. Benchmarking mobile device control agents across diverse configurations.arXiv preprint arXiv:2404.16660, 2024
-
[23]
Yanda Li, Chi Zhang, Wanqi Yang, Bin Fu, Pei Cheng, Xin Chen, Ling Chen, and Yunchao Wei. Appagent v2: Advanced agent for flexible mobile interactions.arXiv preprint arXiv:2408.11824, 2024
-
[24]
Gui-ceval: A hierarchical and comprehensive chinese benchmark for mobile gui agents,
Yang Li, Yuchen Liu, Haoyu Lu, Zhiqiang Xia, Hongzhen Wang, Kaiyang Han, Changpeng Yang, Jinyang Wu, Jiaming Xu, Runyu Shi, et al. Gui-ceval: A hierarchical and comprehensive chinese benchmark for mobile gui agents.arXiv preprint arXiv:2603.15039, 2026
-
[25]
Openmanus: An open-source framework for building general ai agents, 2025
Xinbin Liang, Jinyu Xiang, Zhaoyang Yu, Jiayi Zhang, Sirui Hong, Sheng Fan, and Xiao Tang. Openmanus: An open-source framework for building general ai agents, 2025
2025
-
[26]
Zeyi Liao, Jaylen Jones, Linxi Jiang, Yuting Ning, Eric Fosler-Lussier, Yu Su, Zhiqiang Lin, and Huan Sun. Redteamcua: Realistic adversarial testing of computer-use agents in hybrid web-os environments.arXiv preprint arXiv:2505.21936, 2025
-
[27]
Showui: One vision-language-action model for gui visual agent
Kevin Qinghong Lin, Linjie Li, Difei Gao, Zhengyuan Yang, Shiwei Wu, Zechen Bai, Stan Weix- ian Lei, Lijuan Wang, and Mike Zheng Shou. Showui: One vision-language-action model for gui visual agent. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 19498–19508, 2025. 11
2025
-
[28]
Learnact: Few-shot mobile gui agent with a unified demonstration benchmark,
Guangyi Liu, Pengxiang Zhao, Liang Liu, Zhiming Chen, Yuxiang Chai, Shuai Ren, Hao Wang, Shibo He, and Wenchao Meng. Learnact: Few-shot mobile gui agent with a unified demonstration benchmark.arXiv preprint arXiv:2504.13805, 2025
-
[29]
Yuxuan Lu, Jing Huang, Hui Liu, Jiri Gesi, Yan Han, Shihan Fu, Tianqi Zheng, and Dakuo Wang. Webserv: A browser-server environment for efficient training of reinforcement learning-based web agents at scale.arXiv preprint arXiv:2510.16252, 2025
-
[30]
GUI-R1 : A Generalist R1-Style Vision-Language Action Model For GUI Agents
Run Luo, Lu Wang, Wanwei He, and Xiaobo Xia. Gui-r1: A generalist r1-style vision-language action model for gui agents.arXiv preprint arXiv:2504.10458, 2025
work page internal anchor Pith review arXiv 2025
-
[31]
Gaia: a benchmark for general ai assistants
Grégoire Mialon, Clémentine Fourrier, Thomas Wolf, Yann LeCun, and Thomas Scialom. Gaia: a benchmark for general ai assistants. InThe Twelfth International Conference on Learning Representations, 2023
2023
-
[32]
Browser use: Enable ai to control your browser, 2024
Magnus Müller and Gregor Žuni ˇc. Browser use: Enable ai to control your browser, 2024
2024
-
[33]
Gui agents: A survey
Dang Nguyen, Jian Chen, Yu Wang, Gang Wu, Namyong Park, Zhengmian Hu, Hanjia Lyu, Junda Wu, Ryan Aponte, Yu Xia, et al. Gui agents: A survey. InFindings of the Association for Computational Linguistics: ACL 2025, pages 22522–22538, 2025
2025
-
[34]
Computer-using agent
OpenAI. Computer-using agent. https://openai.com/index/computer-using-agent/, January 2025. Published: January 23, 2025; Accessed: 2025-05-03
2025
-
[35]
Introducing gpt 5.2, 2025
OpenAI. Introducing gpt 5.2, 2025
2025
-
[36]
arXiv preprint arXiv:2406.12373 , year=
Yichen Pan, Dehan Kong, Sida Zhou, Cheng Cui, Yifei Leng, Bing Jiang, Hangyu Liu, Yanyi Shang, Shuyan Zhou, Tongshuang Wu, et al. Webcanvas: Benchmarking web agents in online environments.arXiv preprint arXiv:2406.12373, 2024
-
[37]
Webmall– a multi-shop benchmark for evaluating web agents.arXiv e-prints, pages arXiv–2508, 2025
Ralph Peeters, Aaron Steiner, Luca Schwarz, Julian Yuya Caspary, and Christian Bizer. Webmall– a multi-shop benchmark for evaluating web agents.arXiv e-prints, pages arXiv–2508, 2025
2025
-
[38]
UI-TARS: Pioneering Automated GUI Interaction with Native Agents
Yujia Qin, Yining Ye, Junjie Fang, Haoming Wang, Shihao Liang, Shizuo Tian, Junda Zhang, Jiahao Li, Yunxin Li, Shijue Huang, et al. Ui-tars: Pioneering automated gui interaction with native agents.arXiv preprint arXiv:2501.12326, 2025
work page Pith review arXiv 2025
-
[39]
Qwen3.5: Towards native multimodal agents, February 2026
Qwen Team. Qwen3.5: Towards native multimodal agents, February 2026
2026
-
[40]
AndroidWorld: A Dynamic Benchmarking Environment for Autonomous Agents
Christopher Rawles, Sarah Clinckemaillie, Yifan Chang, Jonathan Waltz, Gabrielle Lau, Mary- beth Fair, Alice Li, William Bishop, Wei Li, Folawiyo Campbell-Ajala, et al. Android- world: A dynamic benchmarking environment for autonomous agents.URL https://arxiv. org/abs/2405.14573, 2024
work page internal anchor Pith review arXiv 2024
-
[41]
An- droidinthewild: A large-scale dataset for android device control.Advances in Neural Information Processing Systems, 36:59708–59728, 2023
Christopher Rawles, Alice Li, Daniel Rodriguez, Oriana Riva, and Timothy Lillicrap. An- droidinthewild: A large-scale dataset for android device control.Advances in Neural Information Processing Systems, 36:59708–59728, 2023
2023
-
[42]
Marta Sumyk and Oleksandr Kosovan. Cuaaudit: Meta-evaluation of vision-language models as auditors of autonomous computer-use agents.arXiv preprint arXiv:2603.10577, 2026
-
[43]
GUI-G2: Gaussian reward modeling for gui grounding.arXiv preprint arXiv:2507.15846, 2025
Fei Tang, Zhangxuan Gu, Zhengxi Lu, Xuyang Liu, Shuheng Shen, Changhua Meng, Wen Wang, Wenqi Zhang, Yongliang Shen, Weiming Lu, et al. Gui-g2: Gaussian reward modeling for gui grounding.arXiv preprint arXiv:2507.15846, 2025
-
[44]
Kimi Team, Tongtong Bai, Yifan Bai, Yiping Bao, SH Cai, Yuan Cao, Y Charles, HS Che, Cheng Chen, Guanduo Chen, et al. Kimi k2. 5: Visual agentic intelligence.arXiv preprint arXiv:2602.02276, 2026
work page internal anchor Pith review arXiv 2026
-
[45]
Kimi Team, Angang Du, Bohong Yin, Bowei Xing, Bowen Qu, Bowen Wang, Cheng Chen, Chenlin Zhang, Chenzhuang Du, Chu Wei, Congcong Wang, Dehao Zhang, Dikang Du, Dongliang Wang, Enming Yuan, Enzhe Lu, Fang Li, Flood Sung, Guangda Wei, Guokun Lai, Han Zhu, Hao Ding, Hao Hu, Hao Yang, Hao Zhang, Haoning Wu, Haotian Yao, Haoyu Lu, Heng Wang, Hongcheng Gao, Huabi...
2025
-
[46]
UI-TARS-2 Technical Report: Advancing GUI Agent with Multi-Turn Reinforcement Learning
Haoming Wang, Haoyang Zou, Huatong Song, Jiazhan Feng, Junjie Fang, Junting Lu, Longxi- ang Liu, Qinyu Luo, Shihao Liang, Shijue Huang, et al. Ui-tars-2 technical report: Advancing gui agent with multi-turn reinforcement learning.arXiv preprint arXiv:2509.02544, 2025
work page internal anchor Pith review arXiv 2025
-
[47]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Shao, et al. Internvl3.5: Advancing open-source multimodal models in versatility, reasoning, and efficiency.arXiv preprint arXiv:2508.18265, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[48]
GUIGuard: Toward a General Framework for Privacy-Preserving GUI Agents, jan 2026
Yanxi Wang, Zhiling Zhang, Wenbo Zhou, Weiming Zhang, Jie Zhang, Qiannan Zhu, Yu Shi, Shuxin Zheng, and Jiyan He. Guiguard: Toward a general framework for privacy-preserving gui agents.arXiv preprint arXiv:2601.18842, 2026
work page internal anchor Pith review arXiv 2026
-
[49]
arXiv preprint arXiv:2501.11733 , year=
Zhenhailong Wang, Haiyang Xu, Junyang Wang, Xi Zhang, Ming Yan, Ji Zhang, Fei Huang, and Heng Ji. Mobile-agent-e: Self-evolving mobile assistant for complex tasks.arXiv preprint arXiv:2501.11733, 2025
-
[50]
Jing Wu, Daphne Barretto, Yiye Chen, Nicholas Gydé, Yanan Jian, Yuhang He, and Vibhav Vineet. Os-marathon: Benchmarking computer-use agents on long-horizon repetitive tasks. arXiv preprint arXiv:2601.20650, 2026
-
[51]
Tianbao Xie, Jiaqi Deng, Xiaochuan Li, Junlin Yang, Haoyuan Wu, Jixuan Chen, Wenjing Hu, Xinyuan Wang, Yuhui Xu, Zekun Wang, et al. Scaling computer-use grounding via user interface decomposition and synthesis.arXiv preprint arXiv:2505.13227, 2025
-
[52]
Osworld: Benchmarking multimodal agents for open-ended tasks in real computer environments.Advances in Neural Information Processing Systems, 37:52040–52094, 2024
Tianbao Xie, Danyang Zhang, Jixuan Chen, Xiaochuan Li, Siheng Zhao, Ruisheng Cao, Toh J Hua, Zhoujun Cheng, Dongchan Shin, Fangyu Lei, et al. Osworld: Benchmarking multimodal agents for open-ended tasks in real computer environments.Advances in Neural Information Processing Systems, 37:52040–52094, 2024
2024
-
[53]
Haiyang Xu, Xi Zhang, Haowei Liu, Junyang Wang, Zhaozai Zhu, Shengjie Zhou, Xuhao Hu, Feiyu Gao, Junjie Cao, Zihua Wang, et al. Mobile-agent-v3. 5: Multi-platform fundamental gui agents.arXiv preprint arXiv:2602.16855, 2026
-
[54]
Turkingbench: A challenge benchmark for web agents
Kevin Xu, Yeganeh Kordi, Tanay Nayak, Adi Asija, Yizhong Wang, Kate Sanders, Adam Byerly, Jingyu Zhang, Benjamin Van Durme, and Daniel Khashabi. Turkingbench: A challenge benchmark for web agents. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volum...
2025
- [55]
-
[56]
Jingyi Yang, Shuai Shao, Dongrui Liu, and Jing Shao. Riosworld: Benchmarking the risk of multimodal computer-use agents.arXiv preprint arXiv:2506.00618, 2025
-
[57]
Pei Yang, Hai Ci, and Mike Zheng Shou. macosworld: A multilingual interactive benchmark for gui agents.arXiv preprint arXiv:2506.04135, 2025
-
[58]
Webshop: Towards scalable real-world web interaction with grounded language agents.Advances in Neural Information Processing Systems, 35:20744–20757, 2022
Shunyu Yao, Howard Chen, John Yang, and Karthik Narasimhan. Webshop: Towards scalable real-world web interaction with grounded language agents.Advances in Neural Information Processing Systems, 35:20744–20757, 2022. 13
2022
-
[59]
Realwe- bassist: A benchmark for long-horizon web assistance with real-world users
Suyu Ye, Haojun Shi, Darren Shih, Hyokun Yun, Tanya G Roosta, and Tianmin Shu. Realwe- bassist: A benchmark for long-horizon web assistance with real-world users. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 34441–34449, 2026
2026
- [60]
-
[61]
A Functionality-Grounded Benchmark for Evaluating Web Agents in E-commerce Domains
Xianren Zhang, Shreyas Prasad, Di Wang, Qiuhai Zeng, Suhang Wang, Wenbo Yan, and Mat Hans. A functionality-grounded benchmark for evaluating web agents in e-commerce domains. arXiv preprint arXiv:2508.15832, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[62]
Cola: Collaborative multi-agent framework with dynamic task scheduling for gui automation
Di Zhao, Longhui Ma, Siwei Wang, Miao Wang, and Zhao Lv. Cola: Collaborative multi-agent framework with dynamic task scheduling for gui automation. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 4570–4593, 2025
2025
-
[63]
WebArena: A Realistic Web Environment for Building Autonomous Agents
Shuyan Zhou, Frank F Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, et al. Webarena: A realistic web environment for building autonomous agents.arXiv preprint arXiv:2307.13854, 2023
work page Pith review arXiv 2023
-
[64]
Yuqi Zhou, Sunhao Dai, Shuai Wang, Kaiwen Zhou, Qinglin Jia, and Jun Xu. Gui-g1: Understanding r1-zero-like training for visual grounding in gui agents.arXiv preprint arXiv:2505.15810, 2025. 14 Appendix A Limitations and Future Work 15 B Code and Data Availability 15 C Impact Statement 16 D Ethical, Privacy, and Safeguarding Statement 16 E Example of a Re...
-
[65]
N a v i g a t i n g complex w eb si tes and e x t r a c t i n g precise i n f o r m a t i o n
-
[66]
A u t o m a t i n g form s u b m i s s i o n s and i n t e r a c t i v e web actions
-
[67]
G a t h e r i n g and saving i n f o r m a t i o n
-
[68]
Using your f i l e s y s t e m e f f e c t i v e l y to decide what to keep in your ,→context
-
[69]
Operate e f f e c t i v e l y in an agent loop
-
[70]
E f f i c i e n t l y p e r f o r m i n g diverse web tasks </ intro > < l a n g u a g e _ s e t t i n g s > - Default working l an gu age : ** English ** - Always respond in the same l an gu age as the user request </ l a n g u a g e _ s e t t i n g s > < input > At every step , your input will consist of :
-
[71]
< agent_history >: A c h r o n o l o g i c a l event stream i n c l u d i n g your p re vi ous ,→actions and their results
-
[72]
< agent_state >: Current < user_request > , summary of < todo_contents > , ,→and < step_info >
-
[73]
< browser_state >: Current URL , open tabs , i n t e r a c t i v e e le men ts indexed ,→for actions , and visible page content
-
[74]
If you used s c r e e n s h o t before , this ,→will contain a s c r e e n s h o t
< browser_vision >: S c r e e n s h o t of the browser with b ou ndi ng boxes ,→around i n t e r a c t i v e el em ent s . If you used s c r e e n s h o t before , this ,→will contain a s c r e e n s h o t
-
[75]
This data is only shown in the current step ,→
< read_state > This will be d i s p l a y e d only if your p re vi ou s action was ,→extract or r e a d _ f i l e . This data is only shown in the current step ,→. </ input > < agent_history > Agent history will be given as a list of step i n f o r m a t i o n as follows : < step_ {{ s t e p _ n u m b e r }} >: E v a l u a t i o n of Pre vi ou s Step : A ...
-
[76]
Open Tabs : Open tabs with their ids
Browser State will be given as : Current URL : URL of the page you are c u r r e n t l y viewing . Open Tabs : Open tabs with their ids . I n t e r a c t i v e E le men ts : All i n t e r a c t i v e el em en ts will be p ro vi de d in ,→format as [ index ] < type > text </ type > where - index : Numeric i d e n t i f i e r for i n t e r a c t i o n - typ...
-
[77]
results . md
< div > User form </ div > \ t *[35] < button aria - label = ’ Submit form ’ > Submit </ button > Note that : 20 - Only ele me nt s with numeric indexes in [] are i n t e r a c t i v e - ( stacked ) i n d e n t a t i o n ( with \ t ) is i m p o r t a n t and means that the ,→element is a ( html ) child of the element above ( with a lower ,→index ) - E lem...
-
[78]
a c t i o n _ n a m e
WRONG FORMAT : {{" a c t i o n _ n a m e ": " input " , " params ": {{" index ": 1 , ,→...}}}}
-
[79]
input ": {{
CORRECT FORMAT : {{" input ": {{" index ": 1 , " text ": " example " , " clear ": ,→true }}}}
-
[80]
action
" action " is an array . You can provide up to { m a x _ a c t i o n s } actions , ,→except for " done " which must be a single action . </ output > The system prompt for the flash mode is given by: You are an AI agent d es ign ed to operate in an i t e r a t i v e loop to au to ma te ,→browser tasks . Your u lt im at e goal is a c c o m p l i s h i n g t...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.